O Couchbase tem o prazer de anunciar o lançamento de um novo recurso de série temporal como parte do Couchbase 7.2. Esse recurso foi desenvolvido com base na robusta arquitetura de banco de dados distribuído do Couchbase, que foi projetada para ser dimensionada horizontalmente à medida que seus dados crescem, ao mesmo tempo em que oferece redundância e alta disponibilidade integradas. Isso significa que, à medida que sua empresa cresce e suas necessidades de dados de séries temporais aumentam, o Couchbase pode se expandir sem esforço para atender a essas necessidades, tornando-o uma solução ideal para empresas de todos os tamanhos.
Essa nova técnica inovadora para gerenciar dados de séries temporais abre um mundo totalmente novo de possibilidades para os usuários do Couchbase. Com a capacidade de armazenar e analisar grandes quantidades de dados de séries temporais usando o Couchbase SQL++ e SDKs. Isso permite que os usuários aproveitem o conhecimento e a infraestrutura existentes, facilitando a configuração e o desbloqueio de insights poderosos para explorar tendências de dados com facilidade.
Principais benefícios das séries temporais
Os dados de séries temporais são armazenados em documentos JSON no banco de dados Couchbase Multi Model. Ele oferece o mesmo alto desempenho, cache avançado para recuperação rápida de dados e baixa latência. O serviço Couchbase Query SQL++ e Index aprimoram os recursos de recuperação de dados para permitir casos de uso de consultas analíticas complexas.
O suporte a dados de série temporal no Couchbase oferece esses benefícios adicionais:
-
- Armazenamento eficiente para grandes volumes de pontos de dados de séries temporais
- Armazenamento otimizado da estrutura de dados para pontos de dados com registro de data e hora
- Novos recursos avançados de consulta de séries temporais
- Baixo requisito de armazenamento de índice
Exemplos de casos de uso de séries temporais
Negociação financeira A negociação financeira depende da análise de grandes quantidades de dados em tempo real, incluindo preços de ações, taxas de câmbio e preços de commodities. A análise de dados de séries temporais pode ajudar os traders a identificar tendências e tomar decisões informadas sobre compra e venda.
Monitoramento da Internet das Coisas (IoT) Os dispositivos de IoT geram uma grande quantidade de dados de séries temporais, incluindo leituras de temperatura, consumo de energia e dados de sensores. Esses dados podem ser analisados em tempo real para detectar anomalias e prever falhas nos equipamentos antes que elas ocorram.
Manutenção preditiva Muitos setores dependem de equipamentos e maquinário caros, e o tempo de inatividade pode custar caro. Ao analisar dados de séries temporais de sensores e outras fontes, as organizações podem prever quando o equipamento provavelmente falhará e programar proativamente a manutenção para minimizar o tempo de inatividade e maximizar a eficiência.
Principais recursos da série temporal do Couchbase
Você pode armazenar dados de séries temporais no Couchbase, usando nosso SDK/SQL++ para carregar, e o recurso de consulta analítica avançada com o Índice Secundário Global para consultar/analisar os dados da mesma forma que com documentos JSON normais.
Eficiência de armazenamento
Os conjuntos de dados de séries temporais geralmente são muito grandes, com cada ponto de dados composto por atributos, como registro de data e hora, valor(es), granularidade e outras informações relacionadas. O armazenamento eficiente é essencial, pois pode determinar a rapidez com que os dados podem ser consultados para análise.
A série temporal do Couchbase usa duas especificações para melhorar a eficiência do armazenamento.
O uso de matrizes para pontos de dados - Por sua própria natureza, os dados de séries temporais são uma série de pontos de dados. Esses pontos de dados compartilham uma estrutura comum, por exemplo, tempo e valores, ou quaisquer outros atributos associados ao momento em que o ponto de dados foi coletado.
O uso de uma matriz para armazenar um conjunto de pontos de dados para um determinado intervalo pode reduzir muito o custo de armazenamento, em comparação com a necessidade de armazenar cada ponto de dados individual como um documento separado no banco de dados.
