Minha família me ouve falar sobre Bancos de dados JSON com bastante frequência.
Naturalmente, tive que explicar que Jason não é o proprietário da minha empresa! Em vez disso, muitos bancos de dados modernos usam JSON como formato de dados. Eles geralmente saem da sala nesse momento, cansados de satisfazer meu entusiasmo pelo banco de dados JSON do Couchbase.
O que é um banco de dados JSON?
A Banco de dados JSON é, sem dúvida, a categoria mais popular da família de bancos de dados NoSQL. Gerenciamento de banco de dados NoSQL Os bancos de dados de dados de dados são diferentes dos bancos de dados relacionais tradicionais, que se esforçam para armazenar dados fora de colunas e linhas. Em vez disso, eles se adaptam de forma flexível a uma ampla variedade de tipos de dados, alterando os requisitos dos aplicativos e os modelos de dados. Em uma era em que os limites de armazenamento físico não são mais um gargalo, os bancos de dados JSON oferecem escala e desempenho superiores.
Essa flexibilidade fez dos bancos de dados JSON a estrutura de armazenamento preeminente para sistemas NoSQL que suportam processamento multimodal ou multimodal. Sua popularidade se deve principalmente à simplicidade e à flexibilidade da estrutura de documentos do banco de dados JSON.
Apresentado pela primeira vez em 2006, JSON significa "JavaScript Object Notation" e oferece um formato de dados menos detalhado do que o popular XML (eXtensible Markup Language). Atualmente, o formato de dados JSON está alimentando sistemas corporativos em todo o mundo, apesar de suas raízes humildes na habilitação de programação JavaScript e aplicativos simples baseados na Web. Os bancos de dados JSON, como o Couchbase ou o MongoDB, aproveitam a sintaxe simples do padrão, fornecendo estruturas de dados legíveis tanto por humanos quanto por máquinas.
Vamos examinar algumas das vantagens de um banco de dados que armazena dados no formato JSON. Enquanto fazemos isso, considere como você poderá aproveitar essa funcionalidade em aplicativos futuros.
Os bancos de dados JSON têm mais flexibilidade de armazenamento
NoSQL é uma categoria de banco de dados adaptada a casos de uso específicos que se concentram na estrutura de armazenamento, no design de dimensionamento e nos métodos de consulta/indexação. Há também um foco na concorrência, na alta disponibilidade e nas garantias de persistência de dados em tempo real.
Por exemplo, alguns bancos de dados otimizam o armazenamento de dados de valor-chave para a velocidade de recuperação, visando à execução mais rápida possível. Eles costumam ser executados principalmente na memória, evitando o fardo demorado de ler dados de discos rígidos giratórios.
Obviamente, a memória é volátil e as falhas de energia podem apagar os dados armazenados na memória. Os mecanismos de banco de dados de valor-chave oferecem um meio de gravar dados no armazenamento persistente para reduzir a perda de dados. Entretanto, os armazenamentos de valores-chave podem ser muito simplistas para alguns casos de uso.
Além disso, outras estruturas de dados, como os bancos de dados de gráficos, podem ser muito abstratas para outros casos de uso. As estruturas de banco de dados de gráficos podem ser rápidas, pois geralmente suportam o processamento na memória para agilizar as velocidades de passagem de relacionamento. No entanto, para fazer isso, é necessária uma arquitetura de dados nativa com nomes de design sofisticados, como "adjacência sem índice". Essas estruturas associam cada parte dos dados a um conjunto de números de ID de relacionamento armazenados fisicamente em um disco.
Os modelos de dados em gráfico eram mais úteis quando a memória e o espaço em disco eram escassos. Mas criaram desafios ao dimensionar uma estrutura de gráfico em vários nós do banco de dados. Por exemplo, onde você quebra logicamente suas relações nos dados subjacentes?
Os bancos de dados JSON NoSQL manipulam documentos como objetos de arquivos de dados individuais sem usar tabelas estruturadas. A contagem de linhas ou o tamanho da tabela não restringe o número de documentos armazenados em um banco de dados JSON. Em vez disso, a disponibilidade de armazenamento é o único limite para o volume de dados. Felizmente, um cluster pode expandir facilmente o armazenamento.
Particionamento de dados
Essa abordagem baseada em cluster permite que o banco de dados adicione mais nós para criar uma plataforma de dados maior, conforme necessário. Os desenvolvedores também chamam esse processo de "dimensionamento" do cluster. O particionamento de dados entre os nós permite o armazenamento e o processamento distribuídos, em que nenhum nó único está fazendo todo o trabalho.
O banco de dados subjacente particiona os dados para manter esse equilíbrio usando um pool de serviços de armazenamento em uma arquitetura compartilhada sem nada. O sistema equilibra e replica os dados para mantê-los disponíveis se um nó ficar inutilizável.
Processamento de modelos de dados
Um cluster também pode ter uma combinação de tipos de nós - armazenamento de dados, processamento e fornecimento de dados - usando diferentes modelos de acesso. Um banco de dados JSON permite armazenar dados como JSON e fornecê-los aos aplicativos de outras formas.
Por exemplo, os bancos de dados JSON podem operar como um armazenamento de valores-chave na memória para aplicativos que precisam apenas de acesso rápido e fácil. Ou, a indexação e a consulta podem fazer com que os dados JSON apareçam como uma tabela. Além disso, os desenvolvedores podem usar SDKs de estrutura de dados para fornecer atributos atômicos como pares de valores-chave.
Os bancos de dados JSON oferecem esquemas flexíveis
Os bancos de dados de documentos JSON armazenam seus dados em arquivos usando uma notação específica projetada para eliminar a rigidez dos esquemas de bancos de dados relacionais. Eles podem atender mais rapidamente a novos requisitos de estrutura de dados derivados após o projeto inicial do esquema do banco de dados e o lançamento do aplicativo.
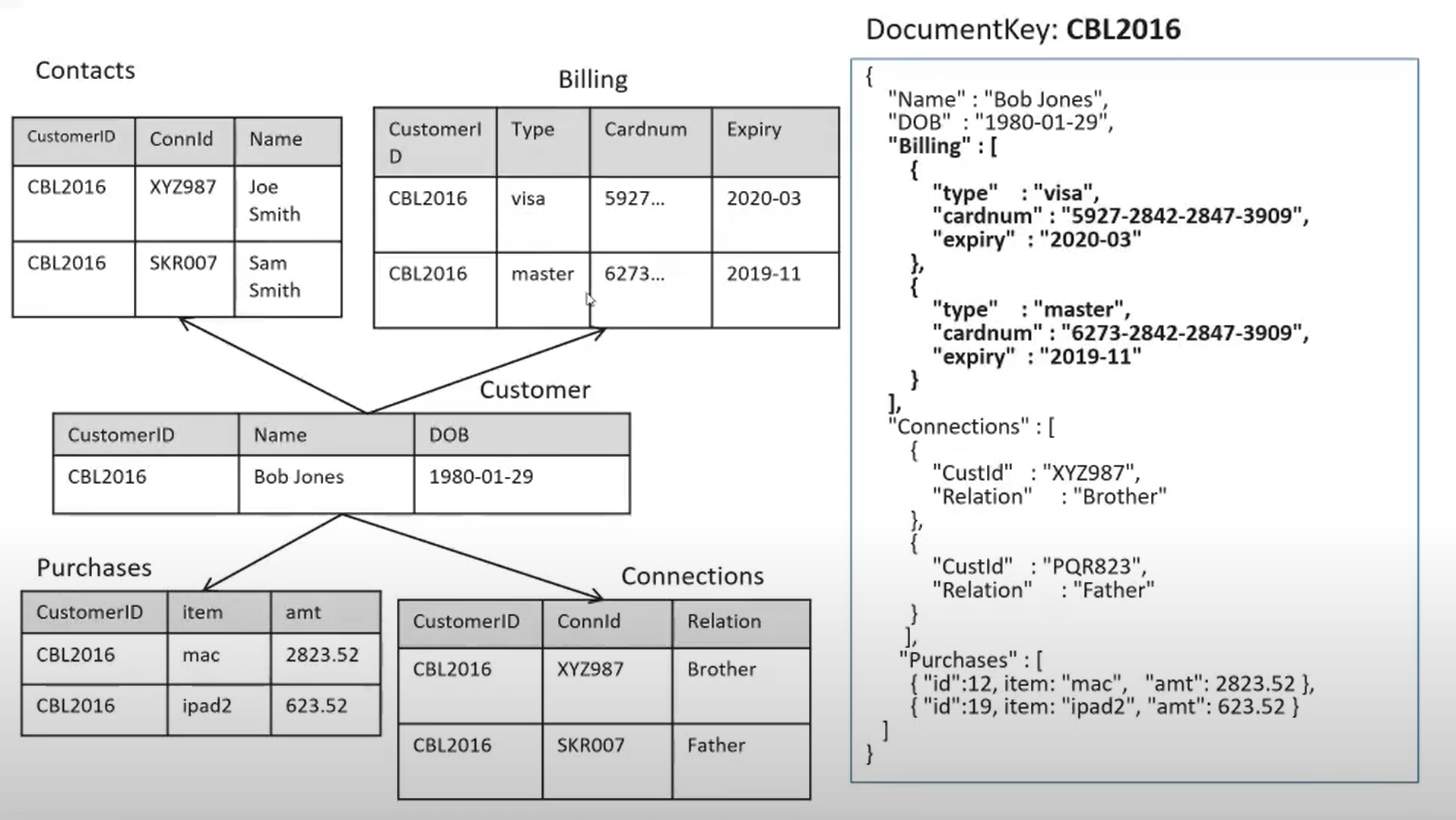
Comparação de um modelo de dados relacional de várias tabelas com um documento JSON simplificado.
Nas décadas de 80 e 90, os ciclos de manutenção e entrega de aplicativos geralmente levavam anos para serem concluídos. E um dos exercícios mais demorados e temidos era a introdução de novas alterações no esquema do banco de dados em um aplicativo.
Agora, os desenvolvedores podem adicionar novos atributos a um documento, essencialmente ampliando o esquema desse documento. Com o poder dos bancos de dados JSON, os desenvolvedores controlam o esquema, não o DBA.
Por exemplo, ao criar um documento que descreve uma pessoa, o desenvolvedor pode adicionar e modificar atributos conforme necessário. O desenvolvedor pode estender um documento que armazenava apenas o nome e o sobrenome para incluir um endereço residencial. A flexibilidade do esquema é o motivo pelo qual os desenvolvedores gostam de bancos de dados JSON e Pesquisas com clientes do Couchbase provar isso.
Os bancos de dados JSON têm uma vantagem moderna, pois as infraestruturas baseadas em nuvem reduziram os custos de armazenamento físico (e a RAM, em menor grau). Portanto, a compactação máxima não é tão importante como costumava ser. Além disso, a organização de documentos em um banco de dados JSON é muito mais intuitiva do que em estruturas relacionais e outras.
Os dados JSON são fáceis de ler
Os dados em um banco de dados JSON são fáceis de ler e escrever, tanto para pessoas quanto para máquinas, devido à sua simplicidade.
Assim como o JavaScript, os documentos contêm conjuntos de nomes-chave associados a atributos ou objetos. O uso de espaço em branco pode tornar os documentos mais legíveis para os seres humanos.
|
1 2 3 |
<document id>: { <key>: <object>, <key>: <object>, ... } hotel_1: { "name": "Grande Hotel de Paris", "City": "Porto" } |
Vários tipos de dados fundamentais estão disponíveis para serem misturados e combinados: texto, numérico, listas e mapas de valores-chave. Os objetos também podem conter outros objetos em uma forma hierárquica.
|
1 2 3 4 5 6 7 8 9 10 11 |
hotel_1: { "name": "Le Grande Hotel", "url": "https://www.guestreservations.com/grande-hotel-de-paris/booking", "RoomCount": 120, "Amenities": ["Pets Ok", "Pool", {"Parking": ["Valet", "Self"]}], "Address": { "Street": "Rua da Fabrica", "StreetNum": "27/29", "City": "Porto", "Country": "Portugal" } } |
Os bancos de dados JSON não exigem validação oficial do esquema. Os aplicativos podem usar/adicionar/modificar os conjuntos de chaves e objetos conforme necessário. Essa flexibilidade elimina a necessidade de um DBA para gerenciar esquemas de aplicativos e acelera a "entrega contínua" de microsserviços.
Mapeamento de esquemas JSON para estruturas SQL
Apesar de destacarmos a natureza opcional dos esquemas com o banco de dados JSON, ainda podemos aplicar qualquer estrutura necessária. Em um contexto de tabela relacional, os nomes de chave do documento JSON podem ser tratados como nomes de coluna. Isso se torna um pouco mais complicado quando há objetos hierárquicos no documento, mas as funções podem ajudar a nivelar os dados (falaremos mais sobre isso em outra ocasião).
Ao mapear os atributos JSON para nomes de colunas, a sintaxe geral do SQL pode ser aplicada. Os bancos de dados JSON podem automatizar esse mapeamento devido à estrutura de sintaxe simples do SQL, abrindo um mundo de possibilidades. Os desenvolvedores já sabem como usar o SQL e podem usá-lo para acelerar o desenvolvimento. Isso também reduz a necessidade de DBAs e arquitetos.
Os bancos de dados JSON suportam uma variedade de tipos de índices
Os bancos de dados JSON também podem gerar índices de coluna que aceleram as consultas de dados SQL. Os desenvolvedores identificam as colunas que seus aplicativos usarão, e o sistema de back-end mantém automaticamente os índices. Uma variedade de índices pode ser aplicada, incluindo índices primários, índices secundários globais (GSI) e até mesmo pesquisa de texto completo índices.
Os dados JSON são fáceis de pesquisar
Pesquisa de texto completo Os aplicativos de mecanismo também são naturais para bancos de dados JSON e são possíveis por meio de outro tipo de índice.
Os desenvolvedores identificam quais atributos devem ser indexados e usam o SDK da linguagem de programação para enviar uma solicitação de pesquisa ao banco de dados. A resposta JSON inclui correspondências de dados, estatísticas de correspondência e outros metadados que os desenvolvedores usam para otimizar os aplicativos clientes.
Os bancos de dados JSON cuidam de si mesmos
Já vimos como os bancos de dados JSON podem ser versáteis e avançados. É muito importante lembrar que o serviço de banco de dados gerencia automaticamente todos os recursos configurados de indexação, particionamento, replicação e acesso a dados.
Os desenvolvedores de aplicativos se beneficiam significativamente desse poder, concentrando-se na criação de soluções em vez de gerenciar clusters. Ao adicionar novos documentos, o sistema percebe e se ajusta, atualizando os dados indexados de acordo, sem intervenção do usuário.
Os painéis de monitoramento fornecem interfaces da Web para métricas de desempenho e ajudam a mostrar quando mais nós ou memória podem ser benéficos. Os usuários podem adicionar facilmente novos nós a um cluster, enquanto o balanceamento e a replicação de dados são feitos automaticamente nos bastidores. Um banco de dados JSON pode desligar o nó quebrado quando houver falhas, ajustar a distribuição de dados e notificar os administradores.
Próximas etapas
Os desenvolvedores esperam que as infraestruturas de dados estejam sempre disponíveis para seus aplicativos. Com bancos de dados JSON como o CouchbaseCom o sistema de gerenciamento de dados, você obtém flexibilidade e alto desempenho imediatamente.
Saiba mais sobre os bancos de dados NoSQL JSON e o Couchbase: