Ratnopam Chakrabarti é um desenvolvedor de software que trabalha atualmente para a Ericsson Inc. Ele tem se concentrado em IoT, tecnologias máquina a máquina, carros conectados e domínios de cidades inteligentes por um bom tempo. Ele adora aprender novas tecnologias e colocá-las em prática. Quando não está trabalhando, gosta de passar o tempo com seu filho de 3 anos.
A pesquisa baseada em texto completo é um recurso que permite que os usuários pesquisem com base em textos e palavras-chave, e é muito popular entre os usuários e a comunidade de desenvolvedores. Portanto, é óbvio que há muitas APIs e estruturas que oferecem pesquisa de texto completo, incluindo Apache Solr, Lucene e Elasticsearch, só para citar alguns. CouchbaseA Couchbase, uma das principais gigantes do NoSQL, começou a implementar esse recurso na versão 4.5 do Couchbase Server.
Nesta postagem, descreverei como integrar o serviço de pesquisa de texto completo em seu aplicativo usando o SDK Java do Couchbase.
Configuração
Vá para start.spring.io e selecione o Couchbase como uma dependência em seu aplicativo de inicialização do Spring.
Depois de configurar o projeto, você deverá ver a seguinte dependência no arquivo de modelo de objeto do projeto (pom.xml). Ela garante que todas as bibliotecas do Couchbase estejam instaladas para o aplicativo.
<dependency>
org.springframework.boot
spring-boot-starter-data-couchbase
</dependency>
Você precisa configurar um bucket do Couchbase para armazenar seu conjunto de dados de amostra para pesquisa.
Criei um bucket chamado "conference" no console de administração do Couchbase.
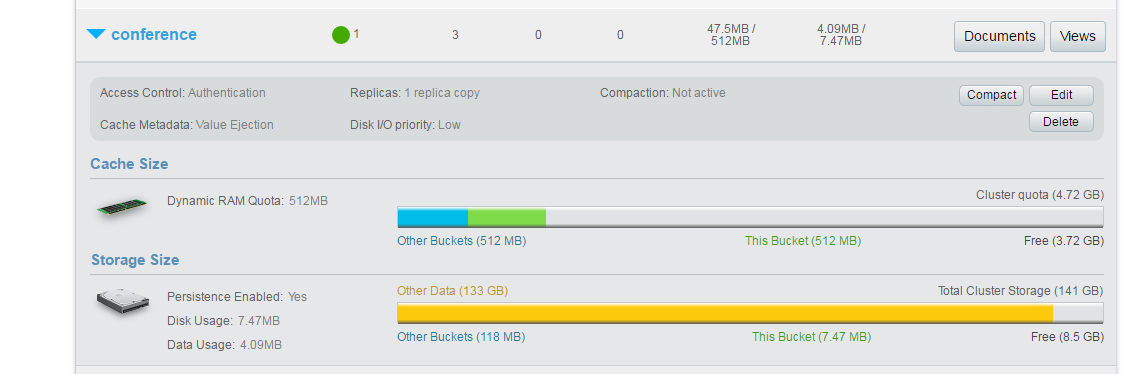
O compartimento "conference" tem três documentos no momento e eles contêm dados sobre diferentes conferências realizadas em todo o mundo. Você pode estender esse modelo de dados ou criar o seu próprio se quiser fazer experiências. Por exemplo, currículos, catálogos de produtos ou até mesmo tweets são bons casos de uso para a pesquisa de texto completo. No entanto, para o caso em questão, vamos nos ater aos dados da conferência, conforme mostrado abaixo:
{
"título": "DockerCon",
"Tipo": "Conferência",
"localização": "Austin",
"start": "04/17/2017",
"end": "04/20/2017",
"tópicos": [
"contêineres",
"devops",
"microsserviços",
"desenvolvimento de produtos",
"virtualização"
],
"participantes": 20000,
"summary": "A DockerCon apresentará tópicos e conteúdo que abrangem todos os aspectos do Docker e seu ecossistema e será adequada para desenvolvedores, DevOps, administradores de sistemas e executivos de nível C",
"social": {
"facebook": "https://www.facebook.com/dockercon",
"twitter": "https://www.twitter.com/dockercon"
},
"alto-falantes": [
{
"name": "Arun Gupta",
"talk": "Docker com couchbase",
"date": "04/18/2017",
"duração": "2"
},
{
"name": "Laura Frank",
"talk": "Opensource",
"date": "04/19/2017",
"duração": "2"
}
]
}
Para usar a pesquisa de texto completo no conjunto de dados acima, primeiro você precisa criar um índice de pesquisa de texto completo. Execute as etapas a seguir:
No console de administração do Couchbase, clique na guia Índices.
