Qualquer aplicativo da Web moderno que interaja com usuários em diferentes localidades deve lidar com diferentes requisitos de privacidade e diretrizes de consentimento de dados do usuário. Isso pode ser um desafio para qualquer equipe de engenharia, independentemente de a equipe ser apenas você ou cinquenta pessoas.
Como você simplifica o processo para eliminar o incômodo e diminuir a probabilidade de não conformidade?
Neste guia, apresentaremos uma implementação que utiliza os serviços do AWS trabalhando em conjunto com o Couchbase para higienizar os dados antes que eles cheguem a um armazenamento de dados. Essa implementação simplificada pode ser utilizada em qualquer contexto e pode ser expandida para se adequar ao caso de uso que você está criando.
tl;dr Interessado em ver apenas o código junto com um README contendo instruções de implantação? Encontre tudo o que você precisa em GitHub.
Visão geral
Cenário de exemplo
Imagine uma pequena plataforma de comércio eletrônico que vende artesanatos exclusivos e feitos à mão. Esse site opera em um modelo de compra única, o que significa que os usuários não precisam criar contas ou fazer login. Os compradores simplesmente navegam pelo catálogo, selecionam os itens que desejam comprar e prosseguem para o checkout. Durante o processo de finalização da compra, eles fornecem informações essenciais, como nome completo, endereço para correspondência, endereço de cobrança, informações de pagamento, número de telefone e endereço de e-mail. Essas informações de identificação pessoal (PII) são necessárias para concluir a compra e garantir que o item seja enviado para o endereço correto.
Depois que o pedido é feito, os dados trafegam por vários microsserviços. O serviço de processamento de pedidos valida os detalhes e verifica o estoque, o serviço de pagamento trata com segurança as informações de faturamento para processar as transações e o serviço de remessa usa o endereço de correspondência fornecido para providenciar a entrega.
O site foi projetado para oferecer aos usuários uma experiência de compra fácil e contínua. Não há contas. Não há necessidade de passar por um longo processo de registro. Basta escolher o item a ser comprado, fazer o pagamento com as informações de envio e pronto. No entanto, embora o cliente tenha tido uma experiência de compra sem atritos, os dados pessoais dele não podem ter a mesma experiência sem atritos em seu aplicativo. Para manter a privacidade e estar em conformidade com as normas, esses dados de identificação pessoal devem ser higienizados antes de serem armazenados no banco de dados do histórico de compras de longo prazo.
Embora esse cenário possa parecer único, na verdade é uma situação que pode ocorrer em nossos aplicativos o tempo todo. Todo aplicativo que coleta qualquer aspecto das informações de um usuário deve garantir um consentimento rigoroso e estar em conformidade com as leis e os regulamentos de cada localidade em que opera em todo o mundo. Isso pode ser um desafio enorme, que acarreta graves ramificações se não for feito corretamente.
Fluxo de trabalho da solução
Para lidar efetivamente com os requisitos de privacidade para dados em tempo real, precisaremos aproveitar os recursos de dados em tempo real do AWS e do Couchbase para transformar os dados assim que forem criados. É legalmente desafiador armazenar dados privados, mesmo que por um momento, em um banco de dados, de acordo com as normas do GDPR. Dessa forma, não só é uma boa prática de dados adicionar os dados somente depois de terem sido higienizados, como também pode ser um requisito legal.
A solução que estamos criando aproveitará o AWS Simple Queue Service (SQS), o Elastic Container Registry (ECR) e uma função Lambda trabalhando em parceria com o Couchbase Capella, o banco de dados como serviço (DBaaS) totalmente gerenciado. Esse fluxo de trabalho pode ser implementado com qualquer remetente de mensagem para o serviço de fila, que iniciará o processo de sanitização de dados. Em outras palavras, ele é compatível com plug and play.
O fluxo de trabalho a seguir demonstra visualmente como a solução funciona.
