Agora está mais fácil do que nunca criar e implantar microsserviços e aplicativos multilocatários no Couchbase. A versão 7.0 apresenta um novo recurso de organização de dados chamado Scopes and Collections.
Os escopos e as coleções permitem o isolamento lógico de diferentes tipos de dados, o gerenciamento independente do ciclo de vida e o controle de segurança em vários níveis de granularidade. Os desenvolvedores de aplicativos os utilizam para organizar e isolar seus dados. DevOps e administradores consideram os vários níveis de controle de acesso baseado em função (RBAC) - no nível de Bucket, Escopo e Coleção - uma opção poderosa para hospedar microsserviços e locatários em escala.
A funcionalidade completa desse recurso é agora disponível no Couchbase Server 7.0. Um Developer Preview com funcionalidade limitada já estava disponível na versão 6.5, e alguns de vocês já devem ter experimentado.
O que são escopos e coleções do Couchbase
Os escopos e as coleções são contêineres lógicos dentro de um Balde do Couchbase.
É útil pensar nas coleções como tabelas em um banco de dados relacional, mas sem a rigidez dos dados. Os escopos são um conjunto de coleções relacionadas, o que os torna semelhantes a um esquema RDBMS. Mas, em ambos os casos, os escopos e as coleções são mais flexíveis, pois armazenam documentos JSON.
A tabela abaixo mostra o mapeamento de construções conhecidas de RDBMS para o Couchbase:
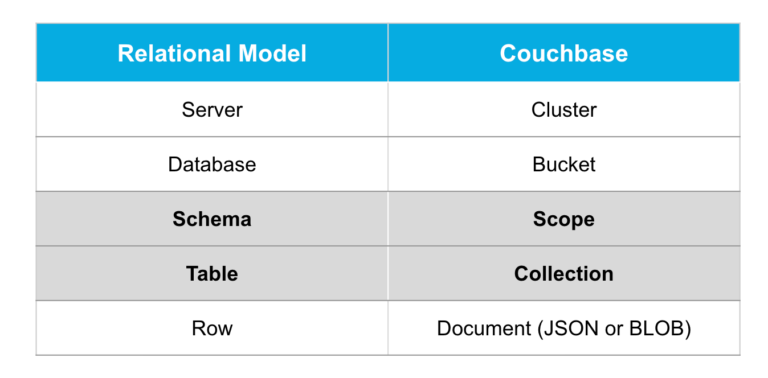
Mapeamento de conceitos de RDBMS para o Couchbase
Aqui está um exemplo de organização dos dados do aplicativo de viagens do Couchbase com escopos e coleções:
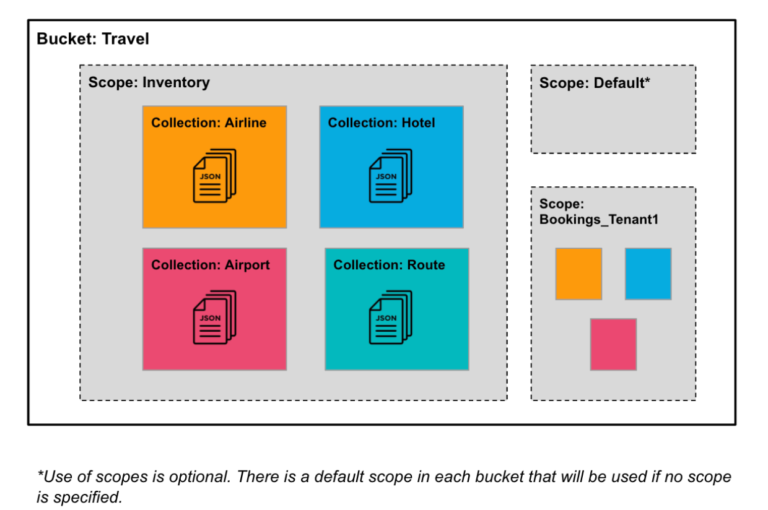
Um exemplo de escopos e coleções com um conjunto de dados de exemplo
Como criar e usar escopos e coleções
Você pode criar escopos e coleções em qualquer um dos SDKs do Couchbase, couchbase-cli, APIs REST, N1QL ou a partir da interface do usuário.
Em particular, N1QLAs consultas N1QL se tornam muito mais simples e sintaticamente mais breves, pois você não precisa mais qualificar diferentes tipos de documentos usando where type = xxx. Em vez disso, você simplesmente faz referência à Coleção diretamente.
No exemplo mostrado abaixo, usamos o N1QL (executei as instruções N1QL usando concha cbq) para criar um escopo, algumas coleções e alguns índices. Em seguida, executamos uma consulta simples que une duas Collections.
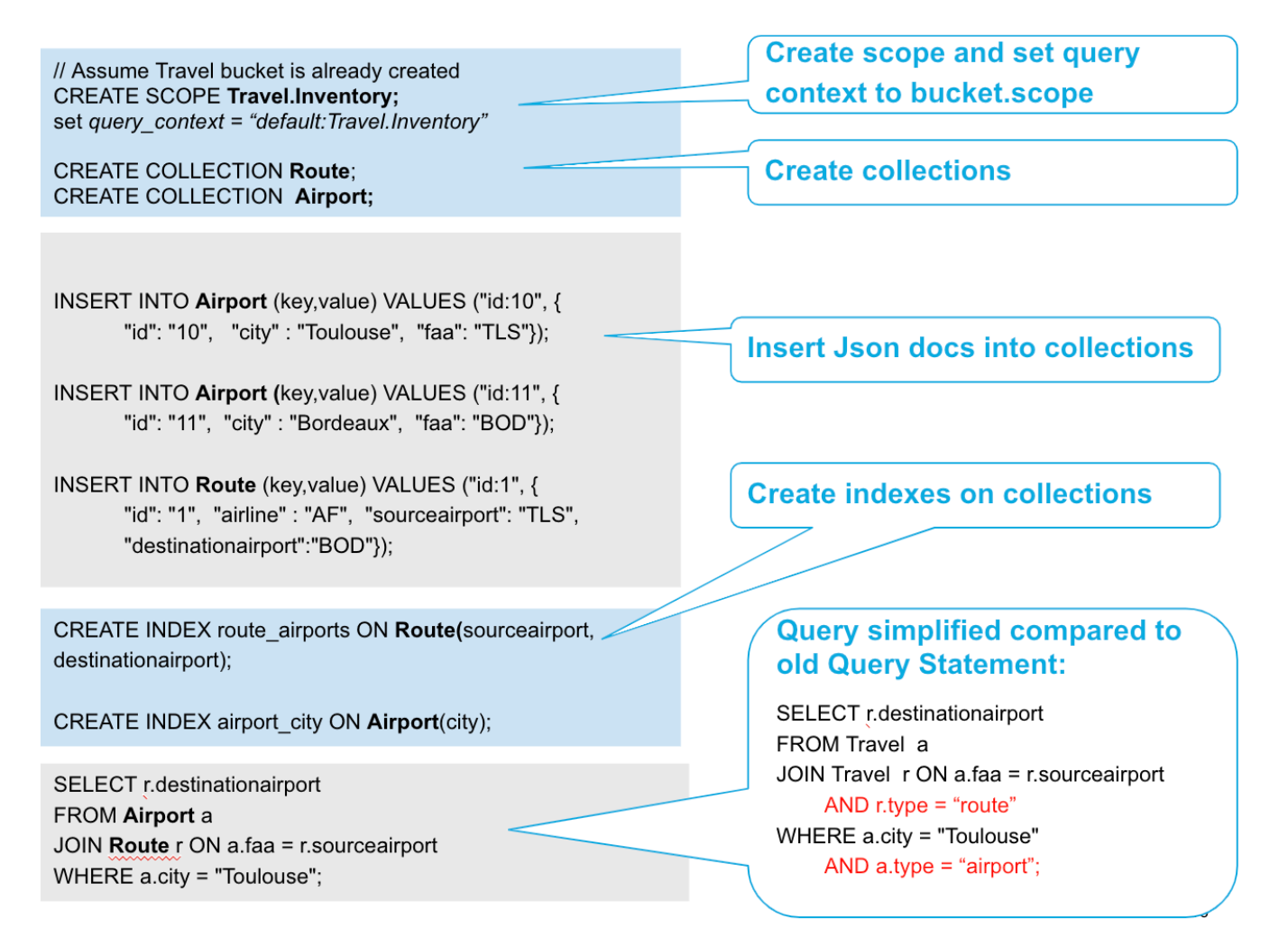
Uma consulta N1QL para criar um escopo, coleções e índices
A escala de escopos e coleções
Atualmente, o Couchbase permite que você tenha 30 Buckets em um único cluster. Os escopos e as coleções permitem que você crie um número maior de entidades em ordem de grandeza.
Como as coleções de fato contêm os dados e os escopos organizam as coleções relacionadas, você normalmente tem menos escopos do que coleções. Os índices secundários globais (GSIs) são criados nas coleções, e uma coleção geralmente tem vários índices.
Tendo esses requisitos em mente, aqui está a escala dessas entidades que você pode criar no Couchbase 7.0 (muitas delas!):
-
- Número de coleções permitidas por cluster: 1,000
- Número de escopos permitidos por cluster: 1,000
- Número de índices secundários globais permitidos por cluster: 10,000
Habilitando o multilocatário em escala
Os aplicativos modernos geralmente são escritos como microsserviços, sendo que cada aplicativo consiste em vários (e, às vezes, centenas) de microsserviços.
Com o advento do SaaS e todas as suas vantagens, muitos desses aplicativos são multilocatários. Para as equipes corporativas, é importante manter o custo baixo para hospedar vários aplicativos e locatários (ou seja, TCO) e, ao mesmo tempo, fornecer o isolamento e a flexibilidade necessários.
Os Buckets, Escopos e Coleções do Couchbase agora oferecem uma hierarquia de contenção de três níveis para ajudá-lo a mapear seus aplicativos, locatários e microsserviços.
Principais recursos para a consolidação de vários locatários e microsserviços
Vamos nos aprofundar nos recursos oferecidos pelos escopos e coleções que possibilitam a consolidação de locatários e microsserviços.
Isolamento lógico e indexação
As coleções permitem que você isole seus dados por tipo e, ao mesmo tempo, aproveite a flexibilidade de um modelo de banco de dados de documentos JSON que evolui com seu aplicativo.
Conforme mostrado no exemplo de viagem acima, os documentos da companhia aérea vão para a coleção de companhias aéreas, os documentos do hotel vão para a coleção de hotéis e assim por diante.
Cada coleção também pode ser indexada individualmente. Tipos diferentes de documentos normalmente têm necessidades diferentes de indexação, e as coleções permitem que você defina índices diferentes para cada tipo.
Gerenciamento do ciclo de vida em vários níveis
Os escopos e as coleções permitem que você gerencie e monitore seus dados em dois novos níveis, além do nível de Bucket existente.
A funcionalidade fornecida inclui:
-
- Criar e soltar coleções ou escopos individuais
- Defina a expiração (tempo máximo de vida, também conhecido como Max TTL) no nível da coleção
- Monitore as estatísticas no nível do escopo e da coleção. Embora um conjunto completo de estatísticas esteja disponível apenas no nível de Bucket, um subconjunto de estatísticas está disponível nos níveis de Collection e Scope (por exemplo, contagem de itens, memória usada, espaço em disco usado, operações por segundo).
Controle de acesso refinado com RBAC
Um dos aspectos mais poderosos dos Escopos e Coleções é a capacidade de controlar a segurança em vários níveis - Bucket, Escopo, Coleção - usando o controle de acesso baseado em função (RBAC). Essa é a chave para consolidar centenas de microsserviços e/ou locatários em um único cluster do Couchbase.
Agora, você pode conceder a um usuário acesso a um Bucket inteiro, a um Escopo ou a uma Coleção. Várias funções de usuário prontas para uso estão disponíveis, e Mais detalhes estão disponíveis na documentação do RBAC).
Controle de replicação refinado com XDCR
O XDCR (Cross Data Center Replication) permite que você controle a replicação no nível do Bucket, do Escopo ou da Coleção.
Você pode optar por replicar um Bucket inteiro, um Escopo ou apenas uma Coleção. Você pode mapear para uma entidade com nome semelhante no destino ou remapear para uma entidade diferente. Você também tem a flexibilidade da filtragem avançada, que já foi introduzida para o XDCR na versão 6.5 do Couchbase.
A flexibilidade fornecida pelo XDCR é crucial para mapear microsserviços e/ou locatários para coleções e escopos, pois permite controlar cada microsserviço e locatário individualmente.
Backup/restauração em vários níveis
Dando continuidade ao tema do gerenciamento do ciclo de vida em vários níveis, o Couchbase 7.0 também permite controlar as opções de backup e restauração em cada um desses níveis.
Portanto, você pode fazer backup (e, da mesma forma, restaurar) de um Bucket, Escopo ou Coleção individual, além de filtrar os dados e remapeá-los durante a restauração.
Fique atento aos blogs de instruções mais detalhados sobre cada um dos temas acima (RBAC, XDCR e Backup/Restauração) nas próximas semanas!
Implantação de microsserviços usando coleções
Um típico arquitetura de microsserviços recomenda que cada microsserviço seja simples (idealmente, de função única), com acoplamento frouxo de outros microsserviços (o que significa ter seu próprio armazenamento de dados) e escalonado de forma independente.
Antes de Servidor Couchbase 7.0, você poderia hospedar cada microsserviço em um cluster separado ou em um Bucket separado. Essas opções de implementação têm limites inerentes à densidade do aplicativo e nem sempre resultam na utilização total do hardware. Agora, com o Couchbase 7.0, você pode mapear cada microsserviço para uma ou mais coleções. E como é possível ter até mil coleções, você pode ter mil microsserviços em um único cluster (!).
Vejamos o exemplo de implantação de microsserviço mostrado abaixo:
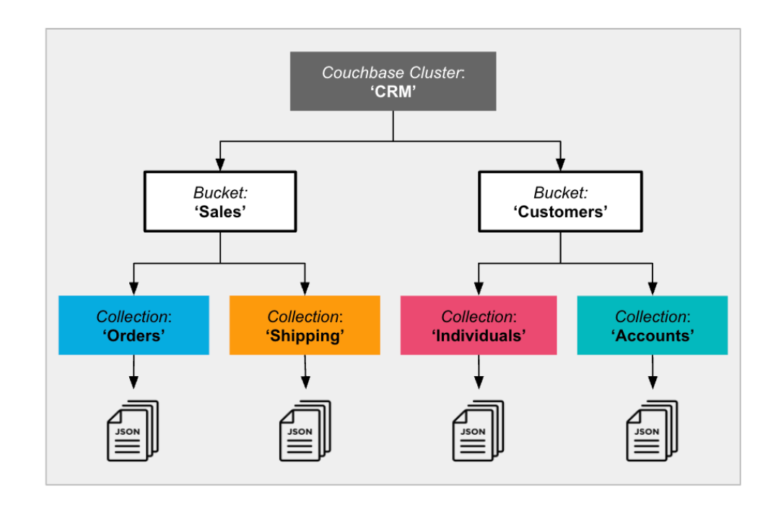
Consolidação de microsserviços usando escopos e coleções do Couchbase
O exemplo acima mostra dois aplicativos de CRM (Sales e Customers) implementados em um único cluster. Cada um dos dois aplicativos é mapeado para um Bucket, o que permite controlar a alocação geral de recursos para cada aplicativo.
O aplicativo Sales tem dois microsserviços: Pedidos e Remessa, e o aplicativo Customers tem dois microsserviços: Individuals (Indivíduos) e Accounts (Contas). Mapeamos cada um dos microsserviços para sua própria coleção. Neste exemplo, não usamos Escopos. Você não precisa definir Escopos se não precisar do nível extra de organização (em vez disso, é usado o Escopo padrão).
Implementação de vários locatários usando escopos
Os aplicativos multilocatários exigem níveis variados de isolamento entre os locatários e níveis variados de compartilhamento de recursos da infraestrutura subjacente. A arquitetura de implementação escolhida é uma compensação entre o isolamento e o custo total de propriedade (TCO).
Alguns locatários podem exigir isolamento físico completo e, nesse caso, clusters separados para cada locatário podem ser a arquitetura certa, embora com um alto TCO. Os Buckets do Couchbase fornecem isolamento físico parcial e segurança total e isolamento lógico e podem ser usados para locatários separados, embora com limites de escala e sobrecarga por Bucket.
O isolamento lógico e de segurança entre locatários geralmente é suficiente. Com os Escopos, você obtém segurança e isolamento lógico em níveis mais granulares dentro de um Bucket. É possível ter milhares de Escopos em um único Bucket, o que permite hospedar milhares de locatários cooperativos (aqueles que não exigem isolamento físico) em um único cluster.
As compensações entre o TCO e os níveis de isolamento entre diferentes arquiteturas multilocatário são capturadas na tabela abaixo.
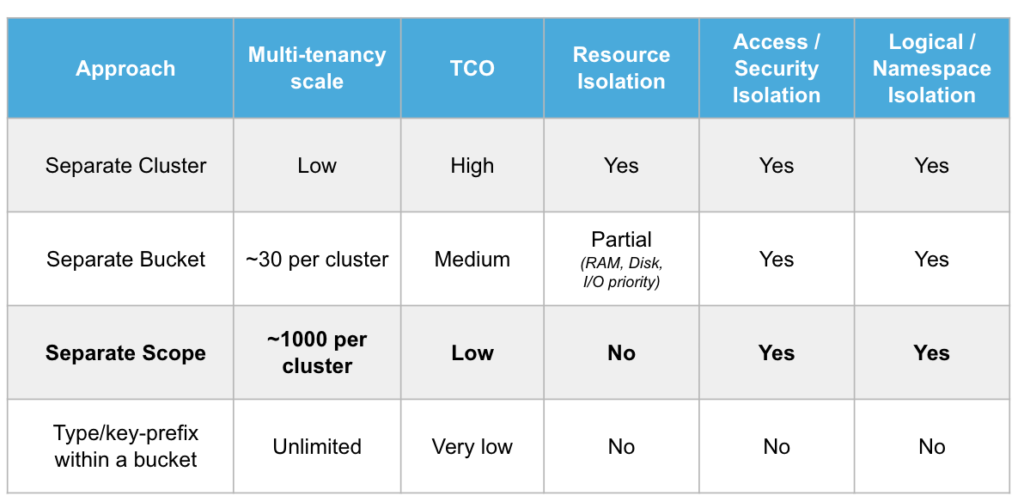
Opções de arquitetura multilocatário usando escopos e coleções do Couchbase
Imagine que os aplicativos de CRM do exemplo acima precisem se tornar multilocatários. Você pode fazer isso facilmente mapeando cada locatário para um escopo separado, conforme mostrado abaixo. (Cust1 e Cust2 são os dois locatários diferentes neste exemplo).
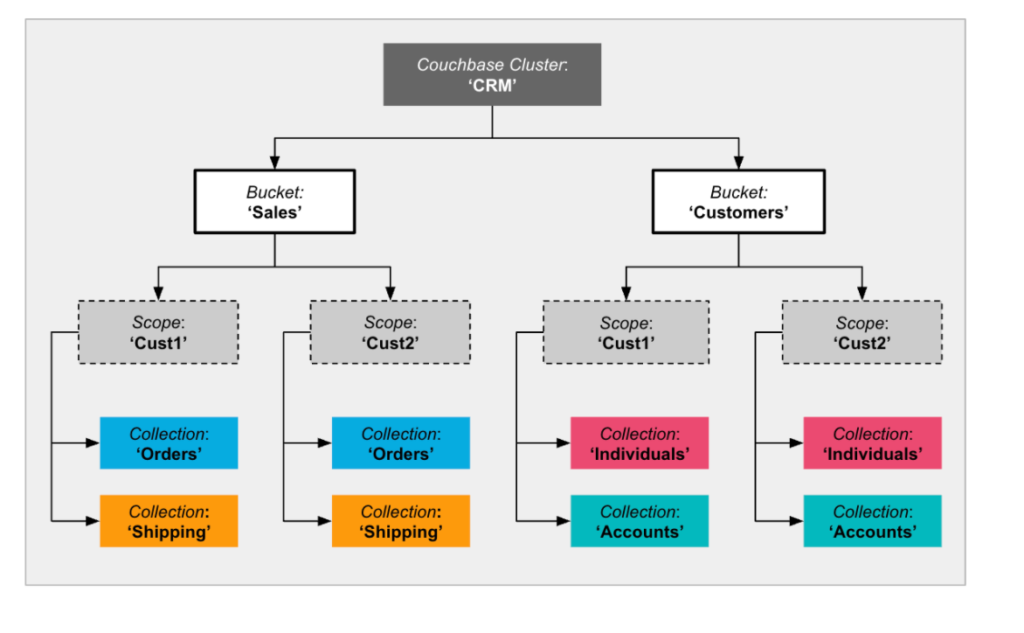
Multitenancy com escopos no Couchbase
A obtenção de multilocação com escopos é bastante simples (sem exigir alterações no aplicativo, pois você pode passar um contexto de escopo). É também uma solução dimensionável e econômica. Os nomes das coleções precisam ser exclusivos apenas em um escopo. Portanto, você pode implementar facilmente vários escopos com os mesmos nomes de coleções, conforme mostrado acima.
Próximas etapas
Espero que você goste da nova funcionalidade Scopes e Collections no Couchbase. Abaixo está uma lista de recursos para você começar e aguardamos seu feedback sobre o Fóruns do Couchbase.
Documentação e artigos
Ótimo artigo... mas gostaria de saber quando o operador do Couchbase para kubernetes estará pronto para ser testado?
@Shivani, o número de escopos é limitado no nível do cluster ou no nível do bucket? Da mesma forma, para a coleção, o número é limitado no nível do escopo ou no nível do cluster.
Se for no nível do cluster, caberá ao aplicativo manter como alocar coleções e escopos em um determinado cluster, o que não me parece correto.
Por favor, confirme.
O número máximo de escopos e de coleções está no nível do cluster. Portanto, se você tiver 2 escopos em um bucket e cada escopo tiver 500 coleções, você terá atingido o limite com um total de 1.000 coleções no cluster.
A estratégia de implementação (seja para um único aplicativo ou para microsserviços e/ou aplicativos SaaS) deve levar em conta esses limites. Os microsserviços e/ou locatários podem ser divididos em vários clusters, é claro.
Obrigado, Shivani, por este e pelo outro artigo sobre como migrar. Ele é muito útil.
Docs (https://docs.couchbase.com/server/current/developer-preview/collections/collections-overview.html) afirmam que o limite é de 1.000 coleções por intervalo. Você pode verificar e, se isso for verdade, corrigir isso e o artigo?
Saudações
Fico feliz que tenha achado os artigos úteis. A página de documentação informa incorretamente que o limite é "1000 por bucket". De fato, são 1.000 coleções por cluster. Vamos corrigir a documentação, obrigado pela observação!
Fico feliz que tenha achado os artigos úteis. A página de documentação informa incorretamente que o limite é "1000 por bucket". De fato, são 1.000 coleções por cluster. Vamos corrigir a documentação, obrigado pela observação!
[...] os destaques do Couchbase 7.0 incluem o aperfeiçoamento do suporte ao processamento de transações ACID; a inclusão de uma nova construção de escopos para adicionar uma aparência relacional ao banco de dados de documentos; e vários desempenhos [...]
[...] os destaques do Couchbase 7.0 incluem o aperfeiçoamento do suporte ao processamento de transações ACID; a inclusão de uma nova construção de escopos para adicionar uma aparência relacional ao banco de dados de documentos; e vários desempenhos [...]
A partir deste artigo, entendo que, com o uso de Bucket, Scope e Collections, o número de microsserviços de diferentes domínios pode ser aumentado.
Mas o artigo começou com o isolamento lógico, isso significa que o Couchbase 7.0 ou a versão anterior suporta o isolamento para outros serviços do couchbase (especialmente o serviço de índice)?
O que quero dizer é que, digamos que todos os domínios de um determinado negócio tenham começado a usar um único cluster do Couchbase, posso controlar e atribuir os recursos do serviço de índice e dos serviços de dados em um nível de bucket?
Os serviços do Couchbase, como o serviço de índice e o serviço de dados (por meio de buckets), sempre permitiram o isolamento de recursos, por exemplo, como você mencionou, é possível controlar os recursos do serviço de índice separadamente do serviço de dados. Esse ainda é o caso e não muda com a versão 7.0.
Com a versão 7.0, o que você tem são dois níveis adicionais em um bucket chamados escopos e coleções. Eles fornecem isolamento lógico e de segurança, mas não isolamento de recursos, pois compartilham os recursos alocados ao bucket. Conforme mencionado, para muitos microsserviços isso é suficiente e, portanto, eles podem ser mapeados para coleções em vez de usar um bucket separado para cada microsserviço.
Eu poderia ter um cluster de 100 ou 1000 nós, então como você explica a restrição rígida de 30 buckets ou uma coleção de 1000? O limite é por nó do couchbase ou por cluster? Alguém pode me explicar?
Você está certo - os limites são os mesmos, quer seu cluster tenha 100 ou 1000 nós. Como você está insinuando, sim, há recursos usados em cada nó para cada coleção e/ou bucket. É por isso que o limite realmente vem do que podemos manipular no nível do nó. O que cada nó pode manipular determina o que o cluster pode manipular, pois cada nó do cluster precisa manter todos os buckets e coleções - o Couchbase distribuiu tudo uniformemente em todos os nós.
Olá, Shivani,
Obrigado por seu artigo.
Estou trabalhando em um recurso para transformar um aplicativo em um aplicativo multilocatário. Todo o sistema tem um backend no Spring Boot 2.5.5 e um aplicativo móvel. O banco de dados é o Couchbase 6.6.
Com o Couchbase 7.0, os escopos e as coleções parecem ser a resposta para muitas das minhas perguntas, mas (sempre há um mas... :)), o Spring Data Couchbase 4.2.5 não é compatível com escopos ou coleções nomeados, nem o SyncGateway 2.8 ou 3.0 (https://docs.couchbase.com/sync-gateway/3.0/server-compatibility-collections.html#using-collections)
Você sabe quando o Spring Data Couchbase 4.3.0 será lançado (a versão 4.3.0-M3 parece funcionar)?
Você sabe quando será lançado um Syncgateway compatível com escopos ou coleções nomeados?
Atenciosamente,
Matthieu
Olá,
Quantos escopos posso criar para um balde?