Eu queria mostrar a maioria dos novos recursos de pesquisa do Couchbase disponíveis na versão 4.5 em um projeto simples. E recentemente houve algum interesse sobre armazenamento de arquivos ou binários no Couchbase. De uma perspectiva geral e genérica, os bancos de dados não são feitos para armazenar arquivos ou binários. Normalmente, o que você faria é armazenar arquivos em um repositório binário e seus metadados associados no banco de dados. Os metadados associados serão o local do arquivo no armazenamento binário e o máximo possível de informações extraídas do arquivo.
Portanto, este é o projeto que mostrarei a você hoje. É um aplicativo Spring Boot muito simples que permite que o usuário faça upload de arquivos, armazene-os em um repositório binário, onde o texto e os metadados associados serão extraídos do arquivo, e permite que você pesquise arquivos com base nesses metadados e no texto. No final, você poderá pesquisar arquivos por tipo de imagem, tamanho da imagem, conteúdo do texto, basicamente qualquer metadado que possa ser extraído do arquivo.
A Loja Binária
Essa é uma pergunta que recebemos com frequência. Certamente é possível armazenar dados binários em um banco de dados, mas os arquivos devem estar em um armazenamento binário apropriado. Decidi criar uma implementação muito simples para este exemplo. Basicamente, há uma pasta no sistema de arquivos declarada no tempo de execução que conterá todos os arquivos carregados. Um resumo SHA1 será calculado a partir do conteúdo do arquivo e usado como nome de arquivo nessa pasta. Obviamente, você poderia usar outros armazenamentos binários mais avançados, como o Manta da Joyent ou o Amazon S3, por exemplo. Mas vamos manter as coisas simples para esta postagem :) Aqui está uma descrição dos serviços usados.
SHA1Serviço
Esse é o mais simples, com um método que basicamente envia de volta um resumo SHA-1 com base no conteúdo do arquivo. Para simplificar ainda mais o código, estou usando o Apache commons-codec:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@Service public class SHA1Service { public String getSha1Digest(InputStream is) { try { return DigestUtils.sha1Hex(is); } catch (IOException e) { throw new RuntimeException(e); } } } |
DataExtractionService
Esse serviço foi criado para extrair metadados e texto dos arquivos carregados. Há muitas maneiras diferentes de fazer isso. Eu optei por usar o ExifTool e Poppler.
O ExifTool é uma excelente ferramenta de linha de comando para ler, gravar e editar metadados de arquivos. Ele também pode gerar metadados diretamente em JSON. E, é claro, não se limita ao padrão Exif. Ele é compatível com uma grande variedade de formatos. O Poppler é uma biblioteca de utilitários para PDF que me permitirá extrair o conteúdo de texto de um PDF. Como essas ferramentas são de linha de comando, usarei plexus-utils para facilitar as chamadas da CLI.
Há dois métodos. O primeiro é extractMetadata e é responsável pela extração de metadados do ExifTool. É o equivalente a executar o seguinte comando:
|
1 2 |
exiftool -n -json somePDFFile |
O -n está aqui para garantir que todos os valores numéricos sejam fornecidos como números e não como strings e -json para garantir que a saída esteja no formato JSON. Isso pode lhe dar uma saída como esta:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[{ "SourceFile": "Desktop/someFile.pdf", "ExifToolVersion": 10.11, "FileName": "someFile.pdf", "Directory": "Desktop", "FileSize": 20468, "FileModifyDate": "2016:03:29 13:50:29+02:00", "FileAccessDate": "2016:03:29 13:50:33+02:00", "FileInodeChangeDate": "2016:03:29 13:50:33+02:00", "FilePermissions": 644, "FileType": "PDF", "FileTypeExtension": "PDF", "MIMEType": "application/pdf", "PDFVersion": 1.4, "Linearized": false, "ModifyDate": "2016:03:29 02:42:32-07:00", "CreateDate": "2016:03:29 02:42:32-07:00", "Producer": "iText 2.1.6 by 1T3XT", "PageCount": 1 }] |
Há algumas informações interessantes, como o tipo mime, o tamanho, a data de criação e muito mais. Se o tipo mime do arquivo for aplicativo/pdf então podemos tentar extrair o texto dele com o poppler, que é o que o segundo método do serviço está fazendo. Ele é equivalente à seguinte chamada da CLI:
|
1 2 |
pdftotext -raw somePDFFile - |
Esse comando envia o texto extraído para a saída padrão. Que podemos recuperar e colocar em um arquivo texto completo em um objeto JSON. Código completo do serviço abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
