O Couchbase se tornou uma opção popular para Casos de uso de IoTgraças à sua flexibilidade modelo múltiplo recursos de gerenciamento de dados.
Recentemente, trabalhei com um cliente do setor de cruzeiros que tinha um desafio único: ele precisava que o Couchbase recebesse e armazenasse atualizações frequentes de muitos sensores que registram leituras em sua frota de navios. Essas leituras poderiam chegar ao Couchbase fora da ordem cronológica. Como eles poderiam garantir que uma nova leitura do sensor só poderia ser armazenada se tivesse um registro de data e hora posterior à leitura anterior?
Cada sensor tem uma chave exclusiva que corresponde à leitura mais recente do sensor. Uma leitura de 10:43:00 AM não poderia sobrescrever uma leitura de 10:42:30 AM, mesmo que essa última tivesse sido recebida mais tarde. Abaixo estão alguns exemplos de leituras e sua ordem de processamento (observe que os registros de data e hora não estão necessariamente em ordem cronológica):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
id: "C-DI_Nautical_Speed" { "speed": 15, "unit": "knots", "timeStamp": "2023-03-10 10:43:00 AM" } id: "C-DI_Nautical_Speed" { "speed": 15.1, "unit": "knots", "timeStamp": "2023-03-10 11:43:00 AM" }, id: "C-DI_Nautical_Speed" { "speed": 14.9, "unit": "knots", "timeStamp": "2023-03-10 10:42:30 AM" } |
Nesta postagem do blog, exploraremos como as opções de vários modelos do Couchbase podem ajudar a lidar com esse cenário e gerenciar com eficiência as atualizações de dados de sensores.
O que é Multi-Model?
O Couchbase talvez seja o banco de dados multimodelo original, pois combina o armazenamento em cache que prioriza a memória com a persistência de dados JSON para oferecer uma abordagem flexível ao gerenciamento de dados. O Couchbase pode lidar com vários tipos de dados, como dados estruturados, semiestruturados e não estruturados, na mesma instância de banco de dados.
Com o tempo, o Couchbase adicionou SQL++, Pesquisa de texto completo (FTS), Eventos, Análises ferramentas: vários modelos para acessar, indexar e interagir com o mesmo pool de dados. Essa abordagem de vários modelos pode tornar o Couchbase mais flexível do que os bancos de dados tradicionais, mas também pode exigir um pouco mais de reflexão sobre as compensações em comparação com os sistemas legados (que podem ter apenas uma maneira de interagir com os dados).
Opções de vários modelos para atualização das leituras do sensor
Quando se trata de atualizar as leituras do sensor para esse caso de uso no banco de dados multimodelo do Couchbase, há várias abordagens a serem consideradas:
-
- API de valor-chave com bloqueio otimista ou pessimista
- API de valor-chave com transação ACID
- Instrução SQL++ UPDATE
- Função OnUpdate de eventos
Todas essas opções têm seu próprio conjunto de vantagens e compensações em termos de desempenho, complexidade e requisitos. A escolha da melhor abordagem dependerá de fatores como o tamanho e a frequência das atualizações, o nível de simultaneidade e os requisitos gerais de desempenho.
Em última análise, a melhor abordagem só pode ser determinada por meio de testes no mundo real com dados em tempo real ou uma boa aproximação dos dados em tempo real. Ao examinar as vantagens e desvantagens e experimentar as diferentes opções, os desenvolvedores podem identificar o método mais eficaz para atualizar as leituras do sensor no banco de dados multimodelo do Couchbase.
É importante observar que, em muitos desses cenários, presumimos que o documento do sensor já existe (que será o cenário mais comum em um estado estável). Quando esse não for o caso, podemos alterar o substituir ou atualização operação para upsert para garantir que o documento seja criado se ele não existir. (Como alternativa, você poderia "semear" a coleção com um documento para cada sensor).
Dito isso, vamos examinar cada possibilidade.
