Um aplicativo típico de agente de IA em 2025 geralmente envolve:
- Um LLM hospedado na nuvem
- Um banco de dados vetorial para recuperação
- Um banco de dados operacional separado
- Gerenciamento de prompts e ferramentas de gerenciamento de ferramentas
- Estruturas de observabilidade e rastreamento
- Grades de proteção
Cada ferramenta resolve um problema. No entanto, coletivamente, elas podem criar uma expansão arquitetônica com latência imprevisível, custos operacionais crescentes e pontos cegos de governança. Como resultado, muitos agentes de IA nunca passam de demonstrações ou protótipos internos porque a complexidade aumenta muito rapidamente.
Esta postagem explica como migramos um aplicativo de agente de IA existente para o Couchbase AI Services e o Agent Catalog, passando para uma única plataforma de IA pronta para produção.
O problema central: a fragmentação mata a IA de produção
É importante entender por que os sistemas agênticos enfrentam dificuldades na produção. Atualmente, a maioria dos agentes de IA é construída a partir de muitas partes frouxamente acopladas: os prompts vivem em um sistema, os vetores em outro, as conversas são registradas de forma inconsistente, as ferramentas são invocadas sem rastreabilidade clara. - tornando o comportamento do agente difícil de depurar. Ao mesmo tempo, o envio de dados corporativos para endpoints de LLM de terceiros introduz riscos de conformidade e segurança. Por fim, a governança geralmente é tratada como uma reflexão tardia; muitas estruturas enfatizam o que um agente pode fazer, mas não explicam por que ele tomou uma decisão, qual prompt ou ferramenta a influenciou ou se essa decisão deveria ter sido permitida. Essa é uma lacuna inaceitável para fluxos de trabalho comerciais reais.
O que são os serviços de IA do Couchbase?
A criação de aplicativos de IA geralmente envolve a combinação de vários serviços: um banco de dados vetorial para memória, um provedor de inferência para LLMs (como OpenAI ou Anthropic) e uma infraestrutura separada para incorporar modelos.
Serviços de IA do Couchbase simplifica isso fornecendo uma plataforma unificada onde seus dados operacionais, pesquisa vetorial e modelos de IA convivem juntos. Ela oferece:
- API de inferência e incorporação de LLM: Acesse LLMs populares (como o Llama 3) e modelos de incorporação diretamente no Couchbase Capella, sem chaves de API externas, sem infraestrutura extra e sem saída de dados. Os dados de seu aplicativo permanecem dentro do Capella. As consultas, os vetores e a inferência de modelos ocorrem onde os dados residem. Isso permite experiências de IA seguras e de baixa latência, ao mesmo tempo em que atende aos requisitos de privacidade e conformidade. O principal valor: dados e IA juntos, com informações confidenciais mantidas dentro de seu sistema.
- Plataforma unificada: Mantenha seu banco de dados, vetorização, pesquisa e modelo em um local central.
- Pesquisa vetorial integrada: Realize pesquisas semânticas diretamente em seus dados JSON com latência de milissegundos.
Por que isso é necessário?
À medida que passamos de simples chatbots para fluxos de trabalho autênticos - em que os modelos de IA usam ferramentas de forma autônoma - a latência e a complexidade da configuração tornam-se os principais gargalos. O Couchbase AI Services adota uma abordagem que prioriza a plataforma. Ao colocar seus dados e serviços de IA no mesmo local, ele reduz a sobrecarga operacional e a latência. Além disso, ferramentas como o Catálogo de agentes ajudam a gerenciar centenas de prompts e ferramentas de agentes, além de fornecer registro e telemetria incorporados para os agentes.
Nesse ponto, a questão muda de por que uma abordagem que prioriza a plataforma é importante para como ela funciona na prática.
Portanto, vamos explorar como você pode migrar um aplicativo agêntico existente e melhorar seu desempenho, governança e confiabilidade ao longo do caminho.