package org.couchbase.devex.service; import java.io.File; import org.codehaus.plexus.util.cli.CommandLineException; import org.codehaus.plexus.util.cli.CommandLineUtils; import org.codehaus.plexus.util.cli.Commandline; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Service; import com.couchbase.client.java.document.json.JsonArray; import com.couchbase.client.java.document.json.JsonObject; @Service public class DataExtractionService { private final Logger log = LoggerFactory.getLogger(DataExtractionService.class); public JsonObject extractMetadata(File file) { String command = "/usr/local/bin/exiftool"; String[] arguments = { "-json", "-n", file.getAbsolutePath() }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { JsonArray arr = JsonArray.fromJson(output); return arr.getObject(0); } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } public String extractText(File file) { String command = "/usr/local/bin/pdftotext"; String[] arguments = { "-raw", file.getAbsolutePath(), "-" }; Commandline commandline = new Commandline(); commandline.setExecutable(command); commandline.addArguments(arguments); CommandLineUtils.StringStreamConsumer err = new CommandLineUtils.StringStreamConsumer(); CommandLineUtils.StringStreamConsumer out = new CommandLineUtils.StringStreamConsumer(); try { CommandLineUtils.executeCommandLine(commandline, out, err); } catch (CommandLineException e) { throw new RuntimeException(e); } String output = out.getOutput(); if (!output.isEmpty()) { return output; } String error = err.getOutput(); if (!error.isEmpty()) { log.error(error); } return null; } } |
Coisas bastante simples, como você pode ver depois de usar o plexus-utils.
BinaryStoreService
Esse serviço é responsável por executar a extração de dados e armazenar arquivos, excluir arquivos ou recuperar arquivos. Vamos começar com a parte de armazenamento. Tudo acontece no serviço storeFile método. A primeira coisa a fazer é recuperar o resumo do arquivo e, em seguida, gravá-lo na pasta de armazenamento binário declarada na configuração. Depois que o arquivo é gravado, o serviço de extração de dados é chamado para recuperar os metadados como um JsonObject. Em seguida, o local do armazenamento binário, o tipo de documento, o resumo e o nome do arquivo são adicionados a esse objeto JSON. Se o arquivo carregado for um PDF, o serviço de extração de dados será chamado novamente para recuperar o conteúdo do texto e armazená-lo em um objeto texto completo field. Em seguida, um JsonDocument é criado com o digest como chave e o JsonObject como conteúdo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public void storeFile(String name, MultipartFile uploadedFile) { if (!uploadedFile.isEmpty()) { try { String digest = sha1Service.getSha1Digest(uploadedFile.getInputStream()); File file2 = new File(configuration.getBinaryStoreRoot() + File.separator + digest); BufferedOutputStream stream = new BufferedOutputStream(new FileOutputStream(file2)); FileCopyUtils.copy(uploadedFile.getInputStream(), stream); stream.close(); JsonObject metadata = dataExtractionService.extractMetadata(file2); metadata.put(StoredFileDocument.BINARY_STORE_DIGEST_PROPERTY, digest); metadata.put("type", StoredFileDocument.COUCHBASE_STORED_FILE_DOCUMENT_TYPE); metadata.put(StoredFileDocument.BINARY_STORE_LOCATION_PROPERTY, name); metadata.put(StoredFileDocument.BINARY_STORE_FILENAME_PROPERTY, uploadedFile.getOriginalFilename()); String mimeType = metadata.getString(StoredFileDocument.BINARY_STORE_METADATA_MIMETYPE_PROPERTY); if (MIME_TYPE_PDF.equals(mimeType)) { String fulltextContent = dataExtractionService.extractText(file2); metadata.put(StoredFileDocument.BINARY_STORE_METADATA_FULLTEXT_PROPERTY, fulltextContent); } JsonDocument doc = JsonDocument.create(digest, metadata); bucket.upsert(doc); } catch (Exception e) { throw new RuntimeException(e); } } else { throw new IllegalArgumentException("File empty"); } } |
Ler ou excluir deve ser bastante simples de entender agora:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public StoredFile findFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { return null; } JsonDocument doc = bucket.get(digest); if (doc == null) return null; StoredFileDocument fileDoc = new StoredFileDocument(doc); return new StoredFile(f, fileDoc); } public void deleteFile(String digest) { File f = new File(configuration.getBinaryStoreRoot() + File.separator + digest); if (!f.exists()) { throw new IllegalArgumentException("Can't delete file that does not exist"); } f.delete(); bucket.remove(digest); } |
Lembre-se de que essa é uma implementação muito ingênua!
Indexação e pesquisa de arquivos
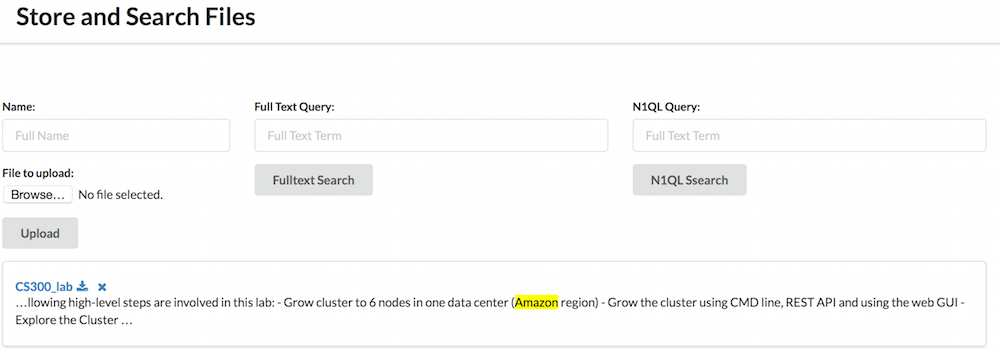
Depois de fazer o upload dos arquivos, você deseja recuperá-los. A primeira maneira muito básica de fazer isso seria exibir a lista completa de arquivos. Em seguida, você poderia usar o N1QL para pesquisá-los com base em suas metadatas ou o FTS para pesquisá-los com base em seu conteúdo.
O serviço de busca
getFiles simplesmente executa a seguinte consulta: SELECT binaryStoreLocation, binaryStoreDigest FROMpadrãoWHERE type= 'file'. Isso envia a lista completa de arquivos carregados com seu resumo e o local do armazenamento binário. Observe a opção de consistência definida como statement_plus. Como se trata de um aplicativo de documentos, prefiro uma consistência forte.
Em seguida, você tem searchN1QLFiles que executa uma consulta N1QL básica com uma cláusula WHERE adicional. Portanto, o padrão é a mesma consulta acima com uma parte WHERE adicional. Até o momento, não há uma integração mais estreita. Poderíamos ter um formulário de pesquisa sofisticado que permitisse ao usuário pesquisar arquivos com base em seus tipos de mime, tamanho ou quaisquer outros campos fornecidos pelo ExifTool.
E, finalmente, você tem searchFulltextFiles que recebe uma String como entrada e a usa em um Jogo consulta. Em seguida, o resultado é enviado de volta com fragmentos de texto em que o termo foi encontrado. Esse fragmento permite destacar o termo no contexto. Também solicito o binaryStoreDigest e binaryStoreLocation campos. Eles são usados para exibir os resultados para o usuário.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
public List<Map<String, Object>> getFiles() { N1qlQuery query = N1qlQuery .simple("SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file'"); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchN1QLFiles(String whereClause) { N1qlQuery query = N1qlQuery.simple( "SELECT binaryStoreLocation, binaryStoreDigest FROM `default` WHERE type= 'file' " + whereClause); query.params().consistency(ScanConsistency.STATEMENT_PLUS); N1qlQueryResult res = bucket.query(query); List<Map<String, Object>> filenames = res.allRows().stream().map(row -> row.value().toMap()) .collect(Collectors.toList()); return filenames; } public List<Map<String, Object>> searchFulltextFiles(String term) { SearchQuery ftq = MatchQuery.on("file_fulltext").match(term) .fields("binaryStoreDigest", "binaryStoreLocation").build(); SearchQueryResult result = bucket.query(ftq); List<Map<String, Object>> filenames = result.hits().stream().map(row -> { Map<String, Object> m = new HashMap<String, Object>(); m.put("binaryStoreDigest", row.fields().get("binaryStoreDigest")); m.put("binaryStoreLocation", row.fields().get("binaryStoreLocation")); m.put("fragment", row.fragments().get("fulltext")); return m; }).collect(Collectors.toList()); return filenames; } |
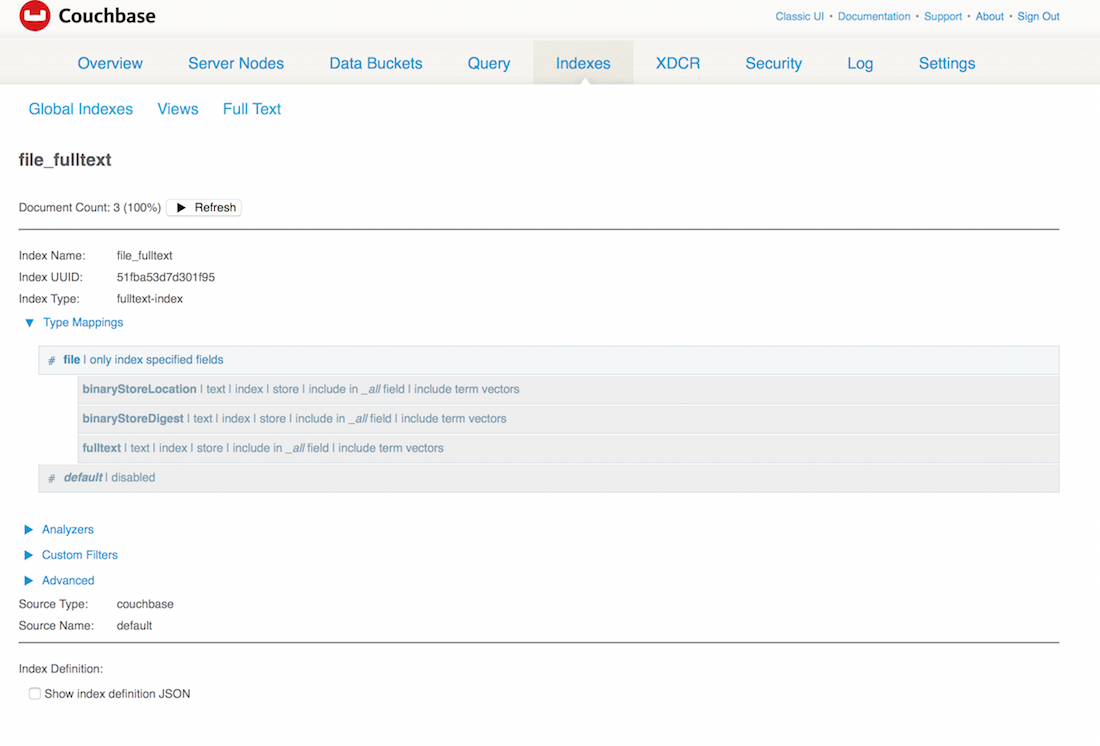
O TermQuery.on define qual índice estou consultando. Aqui ele está definido como 'file_fulltext'. Isso significa que criei um índice de texto completo com esse nome:
Colocando tudo junto
Configuração
Primeiro, uma breve explicação sobre a configuração. A única coisa configurável até agora é o caminho do armazenamento binário. Como estou usando o Spring Boot, só preciso do seguinte código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
package org.couchbase.devex; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Configuration; @Configuration public class BinaryStoreConfiguration { @Value("${binaryStore.root:upload-dir}") private String binaryStoreRoot; public String getBinaryStoreRoot() { return binaryStoreRoot; } } |
Com isso, posso simplesmente adicionar binaryStore.root=/Usuários/ldoguin/binaryStore para minha application.properties arquivo. Também quero permitir o upload de um arquivo de 512 MB, no máximo. Além disso, para aproveitar a autoconfiguração do Spring Boot Couchbase, preciso adicionar o endereço do meu servidor Couchbase. No final, meu application.properties se parece com isso:
|
1 2 3 4 5 |
binaryStore.root=/Users/ldoguin/binaryStore multipart.maxFileSize: 512MB multipart.maxRequestSize: 512MB spring.couchbase.bootstrap-hosts=localhost |
Para usar o autoconfig do Spring Boot, basta ter o spring-boot-starter-parent como pai e o Couchbase no classpath. Portanto, é apenas uma questão de adicionar uma dependência java-client do Couchbase. Estou especificando a versão 2.2.4 aqui porque o padrão é 2.2.3 e o FTS está apenas na versão 2.2.4. Você pode dar uma olhada no arquivo pom completo em Github. Parabéns a Stéphane Nicoll da Pivotal e Simon Baslé do Couchbase para essa maravilhosa integração com o Spring.
Controlador
Como esse aplicativo é muito simples, coloquei tudo no mesmo controlador. O ponto de extremidade mais básico é /arquivos. Ele exibe a lista de arquivos já carregados. Basta uma chamada para o searchService, colocar o resultado no modelo da página e, em seguida, renderizar a página.
|
1 2 3 4 5 6 7 |
@RequestMapping(method = RequestMethod.GET, value = "/files") public String provideUploadInfo(Model model) { List<Map<String, Object>> files = searchService.getFiles(); model.addAttribute("files", files); return "uploadForm"; } |
Eu uso Folha de tomilho para renderização e IU semântica como estrutura CSS. Você pode dar uma olhada no modelo usado aqui. Esse é o único modelo usado no aplicativo.
Quando tiver uma lista de arquivos, você poderá fazer o download ou excluí-los. Ambos os métodos estão chamando o método de serviço de armazenamento binário, e o restante do código é o clássico Spring MVC:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@RequestMapping(method = RequestMethod.GET, value = "/download/{digest}") public String download(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) throws IOException { StoredFile sf = binaryStoreService.findFile(digest); if (sf == null) { redirectAttributes.addFlashAttribute("message", "This file does not exist."); return "redirect:/files"; } response.setContentType(sf.getStoredFileDocument().getMimeType()); response.setHeader("Content-Disposition", String.format("inline; filename="" + sf.getStoredFileDocument().getBinaryStoreFilename() + """)); response.setContentLength(sf.getStoredFileDocument().getSize()); InputStream inputStream = new BufferedInputStream(new FileInputStream(sf.getFile())); FileCopyUtils.copy(inputStream, response.getOutputStream()); return null; } @RequestMapping(method = RequestMethod.GET, value = "/delete/{digest}") public String delete(@PathVariable String digest, RedirectAttributes redirectAttributes, HttpServletResponse response) { binaryStoreService.deleteFile(digest); redirectAttributes.addFlashAttribute("message", "File deleted successfuly."); return "redirect:/files"; } |
Obviamente, você também desejará fazer upload de alguns arquivos. É um simples POST multiparte. O serviço de armazenamento binário é chamado, persiste o arquivo e extrai os dados apropriados e, em seguida, redireciona para o /arquivos ponto final.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@RequestMapping(method = RequestMethod.POST, value = "/upload") public String handleFileUpload(@RequestParam("name") String name, @RequestParam("file") MultipartFile file, RedirectAttributes redirectAttributes) { if (name.isEmpty()) { redirectAttributes.addFlashAttribute("message", "Name can't be empty!"); return "redirect:/files"; } binaryStoreService.storeFile(name, file); redirectAttributes.addFlashAttribute("message", "You successfully uploaded " + name + "!"); return "redirect:/files"; } |
Os dois últimos métodos são usados para a pesquisa. Eles simplesmente chamam o serviço de pesquisa, adicionam o resultado ao modelo da página e o renderizam.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@RequestMapping(method = RequestMethod.POST, value = "/fulltext") public String fulltextQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchFulltextFiles(query); model.addAttribute("files", files); return "uploadForm"; } @RequestMapping(method = RequestMethod.POST, value = "/n1ql") public String n1qlQuery(@ModelAttribute(value = "name") String query, Model model) throws IOException { List<Map<String, Object>> files = searchService.searchN1QLFiles(query); model.addAttribute("files", files); return "uploadForm"; } |
E isso é praticamente tudo o que você precisa para armazenar, indexar e pesquisar arquivos com o Couchbase e o Spring Boot. É um aplicativo simples e há muitas, muitas outras coisas que você poderia fazer para melhorá-lo, começando por um formulário de pesquisa adequado que exponha os campos extraídos do ExifTool. Vários uploads de arquivos e arrastar e soltar seriam uma boa vantagem. O que mais você gostaria de ver? Deixe-nos saber nos comentários abaixo!