Como arquiteto de aplicativos, eventualmente, você terá que escolher o banco de dados ou o banco de dados como um serviço (DBaaS) para alimentar seu aplicativo mais novo ou um microsserviço. A seleção de um dos bancos de dados entre os bancos de dados relacionais foi mais fácil. Os casos de uso foram divididos em OLTP e OLAP (suporte a decisões). As diferenças de carga de trabalho entre OLTP e OLAP eram bem conhecidas. As cargas de trabalho de OLTP consistem em transações em poucas linhas aleatórias, esperando respostas de milissegundos em consultas pré-compiladas; as cargas de trabalho OLAP consistem em cargas de dados, consultas de longa duração que examinam milhões de linhas de uma tabela de fatos de um esquema estrela/floco de neve. Cada uma delas tinha o benchmark de desempenho e o TCO bem definidos, medidos e auditados por meio de Benchmarks da TPC. Você pode usar esses números, aproximar sua carga de trabalho, entender as necessidades e os recursos correspondentes em outras frentes, como a administração.
Depois, há os bancos de dados No-SQL. Os bancos de dados NoSQL foram inventados para lidar com o desempenho em escala da Web de aplicativos operacionais. Ele precisava ser elástico para lidar com a escala e tolerar a queda de nós (também conhecida como tolerância de partição). Isso provocou a inovação para criar bancos de dados em uma variedade de modelos de dados e casos de uso. Existem bancos de dados para JSON, gráficos, séries temporais e muito mais. De bancos de dados do Azure a ZODB, de Couchbase a Cassandra. MongoDB a TiDB, bancos de dados espaciais a JSON - tantos tipos diferentes de bancos de dados. De fato, NoSQL-databases.org listas 225 bancos de dados e DBaaS em novembro de 2018.
Os aplicativos de comércio eletrônico precisam gerar o relatório de vendas, os aplicativos de carrinho de compras precisam informar os carrinhos de compras pendentes etc. Cada aplicativo faz progresso no fluxo de trabalho em nome de seu usuário ou cliente. Essas consultas operacionais podem ser operações simples de valor-chave, consultas de curto alcance ou consultas de pesquisa complexas em NoSQL. Essa carga de trabalho é o pão e a manteiga da maioria das empresas.
As soluções para transações de alto volume e análises de alto volume são aparentemente contraditórias. As operações de pesquisa ou consultas (por exemplo, pesquisa de voos) exigem uma pesquisa muito eficiente e um fluxo de dados rápido de volta ao aplicativo. Os milissegundos são importantes.
"A propósito, a maioria das cargas de trabalho são cargas de trabalho mistas" - Larry EllisonFundador e CTO da Oracle.
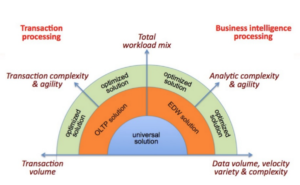
Fonte: BI Research
Reconhecendo a necessidade de lidar com cargas de trabalho mistas, os bancos de dados OLTP adicionaram recursos para consultas complexas (por exemplo, junções de hash, funções de janela) e os bancos de dados NoSQL adicionaram SQL. Os bancos de dados SQL adicionaram o JSON. Talvez estejamos chegando ao estado da paradoxo da escolha!
Até que tenhamos uma solução universal, precisaremos avaliar e combinar diferentes produtos e serviços para fornecer a solução de suporte à carga de trabalho e ao resultado comercial. Por exemplo, você poderia executar o SQL Server para OLTP e o Teradata para OLAP. Usar o Couchbase para um aplicativo de comércio eletrônico e o Hadoop para aprendizado de máquina. Primeiro, você terá que detalhar a carga de trabalho para entender as operações dentro de uma carga de trabalho.
Então, o que é uma carga de trabalho?
O artigo Qual é a sua definição de carga de trabalho? fornece exemplos de carga de trabalho de banco de dados de vários ângulos. Os designers de aplicativos podem definir pelos SLAs do aplicativo em uma determinada simultaneidade. Os DBAs podem definir a carga de trabalho pela CPU, pelo uso da memória, pela taxa de transferência de E/S etc. O conselho é entender o uso dos recursos e vinculá-los a entidades de nível superior, como consultas, usuários e aplicativos.
TPC-C descreve a carga de trabalho e a medição do benchmark da seguinte maneira: A transação mais frequente consiste na entrada de um novo pedido que, em média, é composto por dez itens diferentes. Cada depósito tenta manter o estoque dos 100.000 itens do catálogo da empresa e atender aos pedidos a partir desse estoque. Entretanto, na realidade, um depósito provavelmente não terá todas as peças necessárias para atender a todos os pedidos. Portanto, o TPC-C exige que cerca de dez por cento de todos os pedidos sejam fornecidos por outro depósito da empresa. Outra transação frequente consiste em registrar um pagamento recebido de um cliente. Com menos frequência, os operadores solicitam o status de um pedido feito anteriormente, processam um lote de dez pedidos para entrega ou consultam o sistema sobre possíveis faltas de suprimentos, examinando o nível de estoque no depósito local. Portanto, um total de cinco tipos de transações é usado para modelar essa atividade comercial. A métrica de desempenho relatada pelo TPC-C mede o número de pedidos que podem ser totalmente processados por minuto e é expressa em tpm-C.
Para aplicativos modernos, como arquiteto, você terá que entender todas as operações e padrões de aplicativos e seus SLAs. O desempenho do aplicativo não é medido por um simples benchmark, mas por sua capacidade de desempenho em escala comercial por um longo período. período de tempo. Adicionando o período de tempo O fator significa que você terá que considerar a escala, o SLA e o custo da infraestrutura em um dia lento de verão e no dia em que 100 milhões de clientes estiverem em seu site tentando adicionar seu brinquedo favorito ao carrinho de compras e comprá-lo.
- Quais são as solicitações do aplicativo para o banco de dados?
- Operações simples para obter e definir dados (por exemplo, novo cliente, novo pedido)
- Solicitações de pesquisa (pesquisa de produtos, pedidos, etc.)
- Solicitações de paginação (lista de pedidos de um cliente, classificados por data)
- Carga de trabalho do relatório.
- Consultas de ferramentas de business intelligence.
- À medida que o número de usuários simultâneos aumenta, quais dessas operações precisam ser dimensionadas?
- Qual é o ponto de disparo na carga de trabalho para adicionar ou remover nós de banco de dados?
- Qual é a estratégia de failover?
Comparação de bancos de dados NoSQL:
Os bancos de dados relacionais (também conhecidos como bancos de dados SQL) tinham o mesmo modelo relacional, praticamente os mesmos tipos de dados e implementavam SQL semelhante. A diferença estava no desempenho, que podia ser medido por benchmarks TPC, e na facilidade de administração, que era mais subjetiva.
Variedade é o nome do jogo para bancos de dados No-SQL. Há bancos de dados especializados em valor-chave, JSON, colunas largas, gráficos, séries temporais e espaciais, entre outros. Eles representam diferentes modelos de dados e várias operações que podem ser realizadas com eficiência nesse modelo. Cada um deles tem suas próprias APIs, linguagens de consulta, características de desempenho e recursos de dimensionamento.
Se você exibiu as ordens pendentes de um usuário no aplicativo anteriormente, ainda precisará fazer isso com o novo banco de dados. Você pode mudar a forma de obter o mesmo resultado, mas não o resultado em si. Isso nos leva de volta à carga de trabalho. Você terá que entender a carga de trabalho completa do aplicativo e a carga de trabalho do banco de dados que ele gera. Em seguida, faça o desempenho, a medição do dimensionamento e o dimensionamento. Os casos de uso simples, YCSB O benchmark ajudará, mas para casos de uso complexos, YCSB-JSON pode ser usado. Este exercício exigirá que você traduza a carga de trabalho em operações de banco de dados respectivas e as meça. Meça-as para cada uma das operações críticas, bem como para as características do sistema, como elasticidade, velocidade de replicação e failover.
A lição fundamental ao avaliar os bancos de dados para sua carga de trabalho é:
Os requisitos de negócios e aplicativos do banco de dados não mudarão só porque você pode usar um novo tipo de banco de dados.
Para resumir, a carga de trabalho é descrita pela fórmula modificada Pink Floyd letra. (Com desculpas a Roger Waters).
Carga de trabalho do banco de dados
Tudo o que você armazena em cache
E tudo o que você libera
Tudo o que você fragmenta
Tudo o que você tem
Tudo o que você dimensiona
Tudo o que você não consegue
Todos os testes
Tudo o que você economiza
Tudo o que você compartilha
E tudo o que você armazena
E tudo o que você transaciona
Iniciar, confirmar ou reverter
Tudo o que você cria
E tudo o que você faz
E tudo o que você desfaz
E tudo o que você refaz
E tudo o que você exclui
E cada nó que você adicionar (cada nó que você adicionar)
E tudo o que você busca
E cada chave que você indexa
E tudo o que é planejado
E tudo o que é executado
E tudo isso está para mudar
E tudo sob a base (de dados) está em sintonia
Mas a base está sendo executada na nuvem