Então, já demos uma olhada de alto nível no que está envolvido na criação de uma solução Customer 360 no Couchbase aqui.
É isso mesmo, foi preciso pensar muito.
Desculpe, não há como contornar isso.
Você tem que pensar, não pode ser uma das massas sem noção...
Portanto, supondo que eu não tenha conseguido afugentá-lo com a ameaça do pensamento, vamos começar a investigar alguns dos detalhes.
Em particular, a primeira parte que precisa ser pensada é a obtenção dos dados no Couchbase.
Vamos dar uma olhada novamente no diagrama geral do sistema.
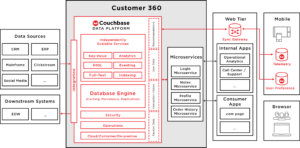
Observando o lado esquerdo, você tem uma coleção de sistemas em uma caixa chamada "Data Sources" (Fontes de dados).
CRM
ERP
Mainframe
(Mainframe? Você ainda tem um Mainframe por aí? Não podemos simplesmente desligar a água e deixar que ele tenha uma morte feia e não natural? Não?!?!? Ugh...)
Fato curioso: os mainframes costumavam ser refrigerados a água!
Sim, quando os engenheiros perceberam o quão quente essas feras ficariam, eles pensaram: "Ei, passar água nos motores de nossos carros parece evitar que eles superaqueçam. Vamos fazer a mesma coisa com esse bebê!"
Fato curioso #2, na década de 90, a empresa Cray Computer, localizada em Minnesota, onde neva 11 meses e meio por ano, decidiu se mudar para um novo prédio, mas descobriu que tinha problemas para vender o prédio da antiga sede.
Parece que o local não tinha aquecedor. Eles apenas canalizaram o calor gerado por seu próprio computador por todo o local!
Tostado!
Mas estou divagando...
Então, basicamente, você tem todos esses sistemas, cada um com seu próprio modelo de dados, dos quais precisa extrair dados para serem ingeridos no Couchbase.
Extração
Se esse fosse meu trabalho, eu tentaria seguir o caminho mais simples.
Não é porque sou preguiçoso...
Quero dizer, talvez eu seja, depende de sua definição de preguiçoso...
Mas esse não é o motivo pelo qual eu sigo o caminho mais fácil.
Estou fazendo isso há algum tempo.
E, pelo que tenho visto, quanto mais simples for uma solução, mais fácil será implementá-la...
Quanto mais fácil for a manutenção...
Quanto menos ele quebrar...
E eu consigo dormir à noite.
Algo de que gosto muito.
Portanto, talvez fácil não seja a descrição correta...
Simples é melhor assim.
Portanto, para manter as coisas simples, vou extrair todos os dados desses sistemas de origem de que preciso, formatá-los no formato JSON e inseri-los no Couchbase.
O que poderia ser mais simples?
Pode ser tão simples quanto conectar as duas extremidades a um fluxo Kafka, canalizando os dados diretamente da fonte para o Couchbase.
Um pouco de configuração em cada extremidade e voilà! Tenho dados de clientes em meu bucket do Couchbase!
Somente...
É tudo desarticulado e sem conexão...
Não estou exatamente atingindo meu objetivo aqui...
Droga! E eu que achava que tinha conseguido sobreviver sem ter que pensar nisso...
Hmm...
Transformar
OK, então eu tenho todos esses dados desconexos de vários sistemas de origem no meu bucket do Couchbase e preciso combiná-los de alguma forma em um modelo de dados que faça sentido.
Sempre há algum detalhe complicado para resolver...
Porém, não sei quando algum desses documentos existentes poderá ser atualizado no sistema de origem.
Eu só tenho que contar com o fato de que eles chegam, a torto e a direito, em momentos aleatórios.
Como posso...
Consegui! Usarei o sistema de eventos do Couchbase para me avisar quando tiver uma atualização...
Vou examinar o novo documento para ver o que é...
Dê uma olhada para ver se tenho outros dados para esse cliente com os quais preciso combiná-los...
E, se for o caso, crie um novo documento, combinando os dados do cliente.
Algo como...
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
function OnUpdate(doc, meta) { // OK, I've got an update, do I have the other // documents I need to combine with it? if haveOtherDocuments(doc) { // I've got the other documents I need to // combine to create the new customer 360 cust360Doc = combineCustomerDocuments(doc); // Save the combined document in the customer 360 bucket tgt[cust360Doc.id] = cust360Doc; } } |
Uau! Muito simples, não é?
É claro que essas duas funções que estou chamando ainda precisam ser desenvolvidas...
Espero que não sejam muito peludos...
Carga
OK, então extraímos os dados de nossos sistemas de origem, os transformamos em um modelo de dados combinado e os carregamos em nosso bucket de destino do Couchbase e...
Espere um pouco...
Extrair... Transformar... Carregar...
ETL?!?!?
Isso não é um palavrão por aqui?
Nós somos o Couchbase!
Nós pregamos o Analytics sem ETL!
Veja, qualquer alteração nos dados do Bucket do Couchbase aparece automaticamente no serviço do Analytics...
...mudança no Bucket do Couchbase...
Nós... eu... nós... eu... Uhh...
Hmm...
Acho que a frase "Sem ETL" só se aplica depois que você coloca seus dados no Couchbase...
Sim, não vejo nenhuma maneira de evitar isso nesse caso.
Mas, nesse caso, poderia ser mais ou menos em tempo real.
Depende do cronograma em que você está executando as extrações dos sistemas de origem.
Se eles estiverem sendo executados todas as noites, como um trabalho em lote, então é apenas o ETL noturno comum.
Mas se você tiver acionadores em seus bancos de dados de CRM ou ERP que colocam as atualizações na fila do Kafka no momento em que os registros do cliente são atualizados nesses sistemas, então é um processo de ETL em tempo real.
Estamos nos aproximando do que pregamos por aqui...
Observação: Para aqueles que desejam se aprofundar nos detalhes nerds de como colocar isso em prática, temos um tutorial muito bom e detalhado em nosso site. Você pode encontrá-lo aqui.
Então, por que o Couchbase novamente?
Quero dizer, qualquer banco de dados sem esquema permitirá que você crie um único e enorme documento contendo todos os dados de seus clientes. Por que você deveria usar o nosso?
Além da facilidade de usar algo que você provavelmente já tem em sua infraestrutura (Kafka) para obter os dados do seu sistema de origem e inseri-los em um bucket do Couchbase e, em seguida, usar nosso serviço Eventing para acionar alguma funcionalidade em tempo real para ETL desses dados?
Quer dizer, você sempre pode pagar muito dinheiro para comprar um software ETL mágico para fazer esse trabalho pesado para você...
Você pode então conectar uma solução de cache para obter a velocidade e o desempenho de que precisa...
E inclua um produto de pesquisa de texto completo para permitir que seus usuários encontrem as informações que desejam...
Em seguida, crie uma API REST para permitir que os dados sejam acessados pelo seu aplicativo móvel...
Adicione outro sistema ETL para extrair os dados e jogá-los em algum sistema analítico de lago de dados...
E então, quando a máquina Rube Goldberg que você construiu tiver o menor problema, corra para consertar as coisas e manter tudo funcionando...
E desistir do hobby de conseguir dormir...
Ou você pode seguir o caminho mais simples e usar apenas o Couchbase para tudo isso.
Como eu disse anteriormente, prefiro soluções simples.