Neste postagemNa seção "Replicações", entrei em detalhes sobre as replicações entre Gateway de sincronização (SG) instâncias em Couchbase Mobile (CBM). Escrevi um aplicativo Java simples com uma interface de usuário baseada em Swing para ilustrar um exemplo de trabalho. Executei o aplicativo junto com duas instâncias do SG para demonstrar tudo.
Esse diagrama mostra o fluxo no aplicativo e as comunicações com o par SG.
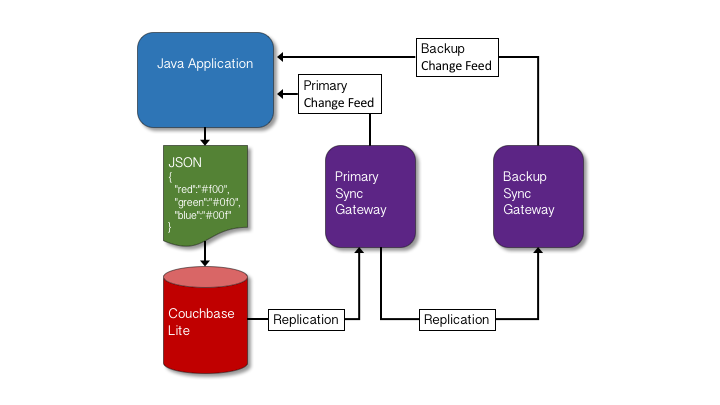
Um painel de edição nos permite inserir dados JSON. Esses dados são salvos na pasta Couchbase Lite (CBL). Temos duas réplicas configuradas. Uma delas envia os dados do banco de dados CBL para a instância do Sync Gateway que chamei de instância primária. Vou me referir a ela simplesmente como Primária. A primária replica a si mesma para a instância SG de backup (doravante denominada Backup).
Para ver isso acontecer, monitoro o _altera o feed do primário e do backup.
Tudo funciona em conjunto no meu Mac. Você pode configurar uma pilha completa de CBM, tudo em execução em sua máquina de desenvolvimento. Isso facilita o desenvolvimento inicial. Também ajuda a entender como todas as peças se encaixam e funcionam. Falarei mais sobre isso em meu blog no futuro.
Vamos examinar as configurações e o código.
Configuração do Sync Gateway
Backup
Executo cada instância do SG com seu próprio arquivo de configuração JSON. A configuração do Backup é um pouco mais simples. Aqui está ela.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "<span class="hljs-attr">interface<\/span>":<extensão classe="hljs-string" estilo="color: #880000">":5984"</extensão>, "<span class="hljs-attr">adminInterface<\/span>":<extensão classe="hljs-string" estilo="color: #880000">":5985"</extensão>, "<span class="hljs-attr">log<\/span>": [<extensão classe="hljs-string" estilo="color: #880000">"*"</extensão>], "<span class="hljs-attr">bancos de dados<\/span>": { "<span class="hljs-attr">db<\/span>": { "<span class="hljs-attr">servidor<\/span>": <extensão classe="hljs-string" estilo="color: #880000">"walrus:"</extensão>, "<span class="hljs-attr">Usu\u00e1rios<\/span>": { "<span class="hljs-attr">GUEST<\/span>": {"<span class="hljs-attr">desabilitado<\/span>": <extensão classe="hljs-literal" estilo="color: #1f811f">falso</extensão>, "<span class="hljs-attr">admin_channels<\/span>": [<extensão classe="hljs-string" estilo="color: #880000">"*"</extensão>] } } } } } |
Como executamos duas cópias do SG, precisamos nos certificar de que elas usem portas de rede diferentes. Por padrão, o SG usa as portas 4984 e 4985. As primeiras linhas do Backup o configuram para escutar nas portas 5984 e 5985. Não há nada de especial nessas portas. Apenas certifique-se de escolher aquelas que não são usadas por outros aplicativos em seu computador.
