A modelagem de dados JSON é uma parte essencial do uso de um banco de dados de documentos como o Couchbase. Além de entender os conceitos básicos de JSON, há duas abordagens principais para modelar relacionamentos entre dados que serão abordados nesta postagem do blog.
Os exemplos nesta postagem serão baseados no exemplo de faturas que mostrei em Ferramenta CSV para migrar do Relacional para o Couchbase.
Atualização de dados importados
No exemplo anterior, comecei com duas tabelas de um banco de dados relacional: Invoices (faturas) e InvoicesItems (itens de faturas). Cada item de fatura pertence a uma fatura, o que é feito com uma chave estrangeira em um banco de dados relacional.
Fiz uma importação muito simples (ingênua) desses dados para o Couchbase. Cada linha se tornou um documento em um bucket de "preparação".

Em seguida, precisamos decidir se esse design de modelagem de dados JSON é adequado ou não (acho que não é, como se o balde chamado "staging" já não tivesse revelado isso).
Duas abordagens para a modelagem de dados JSON de relacionamentos
Com um banco de dados relacional, há apenas uma abordagem: normalizar seus dados. Isso significa tabelas separadas com chaves estrangeiras que vinculam os dados entre si.
Com um banco de dados de documentos, há duas abordagens. Você pode manter os dados normalizados ou pode desnormalizá-los aninhando-os em seu documento pai.
Normalizado (documentos separados)
Um exemplo do estado final do normalizado representa uma única fatura distribuída em vários documentos:
|
1 2 3 4 5 6 7 8 9 10 11 |
chave - fatura::1 { "BillTo": "Lynn Hess", "InvoiceDate" (data da fatura): "2018-01-15 00:00:00.000", "InvoiceNum" (Número da fatura): "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive" } chave - item da fatura::1811cfcc-05b6-4ace-a52a-be3aad24dc52 { "InvoiceId": "1", "Preço": "1000.00", "Produto": "Pastilha de freio", "Quantidade": "24" } chave - item da fatura::29109f4a-761f-49a6-9b0d-f448627d7148 { "InvoiceId": "1", "Preço": "10.00", "Produto": "Volante", "Quantidade": "5" } chave - item da fatura::bf9d3256-9c8a-4378-877d-2a563b163d45 { "InvoiceId": "1", "Preço": "20.00", "Produto": "Pneu", "Quantidade": "2" } |
Isso está alinhado com a importação direta de CSV. O InvoiceId em cada documento de item de fatura é semelhante O Couchbase é um banco de dados de documentos distribuído, mas observe que o Couchbase (e os bancos de dados de documentos distribuídos em geral) não impõe esse relacionamento da mesma forma que os bancos de dados relacionais. Essa é uma troca feita para satisfazer as necessidades de flexibilidade, escalabilidade e desempenho de um sistema distribuído.
Observe que, neste exemplo, os documentos "filhos" apontam para o pai por meio de InvoiceId. Mas também poderia ser o contrário: o documento "pai" poderia conter uma matriz das chaves de cada documento "filho".
Desnormalizado (aninhado)
O estado final do aninhado A abordagem de um documento único para representar uma fatura.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
chave - fatura::1 { "BillTo": "Lynn Hess", "InvoiceDate" (data da fatura): "2018-01-15 00:00:00.000", "InvoiceNum" (Número da fatura): "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive", "Itens": [ { "Preço": "1000.00", "Produto": "Pastilha de freio", "Quantidade": "24" }, { "Preço": "10.00", "Produto": "Volante", "Quantidade": "5" }, { "Preço": "20.00", "Produto": "Pneu", "Quantidade": "2" } ] } |
Observe que o "InvoiceId" não está mais presente nos objetos da tabela Itens array. Esses dados não são mais estrangeiros - agora são nacionais -, portanto, esse campo não é mais necessário.
Regras básicas de modelagem de dados JSON
Você já deve estar pensando que o segundo é uma opção natural nesse caso. Uma fatura nesse sistema é uma opção natural raiz agregada. No entanto, nem sempre é simples e óbvio quando e como escolher entre essas duas abordagens em seu aplicativo.
Aqui estão algumas regras de ouro para saber quando escolher cada modelo:
| Se ... | Então, considere... |
|---|---|
|
O relacionamento é de 1 para 1 ou de 1 para muitos |
Objetos aninhados |
|
O relacionamento é de muitos para 1 ou de muitos para muitos |
Documentos separados |
|
As leituras de dados são, em sua maioria, campos pai |
Documento separado |
|
As leituras de dados são, em sua maioria, campos pai + filho |
Objetos aninhados |
|
As leituras de dados são, em sua maioria, parentais ou filho (não ambos) |
Documentos separados |
|
As gravações de dados são, em sua maioria, pai e criança (ambos) |
Objetos aninhados |
Exemplo de modelagem
Para explorar isso mais a fundo, vamos fazer algumas suposições sobre o sistema de faturas que estamos criando.
- Um usuário geralmente visualiza a fatura inteira (incluindo os itens da fatura)
- Quando um usuário cria uma fatura (ou faz alterações), ele atualiza os campos "raiz" e os "itens" juntos
- Existem alguns consultas (mas não muitas) no sistema que se preocupam apenas com os dados raiz da fatura e ignoram os campos "itens"
Então, com base nesse conhecimento, sabemos que:
- A relação é de 1 para muitos (uma única fatura tem muitos itens)
- As leituras de dados são principalmente campos pai + filho juntos
Portanto, "objetos aninhados" parece ser o design correto.
Lembre-se de que essas não são regras rígidas e rápidas que sempre serão aplicadas. Elas são apenas diretrizes para ajudá-lo a começar. A única "prática recomendada" é usar seu próprio conhecimento e experiência.
Transformação de dados de preparação com N1QL
Agora que fizemos alguns exercícios de modelagem de dados JSON, é hora de transformar os dados no bucket de teste de documentos separados que vieram diretamente do banco de dados relacional para o design de objetos aninhados.
Há muitas abordagens para isso, mas vou mantê-las bem simples e usar o poderoso recurso do Couchbase Linguagem N1QL para executar consultas SQL em dados JSON.
Preparando os dados
Primeiro, crie um bucket de "operação". Vou transformar os dados e movê-los para o bucket "staging" (que contém os dados diretos da operação). Importação de CSV) para o compartimento "operação".
Em seguida, vou marcar os documentos "raiz" com um campo "tipo". Essa é uma maneira de marcar os documentos como sendo de um determinado tipo e será útil mais tarde.
|
1 2 3 |
ATUALIZAÇÃO preparação CONJUNTO tipo = 'fatura' ONDE InvoiceNum IS NÃO FALTANDO; |
Sei que os documentos raiz têm um campo chamado "InvoiceNum" e que os itens não têm esse campo. Portanto, essa é uma maneira segura de diferenciar.
Em seguida, preciso modificar os itens. Anteriormente, eles tinham uma chave estrangeira que era apenas um número. Agora, esses valores devem ser atualizados para apontar para a nova chave do documento.
|
1 2 |
ATUALIZAÇÃO preparação s CONJUNTO s.InvoiceId = 'invoice::' || s.InvoiceId; |
Isso é apenas acrescentar "invoice::" ao valor. Observe que os documentos raiz não têm um campo InvoiceId, portanto, eles não serão afetados por essa consulta.
Depois disso, preciso criar um índice nesse campo.
Preparação de um índice
|
1 |
CRIAR ÍNDICE ix_invoiceid ON preparação(InvoiceId); |
Esse índice será necessário para a união transformacional que virá a seguir.
Agora, antes de tornar esses dados operacionais, vamos executar um SELECIONAR para obter uma visualização e garantir que os dados serão unidos da forma esperada. Use a função NEST operação:
|
1 2 3 4 |
SELECIONAR i.*, t AS Itens DE preparação AS i NEST preparação AS t ON CHAVE t.InvoiceId PARA i ONDE i.tipo = 'fatura'; |
O resultado dessa consulta deve ser um total de três documentos de fatura raiz.
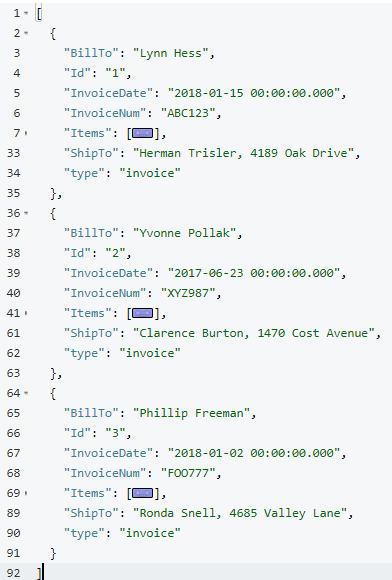
Os itens da fatura agora devem ser aninhados em uma matriz "Items" dentro da fatura principal (eu os coloquei em colapso na captura de tela acima por uma questão de brevidade).
Mover os dados para fora da preparação
Depois de verificar se isso está correto, os dados podem ser movidos para o bucket de "operação" usando um INSERIR que será apenas uma pequena variação do comando acima SELECIONAR comando.
|
1 2 3 4 5 |
INSERIR PARA operação (CHAVE k, VALOR v) SELECIONAR META(i).id AS k, { i.BillTo, i.InvoiceDate (data da fatura), i.InvoiceNum, "Itens": t } AS v DE preparação i NEST preparação t ON CHAVE t.InvoiceId PARA i onde i.tipo = 'fatura'; |
Se você é novo no N1QL, há algumas coisas que devem ser destacadas aqui:
INSERIRsempre usaráCHAVEeVALOR. Você não lista todos os campos nessa cláusula, como faria em um banco de dados relacional.META(i).idé uma forma de acessar a chave de um documento- A sintaxe literal do JSON sendo SELECIONADO COMO v é uma forma de especificar quais campos você deseja mover. Os curingas podem ser usados aqui.
NESTé um tipo de união que aninhará os dados em uma matriz em vez de no nível da raiz.PARA iespecifica o lado esquerdo doNA CHAVEjoin. Essa sintaxe é provavelmente a parte mais fora do padrão do N1QL, mas a próxima versão principal do Couchbase Server incluirá a funcionalidade "ANSI JOIN", que será muito mais natural para leitura e gravação.
Depois de executar essa consulta, você deverá ter um total de 3 documentos no seu bucket de "operação", representando 3 faturas.
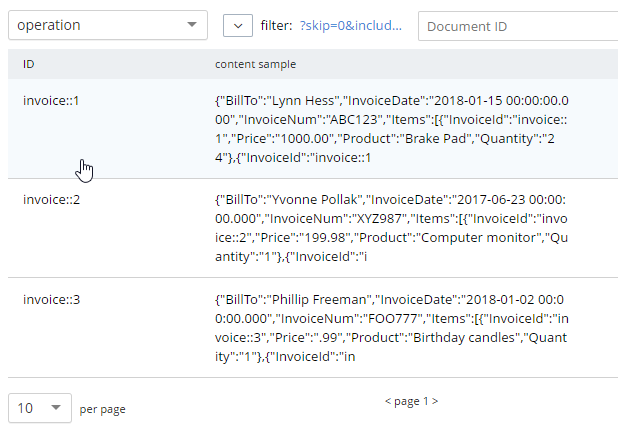
Você pode excluir/descarregar o bucket de teste, pois ele agora contém dados obsoletos. Ou você pode mantê-lo por perto para fazer mais experimentos.
Resumo
Migrar dados diretamente para o Couchbase Server pode ser tão fácil quanto importar via CSV e transformar com algumas linhas de N1QL. A modelagem real e a tomada de decisões exigem mais tempo e reflexão. Depois de decidir como modelar, o N1QL oferece a flexibilidade de transformar dados relacionais planos e dispersos em um modelo de documento orientado a agregados.
Mais recursos:
- Usando a Hackolade para colaborar na modelagem de dados JSON.
- Parte da série SQL Server discute o mesmo tipo de decisões de modelagem de dados JSON
- Como o Couchbase supera a OracleSe estiver pensando em transferir alguns de seus dados para fora da Oracle
- Mudança do sistema relacional para o NoSQL: Como começar white paper.
Sinta-se à vontade para entrar em contato comigo se tiver alguma dúvida ou precisar de ajuda. Eu sou
@mgroves no Twitter. Você também pode fazer perguntas no Fóruns do Couchbase. Há especialistas em N1QL lá que são muito receptivos e podem ajudá-lo a escrever o N1QL para acomodar sua modelagem de dados JSON.