Como é o aplicativo atual
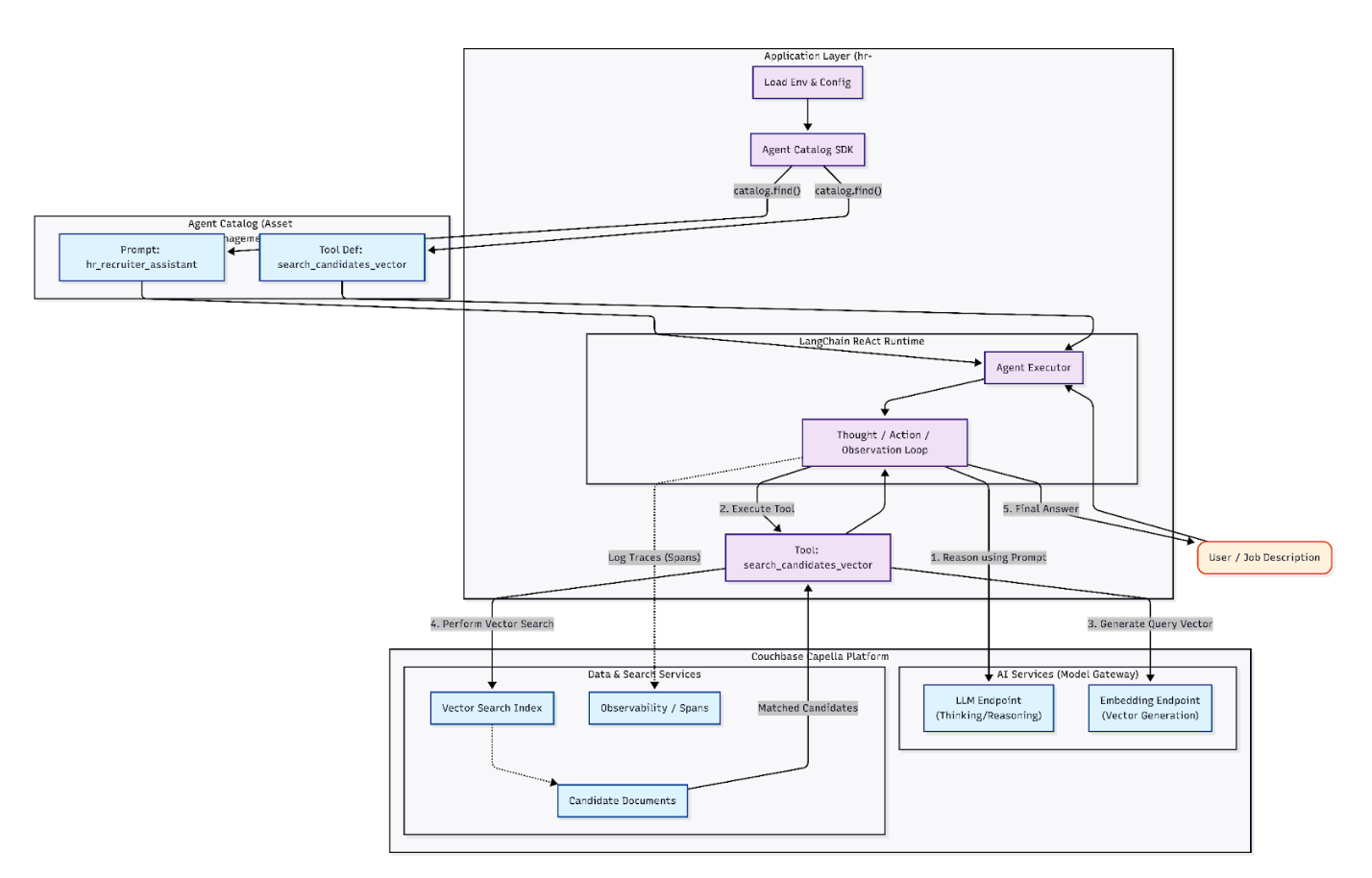
O aplicativo atual é um HR Sourcing Agent projetado para automatizar a triagem inicial de candidatos. A principal função do aplicativo agente é ingerir arquivos de currículos brutos (PDFs), entender o conteúdo dos currículos usando um LLM e estruturar os dados não estruturados em um formato de consulta enriquecido com embeddings semânticos no Couchbase. Ele permite que os profissionais de RH carreguem uma nova descrição de cargo e obtenham resultados para os candidatos mais adequados usando a pesquisa vetorial do Couchbase.