O restante do arquivo de configuração faz com que o SG registre tudo, configura-se para servir dados de um banco de dados na memória para fins especiais (indicado pela palavra-chave "walrus") e permite acesso aberto a qualquer pessoa por meio do usuário "GUEST". Essa é uma boa parte a ser lembrada no início do desenvolvimento. O Walrus permite que você use o SG de forma autônoma, sem um backend de servidor. Usar o GUEST com todo o acesso significa que você pode colocar as coisas em funcionamento sem se preocupar com a autenticação e a configuração de canais. Observe que, por padrão, o SG registra os logs no stderr. É possível adicionar uma opção para que ele registre em um arquivo.
Replicação primária e entre instâncias
Definimos a replicação por push na configuração do Primary. Ela tem alguns dos mesmos parâmetros padrão.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "<span class="hljs-attr">log<\/span>": [<extensão classe="hljs-string" estilo="color: #880000">"*"</extensão>], "<span class="hljs-attr">bancos de dados<\/span>": { "<span class="hljs-attr">db<\/span>": { "<span class="hljs-attr">servidor<\/span>": <extensão classe="hljs-string" estilo="color: #880000">"walrus:"</extensão>, "<span class="hljs-attr">Usu\u00e1rios<\/span>": { "<span class="hljs-attr">GUEST<\/span>": {"<span class="hljs-attr">desabilitado<\/span>": <extensão classe="hljs-literal" estilo="color: #1f811f">falso</extensão>, "<span class="hljs-attr">admin_channels<\/span>": [<extensão classe="hljs-string" estilo="color: #880000">"*"</extensão>] } } } }, "<span class="hljs-attr">replica\u00e7\u00f5es<\/span>":[ { "<span class="hljs-attr">fonte<\/span>": <extensão classe="hljs-string" estilo="color: #880000">"db"</extensão>, "<span class="hljs-attr">alvo<\/span>": <extensão classe="hljs-string" estilo="color: #880000">"http://localhost:5985/db"</extensão>, "<span class="hljs-attr">Cont\u00ednuo<\/span>": <extensão classe="hljs-literal" estilo="color: #1f811f">verdadeiro</extensão> } ] } |
A seção "replications" é onde as coisas interessantes acontecem. Observe que a entrada é uma matriz. Você pode especificar qualquer número de réplicas. Aqui temos apenas uma.
Para especificar uma replicação, você precisa fornecer uma origem e um destino. Lembre-se de que todas as replicações são unidirecionais.
O parâmetro "source" indica que queremos replicar o banco de dados identificado como "db". Você pode ver a seção em "bancos de dados", onde configuramos isso com o Walrus.
O destino pode ser outro banco de dados conectado à mesma instância do SG ou você pode especificar um URL HTTP, como fizemos aqui. Use o nome do banco de dados remoto para a parte do caminho do URL (/db, neste caso).
Execução do Sync Gateway
Salvei as configurações em dois arquivos, primary_gateway_config.json e backup_gateway_config.json. Você pode executar o SG manualmente a partir de uma linha de comando. Você pode encontrar informações sobre o download e a execução do SG para diferentes plataformas aqui.
Eu inicio o backup primeiro. Caso contrário, o Primary emite muitas mensagens sobre falhas na conexão para realizar a replicação.
O aplicativo Java
Escrevi o aplicativo Java usando Swing para a interface do usuário, usando o IntelliJ IDEA para o layout. Esta é a aparência do aplicativo na inicialização.
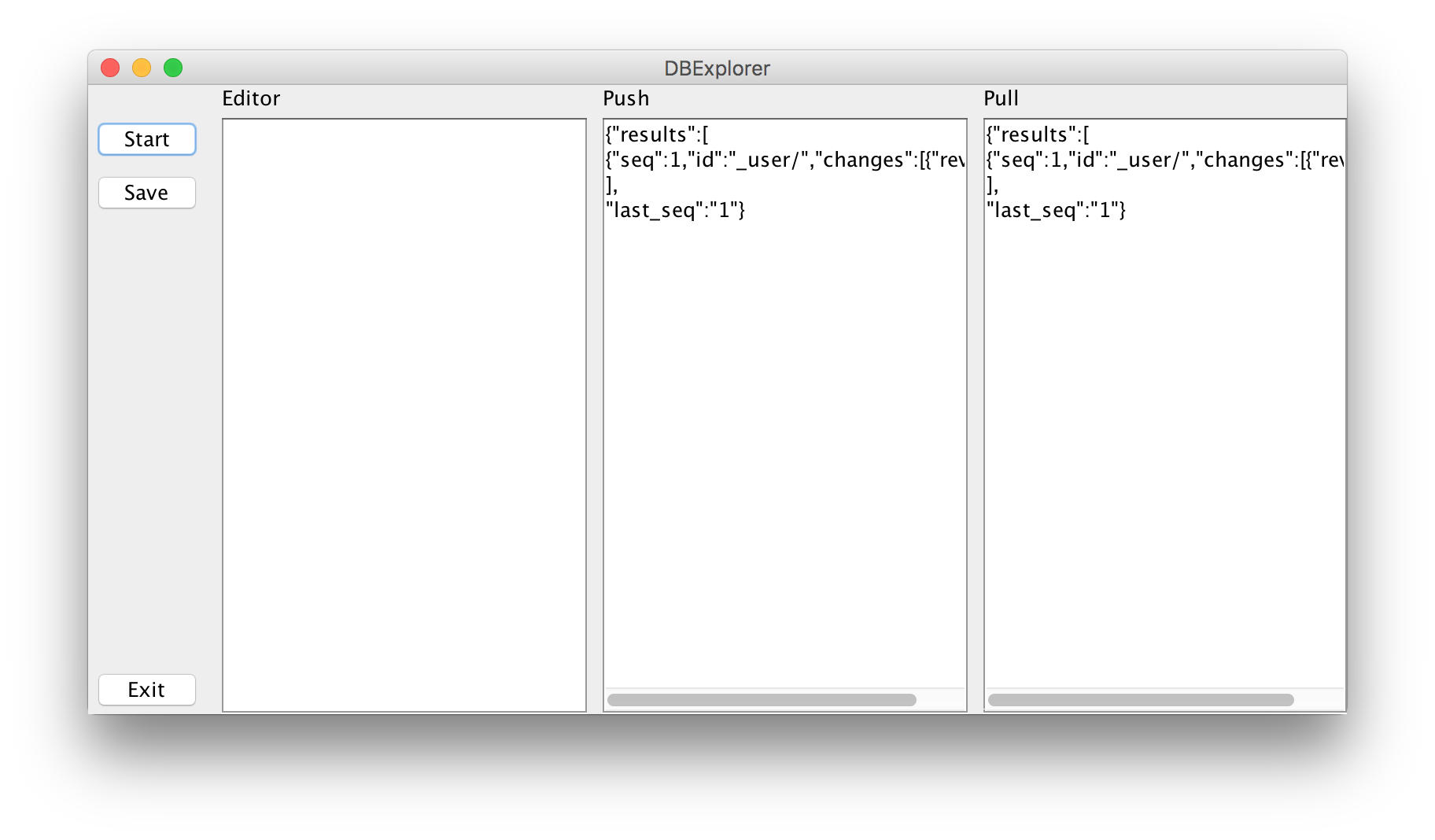
Para usá-lo, cole o JSON no painel de texto mais à esquerda. Clique no botão Salvar. Isso armazena um novo documento JSON no banco de dados CBL. A sincronização está pronta para começar. Clique no botão Start para ativá-la.
O painel de texto do meio monitora o feed de alterações primárias. O painel mais à direita monitora o feed de alterações de backup.
Com a sincronização ativada, toda vez que você salvar um documento, deverá ver os feeds de alterações responderem. Veja como isso acontece.
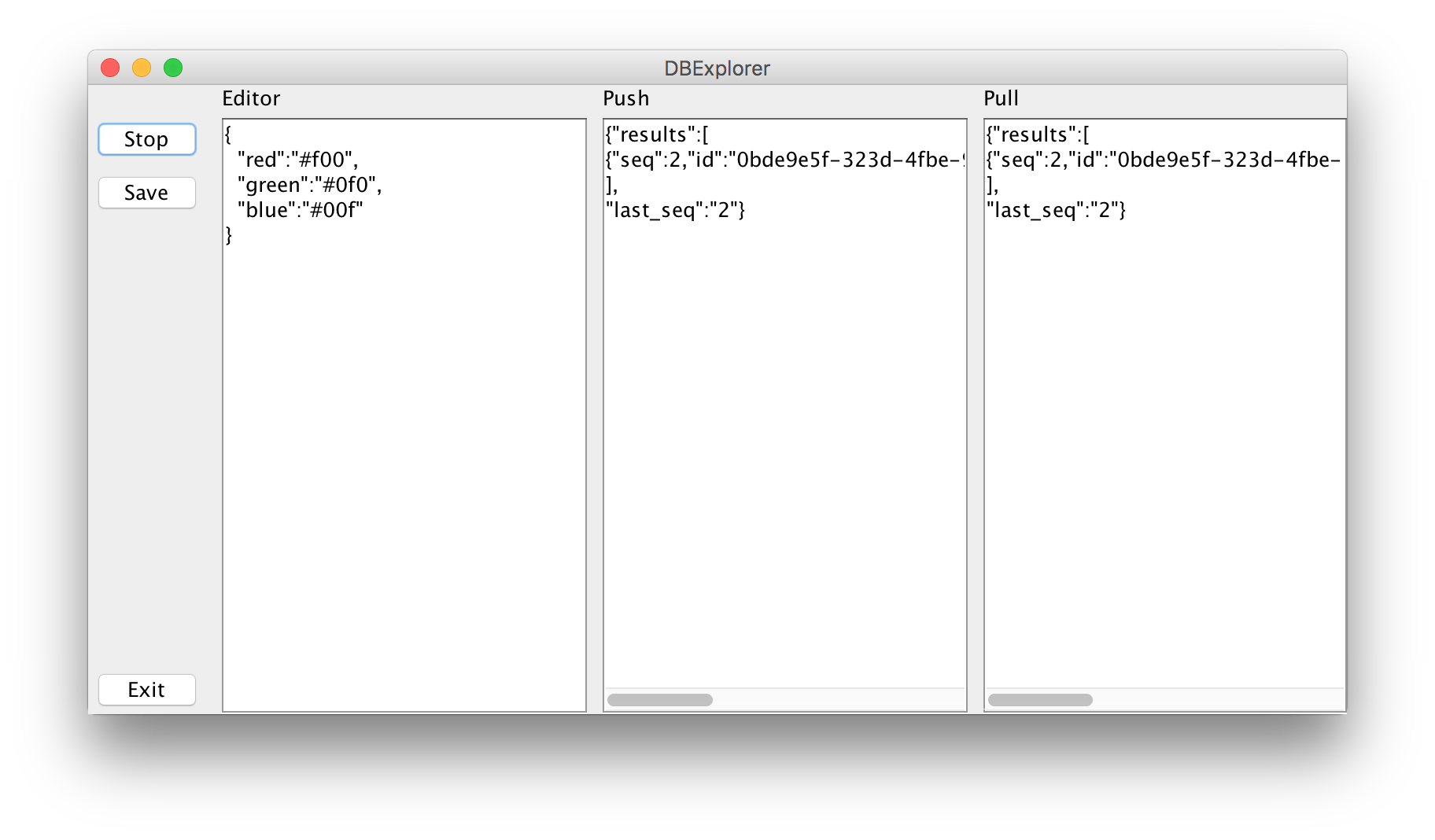
Você pode encontrar a fonte do projeto em GitHub. (Observe que esta amostra destaca os conceitos básicos. Não é um código de qualidade de produção). Vamos examinar algumas peças-chave.
Há quatro classes. A maior parte da interface do usuário está em DBExplorer.java. DBService.java é uma classe auxiliar bastante típica. Dê uma olhada nela para ver como as replicações são configuradas entre o CBL e o SG. O Runtime.java existe principalmente para ter uma instância compartilhada de um Jackson JSON ObjectMapper.
O SGMonitor.java se encarrega de monitorar os dois feeds de alterações. Eu uso o arquivo OkHttp da Square para fazer as chamadas REST.
Para monitorar o feed de alterações, uso o que é conhecido como longpolling. Com o longpoll, se não houver novos dados para transferir, a chamada HTTP não retorna imediatamente. Em vez disso, ela aguarda até que novos dados sejam enviados (ou até o tempo limite). A conexão é então fechada. Isso significa que você precisa de um loop para continuar verificando os registros de alterações. Observe que os registros de alterações são enviados como JSON. Os resultados são agrupados como uma matriz, portanto, é possível ter mais de um registro por resposta.
Para simplificar a criação da solicitação HTTP, criei um construtor de URL com os parâmetros necessários para cada chamada adicionada.
|
1 2 3 4 5 |
Criador de url = HttpUrl.analisar(url).newBuilder() .addPathSegment(<extensão classe="hljs-string" estilo="color: #880000">"_changes"</extensão>) .addQueryParameter(<extensão classe="hljs-string" estilo="color: #880000">"feed"</extensão>, <extensão classe="hljs-string" estilo="color: #880000">"longpoll"</extensão>) .addQueryParameter(<extensão classe="hljs-string" estilo="color: #880000">"timeout"</extensão>, <extensão classe="hljs-string" estilo="color: #880000">"0"</extensão>); |
Lendo isso, estamos nos conectando ao ponto de extremidade _changes, usando um tipo de feed de longpoll e definindo o tempo limite como 0 (0 significa que nunca há tempo limite).
Configurei um thread SwingWorker para executar o loop. Ele cria uma solicitação HTTP, dispara-a e aguarda a resposta.
O truque final aqui é informar ao Sync Gateway quais dados você precisa. Toda resposta SG _changes contém uma propriedade "last_seq". Essa propriedade é apenas um número inteiro que ajuda a rastrear quais registros um cliente já recebeu. É responsabilidade do cliente manter o controle dos dados que processou. Depois de lidar com uma resposta, você precisa adicionar ou atualizar o parâmetro "since" para solicitações futuras. Assim, o SG saberá transmitir apenas as alterações mais recentes.
Aqui está a última parte do loop.
|
1 2 3 4 5 6 7 8 |
Cordas corpo = resposta.corpo().string(); JsonNode árvore = mapeador.readTree(corpo); Criador de url.setQueryParameter(<extensão classe="hljs-string" estilo="color: #880000">"desde"</extensão>, árvore.obter(<extensão classe="hljs-string" estilo="color: #880000">"last_seq"</extensão>).asText()); publicar(corpo); |
Uso o Jackson ObjectMapper para analisar o registro de alterações. Em seguida, adiciono "since" como um parâmetro de consulta com o valor extraído da propriedade last_seq. Isso configura o URL para a próxima solicitação. A chamada de publicação se encarrega de atualizar a área de texto na interface do usuário.
É isso aí. O projeto inteiro pode ser executado em uma máquina. Isso permitirá que você explore o Couchbase Lite, o Sync Gateway e as replicações em detalhes. Aproveite.
Pós-escrito
Confira mais recursos em nosso portal do desenvolvedor e nos siga no Twitter @CouchbaseDev.
Você pode postar perguntas em nosso fóruns. E participamos ativamente de Estouro de pilha.
Você pode me seguir pessoalmente em @HodGreeley