Clique no link Full Text (Texto completo), que listará os índices de texto completo atuais.
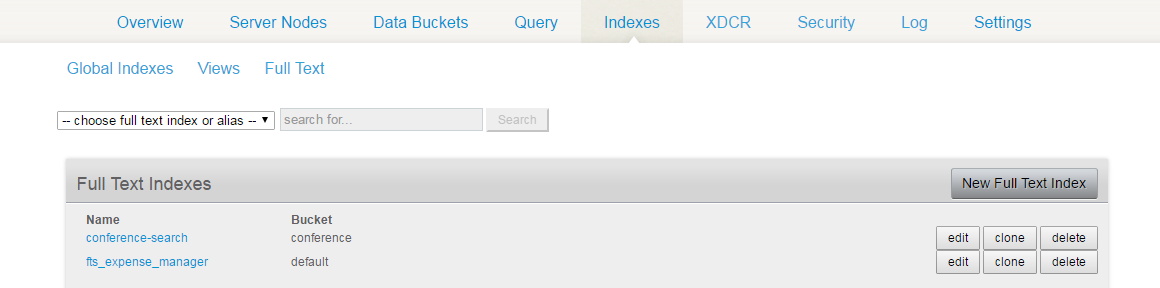
Como você pode imaginar, criei um índice chamado "conference-search" que eu usaria no código Java para pesquisar os dados relacionados à conferência.
Clique no botão New Full Text Index (Novo índice de texto completo) para criar um novo índice.
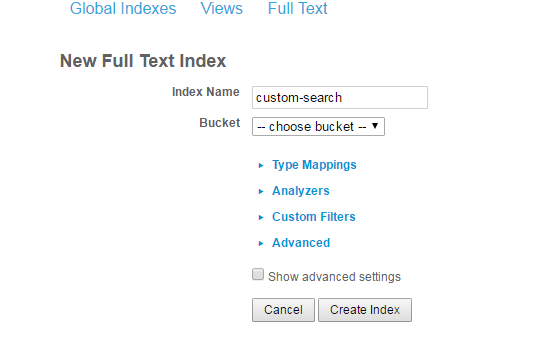
Sim, é muito fácil. Depois de criar o índice, você estará pronto para usá-lo no aplicativo que está criando.
Antes de nos aprofundarmos no código, vamos dar uma olhada nos outros dois documentos que já estão no balde.
Conferência::2
{
"título": "Devoxx UK",
"Tipo": "Conferência",
"localização": "Belgium",
"start": "05/11/2017",
"end": "05/12/2017",
"tópicos": [
"nuvem",
"iot",
"big data",
"aprendizado de máquina",
"realidade virtual"
],
"participantes": 10000,
"summary": "A Devoxx UK retorna a Londres em 2017. Mais uma vez, receberemos palestrantes e participantes incríveis para obter o melhor conteúdo para desenvolvedores e experiências incríveis",
"social": {
"facebook": "https://www.facebook.com/devoxxUK",
"twitter": "https://www.twitter.com/devoxxUK"
},
"alto-falantes": [
{
"name": "Viktor Farcic",
"talk": "Cloudbees",
"date": "05/11/2017",
"duração": "2"
},
{
"name": "Patrick Kua",
"talk": "Thoughtworks",
"date": "05/12/2017",
"duração": "2"
}
]
}
Conferência::3
{
"título": "ReInvent",
"Tipo": "Conferência",
"localização": "Las Vegas",
"start": "11/28/2017",
"end": "11/30/2017",
"tópicos": [
"aws",
"sem servidor",
"microsserviços",
"computação em nuvem",
"realidade aumentada"
],
"participantes": 30000,
"summary": "Aamazon web services reInvent 2017 promete um local maior, mais sessões e um foco em tecnologias como microsserviços e Lambda.",
"social": {
"facebook": "https://www.facebook.com/reinvent",
"twitter": "https://www.twitter.com/reinvent"
},
"alto-falantes": [
{
"name": "Ryan K",
"talk": "Amazon Alexa",
"date": "11/28/2017",
"duração": "2.5"
},
{
"name": "Anthony J",
"talk": "Lambda",
"date": "11/29/2017",
"duração": "1.5"
}
]
}
Chamando a pesquisa de texto completo a partir do código Java
Conectar-se ao bucket do Couchbase a partir do código
O Spring boot oferece uma maneira conveniente de se conectar ao ambiente do Couchbase, permitindo especificar determinados detalhes do ambiente do Couchbase como uma configuração do Spring. Normalmente, especificamos os seguintes parâmetros no arquivo application.properties:
spring.couchbase.bootstrap-hosts=127.0.0.1
spring.couchbase.bucket.name=conference
spring.couchbase.bucket.password=
Aqui, especifiquei meu IP localhost, pois estou executando o Couchbase Server no meu laptop. Observação: Você pode executar o Couchbase como um contêiner do Docker fornecendo o endereço IP do contêiner.
O nome do bucket deve corresponder ao nome do bucket criado usando o console do Couchbase.
Também podemos especificar um cluster de endereços IP como bootstrap-hosts. O Spring fornecerá um cluster de ambiente do Couchbase com todos os nós que executam o Couchbase neles. Se uma senha foi configurada quando o bucket foi criado, podemos especificá-la também; caso contrário, deixe esse campo vazio. No nosso caso, deixamos em branco.
Para executar a consulta em nosso bucket desejado, primeiro precisamos ter uma referência ao objeto bucket. E a configuração do spring-couchbase faz todo o trabalho pesado nos bastidores para nós. Tudo o que precisamos fazer é injetar o bucket no construtor da classe do bean de serviço do Spring.
Aqui está o código:
@Serviço
classe pública FullTextSearchService {
balde privado bucket;
public FullTextSearchService(Bucket bucket) {
this.bucket = bucket;
log.info("******** Bucket :: = " + bucket.name());
}
public void findByTextMatch(String searchText) throws Exception {
SearchQueryResult result = getBucket().query(
new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.matchPhrase(searchText)).fields("summary"));
para (SearchQueryRow hit : result.hits()) {
log.info("****** score := " + hit.score() + " e conteúdo := "
+ bucket.get(hit.id()).content().get("title"));
}
}
Também podemos personalizar alguns dos parâmetros de configuração do CouchbaseEnvironment. Para obter uma lista detalhada dos parâmetros que podemos personalizar, dê uma olhada no seguinte diretrizes de referência:
Nesse ponto, podemos chamar o serviço a partir do CommandLineRunner feijão.
@Configuração
public class FtsRunner implements CommandLineRunner {
@Autowired
FullTextSearchService fts;
@Override
public void run(String... arg0) throws Exception {
fts.findByTextMatch("developer");
}
}
Uso do serviço de pesquisa de texto completo
No núcleo do Java SDK, o Couchbase oferece consulta() como uma forma de consultar em um bucket especificado. Se você estiver familiarizado com o N1QL Query ou View Query, então o método consulta() oferece um padrão semelhante; a única diferença para o Search é que ele aceita um Pesquisa como um argumento.
A seguir, o código que pesquisa um determinado texto no compartimento "conference". getBucket() retorna um identificador do balde.
Ao criar uma SearchQuery, é necessário fornecer o nome do índice que foi criado na seção Configuração acima. Aqui, estou usando "conference-search" como o índice especificado em FtsConstants.FTS_IDX_CONF. A propósito, o código-fonte completo do aplicativo foi carregado no GitHub e está disponível para download. O link está no final da postagem.
public static void findByTextMatch(String searchText) throws Exception {
SearchQueryResult result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.matchPhrase(searchText)).fields("summary"));
log.info("****** total hits := "+ result.hits().size());
para (SearchQueryRow hit : result.hits()) {
log.info("****** score := " + hit.score() + " e conteúdo := "+ bucket.get(hit.id()).content().get("title"));
}
}
O código acima está pesquisando no campo "summary" dos documentos no bucket usando o matchPhrase(searchText) método.