Em seu estado atual, o aplicativo HR Sourcing é um microsserviço baseado em Python que envolve um LLM com o Google ADK. Ele conecta manualmente definições de modelos, solicitações de agentes e pipelines de execução. Embora funcional, a arquitetura exige que o desenvolvedor gerencie o estado da sessão na memória, manipule a lógica de repetição, limpe as saídas brutas do modelo e mantenha a integração entre o LLM e o banco de dados manualmente. Além disso, não há telemetria integrada para o nosso agente.
O aplicativo instancia manualmente um provedor de modelo. Nesse caso específico, ele se conecta a um modelo de código aberto hospedado (Qwen 2.5-72B via Nebius) usando o LiteLLM wrapper. O aplicativo precisa criar manualmente um ambiente de tempo de execução para o agente. Ele inicializa um InMemorySessionService para rastrear o estado da conversa (mesmo que de curta duração) e um Runner para executar a entrada do usuário (o texto de resumo) no pipeline do agente.
Migração do aplicativo agente para os serviços de IA do Couchbase
Agora vamos nos aprofundar em como migrar a lógica central do nosso agente para usar o Couchbase AI Services e o Agent Catalog.
O novo agente usa um agente LangChain ReAct para processar descrições de cargos, realiza a correspondência inteligente de candidatos usando pesquisa vetorial e fornece recomendações de candidatos classificados com explicações.
Pré-requisitos
Antes de começarmos, verifique se você tem:
- Python 3.10+ instalado.
Instalar dependências
Começaremos instalando os pacotes necessários. Isso inclui o pacote agente CLI para o catálogo e os pacotes de integração do LangChain.
|
1 2 3 4 5 6 |
%pip install -q \ "pydantic>=2.0.0,<3.0.0" \ "python-dotenv>=1.0.0,<2.0.0" \ "pandas>=2.0.0,<3.0.0" \ "nest-asyncio>=1.6.0,<2.0.0" \ "langchain-couchbase>=0.2.4,<0.5.0" \ "langchain-openai>=0.3.11,<0.4.0" \ "arize-phoenix>=11.37.0,<12.0.0" \ "openinference-instrumentation-langchain>=0.1.29,<0.2.0" # Install Agent Catalog %pip install agentc==1.0.0 |
Serviço de modelo centralizado (integração de serviços de modelo de IA do Couchbase)
No original adk_resume_agent.py, Na versão anterior, tivemos que instanciar manualmente o LiteLLM, gerenciar chaves de API de provedores específicos (Nebius, OpenAI etc.) e lidar com a lógica de conexão dentro do código do aplicativo. Migraremos o código para usar o Couchbase.
O Couchbase AI Services fornece pontos de extremidade compatíveis com OpenAI que são usados pelos agentes. Para o LLM e os embeddings, usamos o pacote LangChain OpenAI, que se integra diretamente com o conector LangChain Couchbase.
Habilitar serviços de IA
- Navegue até a seção AI Services (Serviços de IA) da Capella na interface do usuário.
- Implemente os modelos Embeddings e LLM.
- Você precisa iniciar uma incorporação e um LLM para essa demonstração na mesma região que o cluster do Capella onde os dados serão armazenados.
- Implante um LLM que tenha recursos de chamada de ferramentas, como mistralai/mistral-7b-instruct-v0.3. Para embeddings, você pode escolher um modelo como o nvidia/llama-3.2-nv-embedqa-1b-v2.
- Anote o URL do endpoint e gere chaves de API.
Para obter mais detalhes sobre o lançamento de modelos de IA, você pode consultar o documentação oficial.
Implementação da lógica de código para LLM e modelos de incorporação
Precisamos configurar os pontos de extremidade do Capella Model Services. Os Capella Model Services são compatíveis com o formato da API OpenAI, portanto, podemos usar o padrão langchain-openai apontando-a para o nosso ponto de extremidade do Capella. Inicializamos o modelo de incorporação com Aberturas do OpenAIEmbeddings e o LLM com ChatOpenAI, mas aponte para Capella.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# Model Services Config CAPELLA_API_ENDPOINT = getpass.getpass("Capella Model Services Endpoint: ") CAPELLA_API_LLM_MODEL = "mistralai/mistral-7b-instruct-v0.3" CAPELLA_API_LLM_KEY = getpass.getpass("LLM API Key: ") CAPELLA_API_EMBEDDING_MODEL = "nvidia/llama-3.2-nv-embedqa-1b-v2" CAPELLA_API_EMBEDDINGS_KEY = getpass.getpass("Embedding API Key: ") def setup_ai_services(temperature: float = 0.0): embeddings = None llm = None if not embeddings and os.getenv("CAPELLA_API_ENDPOINT") and os.getenv("CAPELLA_API_EMBEDDINGS_KEY"): try: endpoint = os.getenv("CAPELLA_API_ENDPOINT") api_key = os.getenv("CAPELLA_API_EMBEDDINGS_KEY") model = os.getenv("CAPELLA_API_EMBEDDING_MODEL", "Snowflake/snowflake-arctic-embed-l-v2.0") api_base = endpoint if endpoint.endswith('/v1') else f"{endpoint}/v1" embeddings = OpenAIEmbeddings( model=model, api_key=api_key, base_url=api_base, check_embedding_ctx_length=False, ) except Exception as e: logger.error(f"Couchbase AI embeddings failed: {e}") if not llm and os.getenv("CAPELLA_API_ENDPOINT") and os.getenv("CAPELLA_API_LLM_KEY"): try: endpoint = os.getenv("CAPELLA_API_ENDPOINT") llm_key = os.getenv("CAPELLA_API_LLM_KEY") llm_model = os.getenv("CAPELLA_API_LLM_MODEL", "deepseek-ai/DeepSeek-R1-Distill-Llama-8B") api_base = endpoint if endpoint.endswith('/v1') else f"{endpoint}/v1" llm = ChatOpenAI( model=llm_model, base_url=api_base, api_key=llm_key, temperature=temperature, ) test_response = llm.invoke("Hello") except Exception as e: logger.error(f"Couchbase AI LLM failed: {e}") llm = None |
Em vez de codificar os provedores de modelos, o agente agora se conecta a um ponto de extremidade Capella unificado, que atua como um gateway de API para o LLM e o modelo de incorporação.
Desacoplamento de prompts e ferramentas com o catálogo de agentes
O Agent Catalog é uma ferramenta avançada para gerenciar o ciclo de vida dos recursos do seu agente. Em vez de codificar prompts e definições de ferramentas em seus arquivos Python, você os gerencia como ativos com versão. É possível centralizar e reutilizar suas ferramentas entre as equipes de desenvolvimento. Também é possível examinar e monitorar as respostas do agente com o Agent Tracer. Esses recursos oferecem visibilidade, controle e rastreabilidade para o desenvolvimento e a implementação de agentes. Suas equipes podem criar agentes com confiança, sabendo que eles podem ser auditados e gerenciados com eficiência.
Sem a capacidade de rastrear o comportamento do agente, torna-se impossível automatizar a confiança, a validação e a corroboração contínuas das decisões autônomas tomadas pelos agentes. No Catálogo de Agentes, isso é feito por meio da avaliação do código do agente e da transcrição da conversa com o LLM para avaliar a adequação da decisão pendente ou da pesquisa da ferramenta MCP.
Portanto, vamos incorporar o Agent Catalog ao projeto.
Adição da ferramenta de pesquisa de vetores
Começaremos adicionando nossa definição de ferramenta para o Catálogo de Agentes. Nesse caso, temos a ferramenta de pesquisa vetorial.
Para adicionar uma nova função Python como uma ferramenta para seu agente, você pode usar o comando add da ferramenta de linha de comando do Catálogo de agentes:
agente adicionar
Se você tiver uma ferramenta Python existente que deseja adicionar ao Catálogo de agentes, adicione agentc às suas importações e o decorador @agentc.catalog.tool à sua definição de ferramenta. Em nosso exemplo, definimos uma função Python para executar a pesquisa vetorial como nossa ferramenta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
""" Vector search tool for finding candidates based on job descriptions. This tool uses Couchbase vector search to find the most relevant candidates. Updated for Agent Catalog v1.0.0 with @tool decorator. """ import os import logging from typing import List, Dict, Any from datetime import timedelta from agentc_core.tool import tool from couchbase.cluster import Cluster from couchbase.auth import PasswordAuthenticator from couchbase.options import ClusterOptions from couchbase.vector_search import VectorQuery, VectorSearch from couchbase.search import SearchRequest, MatchNoneQuery logger = logging.getLogger(__name__) def generate_embedding(text: str, embeddings_client) -> List[float]: """Generate embeddings for text using the provided embeddings client.""" try: # Use the embeddings client to generate embeddings result = embeddings_client.embed_query(text) return result except Exception as e: logger.error(f"Error generating embedding: {e}") return [0.0] * 1024 # Return zero vector as fallback @tool( name="search_candidates_vector", description="Search for candidates using vector similarity based on a job description. Returns matching candidate profiles ranked by relevance.", annotations={"category": "hr", "type": "search"} ) def search_candidates_vector( job_description: str, num_results: int = 5, embeddings_client=None, ) -> str: """ Search for candidates using vector similarity based on job description. Args: job_description: The job description text to search against num_results: Number of top candidates to return (default: 5) embeddings_client: The embeddings client for generating query embeddings Returns: Formatted string with candidate information """ try: # Get environment variables bucket_name = os.getenv("CB_BUCKET", "travel-sample") scope_name = os.getenv("CB_SCOPE", "agentc_data") collection_name = os.getenv("CB_COLLECTION", "candidates") index_name = os.getenv("CB_INDEX", "candidates_index") # Connect to Couchbase cluster = get_cluster_connection() if not cluster: return "Error: Could not connect to database" bucket = cluster.bucket(bucket_name) scope = bucket.scope(scope_name) collection = scope.collection(collection_name) # Use scope.collection(), not bucket.collection() # Generate query embedding logger.info(f"Generating embedding for job description...") if embeddings_client is None: return "Error: Embeddings client not provided" query_embedding = generate_embedding(job_description, embeddings_client) # Perform vector search logger.info(f"Performing vector search with index: {index_name}") search_req = SearchRequest.create(MatchNoneQuery()).with_vector_search( VectorSearch.from_vector_query( VectorQuery("embedding", query_embedding, num_candidates=num_results * 2) ) ) result = scope.search(index_name, search_req, timeout=timedelta(seconds=20)) rows = list(result.rows()) if not rows: return "No candidates found matching the job description." # Fetch candidate details candidates = [] for row in rows[:num_results]: try: doc = collection.get(row.id, timeout=timedelta(seconds=5)) if doc and doc.value: data = doc.value data["_id"] = row.id data["_score"] = row.score candidates.append(data) except Exception as e: logger.warning(f"Error fetching candidate {row.id}: {e}") continue # Format results if not candidates: return "No candidate details could be retrieved." result_text = f"Found {len(candidates)} matching candidates:\n\n" for i, candidate in enumerate(candidates, 1): result_text += f"**Candidate {i}: {candidate.get('name', 'Unknown')}**\n" result_text += f"- Match Score: {candidate.get('_score', 0):.4f}\n" result_text += f"- Email: {candidate.get('email', 'N/A')}\n" result_text += f"- Location: {candidate.get('location', 'N/A')}\n" result_text += f"- Years of Experience: {candidate.get('years_experience', 0)}\n" skills = candidate.get('skills', []) if skills: result_text += f"- Skills: {', '.join(skills[:10])}\n" technical_skills = candidate.get('technical_skills', []) if technical_skills: result_text += f"- Technical Skills: {', '.join(technical_skills[:10])}\n" summary = candidate.get('summary', '') if summary: # Truncate summary if too long summary_text = summary[:200] + "..." if len(summary) > 200 else summary result_text += f"- Summary: {summary_text}\n" result_text += "\n" return result_text except Exception as e: logger.error(f"Error in vector search: {e}") import traceback traceback.print_exc() return f"Error performing candidate search: {str(e)}" |
Adicionando os prompts
Na arquitetura original, as instruções do agente ficavam enterradas no código Python como grandes variáveis de cadeia de caracteres, o que dificultava a versão ou a atualização sem uma implantação completa. Com o Agent Catalog, agora definimos nossa persona “HR Recruiter” como um ativo autônomo e gerenciado usando prompts. Usando uma definição YAML estruturada (record_kind: prompt), criamos o hr_recruiter_assistant. Essa definição não contém apenas o texto; ela encapsula todo o comportamento do agente, definindo estritamente o padrão ReAct (Pensamento → Ação → Observação) que orienta o LLM a usar a ferramenta de pesquisa vetorial de forma eficaz.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
record_kind: prompt name: hr_recruiter_assistant description: AI-powered HR recruiter assistant that helps match candidates to job descriptions using vector search annotations: category: hr type: recruitment content: | You are an expert HR recruiter assistant with deep knowledge of talent acquisition and candidate matching. Your role is to help HR professionals find the best candidates for job openings by analyzing job descriptions and searching through a database of candidate profiles. You have access to the following tools: {tools} Use the following format for your responses: Question: the input question or job description you must analyze Thought: think about what information you need to find the best candidates Action: the action to take, should be one of [{tool_names}] Action Input: the input to the action (for candidate search, provide the job description text) Observation: the result of the action ... (this Thought/Action/Action Input/Observation can repeat N times) Thought: I now have enough information to provide recommendations Final Answer: Provide a comprehensive summary of the top candidates including: - Candidate names and key qualifications - Skills match percentage and relevance - Years of experience - Why each candidate is a good fit for the role - Any notable strengths or unique qualifications IMPORTANT GUIDELINES: - Always use the search_candidates_vector tool to find candidates - Analyze the job description to understand required skills and experience - Provide detailed reasoning for candidate recommendations - Highlight both technical skills and soft skills when relevant - Be specific about match percentages and scores - Format your final answer in a clear, professional manner Begin! Question: {input} Thought: {agent_scratchpad} |
Indexação e publicação dos arquivos locais
Usamos agente para indexar nossos arquivos locais e publicá-los no Couchbase. Isso armazena os metadados no banco de dados, tornando-os pesquisáveis e detectáveis pelo agente em tempo de execução.
|
1 2 3 4 5 |
# Create local index of tools and prompts agentc index . # Upload to Couchbase agentc publish |
Em nosso código, inicializamos o Catalog e usamos catalog.find() para recuperar prompts e ferramentas verificados. Não codificamos mais os prompts; em vez disso, nós os buscamos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# BEFORE: Hardcoded Prompt Strings # parse_instruction = "You are a resume parsing assistant..." import agentc from agentc import Catalog, Span # AFTER: Dynamic Asset Loading catalog = Catalog() # Load the "search" tool dynamically tool_result = catalog.find("tool", name="search_candidates_vector") # Load the "recruiter" persona dynamically prompt_result = catalog.find("prompt", name="hr_recruiter_assistant") # We act on the retrieved metadata tools = [Tool(name=tool_result.meta.name, func=...)] |
Mecanismo de raciocínio padronizado (integração LangChain)
O aplicativo anterior usava um pipeline SequentialAgent personalizado. Embora flexível, isso significava que tínhamos de manter nossos próprios loops de execução, tratamento de erros e lógica de repetição para as etapas de raciocínio do agente.
Aproveitando a compatibilidade do Agent Catalog com o LangChain, mudamos para uma arquitetura de agente ReAct (Reason + Act) padrão. Simplesmente alimentamos as ferramentas e os prompts obtidos do catálogo diretamente em create_react_agent.
Qual é o benefício? Obtemos loops de raciocínio padrão do setor - Pensamento -> Ação -> Observação - fora da caixa. Agora, o agente pode decidir de forma autônoma pesquisar “Desenvolvedores React”, analisar os resultados e, em seguida, realizar uma segunda pesquisa por “Engenheiros de front-end” se a primeira produzir poucos resultados, algo com que o pipeline linear do ADK tinha dificuldades.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
def create_langchain_agent(self, catalog: Catalog, embeddings, llm): try: # Load tools from catalog using v1.0.0 API tool_result = catalog.find("tool", name="search_candidates_vector") # Create tool wrapper that injects embeddings client def search_with_embeddings(job_description: str) -> str: return tool_result.func( job_description=job_description, num_results=5, embeddings_client=embeddings, ) tools = [ Tool( name=tool_result.meta.name, description=tool_result.meta.description, func=search_with_embeddings, ), ] # Load prompt from catalog using v1.0.0 API prompt_result = catalog.find("prompt", name="hr_recruiter_assistant") if prompt_result is None: raise ValueError("Could not find hr_recruiter_assistant prompt in catalog. Run 'agentc index' first.") custom_prompt = PromptTemplate( template=prompt_result.content.strip(), input_variables=["input", "agent_scratchpad"], partial_variables={ "tools": "\n".join([f"{tool.name}: {tool.description}" for tool in tools]), "tool_names": ", ".join([tool.name for tool in tools]), }, ) # Create agent agent = create_react_agent(llm, tools, custom_prompt) agent_executor = AgentExecutor( agent=agent, tools=tools, verbose=True, handle_parsing_errors=handle_parsing_error, max_iterations=5, max_execution_time=120, early_stopping_method="force", return_intermediate_steps=True, ) logger.info("LangChain ReAct agent created successfully") return agent_executor |
Observabilidade integrada (rastreamento de agentes)
No aplicativo de agente anterior, a observabilidade era limitada às instruções print(). Não havia nenhuma maneira de “reproduzir” a sessão de um agente para entender por que ele rejeitou um candidato específico.
O Agent Catalog fornece rastreamento. Ele permite que os usuários usem o SQL++ com rastreamentos, aproveitem o desempenho do Couchbase e obtenham informações sobre detalhes de prompts e ferramentas na mesma plataforma.
Podemos adicionar a observabilidade transacional usando catalog.Span(). Envolvemos a lógica de execução em um gerenciador de contexto que registra cada pensamento, ação e resultado de volta ao Couchbase. Agora podemos visualizar um “rastreamento” completo da sessão de recrutamento na interface do usuário do Capella, mostrando exatamente como o LLM processou o currículo de um candidato.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
application_span = catalog.Span(name="HR Recruiter Agent") # AFTER: granular observability with span.new(name="job_matching_query") as query_span: # Log the input query_span.log(UserContent(value=job_description)) # Run the agent response = agent.invoke({"input": job_description}) # Log the agent's final decision query_span.log(AssistantContent(value=response["output"])) |
Conclusão
Os agentes de IA falham na produção não porque os LLMs não têm capacidade, mas porque os sistemas agênticos podem se tornar muito complexos. Ao adotar uma abordagem que prioriza a plataforma com o Couchbase AI Services e o Agent Catalog, transformamos um agente complexo em um sistema agêntico governado e dimensionável.
Se você está criando agentes de IA hoje, a verdadeira questão não é Qual LLM usar - é como você executará agentes de forma segura, observável e em escala. Os serviços de IA do Couchbase foram criados exatamente para isso.