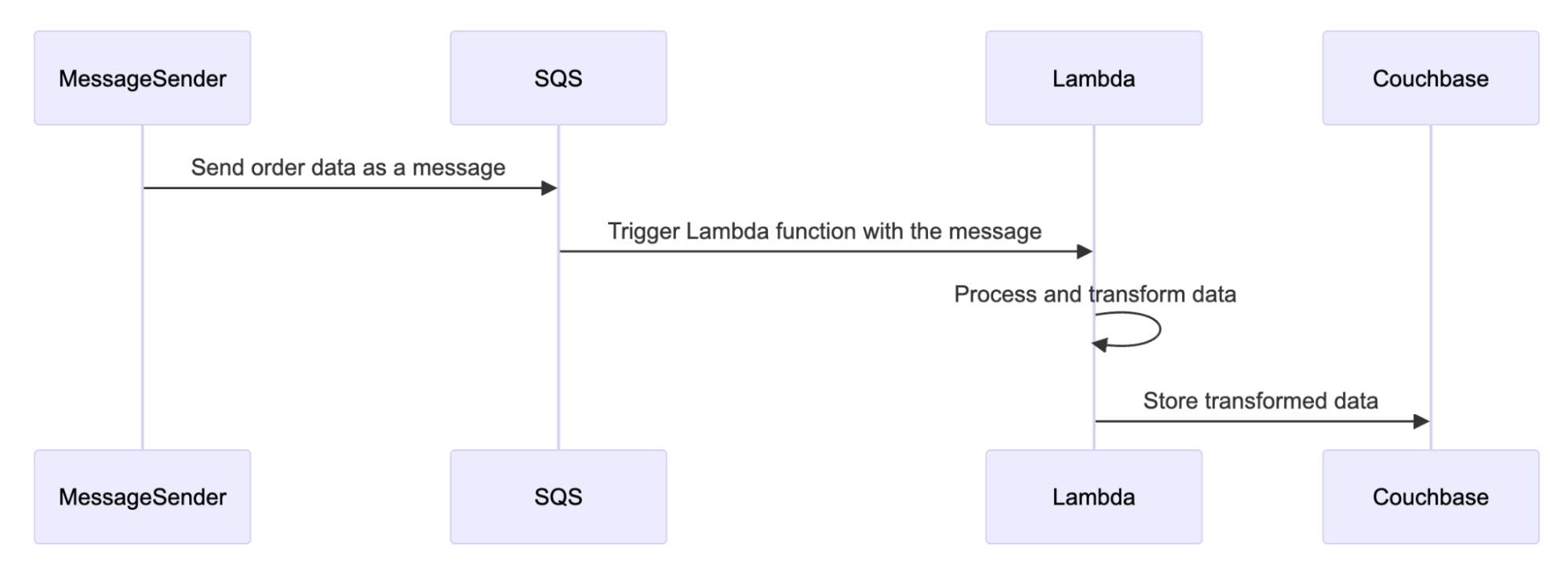
Primeiro, qualquer remetente de mensagem envia dados para o serviço de fila. Isso aciona a função Lambda com a mensagem. A função Lambda processa e transforma os dados removendo todas as PII da mensagem. Por fim, os dados higienizados são enviados ao Couchbase para serem adicionados com segurança ao armazenamento de dados.
Agora que entendemos o fluxo de trabalho, vamos criá-lo!
Implementação
Configuração do Couchbase Capella
É gratuito se inscrever e experimentar o Couchbase Capella e, se você ainda não o fez, pode fazê-lo navegando até cloud.couchbase.com e criando uma conta usando suas credenciais do GitHub ou do Google, ou criando uma nova conta com uma combinação de endereço de e-mail e senha.
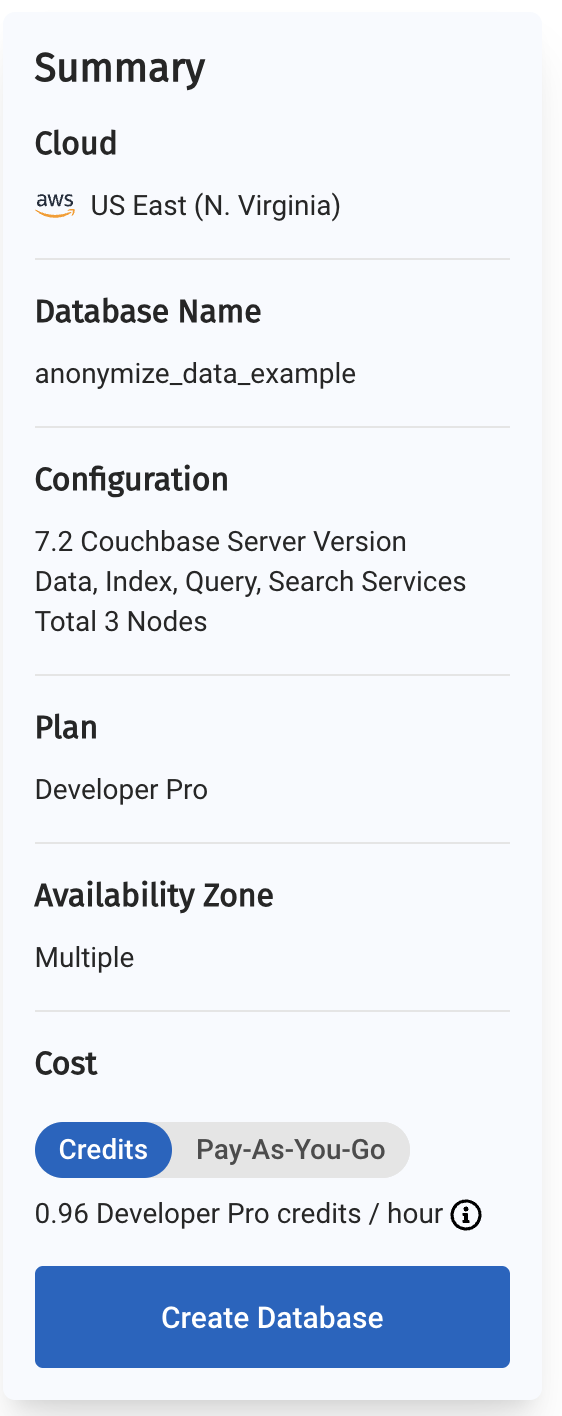 Depois de fazer isso, no painel do Capella, você criará seu primeiro banco de dados. Para fins deste passo a passo, vamos chamá-lo de anonymize_data_example (exemplo de dados anônimos).
Depois de fazer isso, no painel do Capella, você criará seu primeiro banco de dados. Para fins deste passo a passo, vamos chamá-lo de anonymize_data_example (exemplo de dados anônimos).
O resumo de seu novo banco de dados será apresentado no lado esquerdo do painel. O Capella é multinuvem e pode funcionar com AWS, Google Cloud ou Azure. Para este exemplo, você fará a implementação no AWS.
Depois de criar o banco de dados, você precisa criar um arquivo balde. A balde no Couchbase é o contêiner onde os dados são armazenados. Cada item de dados, conhecido como documentoé mantido em JSON, o que torna sua sintaxe familiar para a maioria dos desenvolvedores. Você pode dar o nome que quiser ao seu bucket. No entanto, para fins deste passo a passo, vamos nomear esse bucket como exemplo de dados anônimos.
Agora que você criou o banco de dados e o bucket, está pronto para criar as credenciais de acesso ao banco de dados e obter o URL de conexão que será usado na função Lambda.
Navegue até a seção Conectar no painel do Capella e observe a seção Cadeia de conexão.
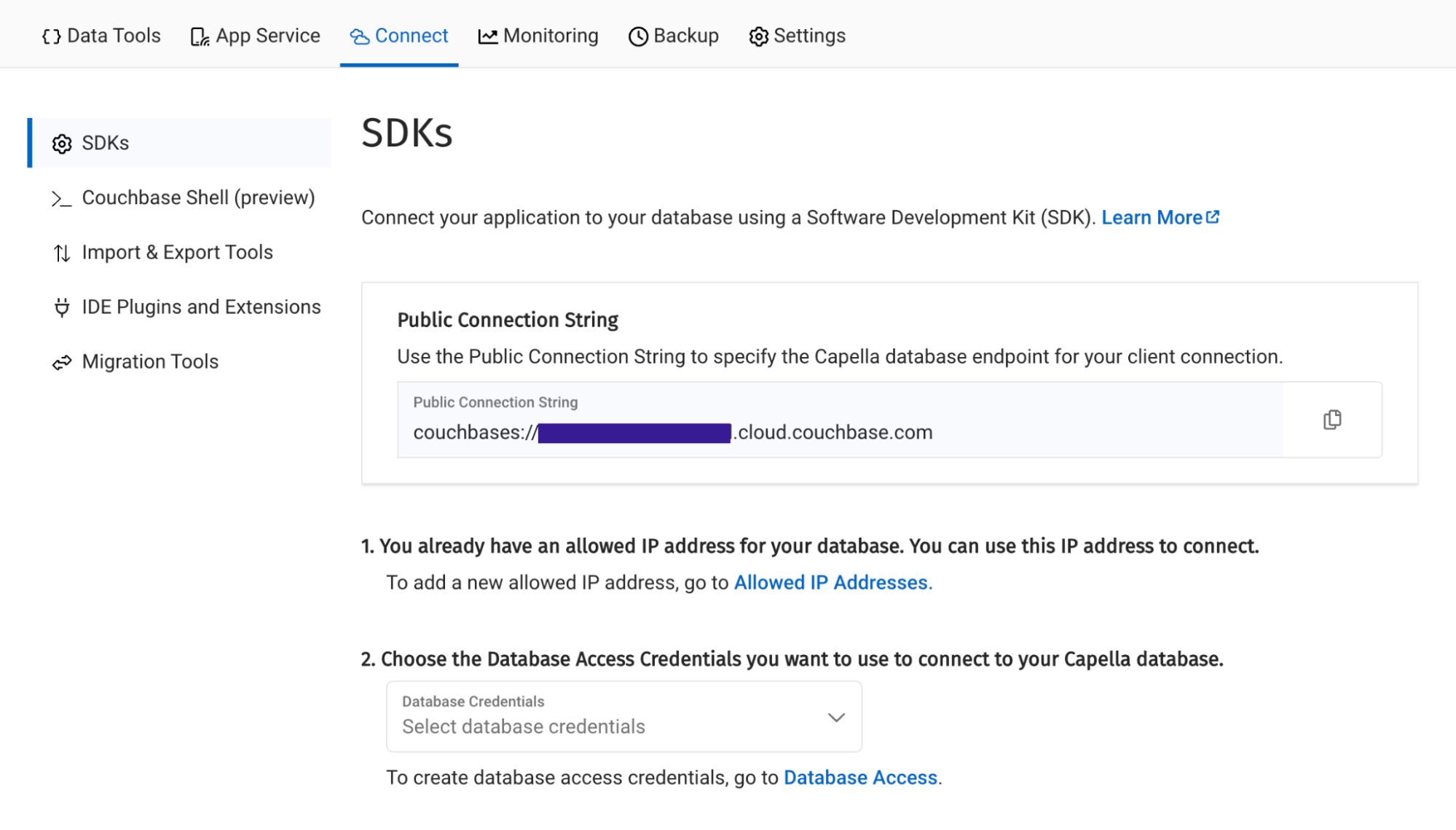
Em seguida, clique no botão Acesso ao banco de dados na seção dois. Nessa seção, você criará credenciais - um nome de usuário e uma senha - que a função Lambda usará para se autenticar no banco de dados. É possível definir o escopo das credenciais para o bucket específico que você criou ou conceder permissão para todos os buckets e bancos de dados da sua conta. De qualquer forma, você precisa garantir que ela tenha acesso de leitura e gravação.
Nesse ponto, você está pronto para criar a função Lambda que será chamada sempre que uma mensagem for recebida pelo serviço de fila.
Criação da função Lambda
Cada aplicativo terá diferentes PII que poderá coletar e, dependendo das localidades em que o aplicativo estiver operando, também poderá ter diferentes requisitos sobre o que deve ser removido antes de salvar os dados. Neste exemplo, removeremos o endereço IP e o sobrenome de cada mensagem antes de enviá-la ao Couchbase.
A função para higienizar os dados é bastante simples:
|
1 2 3 4 5 |
function anonymizeData(data) { data.user.last_name = ''; delete data.user.ip_address; return data; } |
Essa função, anonymizeData (dados anônimos)será invocado no manipulador do código. Se você não estiver familiarizado com um manipulador é usada pelo AWS Lambda para processar as mensagens recebidas da fila SQS, transformar os dados e armazená-los no Couchbase. Seu código executável principal deve começar com um exports.handler.
O manipulador obtém as credenciais do Couchbase e a string de conexão das variáveis de ambiente definidas na configuração da função Lambda. Instruções detalhadas sobre a configuração de variáveis de ambiente para uma função Lambda podem ser encontradas na seção Documentação da AWS. Em seguida, a função analisa a mensagem recebida do SQS e chama a função anonymizeData (dados anônimos) nele. Por fim, ele inserções superiores os dados no bucket do Couchbase.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
exports.handler = async (event) => { console.log('Starting Lambda function'); if (!event.Records || !Array.isArray(event.Records)) { throw new TypeError('event.Records is not iterable'); } const connectionString = process.env.COUCHBASE_CONNECTION_STRING; const username = process.env.COUCHBASE_USERNAME; const password = process.env.COUCHBASE_PASSWORD; const bucketName = process.env.COUCHBASE_BUCKET_NAME; try { const cluster = await couchbase.connect(connectionString, { username: username, password: password }); console.log('Connected to Couchbase cluster'); const bucket = cluster.bucket(bucketName); const collection = bucket.defaultCollection(); for (const record of event.Records) { console.log('Processing record:', record); const payload = JSON.parse(record.body); const transformedData = anonymizeData(payload); console.log('Transformed data:', transformedData); await collection.upsert(transformedData.record_id, transformedData); console.log('Data upserted:', transformedData.record_id); } } catch (error) { console.error('Error during processing:', error); throw error; } }; |
Para configurar a função Lambda usando a CLI do AWS, você precisa criar uma nova função Lambda e especificar a função IAM e o manipulador necessários. Veja como você pode fazer isso:
|
1 2 3 4 |
aws lambda create-function --function-name AnonymizeDataExampleFunction \ --package-type Image \ --code ImageUri=<your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest \ --role arn:aws:iam::<your-account-id>:role/<your-lambda-execution-role> |
Certifique-se de substituir <your-account-id>, <your-region>e <your-lambda-execution-role> com o ID da sua conta AWS real, a região e o ARN da função IAM que você criou para a função Lambda. Esse comando configura a função Lambda para usar a imagem do Docker que você publicará no AWS ECR.
A função Lambda agora está pronta para ser empacotada em uma imagem do Docker e publicada no serviço AWS ECR.
Implementação da imagem do Docker no ECR
Para implantar a imagem do Docker no AWS ECR, começamos criando a imagem do Docker para a plataforma linux/amd64. Isso garante a compatibilidade com a arquitetura x86_64 da nossa função Lambda. Usamos um Dockerfile que instala as ferramentas e dependências necessárias, define o diretório de trabalho, copia os arquivos necessários, instala as dependências e copia o código da função Lambda. A função Dockerfile também especifica o comando para executar a função Lambda.
Aqui está o Dockerfile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
FROM public.ecr.aws/lambda/nodejs:18 # Install necessary tools and dependencies RUN yum -y install gcc-c++ tar gzip findutils # Set the working directory WORKDIR /var/task # Copy package.json and package-lock.json COPY package*.json ./ # Install dependencies RUN npm install # Copy the function code COPY index.js ./ # Command to run the Lambda function CMD [ "index.handler" ] |
Quando o Dockerfile estiver pronto, criamos a imagem do Docker com a plataforma especificada:
|
1 |
docker build --platform linux/amd64 -t anonymize_data_example_image . |
Depois de criar a imagem, nós a marcamos adequadamente para o repositório AWS ECR:
|
1 |
docker tag anonymize_data_example_image:latest <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Para enviar a imagem do Docker para o ECR, primeiro fazemos login no registro do ECR usando a CLI do AWS para obter as credenciais de login:
|
1 |
aws ecr get-login-password --region <your-region> | docker login --username AWS --password-stdin <your-account-id>.dkr.ecr.<your-region>.amazonaws.com |
Com as credenciais instaladas, enviamos a imagem do Docker para o repositório ECR:
|
1 |
docker push <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Por fim, atualizamos a função Lambda chamada AnonymizeDataExampleFunction (Função de exemplo de dados anônimos) para usar a nova imagem do Docker do ECR. Isso envolve especificar o URI da imagem e garantir que a função Lambda esteja configurada para executar o código da nova imagem do Docker enviada:
|
1 |
aws lambda update-function-code --function-name AnonymizeDataExampleFunction --image-uri <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Ao seguir essas etapas, a imagem do Docker é implantada com êxito no AWS ECR e a função Lambda é atualizada para usar a nova imagem, permitindo que o aplicativo higienize as PII antes de armazená-las no Couchbase. Essa configuração garante que o processamento de dados esteja em conformidade com os requisitos de privacidade e, ao mesmo tempo, aproveite o poder do AWS e do Couchbase.
Configuração do serviço SQS
Para facilitar o fluxo de dados entre o remetente da mensagem e a função Lambda, precisamos configurar uma fila do Amazon SQS. A fila do SQS funcionará como um buffer que recebe e armazena mensagens até que sejam processadas pela função Lambda. Veja como você pode configurar uma fila SQS e torná-la um acionador para a função Lambda usando a CLI do AWS.
Primeiro, crie uma nova fila SQS. Essa fila receberá mensagens contendo dados do usuário do remetente da mensagem, que é o aplicativo.
|
1 |
aws sqs create-queue --queue-name AnonymizeDataExampleQueue |
Depois de criar a fila, você receberá um URL para a fila. Esse URL é necessário para enviar mensagens para a fila e configurá-la como um acionador para a função Lambda.
Em seguida, precisamos obter o ARN da fila do SQS, que é necessário para configurar permissões e acionadores. Use o comando a seguir para recuperar o ARN:
|
1 |
aws sqs get-queue-attributes --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --attribute-names QueueArn |
Substituir <your-region> e <your-account-id> com sua região real da AWS e ID da conta.
A saída incluirá o FilaArnque é mais ou menos assim:
|
1 2 3 4 5 |
{ "Attributes": { "QueueArn": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } } |
Agora, precisamos conceder permissão à função Lambda para ler mensagens da fila do SQS. Crie um arquivo de política chamado lambda-sqs-policy.json com o seguinte conteúdo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sqs:ReceiveMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:DeleteMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:GetQueueAttributes", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } ] } |
Aplique essa política à função de execução do Lambda:
|
1 |
aws iam put-role-policy --role-name <your-lambda-execution-role> --policy-name LambdaSQSPolicy --policy-document file://lambda-sqs-policy.json |
Em seguida, adicione a fila SQS como um acionador para a função Lambda:
|
1 |
aws lambda create-event-source-mapping --function-name AnonymizeDataExampleFunction --batch-size 10 --event-source-arn arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue |
Esse comando configura a função Lambda para ser acionada por mensagens que chegam à fila do SQS.
Agora, sua função Lambda está configurada para receber todas as mensagens enviadas para o serviço de fila. O fluxo de trabalho está completo! Essa configuração garante o manuseio eficiente dos dados do usuário e, ao mesmo tempo, mantém a conformidade com os requisitos de privacidade.
Teste a implementação localmente
Para garantir que tudo funcione conforme o esperado, você mesmo pode testar o fluxo de trabalho enviando uma mensagem diretamente para a fila. Na linha de comando, execute o seguinte:
|
1 |
aws sqs send-message --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --message-body "{\"record_id\": \"purchase_002\", \"item\": \"item_1\", \"user\": {\"first_name\": \"John\", \"last_name\": \"Doe\", \"ip_address\": \"192.168.1.1\"}, \"timestamp\": \"2024-07-01T12:34:56Z\"}" |
A mensagem acionará a função Lambda, que, por sua vez, adicionará os dados ao seu bucket do Couchbase depois de higienizá-los. Você pode visualizar os dados de amostra enviados na mensagem fazendo login no painel do Capella ou em seu VSCode ou Jetbrains IDE diretamente, usando suas respectivas extensões do Couchbase.
Concluindo
O trabalho de criar, implantar e manter qualquer aplicativo moderno atualmente é uma tarefa enorme. Na medida do possível, as partes dessa tarefa que não estão diretamente relacionadas ao negócio principal do aplicativo devem ser simplificadas e abstraídas para reduzir a carga cognitiva dos engenheiros, dos SREs e de todos os envolvidos. As normas de privacidade são um item importante que deve ser rigorosamente cumprido e também não deve causar grandes dores de cabeça nem aumentar a carga de trabalho.
A criação de um fluxo de trabalho automatizado do tipo plug and play que possa ser facilmente instalado entre qualquer aplicativo que interaja com informações de identificação pessoal e o banco de dados no qual os dados estão armazenados aliviará significativamente a carga cognitiva, reduzirá a carga e simplificará o processo de desenvolvimento. Com o aproveitamento conjunto do AWS e do Couchbase, você pode tornar isso possível para as suas necessidades de sanitização de dados em tempo real, garantindo assim a integridade do usuário e a produtividade da engenharia.
