Como arquitecto de aplicaciones, al final tendrá que elegir la base de datos o la base de datos como servicio (DBaaS) para impulsar su aplicación más reciente o un microservicio. Seleccionar una de las bases de datos relacionales fue más fácil. Los casos de uso se dividían a grandes rasgos en OLTP y OLAP (apoyo a la toma de decisiones). Las diferencias de carga de trabajo entre OLTP y OLAP eran bien conocidas. Las cargas de trabajo OLTP consisten en transacciones en pocas filas aleatorias, esperando respuestas en milisegundos en consultas precompiladas; las cargas de trabajo OLAP consisten en cargas de datos, consultas de larga duración que escanean millones de filas de una tabla de hechos de un esquema estrella/ copo de nieve. Cada uno de ellos tenía el punto de referencia de rendimiento y el coste total de propiedad bien definidos, medidos y auditados a través de Puntos de referencia TPC. Usted puede hacer uso de estos números, aproximar su carga de trabajo, entender las necesidades y capacidades coinciden en otros frentes como la administración.
Luego están las bases de datos No-SQL. Las bases de datos NoSQL se inventaron para gestionar el rendimiento a escala web de las aplicaciones operativas. Tenían que ser elásticas para manejar la escala y tolerar la caída de nodos (también conocida como tolerancia a la partición). Eso provocó la innovación para crear bases de datos en una variedad de modelos de datos y casos de uso. Existen bases de datos para JSON, gráficos, series temporales y mucho más. Desde bases de datos Azure a ZODB, de Couchbase a Cassandra. De MongoDB a TiDB, de bases de datos espaciales a JSON: tantos tipos diferentes de bases de datos. De hecho, Bases de datos NoSQL.org listas 225 bases de datos y DBaaS a noviembre de 2018.
Las aplicaciones de comercio electrónico necesitan generar el informe de ventas, las aplicaciones de carritos de la compra necesitan informar de los carritos pendientes, etc. Cada aplicación avanza en el flujo de trabajo en nombre de su usuario o cliente. Estas consultas operativas pueden ser simples operaciones clave-valor, consultas de corto alcance o complejas consultas de búsqueda en NoSQL. Esta carga de trabajo es el pan de cada día de la mayoría de las empresas.
Las soluciones para las transacciones de gran volumen y los análisis de gran volumen son aparentemente contradictorias. Las operaciones de búsqueda o consultas (por ejemplo, búsqueda de vuelos) requieren una búsqueda muy eficiente y un flujo de datos rápido de vuelta a la aplicación. Los milisegundos importan.
"Por cierto, la mayoría de las cargas de trabajo son cargas de trabajo mixtas" - Larry EllisonFundador y Director Técnico de Oracle.
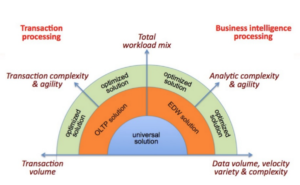
Fuente: BI Research
Reconociendo la necesidad de abordar cargas de trabajo mixtas, las bases de datos OLTP han añadido funciones para consultas complejas (por ejemplo, uniones hash, funciones de ventana), las bases de datos NoSQL han añadido SQL. Las bases de datos SQL han añadido JSON. Puede que estemos llegando al estado del paradoja de la elección!
Hasta que dispongamos de una solución universal, tendremos que evaluar y combinar distintos productos y servicios para ofrecer una solución que respalde la carga de trabajo y los resultados empresariales. Por ejemplo, se podría utilizar SQL Server para el OLTP y Teradata para el OLAP. Utilizar Couchbase para una aplicación de comercio electrónico y Hadoop para el aprendizaje automático. En primer lugar, tendrá que desglosar la carga de trabajo para comprender las operaciones dentro de una carga de trabajo.
¿Qué es la carga de trabajo?
El artículo ¿Cuál es su definición de la carga de trabajo? ofrece ejemplos de carga de trabajo de bases de datos desde varios ángulos. Los diseñadores de aplicaciones pueden definir los SLA de la aplicación para una concurrencia determinada. Los administradores de bases de datos pueden definir la carga de trabajo en función de la CPU, el uso de memoria, el rendimiento de E/S, etc. El consejo es comprender el uso de los recursos y vincularlos a entidades de nivel superior como las consultas, los usuarios y las aplicaciones.
TPC-C describe la carga de trabajo de referencia y la medición de la siguiente manera: La transacción más frecuente consiste en introducir un nuevo pedido que, por término medio, se compone de diez artículos diferentes. Cada almacén intenta mantener existencias para los 100.000 artículos del catálogo de la empresa y servir los pedidos a partir de esas existencias. Sin embargo, en la realidad, es probable que un almacén no disponga de todas las piezas necesarias para atender todos los pedidos. Por lo tanto, TPC-C exige que cerca del diez por ciento de todos los pedidos sean suministrados por otro almacén de la Empresa. Otra transacción frecuente consiste en registrar un pago recibido de un cliente. Con menor frecuencia, los operarios solicitan el estado de un pedido realizado previamente, procesan un lote de diez pedidos para su entrega o consultan el sistema para detectar posibles faltas de suministro examinando el nivel de existencias en el almacén local. En total, se utilizan cinco tipos de transacciones para modelar esta actividad comercial. La métrica de rendimiento indicada por TPC-C mide el número de pedidos que pueden procesarse completamente por minuto y se expresa en tpm-C.
Para las aplicaciones modernas, como arquitecto, tendrá que entender todas las operaciones de la aplicación, los patrones y sus SLA. El rendimiento de una aplicación no se mide por un simple parámetro de referencia, sino por su capacidad para funcionar a escala empresarial durante un largo periodo de tiempo. periodo de tiempo. Añadir el periodo de tiempo factor significa que tendrá que considerar la escala, el SLA y el coste de la infraestructura en un día lento de verano y el día en que 100 millones de clientes entren en su sitio web intentando añadir su juguete favorito al carrito de la compra y comprarlo.
- ¿Cuáles son las peticiones de la aplicación a la base de datos?
- Operaciones sencillas para obtener y establecer datos (p. ej., nuevo cliente, nuevo pedido)
- Solicitudes de búsqueda (búsqueda de productos, pedidos, etc.)
- Solicitudes de paginación (lista de pedidos de un cliente, ordenados por fecha)
- Carga de trabajo de los informes.
- Consultas desde herramientas de inteligencia empresarial.
- A medida que aumenta el número de usuarios simultáneos, ¿cuáles de estas operaciones deben escalarse?
- ¿Cuál es el punto de activación en la carga de trabajo para añadir o eliminar nodos de base de datos?
- ¿Cuál es la estrategia de conmutación por error?
Comparación de bases de datos NoSQL:
Las bases de datos relacionales (también conocidas como bases de datos SQL) tenían el mismo modelo relacional, aproximadamente los mismos tipos de datos e implementaban SQL similares. La diferencia radicaba en el rendimiento, que podía medirse con referencias TPC, y en la facilidad de administración, que era más subjetiva.
Variedad es el nombre del juego para las bases de datos No-SQL. Hay bases de datos especializadas para clave-valor, JSON, columna ancha, gráfico, series temporales y espacial y más. Éstas representan diferentes modelos de datos y diversas operaciones que pueden realizarse eficazmente en este modelo. Cada una de ellas tiene sus propias API, lenguajes de consulta, características de rendimiento y capacidades de escalado.
Si antes mostraba las órdenes pendientes de un usuario en la aplicación, deberá seguir haciéndolo con la nueva base de datos. Puede cambiar la forma de obtener el mismo resultado, pero no el resultado en sí. Esto nos lleva de nuevo a la carga de trabajo. Tendrás que entender toda la carga de trabajo de la aplicación y la carga de trabajo de la base de datos que genera. A continuación, haz las mediciones de rendimiento, escalado y escalado. Los casos de uso sencillos, YCSB benchmark ayudará, pero para casos de uso complejos, YCSB-JSON puede utilizarse. Este ejercicio requerirá que traduzcas la carga de trabajo en operaciones de base de datos respectivas y las midas. Mídelas para cada una de las operaciones críticas, así como para características del sistema como la elasticidad, la velocidad de replicación y la conmutación por error.
La lección fundamental a la hora de evaluar las bases de datos para su carga de trabajo es:
Los requisitos de negocio y aplicación de la base de datos no cambiarán sólo porque se pueda utilizar un nuevo tipo de base de datos.
En resumen, la carga de trabajo se describe mediante la fórmula modificada Pink Floyd lírica. (Con perdón de Roger Waters).
Carga de trabajo de la base de datos
Todo lo que guardas
Y todo lo que tiras
Todo lo que desmenuzas
Todo lo que hash
Todo lo que escamas
Todo lo que fallas
Todas las pruebas
Todo lo que ahorras
Todo lo que compartes
Y todo lo que almacenas
Y todo lo que tramites
Iniciar, confirmar o revertir
Todo lo que creas
Y todo lo que haces
Y todo lo que deshaces
Y todo lo que rehaces
Y todo lo que borres
Y cada nodo que añadas (cada nodo que añadas)
Y todo lo que buscas
Y cada tecla que indexes
Y todo lo que está previsto
Y todo lo que se ejecuta
Y todo eso va a cambiar
Y todo bajo la base (de datos) está en sintonía
Pero la base está funcionando en la nube