O código é chamado por uma simples chamada:
findByTextMatch("developer");
Portanto, a pesquisa de texto completo deve retornar todos os documentos no intervalo de conferências que tenham o texto "developer" no campo de resumo. Aqui está o resultado:
Conferência de balde aberto
****** total hits := 1
****** score := 0.036940739161339185 e conteúdo := Devoxx UK
O total de acertos representa o número total de correspondências encontradas. Aqui é 1 e a pontuação correspondente dessa correspondência também pode ser encontrada. O código não imprime o documento inteiro, apenas o título da conferência. Você pode imprimir os outros atributos do documento, se desejar.
Há outras maneiras de usar o SearchQuery que serão discutidas a seguir.
Pesquisa de texto difuso
Você pode realizar uma consulta difusa especificando um valor máximo de Distância de Levenshtein como o máximo de fuzziness() a ser permitido no termo. A imprecisão padrão é 2.
Por exemplo, digamos que eu queira encontrar a conferência em que "sysops" seja um dos "tópicos". No conjunto de dados acima, você pode ver que não há nenhum tópico "sysops" presente em nenhuma das conferências. A correspondência mais próxima é "devops"; no entanto, essa distância é de 3 Levenshtein. Portanto, se eu executar o código a seguir com a imprecisão 1 ou 2, ele não deverá apresentar nenhum resultado, o que não acontece.
SearchQueryResult resultFuzzy = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, SearchQuery.match(searchText).fuzziness(2)).fields("topics"));
log.info("****** total hits := "+ resultFuzzy.hits().size());
para (SearchQueryRow hit : resultFuzzy.hits()) {
log.info("****** score := " + hit.score() + " e conteúdo := "+ bucket.get(hit.id()).content().get("topics"));
}
findByTextFuzzy("sysops"); fornece o seguinte resultado:
total de acertos := 0
Agora, se eu alterar a imprecisão para "3" e invocar o mesmo código novamente, recebo um documento de volta. Aqui vai:
****** total hits := 1
****** score := 0.016616112953992054 and content := ["containers","devops", "microsserviços", "desenvolvimento de produtos", "virtualização"]
Como "devops" corresponde a "sysops" com uma imprecisão de 3, a pesquisa é capaz de encontrar o documento.
Consulta de expressão regular
Você pode fazer consultas baseadas em expressões regulares usando o SearchQuery. O código a seguir faz uso da função RegExpQuery para pesquisar "tópicos" com base em um padrão fornecido.
RegexpQuery rq = new RegexpQuery(regexp).field("topics");
SearchQueryResult resultRegExp = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, rq));
log.info("****** total hits := "+ resultRegExp.hits().size());
para (SearchQueryRow hit : resultRegExp.hits()) {
log.info("****** score := " + hit.score() + " e conteúdo := "+ bucket.get(hit.id()).content().get("topics"));
}
Quando invocado como
findByRegExp("[a-z]*\\s*reality");
Ele retorna os dois documentos a seguir:
****** total de acertos := 2
****** score := 0.11597946228887497 and content := ["aws", "serverless", "microservices", "cloud computing","realidade aumentada“]
****** score := 0.1084888528694293 and content := ["cloud", "iot", "big data", "machine learning","realidade virtual“]
Consulta por prefixo
O Couchbase permite que você faça consultas com base em um "prefixo" de um elemento de texto. A API pesquisa os textos que começam com o prefixo especificado. O código é simples de usar; ele pesquisa no campo "summary" do documento os textos que têm o prefixo fornecido.