API de valor-chave com bloqueio otimista ou pessimista
Uma abordagem para atualizar as leituras do sensor no banco de dados multimodelo do Couchbase é por meio do bloqueio otimista ou pessimista. Esse mecanismo de bloqueio, que está presente no Couchbase há muito tempo, usa uma técnica chamada CAS (comparar e trocar) para garantir atualizações condicionais de documentos individuais.
O valor CAS é um número arbitrário que muda sempre que um documento é alterado. Ao fazer a correspondência dos valores CAS, os desenvolvedores podem atualizar condicionalmente os dados do sensor com o mínimo de sobrecarga. Nesta seção, exploraremos como o bloqueio otimista e pessimista pode ser usado para esse caso de uso de dados do sensor.
Bloqueio otimista
O bloqueio otimista é uma abordagem simples para atualizar os dados do sensor no Couchbase, com apenas três etapas necessárias:
O primeira etapa envolve a recuperação do documento por chave, que inclui o valor do documento e seus metadados (incluindo o valor CAS).
Uma vez recuperado, o segunda etapa é verificar se o carimbo de data/hora é mais antigo do que o carimbo de data/hora de entrada.
Se for o caso, o terceira etapa envolve a substituição do documento pelo novo valor e o envio do valor CAS com ele.
É aqui que entra a parte "otimista". Se os valores CAS corresponderem, a operação será bem-sucedida e os dados do sensor serão atualizados. Entretanto, se o valor CAS não corresponder, isso significa que os dados do sensor foram atualizados (por algum outro thread/processo) desde a última operação de leitura. Nesse caso, você tem a opção de tentar novamente a operação desde o início. Se você não espera que o documento específico do sensor seja atualizado com frequência, então o bloqueio otimista é a melhor opção (já que as tentativas de atualização não seriam frequentes).
Aqui está um exemplo de bloqueio otimista com lógica de repetição simples:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
// get existing sensor reading var currentDoc = await _collection.GetAsync(sensorId); var currentDocCas = currentDoc.Cas; var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine("Incoming sensor reading is newer. Updating."); var retries = 3; while (retries > 0) { try { await _collection.ReplaceAsync(sensorId, newSensorReading, options => options.Cas(currentDocCas)); return; } catch (CasMismatchException) { Console.WriteLine($"CAS mismatch. Retries remaining: {retries}"); retries--; } } Console.WriteLine("Retry max exceeded. Sensor reading was not updated."); } else { Console.WriteLine("Incoming sensor reading is not new. Ignoring."); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } |
Bloqueio pessimista
Bloqueio pessimista é outra maneira de abordar o mesmo problema. Assim como o bloqueio otimista, ele tem três etapas, mas com algumas pequenas diferenças.
O primeira etapa é obter e bloquear um documento por chave, anotando o valor CAS. Ao contrário do bloqueio otimista, em que o documento é simplesmente lido, no bloqueio pessimista, o documento é explicitamente bloqueado. Isso significa que nenhum outro processo pode fazer alterações no documento até que ele seja desbloqueado.
No segunda etapaAssim como no bloqueio otimista, o carimbo de data/hora é verificado para ver se é mais antigo do que o carimbo de data/hora de entrada.
Se for, então no terceira etapao documento é substituído pelo novo valor e enviado com o valor CAS.
Na etapa 1 do bloqueio pessimista, você também precisa especificar uma janela de tempo limite. Por quê? É possível que a etapa 3 nunca aconteça devido a um erro ou falha, e o documento precisa ser eventualmente desbloqueado.
Se você espera que o documento do sensor seja atualizado com frequência, o pessimista pode ser a melhor abordagem. Mas, devido ao bloqueio, pode haver uma latência reduzida em outros processos que aguardam o desbloqueio do documento.
Para ilustrar, aqui está um exemplo de bloqueio pessimista em ação:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// get current sensor data var maxLockTime = TimeSpan.FromSeconds(30); var currentDoc = await _collection.GetAndLockAsync(sensorId, maxLockTime); var currentDocCas = currentDoc.Cas; var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps against new reading if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine("Incoming sensor reading is newer. Updating."); await _collection.ReplaceAsync(sensorId, newSensorReading, options => options.Cas(currentDocCas)); return; } else { await _collection.UnlockAsync(sensorId, currentDocCas); Console.WriteLine("Incoming sensor reading is not new. Ignoring."); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } |
Compensações de bloqueio de CAS
Quando se trata de bloqueio de CAS, há compensações a serem consideradas. O bloqueio otimista funciona bem quando os conflitos não são frequentes, mas você precisará implementar uma lógica de nova tentativa apropriada para lidar com possíveis novas tentativas.
Para ajudar nessa troca, poderiam ser usadas tentativas mais avançadas ou especializadas. Por exemplo, nesse caso de uso, pode ser aceitável "desistir" e descartar uma leitura de sensor recebida se houver muitas tentativas e/ou se a leitura for muito antiga.
O bloqueio pessimista, por outro lado, é uma abordagem "mais segura", mas requer uma compreensão clara das implicações de desempenho do bloqueio. O bloqueio pode aumentar a latência em outros processos que precisam esperar que o documento seja desbloqueado.
Transação ACID
Outra possível solução para o problema de atualização do sensor é usar uma transação ACID. Essa abordagem pode ser um exagero para atualizar um único documento nesse caso de uso, mas pode ser útil em diferentes casos de uso em que vários documentos precisam ser atualizados atomicamente.
Um desafio com os dados do sensor é que eles podem estar chegando em um ritmo acelerado. No intervalo de tempo entre a verificação dos dados atuais e a atualização com os dados de sensores recebidos, outra leitura pode estar chegando. Para evitar esse problema, uma transação ACID pode ser usada para atualizar os dados condicionalmente.
O código de exemplo abaixo demonstra como usar uma transação ACID para atualizar um documento de sensor. A transação garante que apenas uma operação de atualização possa ocorrer por vez por sensor, evitando que várias leituras de sensores de entrada interfiram umas nas outras.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var transaction = Transactions.Create(_cluster, TransactionConfigBuilder.Create() .DurabilityLevel(DurabilityLevel.None)); // set to 'none' because I'm using a single-node dev cluster // for more details see: https://docs.couchbase.com/dotnet-sdk/current/howtos/distributed-acid-transactions-from-the-sdk.html await transaction.RunAsync(async (context) => { // get existing sensor reading var currentDoc = await context.GetAsync(_collection, sensorId); var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine("Incoming sensor reading is newer. Updating."); await context.ReplaceAsync(currentDoc, newSensorReading); } else { Console.WriteLine("Incoming sensor reading is not new. Ignoring."); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } }); |
Compensações de transações ACID
A API de valor-chave deve ser usada sempre que possível para maximizar o desempenho. No entanto, o uso de uma transação ACID distribuída no Couchbase terá alguma sobrecarga devido às operações adicionais de valor-chave executadas (nos bastidores) para coordenar a transação. Como os dados no Couchbase são automaticamente distribuídos, as operações provavelmente serão coordenadas em uma rede para vários servidores.
Uma vantagem de usar uma transação ACID em vez de uma operação CAS é que as bibliotecas de transações do Couchbase já têm uma lógica de repetição sofisticada incorporada. Essa pode ser uma maneira de evitar escrever sua própria lógica de nova tentativa. Além disso, uma transação ACID é recomendada (provavelmente necessária, na verdade) se um caso de uso envolver a atualização de vários documentos de sensores.
Operação de atualização do SQL++
Outra abordagem para realizar atualizações condicionais é usar uma consulta SQL++ UPDATE.
Aqui está um exemplo de implementação:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var retries = 3; while (retries > 0) { try { await _cluster.QueryAsync<dynamic>(@"UPDATE sensordata s USE KEYS $sensorId SET s.speed = $newSpeed, s.unit = $newUnit, s.timeStamp = $newTimeStamp WHERE DATE_DIFF_STR($newTimeStamp, s.timeStamp, 'millisecond') > 0", options => { options.Parameter("sensorId", sensorId); options.Parameter("newSpeed", sensorReading.Speed); options.Parameter("newUnit", sensorReading.Unit); options.Parameter("newTimeStamp", sensorReading.TimeStamp); }); return; } c atch (CasMismatchException) { Console.WriteLine($"UPDATE CAS mismatch, tries remaining: {retries}"); retries--; } } Console.WriteLine("Max retries exceeded, sensor not updated"); |
(A propósito, o uso de um carimbo de data/hora de época provavelmente proporcionará melhor desempenho).
Como você deve ter adivinhado pelo código, a consulta SQL++ está, na verdade, usando o CAS nos bastidores, assim como está sendo feito com o exemplo da API KV anteriormente.
Compensações do SQL++
A abordagem do SQL++ para atualizações condicionais tem algumas desvantagens. Embora o USAR CHAVES ajuda a eliminar a necessidade de um índice, a consulta ainda precisa ser analisada pelo serviço de consulta, que envolve muitas etapas. Isso pode aumentar a pressão sobre o sistema se outros componentes já estiverem usando o serviço de consulta.
De modo geral, como a abordagem do SQL++ é muito semelhante à API KV, com a sobrecarga adicional de analisar a consulta, talvez não seja a melhor opção, a menos que você tenha uma necessidade específica de lógica complexa expressa em SQL++ ou se o uso da API KV não for uma opção.
Eventos
A última abordagem que quero abordar é o uso do Eventing.
A criação de eventos no Couchbase consiste em escrever funções JavaScript que respondem a eventos de alteração de dados de forma assíncrona e implantá-las no cluster do Couchbase.
Para esse caso de uso específico, acho que usar uma coleção de "preparação" como um local para as leituras do sensor inicialmente é o caminho a seguir. Esta é a sequência:
-
- As leituras do sensor que chegam são gravadas em uma coleção de "preparação".
- Um evento Sobre a atualização responde às novas leituras do sensor.
- O Sobre a atualização A função verifica os registros de data e hora em relação ao documento correspondente na coleção "current"
- Se o registro de data e hora for mais atual, o documento na coleção "current" será atualizado.
Sobre a atualização será executado quando um documento for criado ou atualizado, portanto, não há problema em deixar o documento antigo em staging (isso simplifica o código de eventos). Além disso, um TTL pode ser definido na coleção, de modo que, se uma leitura de sensor não for atualizada em um determinado período, ela será automaticamente limpa.
Aqui está um exemplo de uma função de evento que funciona com esse design:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
function OnUpdate(doc, meta) { // Only process documents with a "timestamp" if (doc.timestamp) { // Extract timestamp and sensor ID from the staged document var stagedTimestamp = doc.timestamp; // note that this will loop indefinitely // but you can also limit it to a certain number of reties if you wish while(true) { // Get the current document for the same sensor ID from the "destination" collection var currentDoc = dst_col[meta.id]; // If there is no current document, or the staged timestamp is later than the current timestamp, update the current document if (!currentDoc || stagedTimestamp > currentDoc.timestamp) { // dst_col is a READ+WRITE ALIAS dst_col[meta.id] = doc; // the whole document is overwritten, but you can also choose to override certain fields if you wish } // src_col is a READ ALIAS var result = couchbase.get(src_col, meta); if (result.success) { if (result.meta.cas == meta.cas) { // the document was unchanged in the stage collection we are done break; } doc = result.doc; stagedTimestamp = doc.timestamp; } else { if (result.error.key_not_found) { // this might be okay, assuming 'staging' collection gets cleaned up or has a TTL // again, this will depend on what kind of retry logic you have break; } else { log('failure could not read stage adv. get: id',meta.id,'result',result); } } } } } |
E aqui está a configuração para essa função de eventos:
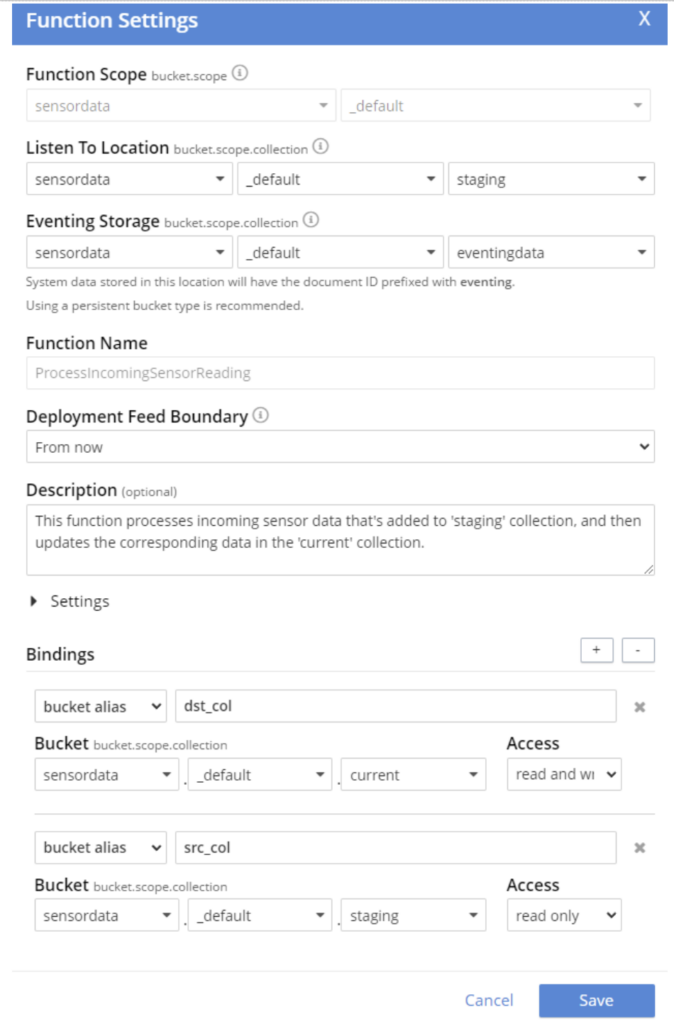
Compensações de eventos
Novamente, observe que um bloqueio CAS otimista está sendo usado nesse código. De fato, quase se poderia dizer que essa é uma versão JavaScript do código que usa a API KV anteriormente.
Uma diferença importante é que essa função está sendo executada no próprio cluster do Couchbase. E esse é o principal benefício da geração de eventos: não importa de onde os dados do sensor estejam vindo, a função Eventing do Couchbase garantirá que eles sejam processados. Isso mantém a lógica próxima aos dados. Se você tiver dois ou mais clientes que usam a API KV, isso significa que você precisa de duas ou mais implementações do mesmo código. Isso pode gerar problemas quando a lógica for alterada, pois ela precisará ser atualizada em vários locais.
No entanto, assim como no SQL++, o Eventing envolve algumas despesas gerais. Nesse caso, várias coleções e o próprio serviço de eventos. Normalmente, isso poderia envolver um nó adicional do Couchbase na produção. Além disso, o Eventing não está disponível atualmente no Couchbase Server Community.
Resumo
O Couchbase é um banco de dados multimodelo que oferece opções e compensações para seu caso de uso. Nesta postagem, o caso de uso de atualizações de dados de sensores foi abordado com quatro padrões diferentes de acesso a dados, cada um com seus prós e contras:
-
- API KV - de alto desempenho, simples, mas pode exigir alguma lógica de repetição
- Transações ACID - confiáveis, mas com sobrecarga
- SQL++ - familiar, declarativo, mas tem análise de consulta e sobrecarga de execução
- Eventos - próximo aos dados, consolida a lógica, mas tem a sobrecarga do serviço de eventos e coleções extras
Todos os exemplos de código são disponível no GitHub.
Você já pensou em uma abordagem diferente? Deixe um comentário abaixo ou compartilhe-o na seção Discórdia do Couchbase.