A liderança da Red Hat no espaço de orquestração de contêineres com o OpenShift reflete a liderança da Couchbase no espaço de banco de dados em contêineres com seu Autonomous Operator. Esse fato é a base da parceria entre a Red Hat e a Couchbase. Eu trabalhei pessoalmente na parceria nos últimos dois anos. Gostaria de aproveitar esta oportunidade para discutir por que agora é um ótimo momento para executar o Couchbase no Red Hat OpenShift.
O "estado" atual do Kubernetes
Antes de ingressar no Couchbase, trabalhei em uma empresa de monitoramento de SaaS. Trabalhar em uma empresa de monitoramento lhe dá uma visão única das tecnologias que seus clientes estão usando. Em 2017, era possível ver o ponto de inflexão do Kubernetes e do OpenShift nos painéis de monitoramento dos nossos clientes. Ficou claro que o Red Hat OpenShift estava vencendo a guerra da orquestração de contêineres entre as grandes empresas. Mas havia uma coisa que você definitivamente não via: bancos de dados no Kubernetes. Especialmente na produção. De fato, a execução de qualquer carga de trabalho "com estado" no Kubernetes era considerada arriscada. A arquitetura típica envolvia a execução de suas cargas de trabalho sem estado no Kubernetes ou no OpenShift e a execução de seus bancos de dados em outro lugar.
Como qualquer engenheiro de banco de dados lhe dirá, gerenciar o estado em um aplicativo distribuído é difícil. Quando você adiciona várias camadas de abstração e dimensionamento elástico à mistura, fica ainda mais difícil. O Kubernetes é e foi ótimo no gerenciamento de recursos de computação e memória, mas o armazenamento não era algo gerenciado diretamente pelo Kubernetes. Em outras palavras, o Kubernetes e o OpenShift eram ótimos para gerenciar cargas de trabalho sem estado, mas apenas algumas almas corajosas ousavam executar aplicativos persistentes e com estado diretamente no Kubernetes (ou seja, bancos de dados). O padrão típico era hospedar seu banco de dados em outro lugar (veja "Then" no diagrama abaixo).
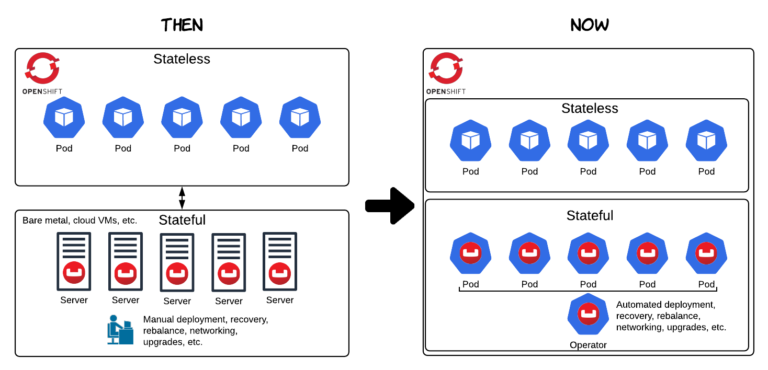
Armazenamento - Volumes persistentes
A comunidade queria resolver esse problema e Volumes persistentes foi um importante elemento de construção. Os Volumes Persistentes (PVs) forneceram uma solução para o gerenciamento e o isolamento do armazenamento na forma de uma API que suporta a conexão de diferentes classes de armazenamento para os pods em execução. Os PVs têm um ciclo de vida independente de qualquer pod individual, o que permite que eles persistam seus dados mesmo depois que um pod é destruído. Isso significa que você não precisa se preocupar com a perda de dados em um cenário de desastre quando perde um banco de dados ou um nó do OpenShift.
Vários fornecedores de armazenamento adicionaram suporte ao Kubernetes por meio da API Persistent Volumes, incluindo os provedores de nuvem e o parceiro Red Hat, Portworx. Isso significa que você tem opções ao escolher seu armazenamento. Isso é fundamental do ponto de vista de um fornecedor de banco de dados, em que a escolha do armazenamento correto pode ter um grande impacto no desempenho e na confiabilidade.
A estrutura do operador
A segunda grande inovação, que permitiu que o Couchbase se tornasse o líder em bancos de dados NoSQL no OpenShift, é o o Estrutura do operador. A Couchbase foi a primeira empresa de banco de dados NoSQL a fazer um investimento sério no desenvolvimento de um Operator (consulte "Principais operadores de Kubernetes que avançam no modelo de capacidade do operador"). Colaboramos com a equipe do CoreOS desde o início do desenvolvimento do Operator Framework. Hoje, os clientes do Couchbase podem contar com o Couchbase Autonomous Operator para gerenciar muitas das operações de cluster, incluindo implantação, dimensionamento, recuperação de desastres, atualizações contínuas e muito mais. Isso representa um enorme valor para os clientes do Couchbase e também está ajudando a impulsionar a adoção do OpenShift.
Então, o que é um Operator? Esta citação da equipe do Red Hat CoreOS resume melhor:
"Conceitualmente, Um Operador pega o conhecimento operacional humano e o codifica em um software que é mais facilmente empacotado e compartilhado com os consumidores. Pense em um Operador como uma extensão da equipe de engenharia do fornecedor de software que vigia seu ambiente Kubernetes e usa seu estado atual para tomar decisões em milissegundos. Os operadores seguem um modelo de maturidade que vai desde a funcionalidade básica até a lógica específica de um aplicativo. Os operadores avançados são projetados para lidar com upgrades sem problemas, reagir a falhas automaticamente e não tomar atalhos, como pular um processo de backup de software para economizar tempo."
https://coreos.com/blog/introducing-operator-framework
Como o gerenciamento do estado distribuído é desafiador, e sistemas diferentes gerenciam o estado de forma diferente com base em detalhes de implementação muito específicos, nunca foi razoável esperar que a comunidade Kubernetes codificasse para todos os cenários possíveis que todo e qualquer aplicativo com estado poderia encontrar. O Operator Framework permite que os desenvolvedores preencham essa lacuna e façam isso de uma forma que se encaixe no paradigma do Kubernetes. Por exemplo: Em um cenário de desastre, quando um nó do OpenShift que executa um pod do Couchbase fica inativo, o Operador Autônomo do Couchbase restaurará o cluster de forma automática e graciosa e reequilibrará seus dados sem nenhuma interrupção dos serviços que usam o Couchbase. E, se você estiver usando Persistent Volumes, ele até mesmo reanexará o volume do pod perdido ao novo pod do Couchbase, acelerando consideravelmente o tempo necessário para reequilibrar os dados.
Gerente do ciclo de vida do operador
À medida que os operadores amadureceram, o mesmo aconteceu com as ferramentas que os cercam. O melhor exemplo é o Gerente do ciclo de vida do operador (OLM). OLM estava em pré-visualização técnica a partir do OpenShift 3.11. A partir do OpenShift 4, ele é um recurso oficialmente suportado. Normalmente, a instalação de um Operator requer privilégios de administrador de cluster e algumas etapas manuais, como a instalação de um Definição de recursos personalizados. O OLM automatiza a tarefa de instalação e também pode gerenciar atualizações para você sem exigir privilégios de administrador de cluster. O OLM se conecta diretamente ao OperatorHub ou seja, à medida que novas atualizações de Operator forem lançadas, elas aparecerão no catálogo do OperatorHub e poderão ser instaladas por meio do OLM. Isso permite que os usuários encontrem o Operator de que precisam e o instalem com apenas alguns cliques.
Um dos principais benefícios disso é a produtividade do desenvolvedor. Ele oferece aos desenvolvedores "Operadores como serviço" em seus ambientes de desenvolvimento OpenShift.
Por que o Couchbase?
Nos últimos anos, o termo "Cloud Native" tornou-se parte da linguagem comum em tecnologia. Ele aparece com frequência principalmente no contexto das discussões sobre o Kubernetes e o OpenShift. O Kubernetes é frequentemente posicionado como a plataforma para aplicativos nativos da nuvem. Cloud Native significa software projetado para aproveitar o modelo de computação em nuvem. Na prática, isso significa que os aplicativos se encaixam mais em um padrão de arquitetura orientada a serviços e microsserviços (em oposição a uma arquitetura monolítica), visam à escala horizontal (em oposição à escala vertical) e podem ser executados em contêineres relativamente leves. Isso representa um problema para os bancos de dados tradicionais relacionais (e alguns NoSQL), que seguem muito os padrões monolíticos e não foram projetados para escalonar horizontalmente da mesma forma que o Couchbase.
É nesse ponto que o Couchbase se destaca em relação a outras opções. No início da vida do Couchbase, ele foi pressionado e desafiado a suportar cargas de trabalho em escala da Web em ambientes de nuvem por seus maiores usuários. Desde o início, o Couchbase adotou uma arquitetura que se assemelha ao que hoje chamamos de Cloud Native. No Couchbase, isso se reflete em nossa Dimensionamento multidimensional capacidade. O dimensionamento multidimensional permite que cada um dos serviços do Couchbase (dados, índice, consulta, análise, pesquisa de texto completo e eventos) seja dimensionado de forma independente, enquanto estiver on-line e atendendo ao tráfego. É exatamente assim que você deseja projetar um aplicativo com a nuvem nativa em mente.
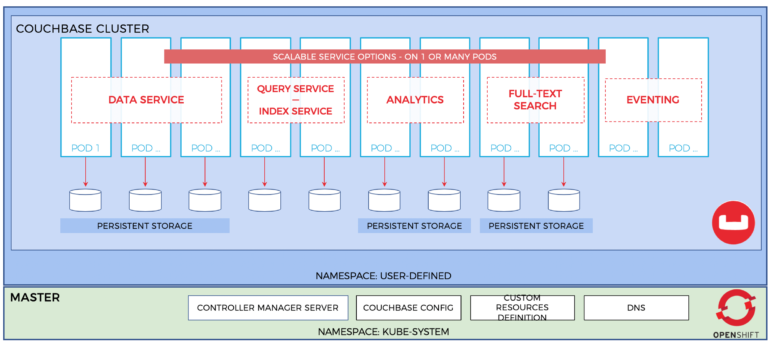
Além do dimensionamento multidimensional, outros recursos do Couchbase, como o armazenamento automático e uma interface administrativa integrada e robusta, ajudam a facilitar a experiência de gerenciamento das cargas de trabalho NoSQL no OpenShift.
Para onde vamos a partir de agora
Operador autônomo do Couchbase 2.0 Beta
Nosso objetivo é automatizar todas as práticas recomendadas operacionais do Couchbase necessárias para executar clusters com nosso Operador. O objetivo final é que nossos clientes e os clientes da Red Hat possam operar com eficiência seu próprio DBaaS do Couchbase em qualquer ambiente OpenShift na nuvem, no local ou em ambos. Até mesmo a própria oferta de DBaaS do Couchbase depende muito do Couchbase Autonomous Operator.
Recentemente, lançamos o Operador autônomo do Couchbase 2.0 Beta. Embora continuemos a adicionar novos recursos ao próprio Operador, reconhecemos que o Couchbase é apenas uma parte da infraestrutura. Na prática, há outras funções, como monitoramento de métricas e logs e segurança, que abrangem várias partes da infraestrutura. O Operator 2.0 inclui a integração com o Couchbase Prometheus Exporter para coletar e expor as métricas do Couchbase Server. Isso significa que você pode monitorar o Couchbase junto com outros aplicativos no ambiente Ret Hat OpenShift.
Habilitando cargas de trabalho de nuvem múltipla e híbrida
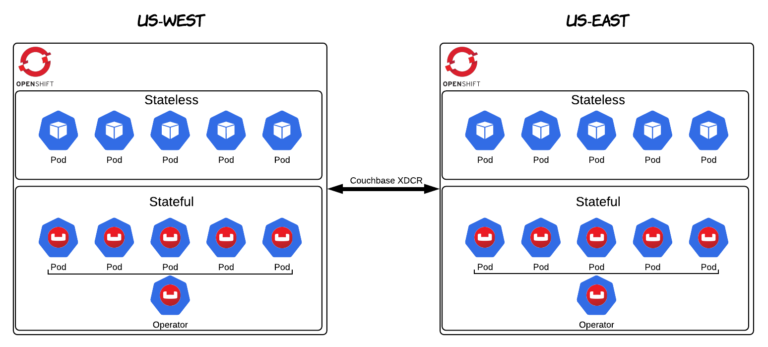
Eu seria negligente se não mencionasse outro recurso importante do Couchbase - o Replicação entre centros de dados (XDCR). O XDCR sempre foi um recurso popular do Couchbase. O motivo pelo qual ele é importante nesse contexto é sua função de permitir cargas de trabalho com estado em várias nuvens e na nuvem híbrida no OpenShift. O OpenShift já facilita a implantação de aplicativos em diferentes nuvens e no local. Com o XDCR, você também pode obter a replicação de dados entre clusters do OpenShift. Nas próximas semanas, nós (Red Had e Couchbase) planejamos fornecer mais conteúdo e atualizações sobre esse tópico especificamente. Fique ligado!
Recursos
- Blog do Red Hat OpenShift:Principais operadores de Kubernetes avançando no modelo de capacidade do operador
- Anúncio do Couchbase Autonomous Operator 2.0 Beta
- Instalação do operador autônomo do Couchbase no Red Hat OpenShift
- Página de parceiro do Couchbase na Red Hat