PrefixQuery pq = new PrefixQuery(prefix).field("summary");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, pq).fields("summary"));
log.info("****** total hits := "+ resultPrefix.hits().size());
para (SearchQueryRow hit : resultPrefix.hits()) {
log.info("****** score := " + hit.score() + " e conteúdo := "+ bucket.get(hit.id()).content().get("summary"));
}
Se você invocar o código como findByPrefix("micro");
Você obtém o seguinte resultado:
****** total hits := 1
****** score := 0.08200986407165835 and content := Aamazon web services reInvent 2017 promete um local maior, mais sessões e um foco em tecnologias como microsserviços e Lambda.
Consulta por frase
O código a seguir permite que você consulte uma frase em um texto.
MatchPhraseQuery mpq = novo MatchPhraseQuery(matchPhrase).field("speakers.talk");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mpq).fields("speakers.talk"));
log.info("****** total hits := "+ resultPrefix.hits().size());
para (SearchQueryRow hit : resultPrefix.hits()) {
log.info("****** score := " + hit.score() + " and content := "+ bucket.get(hit.id()).content().get("title") + " speakers = "+bucket.get(hit.id()).content().get("speakers"));
}
Aqui, a consulta está procurando uma frase no campo "speakers.talk" e retorna a correspondência, se encontrada.
Um exemplo de invocação do código acima com
findByMatchPhrase("Docker with couchbase") fornece o seguinte resultado esperado:
****** total hits := 1
****** score := 0.25054427342401087 and content := DockerCon speakers = [{"duration": "2″, "date": "04/18/2017″, "talk":"Docker com couchbase", "name": "Arun Gupta"},{"duration": "2″, "date": "04/19/2017″, "talk": "Opensource", "name": "Laura Frank"}]
Consulta de intervalo
A pesquisa de texto completo também é bastante útil quando se trata de pesquisa baseada em intervalo, seja um intervalo numérico ou até mesmo um intervalo de datas. Por exemplo, se você quiser descobrir a(s) conferência(s) em que o número de participantes está dentro de um intervalo, poderá fazer isso facilmente,
findByNumberRange(5000, 30000);
Aqui, o primeiro argumento é o mínimo do intervalo e o segundo argumento é o máximo do intervalo.
Aqui está o código que é acionado:
NumericRangeQuery nrq = new NumericRangeQuery().min(min).max(max).field("attendees");
SearchQueryResult resultPrefix = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, nrq).fields("title", "attendees", "location"));
log.info("****** total hits := "+ resultPrefix.hits().size());
para (SearchQueryRow hit : resultPrefix.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** score := " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " location := " + row.content().get("location"));
}
O resultado é o seguinte: as conferências que têm participantes entre o intervalo fornecido são retornadas.
****** total de acertos := 2
****** score := 5.513997563179222E-5 and title := Participantes da DockerCon := 20000 local := Austin
****** score := 5.513997563179222E-5 and title := Participantes da Devoxx UK := 10000 localização := Bélgica
Consulta de combinação
O serviço de pesquisa de texto completo do Couchbase permite que você use uma combinação de consultas de acordo com sua necessidade. Para demonstrar isso, vamos primeiro invocar a API fornecendo dois argumentos.
findByMatchCombination("aws", "containers");
Aqui, o código do cliente está tentando usar a pesquisa combinada com base em "aws" e "containers". Vamos dar uma olhada na API de consulta agora.
MatchQuery mq1 = new MatchQuery(text1).field("topics");
MatchQuery mq2 = new MatchQuery(text2).field("topics");
SearchQueryResult match1Result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mq1).fields("title", "attendees", "location", "topics"));
log.info("****** total de ocorrências para match1 := "+ match1Result.hits().size());
para (SearchQueryRow hit : match1Result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** scores for match 1 := " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
SearchQueryResult match2Result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, mq2).fields("title", "attendees", "location", "topics"));
log.info("****** total de ocorrências para match2 := "+ match2Result.hits().size());
para (SearchQueryRow hit : match2Result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** scores for match 2:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
ConjunctionQuery conjunction = new ConjunctionQuery(mq1, mq2);
SearchQueryResult result = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, conjunction).fields("title", "attendees", "location", "topics"));
log.info("****** total de ocorrências para a consulta de conjunção := "+ result.hits().size());
para (SearchQueryRow hit : result.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** scores for conjunction query:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
DisjunctionQuery dis = new DisjunctionQuery(mq1, mq2);
SearchQueryResult resultDis = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, dis).fields("title", "attendees", "location", "topics"));
log.info("****** total de ocorrências para a consulta de disjunção := "+ resultDis.hits().size());
para (SearchQueryRow hit : resultDis.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** scores for disjunction query:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
BooleanQuery bool = new BooleanQuery().must(mq1).mustNot(mq2);
SearchQueryResult resultBool = getBucket().query(new SearchQuery(FtsConstants.FTS_IDX_CONF, bool).fields("title", "attendees", "location", "topics"));
log.info("****** total de ocorrências para a consulta booelan := "+ resultBool.hits().size());
para (SearchQueryRow hit : resultBool.hits()) {
JsonDocument row = bucket.get(hit.id());
log.info("****** scores for resultBool query:= " + hit.score() + " and title := "+ row.content().get("title") + " attendees := "+ row.content().get("attendees") + " topics := " + row.content().get("topics"));
}
Primeiro, as correspondências individuais são encontradas com base nos textos. Encontramos os documentos do conjunto de resultados que correspondem a "aws" como um dos tópicos da conferência. Da mesma forma, encontramos os documentos que têm "containers" como tópicos.
Em seguida, começamos a combinar os resultados individuais para formar consultas combinadas.
Consulta de conjunção
A consulta de conjunção retornaria todas as conferências correspondentes que têm "aws" e "containers" listados como tópicos. Nosso conjunto de dados atual ainda não tem uma conferência desse tipo; portanto, como esperado, quando executamos a consulta, não recebemos nenhum documento correspondente.
****** total de ocorrências para match1 := 1 - isso corresponde a "aws"
****** pontuações para a correspondência 1 := 0,11597946228887497 e título := ReInvent participantes := 30000 tópicos := ["aws", "serverless", "microservices", "cloud computing", "augmented reality"]
****** total de ocorrências para match2 := 1 - isso corresponde a "containers"
****** scores for match 2:= 0.12527214351929328 and title := DockerCon attendees := 20000 topics := ["containers", "devops", "microservices", "product development", "virtualization"]
****** total de ocorrências para a consulta de conjunção := 0
Consulta de disjunção
A consulta de disjunção retornaria todas as conferências correspondentes se qualquer uma das consultas candidatas retornasse uma correspondência. Como cada uma das consultas de correspondência individual retorna uma conferência cada, quando executamos nossa consulta de disjunção, obtemos ambos os resultados.
****** total de ocorrências para a consulta de disjunção := 2
****** pontuações para consulta de disjunção:= 0,018374455634478874 e título := DockerCon participantes := 20000 tópicos := ["contêineres", "devops", "microsserviços", "desenvolvimento de produtos", "virtualização"]
****** pontuações para consulta de disjunção:= 0,01701143945069833 e título := ReInvent participantes := 30000 tópicos := ["aws", "sem servidor", "microsserviços", "computação em nuvem", "realidade aumentada"]
Consulta booleana
Usando a consulta bBoolean, podemos combinar diferentes combinações de consultas de correspondência. Por exemplo, BooleanQuery bool = new BooleanQuery().must(mq1).mustNot(mq2) retorna todas as conferências que devem corresponder ao resultado da consulta do primeiro termo, que é mq1, e, ao mesmo tempo, não devem corresponder a mq2. Você pode inverter a combinação.
O resultado do nosso código é o seguinte:
****** total de ocorrências para a consulta booelan := 1
****** pontuações para resultBool query:= 0.11597946228887497 e title := ReInvent attendees := 30000 topics := ["aws", "sem servidor", "microsserviços", "computação em nuvem", "realidade aumentada"]
Ele retorna a conferência que tem um tópico chamado "aws" (que, a propósito, é o mesmo que mq1) e não tem um tópico chamado "containers" (ou seja, mq2). A única conferência que atende a essas duas condições é a intitulada "ReInvent", que é retornada como saída.
Espero que a postagem tenha sido útil para você. O código-fonte pode ser encontrado on-line. Para obter uma ideia geral sobre o serviço de pesquisa de texto completo do Couchbase, consulte o seguinte postagem no blog para obter algumas percepções úteis: