Couchbase N1QL é um mecanismo moderno de processamento de consultas projetado para fornecer SQL agregado para JSON por índice em dados distribuídos com um modelo de dados flexível. Os bancos de dados modernos são implantados em clusters enormes. O uso do JSON oferece um modo de dados flexível. O N1QL oferece suporte a SQL aprimorado de grupo por índice para JSON para facilitar o processamento de consultas.
Os aplicativos e drivers de banco de dados enviam a consulta N1QL a um dos nós de consulta disponíveis em um cluster. O nó de consulta analisa a consulta e usa metadados em objetos subjacentes para descobrir o plano de execução ideal, que é então executado. Durante a execução, dependendo da consulta, usando os índices aplicáveis, o nó de consulta trabalha com os nós de índice e de dados para recuperar dados e realizar as operações planejadas. Como o Couchbase é um banco de dados modular em cluster, você dimensiona os serviços de dados, índice e consulta para atender às suas metas de desempenho e disponibilidade.
Antes do Couchbase 5.5, mesmo quando uma consulta com GROUP BY e/ou agregados era coberta por um índice, a consulta buscava todos os dados relevantes do indexador e executava o agrupamento/agregação dos dados no mecanismo de consulta.
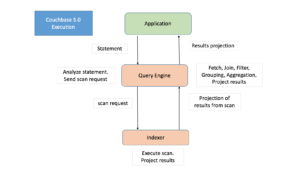
No Couchbase 5.5, o planejador de consultas foi aprimorado para solicitar de forma inteligente que o indexador execute o agrupamento e a agregação, além da varredura de intervalo para o índice de cobertura. O Indexador foi aprimorado para executar agrupamento, COUNT(), SUM(), MIN(), MAX(), AVG() e operações relacionadas em tempo real.
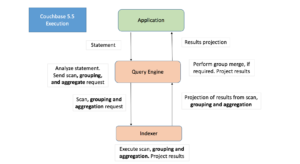
Isso não requer alterações na consulta do usuário, mas é necessário um bom projeto de índice para cobrir a consulta e ordenar as chaves do índice. Nem toda consulta se beneficiará dessa otimização, e nem todo índice pode acelerar todas as operações de agrupamento e agregação. A compreensão dos padrões corretos o ajudará a projetar seus índices e consultas. O agrupamento e a agregação de índices no índice secundário global são compatíveis com os dois mecanismos de armazenamento: GSI padrão e GSI otimizado para memória (MOI). O agrupamento e a agregação de índices são compatíveis somente com a Enterprise Edition.
Essa etapa de redução da execução de GROUP BY e Aggregation pelo indexador reduz a quantidade de transferência de dados e E/S de disco, resultando em:
- Melhoria no tempo de resposta da consulta
- Melhor utilização dos recursos
- Baixa latência
- Alta escalabilidade
- Baixo custo total de propriedade
Desempenho
O agrupamento e as agregações de índices podem melhorar o desempenho da consulta em ordens de magnitude e reduzir drasticamente as latências. A tabela a seguir lista alguns exemplos de medições de latência de consulta.
Índice :
|
1 |
CREATE INDEX idx_ts_type_country_city ON `travel-sample` (type, country, city); |
| Consulta | Descrição | 5.0 Latências | 5.5 Latências |
SELECT t.type, COUNT(type) AS cnt DE amostra de viagem AS t WHERE t.type IS NOT NULL GROUP BY t.type; |
|
230ms | 13ms |
SELECT t.type, COUNT(1) AS cnt, COUNT(DISTINCT city) AS cntdcity DE amostra de viagem AS t WHERE t.type IN ["hotel", "airport"] GROUP BY t.type, t.country; |
|
40ms | 7ms |
SELECT t.country, COUNT(city) AS cnt DE amostra de viagem AS t ONDE t.type = "airport" (aeroporto) GROUP BY t.country; |
|
25ms | 3ms |
SELECT t.city, cnt DE amostra de viagem AS t WHERE t.type IS NOT NULL GROUP BY t.city LETTING cnt = COUNT(city) HAVING cnt > 0 ; |
|
300ms | 160ms |
Visão geral do agrupamento e da agregação de índices
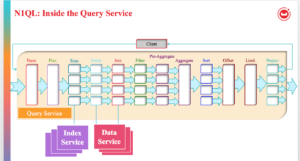
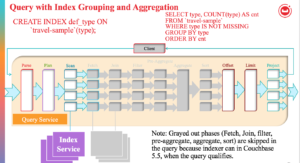
A figura acima mostra todas as fases possíveis pelas quais uma consulta SELECT passa para retornar os resultados. O processo de filtragem usa o espaço-chave inicial e produz um subconjunto ideal dos documentos nos quais a consulta está interessada. Para produzir o menor subconjunto possível, os índices são usados para aplicar o maior número possível de predicados. O predicado da consulta indica o subconjunto de dados de interesse. Durante a fase de planejamento da consulta, selecionamos os índices a serem usados. Em seguida, para cada índice, decidimos os predicados a serem aplicados por cada índice. Os predicados da consulta são traduzidos em varreduras de intervalo no plano de consulta e passados para o Indexador.
Se a consulta não tiver JOINs e for coberta pelo índice, as fases Fetch e Join poderão ser eliminadas.
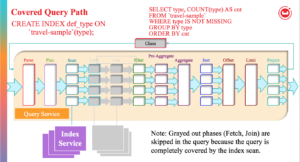
Quando todos os predicados são traduzidos exatamente para varreduras de intervalo, a fase de filtro também pode ser eliminada. Nessa situação, a varredura e os agregados estão lado a lado e, como o indexador tem a capacidade de fazer agregação, essa fase pode ser feita no nó do indexador. Em alguns casos, as fases Sort, Offset e Limit também podem ser feitas no nó do indexador.
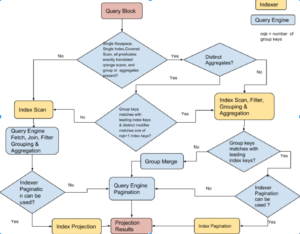
O fluxograma a seguir descreve como o planejador de consultas decide executar a agregação de índices para cada bloco de consulta da consulta. Se a agregação do índice não for possível, as agregações serão feitas no mecanismo de consulta.
Por exemplo, vamos comparar o desempenho anterior e o atual do uso do GROUP BY e examinar o plano EXPLAIN da seguinte consulta que usa um índice definido no Couchbase amostra de viagem balde:
|
1 |
CREATE INDEX `def_type` ON `travel-sample`(`type`); |
Considere a consulta:
|
1 2 3 4 |
SELECT type, COUNT(type) FROM `travel-sample` WHERE type IS NOT MISSING GROUP BY type; |
Antes da versão 5.5 do Couchbase, esse mecanismo de consulta buscava dados relevantes do indexador, e o agrupamento e a agregação dos dados eram feitos no mecanismo de consulta. Essa consulta simples leva cerca de 250 ms.

Agora, na versão 5.5 do Couchbase, essa consulta usa o mesmo índice def_type, mas é executada em menos de 20 ms. Na explicação abaixo, você pode ver menos etapas e a ausência da etapa de agrupamento após a varredura do índice, porque a etapa de varredura do índice também faz o agrupamento e a agregação.

À medida que a complexidade dos dados e das consultas aumenta, o benefício do desempenho (latência e taxa de transferência) também aumenta.
Entendendo o EXPLAIN de agrupamento e agregação de índices
Observando a explicação da consulta:
|
1 |
EXPLAIN SELECT type, COUNT(type) FROM `travel-sample` WHERE type IS NOT MISSING GROUP BY type;{ |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((meta(`travel-sample`).`id`))", "cover (count(cover ((`travel-sample`.`type`))))" ], "index": "def_type", "index_group_aggs": { "aggregates": [ { "aggregate": "COUNT", "depends": [ 0 ], "expr": "cover ((`travel-sample`.`type`))", "id": 2, "keypos": 0 } ], "depends": [ 0 ], "group": [ { "depends": [ 0 ], "expr": "cover ((`travel-sample`.`type`))", "id": 0, "keypos": 0 } ] }, "index_id": "b948c92b44c2739f", "index_projection": { "entry_keys": [ 0, 2 ] }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 1, "low": "null" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialProject", "result_terms": [ { "expr": "cover ((`travel-sample`.`type`))" }, { "expr": "cover (count(cover ((`travel-sample`.`type`))))" } ] }, { "#operator": "FinalProject" } ] } } ] }, "text": "SELECT type, COUNT(type) FROM `travel-sample` WHERE type IS NOT MISSING GROUP BY type;" } |
Você verá "index_group_aggs" na seção IndexScan (ou seja, "#operator": "IndexScan3"). Se "index_group_aggs" estiver faltando, o serviço de consulta está executando agrupamento e agregação. Se a consulta presente estiver usando agrupamento e agregação de índices e tiver todas as informações relevantes, o indexador precisará fazer o agrupamento e a agregação. A tabela a seguir descreve como interpretar as várias informações do objeto index_group_aggs.
| Nome do campo | Descrição | Números de linha do exemplo | Explicar o texto em um exemplo |
| agregados | Matriz de objetos Aggregate, e cada objeto representa um agregado. A ausência desse item significa que apenas group by está presente na consulta. | 14-24 | agregados |
| agregado | Operação agregada (MAX/MIN/SUM/COUNT/COUNTN). | 16 | CONTAGEM |
| distinto | O modificador agregado é DISTINCT | - | False(Quando verdadeiro, somente ele aparece) |
| depende | Lista de posições de chave de índice (começando com 0) das quais a expressão agregada depende. | 17-19 | 0 (porque type é a 0ª chave de índice do índice def_type) |
| expr | expressão agregada | 20 | cobertura ((amostra de viagem.tipo)) |
| id | ID exclusivo fornecido internamente e que será usado em index_projection | 21 | 2 |
| teclas | O código para isso indica o uso da expressão na posição da chave de índice ou do campo expr.
|
22 | 0 (porque type é a 0ª chave de índice do índice def_type) |
| depende | Lista de posições-chave de índice das quais as expressões de grupos/agregados dependem (lista consolidada) | 25-27 | 0 |
| grupo | Matriz de objetos GROUP BY, e cada objeto representa uma chave de grupo. A ausência desse item significa que não há cláusula GROUP BY presente na consulta. | 28-37 | grupo |
| depende | Lista de posições de chave de índice (começando com 0) das quais a expressão de grupo depende. | 30-32 | 0
(porque o tipo é a 0ª chave da chave do índice do índice def_type) |
| expr | expressão de grupo. | 33 | cobertura ((amostra de viagem.tipo)) |
| id | ID exclusivo fornecido internamente e que será usado em index_projection. | 34 | 0 |
| teclas | O código para isso indica o uso da expressão na posição da chave de índice ou do campo expr.
|
35 | 0 (porque type é a 0ª chave de índice do índice def_type) |
O campo covers é uma matriz e tem todas as chaves de índice, chave de documento (META().id), expressões de chaves de grupo que não correspondem exatamente às chaves de índice (classificadas por id), agregados classificados por id. Além disso, "Index_projection" terá todos os ids de grupo/agregado.
|
1 2 3 4 5 |
"covers": [ "cover ((`travel-sample`.`type`))", ← Index key (0) "cover ((meta(`travel-sample`).`id`))", ← document key (1) "cover (count(cover ((`travel-sample`.`type`))))" ← aggregate (2) ] |
No caso acima, a expressão de grupo tipo é a mesma chave de índice do índice def_type. Ele não está incluído duas vezes.
Detalhes de Agrupamento e agregação de índices
Usaremos exemplos para mostrar como funcionam o agrupamento e as agregações de índices. Para seguir os exemplos crie um bucket "default" e insira os seguintes documentos:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO default (KEY,VALUE) VALUES ("ga0001", {"c0":1, "c1":10, "c2":100, "c3":1000, "c4":10000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0002", {"c0":1, "c1":20, "c2":200, "c3":2000, "c4":20000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0003", {"c0":1, "c1":10, "c2":300, "c3":3000, "c4":30000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0004", {"c0":1, "c1":20, "c2":400, "c3":4000, "c4":40000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0005", {"c0":2, "c1":10, "c2":100, "c3":5000, "c4":50000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0006", {"c0":2, "c1":20, "c2":200, "c3":6000, "c4":60000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0007", {"c0":2, "c1":10, "c2":300, "c3":7000, "c4":70000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}), VALUES ("ga0008", {"c0":2, "c1":20, "c2":400, "c3":8000, "c4":80000, "a1":[{"id":1}, {"id":1}, {"id":2}, {"id":3}, {"id":4}, {"id":5}]}); |
Exemplo 1: Agrupar por chaves de índice principais
Vamos considerar a consulta e o índice a seguir:
|
1 2 3 4 5 6 7 8 |
SELECT d.c0 AS c0, d.c1 AS c1, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c0, d.c1 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2; |
Índice necessário:
|
1 |
CREATE INDEX idx1 ON default(c0, c1, c2, c3, c4); |
A consulta tem GROUP BY e vários agregados, alguns dos agregados têm o modificador DISTINCT. A consulta pode ser coberta pelo índice idx1 e o predicado (d.c0 > 0) pode ser convertido em uma varredura de intervalo exata e passado para a varredura de índice. Portanto, a combinação de índice e consulta qualifica o agrupamento e as agregações de índice.
Os índices são naturalmente ordenados e agrupados pela ordem da definição da chave do índice. Na consulta acima, as chaves GROUP BY (d.c0, d.c1) correspondem exatamente às chaves principais (c0, c1) do índice. Portanto, o índice tem cada grupo de dados juntos, o indexador produzirá uma linha por grupo, ou seja, agregação completa. Além disso, a consulta tem um agregado que tem o modificador DISTINCT e corresponde exatamente a uma das chaves de índice com posição menor ou igual ao número de chaves de grupo mais um (ou seja, há 2 chaves de grupo, o modificador DISTINCT pode ser qualquer uma das chaves de índice na posição 0,1,2 porque a chave de índice seguida pelas chaves de grupo e o modificador DISTINCT pode ser aplicado sem ordenação). Portanto, a consulta acima é adequada para o indexador lidar com o agrupamento e a agregação.
Se o grupo não tiver uma das principais chaves de índice e houver um predicado de igualdade, será feita uma otimização especial, tratando a chave de índice implicitamente presente nas chaves de grupo e determinando se a agregação completa é possível ou não. Para o índice de partição, todas as chaves de partição precisam estar presentes nas chaves de grupo para gerar agregações completas.
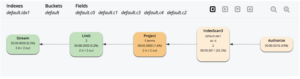
A árvore de execução gráfica acima mostra a varredura de índice (IndexScan3) realizando varreduras e agregações de agrupamento de índices. Os resultados da varredura de índice são projetados.
Vamos dar uma olhada no texto para explicar:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 |
{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "as": "d", "covers": [ "cover ((`d`.`c0`))", "cover ((`d`.`c1`))", "cover ((`d`.`c2`))", "cover ((`d`.`c3`))", "cover ((`d`.`c4`))", "cover ((meta(`d`).`id`))", "cover (count(distinct cover ((`d`.`c2`))))", "cover (countn(cover ((`d`.`c4`))))", "cover (sum(cover ((`d`.`c3`))))", "cover (sum(cover ((`d`.`c4`))))" ], "index": "idx1", "index_group_aggs": { "aggregates": [ { "aggregate": "COUNT", "depends": [ 2 ], "distinct": true, "expr": "cover ((`d`.`c2`))", "id": 6, "keypos": 2 }, { "aggregate": "COUNTN", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 7, "keypos": 4 }, { "aggregate": "SUM", "depends": [ 3 ], "expr": "cover ((`d`.`c3`))", "id": 8, "keypos": 3 }, { "aggregate": "SUM", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 9, "keypos": 4 } ], "depends": [ 0, 1, 2, 3, 4 ], "group": [ { "depends": [ 0 ], "expr": "cover ((`d`.`c0`))", "id": 0, "keypos": 0 }, { "depends": [ 1 ], "expr": "cover ((`d`.`c1`))", "id": 1, "keypos": 1 } ] }, "index_id": "d06df7c5d379cd5", "index_order": [ { "keypos": 0 }, { "keypos": 1 } ], "index_projection": { "entry_keys": [ 0, 1, 6, 7, 8, 9 ] }, "keyspace": "default", "limit": "2", "namespace": "default", "offset": "1", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "0" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "maxParallelism": 1, "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialProject", "result_terms": [ { "as": "c0", "expr": "cover ((`d`.`c0`))" }, { "as": "c1", "expr": "cover ((`d`.`c1`))" }, { "as": "sumc3", "expr": "cover (sum(cover ((`d`.`c3`))))" }, { "as": "avgc4", "expr": "(cover (sum(cover ((`d`.`c4`)))) / cover (countn(cover ((`d`.`c4`)))))" }, { "as": "dcountc2", "expr": "cover (count(distinct cover ((`d`.`c2`))))" } ] }, { "#operator": "FinalProject" } ] } } ] }, { "#operator": "Limit", "expr": "2" } ] }, "text": "SELECT d.c0 AS c0, d.c1 AS c1, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d\nWHERE d.c0 > 0 GROUP BY d.c0, d.c1 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2;" } |
- O "index_group_aggs" (linhas 24-89) na seção IndexScan (ou seja, "#operator": "IndexScan3") mostra a consulta usando agrupamento e agregações de índices.
- Se a consulta usar agrupamento e agregação de índice, os predicados serão convertidos exatamente em varreduras de intervalo e passados para a varredura de índice como parte dos intervalos, portanto, não haverá nenhum operador Filter na explicação.
- Como as chaves de agrupamento por correspondem exatamente às chaves de índice principais, o indexador produzirá agregações completas. Portanto, também eliminamos o agrupamento no serviço de consulta (não há operadores InitialGroup, IntermediateGroup, FinalGroup na explicação).
- O indexador projeta "index_projection" (linhas 99-107), incluindo todas as chaves de grupo e agregados.
- Se a consulta ORDER BY corresponder às chaves de índice principais e GROUP BY estiver nas chaves de índice principais, poderemos usar a ordem de índice. Isso pode ser encontrado em explain (linhas 91-98) e não usará o "#operator": "Order" entre a linha 164-165.
- Como a consulta pode usar a ordem do índice e não há cláusula HAVING na consulta, os valores "offset" e "limit" podem ser passados para o indexador.
- Isso pode ser encontrado na linha 112, 110. O "offset" só pode ser aplicado uma vez que você não verá o "#operator": "Offset" entre as linhas 164-165, mas a reaplicação de "limit" não é possível. Isso pode ser visto na linha 165-168.
- A consulta contém AVG(x) e foi reescrita como SUM(x)/COUNTN(x). O COUNTN(x) só conta quando x é um valor numérico.
Exemplo 2: Agrupar por chaves de índice principais, LETTING, HAVING
Vamos considerar a consulta e o índice a seguir:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT d.c0 AS c0, d.c1 AS c1, sumc3 AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c0, d.c1 LETTING sumc3 = SUM(d.c3) HAVING sumc3 > 0 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2; |
Índice necessário:
|
1 |
CREATE INDEX idx1 ON default(c0, c1, c2, c3, c4); |
A consulta acima é semelhante ao Exemplo 1, mas tem as cláusulas LETTING e HAVING. O indexador não será capaz de lidar com elas e, portanto, as cláusulas LETTING e HAVING são aplicadas no serviço de consulta após o agrupamento e as agregações. Portanto, você vê os operadores Let e Filter após o IndexScan3 na árvore de execução. A cláusula Having é um filtro e elimina ainda mais itens, portanto, "offset" e "limit" não podem ser enviados ao indexador e precisam ser aplicados no serviço de consulta, mas ainda podemos usar a ordem do índice.

Exemplo 3: Agrupar por chaves de índice não principais
Vamos considerar a consulta e o índice a seguir:
|
1 2 3 4 5 6 7 8 |
SELECT d.c1 AS c1, d.c2 AS c2, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(d.c2) AS countc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c1, d.c2 ORDER BY d.c1, d.c2 OFFSET 1 LIMIT 2; |
Índice necessário:
|
1 |
CREATE INDEX idx1 ON default(c0, c1, c2, c3, c4); |
A consulta tem GROUP BY e vários agregados. A consulta pode ser coberta pelo índice idx1 e o predicado (d.c0 > 0) pode ser convertido em uma varredura de intervalo exata e passado para a varredura de índice. Portanto, a combinação de índice e consulta qualifica o agrupamento e as agregações do índice.
Na consulta acima, as chaves GROUP BY (d.c1, d.c2) NÃO correspondem às chaves principais (c0, c1) do índice. Os grupos estão espalhados pelo índice. Portanto, o indexador produzirá várias linhas para cada grupo, ou seja, agregação parcial. No caso da agregação parcial, o serviço de consulta faz a mesclagem de grupos, a consulta não pode usar a ordem do índice nem enviar "offset", "limit" ao indexador. No caso de agregação parcial, se algum agregado tiver o modificador DISTINCT, o agrupamento de índices e a agregação não serão possíveis. A consulta acima é adequada para o indexador lidar com o agrupamento e a agregação.
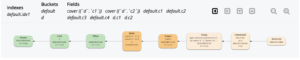
A árvore de execução gráfica acima mostra a varredura de índice (IndexScan3) realizando agregações de varredura e agrupamento de índices. Os resultados da varredura de índice são agrupados novamente e projetados.
Vamos dar uma olhada no texto para explicar:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 |
{ "plan": { "#operator": "Sequence", "~children": [ { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "as": "d", "covers": [ "cover ((`d`.`c0`))", "cover ((`d`.`c1`))", "cover ((`d`.`c2`))", "cover ((`d`.`c3`))", "cover ((`d`.`c4`))", "cover ((meta(`d`).`id`))", "cover (count(cover ((`d`.`c2`))))", "cover (countn(cover ((`d`.`c4`))))", "cover (sum(cover ((`d`.`c3`))))", "cover (sum(cover ((`d`.`c4`))))" ], "index": "idx1", "index_group_aggs": { "aggregates": [ { "aggregate": "COUNT", "depends": [ 2 ], "expr": "cover ((`d`.`c2`))", "id": 6, "keypos": 2 }, { "aggregate": "COUNTN", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 7, "keypos": 4 }, { "aggregate": "SUM", "depends": [ 3 ], "expr": "cover ((`d`.`c3`))", "id": 8, "keypos": 3 }, { "aggregate": "SUM", "depends": [ 4 ], "expr": "cover ((`d`.`c4`))", "id": 9, "keypos": 4 } ], "depends": [ 1, 2, 3, 4 ], "group": [ { "depends": [ 1 ], "expr": "cover ((`d`.`c1`))", "id": 1, "keypos": 1 }, { "depends": [ 2 ], "expr": "cover ((`d`.`c2`))", "id": 2, "keypos": 2 } ], "partial": true }, "index_id": "d06df7c5d379cd5", "index_projection": { "entry_keys": [ 1, 2, 6, 7, 8, 9 ] }, "keyspace": "default", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "0" } ] } ], "using": "gsi" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialGroup", "aggregates": [ "sum(cover (count(cover ((`d`.`c2`)))))", "sum(cover (countn(cover ((`d`.`c4`)))))", "sum(cover (sum(cover ((`d`.`c3`)))))", "sum(cover (sum(cover ((`d`.`c4`)))))" ], "group_keys": [ "cover ((`d`.`c1`))", "cover ((`d`.`c2`))" ] } ] } }, { "#operator": "IntermediateGroup", "aggregates": [ "sum(cover (count(cover ((`d`.`c2`)))))", "sum(cover (countn(cover ((`d`.`c4`)))))", "sum(cover (sum(cover ((`d`.`c3`)))))", "sum(cover (sum(cover ((`d`.`c4`)))))" ], "group_keys": [ "cover ((`d`.`c1`))", "cover ((`d`.`c2`))" ] }, { "#operator": "FinalGroup", "aggregates": [ "sum(cover (count(cover ((`d`.`c2`)))))", "sum(cover (countn(cover ((`d`.`c4`)))))", "sum(cover (sum(cover ((`d`.`c3`)))))", "sum(cover (sum(cover ((`d`.`c4`)))))" ], "group_keys": [ "cover ((`d`.`c1`))", "cover ((`d`.`c2`))" ] }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "InitialProject", "result_terms": [ { "as": "c1", "expr": "cover ((`d`.`c1`))" }, { "as": "c2", "expr": "cover ((`d`.`c2`))" }, { "as": "sumc3", "expr": "sum(cover (sum(cover ((`d`.`c3`)))))" }, { "as": "avgc4", "expr": "(sum(cover (sum(cover ((`d`.`c4`))))) / sum(cover (countn(cover ((`d`.`c4`))))))" }, { "as": "countc2", "expr": "sum(cover (count(cover ((`d`.`c2`)))))" } ] } ] } } ] }, { "#operator": "Order", "limit": "2", "offset": "1", "sort_terms": [ { "expr": "cover ((`d`.`c1`))" }, { "expr": "cover ((`d`.`c2`))" } ] }, { "#operator": "Offset", "expr": "1" }, { "#operator": "Limit", "expr": "2" }, { "#operator": "FinalProject" } ] }, "text": "SELECT d.c1 AS c1, d.c2 AS c2, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(d.c2) AS countc2 FROM default AS d WHERE d.c0 > 0 GROUP BY d.c1, d.c2 ORDER BY d.c1, d.c2 OFFSET 1 LIMIT 2;" } |
- O "index_group_aggs" (linhas 24-88) na seção IndexScan (ou seja, "#operator": "IndexScan3") mostra a consulta usando agrupamento e agregações de índices.
- Se a consulta usar agrupamento e agregação de índice, os predicados serão convertidos exatamente em varreduras de intervalo e passados para a varredura de índice como parte dos intervalos, portanto, não haverá nenhum operador Filter na explicação.
- Como as chaves de grupo por NÃO correspondem às chaves de índice principais, o indexador produzirá agregações parciais. Isso pode ser visto como "partial":true dentro de "index_group_aggs" na linha 87. O serviço de consulta faz a fusão de grupos (consulte a linha 119-161)
- Projetos de indexador "index_projection" (linhas 91-99) contendo chaves de grupo e agregados.
- Se o indexador gerar agregações parciais, a consulta não poderá usar a ordem do índice e exigirá classificação explícita, e "offset" e "limit" não poderão ser enviados ao indexador. O plano terá os operadores explícitos "Order", "Offset" e "Limit" (linha 197 - 217)
- A consulta contém AVG(x) que foi reescrito como SUM(x)/COUNTN(x). O COUNTN(x) só conta quando x é um valor numérico.
- Durante a fusão do grupo
- MIN se torna MIN de MIN
- MAX se torna MAX de MAX
- SUM se torna SUM de SUM
- COUNT se torna SUM de COUNT
- CONTN se torna SUM de COUNTN
- AVG se torna SUM de SUM dividido por SUM de COUNTN
Exemplo 4: Grupo e agregação com índice de matriz
Vamos considerar a consulta e o índice a seguir:
|
1 2 3 4 5 6 7 8 |
SELECT d.c0 AS c0, d.c1 AS c1, SUM(d.c3) AS sumc3, AVG(d.c4) AS avgc4, COUNT(DISTINCT d.c2) AS dcountc2 FROM default AS d WHERE d.c0 > 0 AND d.c1 >= 10 AND ANY v IN d.a1 SATISFIES v.id = 3 END GROUP BY d.c0, d.c1 ORDER BY d.c0, d.c1 OFFSET 1 LIMIT 2; |
Índice necessário:
|
1 |
CREATE INDEX idxad1 ON default(c0, c1, DISTINCT ARRAY v.id FOR v IN a1 END, c2, c3, c4); |
A consulta tem GROUP BY e vários agregados, alguns dos agregados têm o modificador DISTINCT. O predicado da consulta tem a cláusula ANY e a consulta pode ser coberta pelo índice de matriz idxad1. O predicado (d.c0 > 0 AND d,c11 >= 10 AND ANY v IN d.a1 SATISFIES v.id = 3 END ) pode ser convertido em varreduras de intervalo exato e passado para a varredura de índice. Para o índice de matriz, o indexador mantém um elemento separado para cada chave de índice de matriz. Para usar o grupo de índices e a agregação, o predicado SATISFIES deve ter um único predicado de igualdade e a chave de índice de matriz deve ter o modificador DISTINCT. Portanto, a combinação de índice e consulta é adequada para lidar com o agrupamento e a agregação de índices.

