Histórico:
Como o Google faz isso? Quando você pesquisa algo ou alguma coisa no Google, ele lhe devolve os principais resultados relevantes e informa um número aproximado de documentos para o seu tópico - tudo em menos de um segundo. Aqui estão algumas dicas de alto nível: https://www.google.com/search/howsearchworks/algorithms/
Os aplicativos corporativos têm a mesma necessidade, embora com critérios mais complexos de pesquisa, busca, classificação e paginação.
Vamos dar uma olhada no comportamento de paginação do Google para entender os recursos básicos de paginação. Em seguida, discutiremos a implementação da paginação em um aplicativo corporativo, passo a passo.
Paginação do Google:
Pesquise no Google por "N1QL".
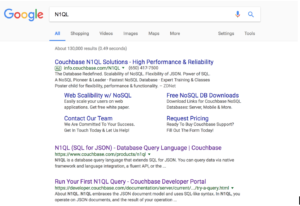
A página que você recebe de volta, o resultado da pesquisa, tem as seguintes informações.
- Número de páginas correspondidas: 130,000
- A pesquisa foi executada em 0,49 segundos
- A página inclui anúncios. Nesse caso, um anúncio do Couchbase. Naturalmente.
- A primeira página do conjunto de resultados: Links para 12 páginas e algumas linhas de cada página.
- Pesquisa relacionada a "N1QL". Algumas sugestões relacionadas às pesquisas
- Links para as próximas 10 páginas de resultados e o link para a PRÓXIMA página.
Paginação do banco de dados
A tarefa da paginação é recuperar e mostrar subconjunto do conjunto de resultados. O subconjunto é determinado pela especificação de paginação (quantas linhas por página) e pela ordem de classificação da consulta emitida pelo aplicativo. Em paginação do banco de dadosQuando o banco de dados é usado, o aplicativo tenta explorar as características e otimizações fornecidas pelo gerenciamento do banco de dados.
Vamos dar uma olhada em cada um dos recursos de paginação que vimos no Google e explorar como você pode implementar e otimizar as consultas no Couchbase.
Nas seções a seguir, vamos nos concentrar na paginação do banco de dados usando o Couchbase.
- Contagem dos resultados totais
- Obtenção do tempo necessário para a execução da consulta
- Obtenção da primeira página
- Criação de links para a próxima página e para outras páginas
- Buscar a página seguinte ou qualquer outra página.
Não abordaremos a seleção de anúncios do Google nem as sugestões de pesquisas relacionadas. Esses são tópicos distintos por si mesmos.
Observe que este artigo usa novos recursos como agrupamento de índices (especificação ASC e DESC para cada chave de índice), pushdown de deslocamento e outras otimizações no Couchbase 5.0.
Seção 1. Contagem dos resultados totais
O Google retornou o seguinte:
Cerca de 130.000 resultados (0,49 segundos)
COUNT: Número estimado de páginas 130.000
TEMPO: Tempo que levou para fazer a pesquisa. Nesse caso, 0,49 segundos
Na paginação do banco de dados, ambos podem ser úteis.
COUNT é útil para determinar o número de links seguintes e anteriores que você precisa gerar ao renderizar os resultados na interface do usuário. Sua consulta de paginação em si pode não retornar o número total de resultados porque o otimizador tentará usar os índices e outras técnicas para limitar o número de processos de documentos. Isso impedirá que a consulta saiba o número total possível de documentos no conjunto de resultados.
Se a consulta tiver ORDER BY, ela poderá sortCount em alguns casos. Isso informa o número total de documentos que classificamos, mesmo que retornemos apenas um documento.
Quando a consulta explora a ordenação de índices para evitar que a classificação avalie uma cláusula ORDER BY, o sortCount não está disponível.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
cbq> select * from `travel-sample` where faa > "4AB" ORDER BY airportname OFFSET 1 LIMIT 1; { "requestID": "709fe2fb-d124-4b0c-b2b4-1c235d3c6f12", "signature": { "*": "*" }, "results": [ { "travel-sample": { "airportname": "Abilene Rgnl", "city": "Abilene", "country": "United States", "faa": "ABI", "geo": { "alt": 1791, "lat": 32.411319, "lon": -99.681897 }, "icao": "KABI", "id": 3718, "type": "airport", "tz": "America/Chicago" } } ], "status": "success", "metrics": { "elapsedTime": "40.111996ms", "executionTime": "40.087977ms", "resultCount": 1, "resultSize": 500, "sortCount": 1659 } } |
Essa consulta abaixo explora o índice no campo faa para obter os dados em ordem ordenada e empurra a cláusula de paginação (OFFSET 50 LIMIT 10) para a varredura do índice. Portanto, sortCount está faltando no conjunto de resultados.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
cbq> select * from `travel-sample` where faa > "4AB" ORDER BY faa OFFSET 50 LIMIT 10; { "requestID": "5bc38dd1-7285-41a5-80e3-0f1da23df178", "signature": { "*": "*" }, "results": [ { "travel-sample": { "airportname": "Andrews Afb", "city": "Camp Springs", "country": "United States", "faa": "ADW", "geo": { "alt": 280, "lat": 38.810806, "lon": -76.867028 }, "icao": "KADW", "id": 3552, "type": "airport", "tz": "America/New_York" } }, ... "status": "success", "metrics": { "elapsedTime": "4.167044ms", "executionTime": "4.143152ms", "resultCount": 10, "resultSize": 5033 } } |
Nesses casos, você pode usar uma varredura de índice de cobertura e simplesmente obter o COUNT() de documentos qualificados. O método IndexCountScan2 (ou IndexCountScan anterior à versão 5.0) simplesmente faz a varredura do índice e conta o número de documentos qualificados, evitando toda a transferência de dados do indexador para o mecanismo de consulta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
cbq> SELECT COUNT(faa) FROM `travel-sample` where faa > "4AB"; { "requestID": "78a3aeae-4dd1-468c-a01c-38610fd87cf4", "signature": { "$1": "number" }, "results": [ { "$1": 1659 } ], "status": "success", "metrics": { "elapsedTime": "2.945555ms", "executionTime": "2.920307ms", "resultCount": 1, "resultSize": 34 } } |
Aqui está o plano de consulta para essa consulta para obter COUNT.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
cbq> EXPLAIN SELECT COUNT(faa) FROM `travel-sample` where faa > "4AB"; { "#operator": "IndexCountScan2", "covers": [ "cover ((`travel-sample`.`faa`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "def_faa", "index_id": "460bd5dad1c6c95d", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "\"4AB\"" } ] } |
Seção 2. Prazos e outras métricas
Cada resultado de consulta tem as métricas básicas sobre a execução da consulta.
|
1 2 3 4 5 6 7 |
"metrics": { "elapsedTime": "40.111996ms", "executionTime": "40.087977ms", "resultCount": 1, "resultSize": 500, "sortCount": 1659 } |
tempo decorrido é a duração do tempo de relógio que o servidor gastou após receber a consulta. Isso inclui qualquer tempo de espera. tempo de execução é estritamente o tempo gasto na execução da consulta. resultCount é o número de documentos retornados. resultSize é o número de bytes no conjunto de resultados. sortCount é o número de documentos classificados antes da paginação.
Se a consulta não incluir OFFSET ou LIMIT, resultCount será o número total de documentos no conjunto de resultados. Quando precisarmos classificar os dados intermediários, como mencionado anteriormente, sortCount estará ausente se não houver nenhuma classificação realizada para avaliar o ORDER BY.
Seção 3. Primeira página do conjunto de resultados
Vamos nos concentrar primeiro na primeira página.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT * FROM `travel-sample` t WHERE type = “hotel” AND country = “United Kingdom” AND ARRAY_LENGTH(public_likes) > 3 ORDER BY ARRAY_LENGTH(public_likes), ratings DESC OFFSET 0 LIMIT 20; CREATE INDEX idx_hotel_ctry_likes ON `travel-sample`(country, ARRAY_LENGTH(public_likes)) WHERE type = “hotel” |
A consulta usando esse índice é executada em cerca de 30 milissegundos.
|
1 2 3 4 5 6 7 8 9 |
"status": "success", "metrics": { "elapsedTime": "30.125957ms", "executionTime": "30.110732ms", "resultCount": 20, "resultSize": 181449, "sortCount": 238 } } |
Esse índice tem os três predicados no índice. Embora o índice faça toda a filtragem, a consulta ainda precisa obter o conjunto completo de resultados, classificá-los e, em seguida, projetar apenas a primeira página. No meu computador, isso é executado em 30 milissegundos. Gostaria de reduzir ainda mais esse tempo para que possamos executar várias consultas simultaneamente.
|
1 2 3 4 |
DROP INDEX `travel-sample`.idx_hotel_ctry_likes; CREATE INDEX idx_hotel_ctry_likes_ratings ON `travel-sample` (country, ARRAY_LENGTH(public_likes), ratings DESC) WHERE type = “hotel” |
Execute a consulta novamente.
|
1 2 3 4 5 6 7 |
"status": "success", "metrics": { "elapsedTime": "9.449025ms", "executionTime": "9.432752ms", "resultCount": 20, "resultSize": 181449 } |
Para essa consulta e esse índice, a explicação mostrará que o LIMIT 20 foi transferido para a varredura do índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ "#operator": "IndexScan2", "index": "idx_hotel_ctry_likes_ratings", "index_id": "f7de95817c4dc84b", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "20", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"United Kingdom\"", "inclusion": 3, "low": "\"United Kingdom\"" }, { "inclusion": 0, "low": "3" } ] } ], |
Essa consulta é executada em menos de 10 milissegundos, evitando a busca e a classificação completas. A maneira mais rápida de classificar é evitar a própria classificação.
Seção 4: Criando os links para a próxima página e para outras páginas

Quando a primeira página é renderizada, o Google também fornece um link para a próxima página e outras 10 páginas subsequentes. Como discutimos na seção 1, a contagem total de resultados potenciais pode ser obtida de várias maneiras. Quando você tiver a contagem, basta criar os links com os respectivos OFFSETs necessários para cada página. Para obter a próxima página, basta definir o OFFSET como 20. Para obter cada página subsequente ou qualquer página aleatória, basta calcular o OFFSET com (page# * o número de documentos em uma página). Obviamente, esse OFFSET deve ser menor que o número total de documentos em potencial no conjunto de resultados. Discutimos como obter essa contagem total na seção 1.
Exemplo:
Primeira página: DESLOCAMENTO 0 LIMITE 20;
Segunda página: DESLOCAMENTO 20 LIMITE 20;
Oito páginas: OFFSET 160 LIMITE 20;
Seção 5: Buscando a próxima página ou qualquer outra página.
Na seção anterior, discutimos a criação dos links com os parâmetros de paginação corretos. Depois de ter a primeira consulta, calcule os OFFSETs para as páginas subsequentes e você terá tudo o que precisa para emitir consultas para todas as consultas subsequentes.
Recupere a segunda página por meio da seguinte consulta:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel-sample` t WHERE type = ‘hotel’ AND country = ‘United Kingdom’ AND ARRAY_LENGTH(public_likes) > 3 ORDER BY ARRAY_LENGTH(public_likes), ratings DESC OFFSET 20 LIMIT 20; |
Você simplesmente obtém cada página subsequente (ou uma página aleatória) alterando o OFFSET.
A partir do Couchbase 5.0, quando o índice pode avaliar o predicado completo e a cláusula ORDER BY, tanto o OFFSET quanto o LIMIT são empurrados para a varredura do índice. Isso tornará a varredura do índice eficiente, retornando apenas o número LIMITADO de linhas depois de ignorar as linhas qualificadas, conforme especificado pelo OFFSET.
Você deverá ver um plano de consulta como o abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "#operator": "IndexScan2", "index": "idx_hotel_ctry_likes_ratings", "index_id": "f7de95817c4dc84b", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "20", "namespace": "default", "offset": "20", "spans": [ { "exact": true, "range": [ { "high": "\"United Kingdom\"", "inclusion": 3, "low": "\"United Kingdom\"" }, { "inclusion": 0, "low": "3" } ] } ], |
Mesmo quando você precisa criar um índice ideal (como nesta consulta), o índice ainda precisa percorrer entradas qualificadas de OFFSET 0 a OFFSET NN para identificar as entradas de índice a serem retornadas. Quando o valor de deslocamento é grande, isso pode ser caro. Quando a consulta não tem um índice apropriado, o processamento de deslocamento é ainda mais caro.
Conclusão
Embora tenhamos otimizado o processamento de consultas N1QL e as varreduras de índices para otimizações, você ainda pode otimizar essas consultas ainda mais quando seus casos de uso forem principalmente "buscar próximo". Esse é um cenário comum e importante. Marks Winand e Lukas Eder discutiram o método de paginação de conjunto de chaves, que melhora ainda mais o desempenho. Seus artigos estão na seção de referência.
No próximo artigo, discutirei a implementação da paginação do conjunto de chaves no Couchbase N1QL.
Referências:
- https://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way
- https://use-the-index-luke.com/sql/partial-results/fetch-next-page
- https://blog.jooq.org/2013/10/26/faster-sql-paging-with-jooq-using-the-seek-method/