Este exemplo é semelhante ao exemplo 1, exceto pelo fato de usar um índice de matriz. A árvore de execução gráfica acima mostra a varredura de índice (IndexScan3) realizando varredura, agregações de agrupamento de índice, ordem, deslocamento e limite. Os resultados da varredura de índice são projetados.
Exemplo 5: Grupo e agregação da operação UNNEST
Vamos considerar a consulta e o índice a seguir:
|
1 2 3 4 5 |
SELECT v.id AS id, d.c0 AS c0, SUM(v.id) AS sumid, AVG(d.c1) AS avgc1 FROM default AS d UNNEST d.a1 AS v WHERE v.id > 0 GROUP BY v.id, d.c0; |
Índice necessário:
|
1 |
CREATE INDEX idxaa1 ON default(ALL ARRAY v.id FOR v IN a1 END, c0, c1); |
A consulta tem GROUP BY e vários agregados. A consulta tem UNNEST no array d.a1 e tem predicado na chave do array (v.id > 0). O índice idxaa1 qualifica a consulta (para que o Unnest use o índice da matriz para a varredura do índice, o índice da matriz deve ser a chave principal e a variável da matriz na definição do índice deve corresponder ao alias UNNEST). O predicado (v.id > 0) pode ser convertido em varreduras de intervalo exato e passado para a varredura de índice. Portanto, a combinação de índice e consulta é adequada para lidar com agrupamentos e agregações de índices.
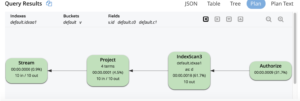
A árvore de execução gráfica acima mostra a varredura de índice (IndexScan3) realizando varreduras e agregações de agrupamento de índices. Os resultados da varredura de índice são projetados. O UNNEST é um tipo especial de JOIN entre o pai e cada elemento da matriz. Portanto, o UNNEST repete os campos do documento pai (d.c0, d.c1) e o d.c0, dc.1 referência teria duplicatas em comparação com o original d documentos (é necessário estar ciente disso ao usar SUM(), AVG()).
Regras para agrupamento e agregação de índices
O agrupamento e a agregação de índices são feitos por bloco de consulta, e a decisão de usar ou não o agrupamento/agregação de índices é tomada somente após o processo de seleção de índices.
- O bloco de consulta não deve conter Joins, NEST, SUBqueries.
- O bloco de consulta deve ser coberto por um índice de linha única.
- O bloco de consulta não deve conter ARRAY_AGG()
- O bloco de consulta não pode ser correlacionado
- Todos os predicados devem ser traduzidos exatamente em varreduras de intervalo.
- As expressões GROUP BY e Aggregate não podem fazer referência a nenhuma subconsulta, parâmetro nomeado ou parâmetro posicional.
- Chaves GROUP BY, expressões agregadas podem ser chaves de índice, chave de documento, expressão em chaves de índice ou expressão em chave de documento
- O índice precisa ser capaz de fazer o agrupamento e a agregação em todos os agregados no bloco de consulta, caso contrário, não haverá agregação de índice. (ou seja, ALL ou None)
- O agregado contém o modificador DISTINCT
- As chaves de grupo devem corresponder exatamente às chaves de índice principais (se a consulta contiver um predicado de igualdade na chave de índice, ela assumirá que essa chave de índice está implicitamente incluída nas chaves de GRUPO, se ainda não estiver presente).
- A expressão de agregação deve estar em uma das n+1 chaves de índice principais (n representa o número de chaves de grupo).
- No caso do índice de partição, as chaves de partição devem corresponder exatamente às chaves de grupo.
Resumo
Ao analisar o plano de explicação, correlacione os predicados na explicação com os intervalos e verifique se todos os predicados foram traduzidos exatamente para varreduras de intervalo e se a consulta está coberta. Certifique-se de que a consulta use agrupamentos e agregações de índices e, se possível, que a consulta use agregações completas do indexador ajustando as chaves do índice para melhorar o desempenho.