O uso da posição da matriz - Observe também que os elementos da matriz de pontos de dados não têm um nome de campo associado, mas dependem da posição do elemento na matriz. Neste exemplo, os três elementos da matriz são: a data de observação, o valor de abertura e o valor de fechamento da ação.
|
1 2 3 4 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] } |
Use o tempo EPOCH - Tempo de época é usado em vez da cadeia de datas ISO para reduzir o tamanho de cada ponto de dados e melhorar o tempo de processamento.
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart and dend denote the */ "ts_end": 1672617599999,/* time range of all data points in ts_data */ "ticker": "XYZ" } |
Consulta otimizada com uma nova função _timeseries
O recurso Couchbase Time Series inclui um novo _timeseries função. A função atende a vários propósitos:
-
- Ele gera dinamicamente os objetos de série temporal a partir do ts_data matriz de matrizes
- Ele transmite os resultados com eficiência quando é usado com UNNEST, otimizando o tempo de resposta e o uso da memória
- Ele pode gerar automaticamente o registro de data e hora para cada ponto de dados quando o parâmetro ts_interval é usado
- Ele oferece suporte a casos de uso de séries temporais mais avançados para intervalos irregulares de pontos de dados de séries temporais, como, por exemplo, em vez de vários conjuntos de pontos de dados por registro de data e hora
Consulte o Documentação de séries temporais do Couchbase para obter mais detalhes.
Armazenamento otimizado de índices
Devido à forma como o Couchbase armazena dados de séries temporais, com cada ponto de dados armazenado como um elemento em uma matriz dentro de um documento JSON, podemos otimizar nossa estratégia de indexação do banco de dados. Especificamente, como cada documento contém a hora inicial e final de todos os pontos de dados na matriz, podemos criar uma única definição de índice para cada documento. Isso significa que, mesmo para grandes conjuntos de dados de séries temporais com milhões de pontos de dados, podemos armazenar os dados em apenas alguns documentos, em vez de um documento por ponto de dados.
Por exemplo, um conjunto de dados de série temporal com 1 milhão de pontos de dados pode ser armazenado em apenas 1.000 documentos, supondo que cada ts_data pode armazenar até 1.000 elementos de dados e o tamanho do documento permanece abaixo do limite de 20 MB de documentos JSON do Couchbase. Isso não apenas reduz o número de documentos necessários para armazenar os dados, mas também leva a tamanhos de índice menores, melhorando o desempenho do banco de dados e reduzindo os requisitos de espaço em disco.
Em resumo, aproveitando a capacidade do Couchbase de armazenar dados de séries temporais como matrizes dentro de documentos JSON, podemos otimizar nossa estratégia de indexação para reduzir significativamente o número de documentos necessários e reduzir o tamanho do índice, resultando em um desempenho de consulta mais rápido e no uso mais eficiente dos recursos de armazenamento.
|
1 |
CREATE INDEX ix1 ON docs(ticker, ts_end, ts_start); |
Retenção de dados
Os documentos de série temporal são armazenados como documentos JSON padrão no Couchbase. Portanto, o mesmo Time-To-Live (TTL) pode ser definido durante o processo de carregamento de dados.
|
1 2 3 4 5 |
/* The document will be automatically removed in 30 days */ INSERT INTO coll1 (KEY, VALUE) VALUES ("stock:XYZ:d1", {"ticker":"XYZ",..}, {"expiration":60*60*24*30}); |
Exemplo de passo a passo
Então, vamos percorrer o processo de carregamento de um conjunto de dados de preços de ações reais no Couchbase usando o modelo de dados de série temporal, conforme definido pelo recurso.
Como descrevi acima, o recurso de série temporal do Couchbase requer o documento JSON nesse formato específico:
|
1 2 3 4 5 6 7 |
docid: "stock:XYZ:d1" { "ts_data": [ [1672531200000, 92.08, 95.62],[1672531201000, 95.62, 99.25],..] "ts_start": 1672531200000 /* dstart and dend denote the */ "ts_end": 1672617599999,/* time range of all data points in ts_data */ "ticker": "XYZ" } |
Siga as etapas abaixo se precisar converter seus próprios dados de série temporal no formato acima.
O conjunto de dados usado aqui é para o preço das ações da XYZ Inc de 2013 a 2015.
XYZ_data.csv
|
1 2 3 4 |
date,open,high,low,close,volume,Name 2013-02-08,27.285,27.595,27.24,27.295,5100734,XYZ 2013-02-11,27.64,27.95,27.365,27.61,8916290,XYZ 2013-02-12,27.45,27.605,27.395,27.545,3866508,XYZ |
Migrar dados para a estrutura de dados de série temporal do Couchbase
- Carregue o arquivo CSV em uma coleção do Couchbase:
|
1 |
cbimport csv --infer-types -c https://<cluster>:8091 -u <login> -p <password> -d 'file://XYZ_data.csv' -b 'ts' --scope-collection-exp "s1.c1" -g "#UUID#" |
A importação criará um documento JSON na coleção c1 para cada ponto de dados.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "c1": { "Name": "XYZ", "close": 55.99, "date": "2016-05-25T00:00:00.000Z", "high": 56.69, "low": 55.7699, "open": 56.47, "volume": 9921707 } }, { "c1": { "Name": "XYZ", "close": 31.075, "date": "2013-06-11T00:00:00.000Z", "high": 31.47, "low": 30.985, "open": 31.15, "volume": 5540312 } }, … |
2. Use o SQL++ para transformar a coleção c1 na estrutura de dados da série temporal e, em seguida, insira na coleção c3:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO ts.s1.c3 (KEY _k, VALUE _v) SELECT "stock:XYZ:2013" _k, {"ticker": a.Name , "ts_start" : MIN(STR_TO_MILLIS(a.date)), "ts_end" : MAX(STR_TO_MILLIS(a.date)), "ts_data" : ARRAY_AGG([STR_TO_MILLIS(a.date), a.close]) } _v FROM ts.s1.c1 a WHERE a.date BETWEEN "2013-01-01" AND "2013-12-31" GROUP BY a.Name; |
O SQL++ executa uma INSERT SELECT e cria um único documento com a estrutura necessária para o processamento de séries temporais do Couchbase. Observe que o ts_data contém todos os pontos de dados de preço de fechamento diário de 2013.
3. Repita o INSERT/SELECT para 2014 e 2015.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
[ { "id": "stock:XYZ:2013", "ticker": "XYZ", "ts_start": 1387497600000, "ts_end": 1365465600000, "ts_data": [ [ 1387497600000, 38.67 ], [ 1380585600000, 36.21 ], ...] }, { "id": "stock:XYZ:2014", "ticker": "XYZ", "ts_start": 1413331200000, "ts_end": 1402444800000, "ts_data": [ [ 1413331200000, 42.59 ], [ 1399507200000, 36.525], ...] }, { "id": "stock:XYZ:2015", "ticker": "XYZ", "ts_start": 1444780800000, "ts_end": 1436313600000, "ts_data": [ [ 1444780800000, 62.92 ], [ 1421280000000, 46.405], ...] } ] |
Estratégias de ingestão de dados
Há vários cenários que você pode ter para o carregamento incremental de seus documentos JSON de série temporal.
-
- Adição de um intervalo de pontos de dados como um novo documento JSON - Para esse cenário, você pode usar o INSERT do SQL++ acima. Você só precisa garantir que os intervalos de pontos de dados não se sobreponham aos documentos existentes.
- Adição de um intervalo de pontos de dados ao um documento JSON existente - Aqui você tem duas opções:
- Substitua o documento inteiro usando UPSERT/SELECT como no INSERT/SELECT
- Use o Couchbase SDK para anexar apenas os pontos de dados do novo item
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// Initialize the Couchbase cluster and bucket objects Cluster cluster = CouchbaseCluster.create("<cluster>"); Bucket bucket = cluster.openBucket("<your_bucket>"); // Specify the document ID and the sub-document path to update String docId = "<doc_id>"; // eg. "stock:XYZ:2015" String path = "a.ts_data[-1]"; // -1 specifies the last element of the array // Create a JSON object representing the new array element to add JsonObject newElement = JsonObject.create() .put("0", "2015-12-31") .put("1", 300); // Use the sub-document API to update the array JsonDocument doc = bucket.get(docId); if (doc != null) { bucket.mutateIn(docId) .arrayAppend(path, newElement) .execute(); } |
Consultar os dados da série temporal
Antes de consultar os dados, você deve criar um índice. Embora isso não seja absolutamente necessário, pois temos apenas alguns documentos, mesmo que cada documento consista no ano inteiro do preço diário das ações.
|
1 |
CREATE INDEX ix1 ON c3(ticker, ts_end, ts_start); |
Em seguida, definimos o intervalo de dados no qual queremos que a consulta seja executada. Aqui, definimos uma matriz com dois elementos, o tempo de época inicial e final para 2013-01-01 e 2015-12-31.
|
1 |
\set -$ts_ranges [1682947800000,1685563200000]; |
Visualizar os pontos de dados da série temporal
Use o _timeseries conforme descrito acima:
|
1 2 3 |
SELECT t.* FROM c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' AND (d.ts_start <= $ts_ranges[1] AND d.ts_end >= $ts_ranges[0]); |
Resultados:
|
1 2 3 4 5 6 |
[ { "_t": 1413331200000, "_v0": 42.59 }, { "_t": 1399507200000, "_v0": 36.525}, { "_t": 1392854400000, "_v0": 37.79 }, { "_t": 1395100800000, "_v0": 39.82 }, { "_t": 1410307200000, "_v0": 41.235}, … ] |
Exibir os dados da série temporal com a função Window do SQL++
Agora que podemos acessar todo o conjunto de dados, podemos usar a função de janelas SQL++ do Couchbase para executar algumas funções avançadas de agregação. Essa consulta retorna a média diária da ação, bem como uma média móvel de 7 dias.
|
Resultados:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
[ { "day": "2014-01-02T00:00:00Z", "dayavg": 39.12, "sevendaymovavg": 39.12 }, { "day": "2014-01-03T00:00:00Z", "dayavg": 39.015, "sevendaymovavg": 39.067499999999995 }, { "day": "2014-01-06T00:00:00Z", "dayavg": 38.715, "sevendaymovavg": 38.949999999999996 }, { "day": "2014-01-07T00:00:00Z", "dayavg": 38.745, "sevendaymovavg": 38.89875 }, { "day": "2014-01-08T00:00:00Z", "dayavg": 38.545, "sevendaymovavg": 38.827999999999996 }, .. ] |
Usar gráficos do SQL++ em dados de séries temporais
Neste exemplo, usamos o recurso Time Series do Couchbase e seu recurso de gráficos para rastrear uma estratégia de negociação popular, rastreando as médias móveis rápidas (5 dias) em relação às médias móveis lentas (30 dias).
|
1 2 3 4 5 6 7 8 9 |
SELECT MILLIS_TO_TZ(day*86400000,"UTC") AS day, dayavg , AVG(dayavg) OVER (ORDER BY day ROWS 5 PRECEDING) AS fma, AVG(dayavg) OVER (ORDER BY day ROWS 30 PRECEDING) AS sma FROM ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' <span style="font-weight: 400"> AND (d.ts_start <= $ts_ranges[</span><span style="font-weight: 400">1</span><span style="font-weight: 400">] AND d.ts_end >= $ts_ranges[</span><span style="font-weight: 400">0</span><span style="font-weight: 400">])</span> GROUP BY IDIV(t._t,86400000) AS day LETTING dayavg = AVG(t._v0); |
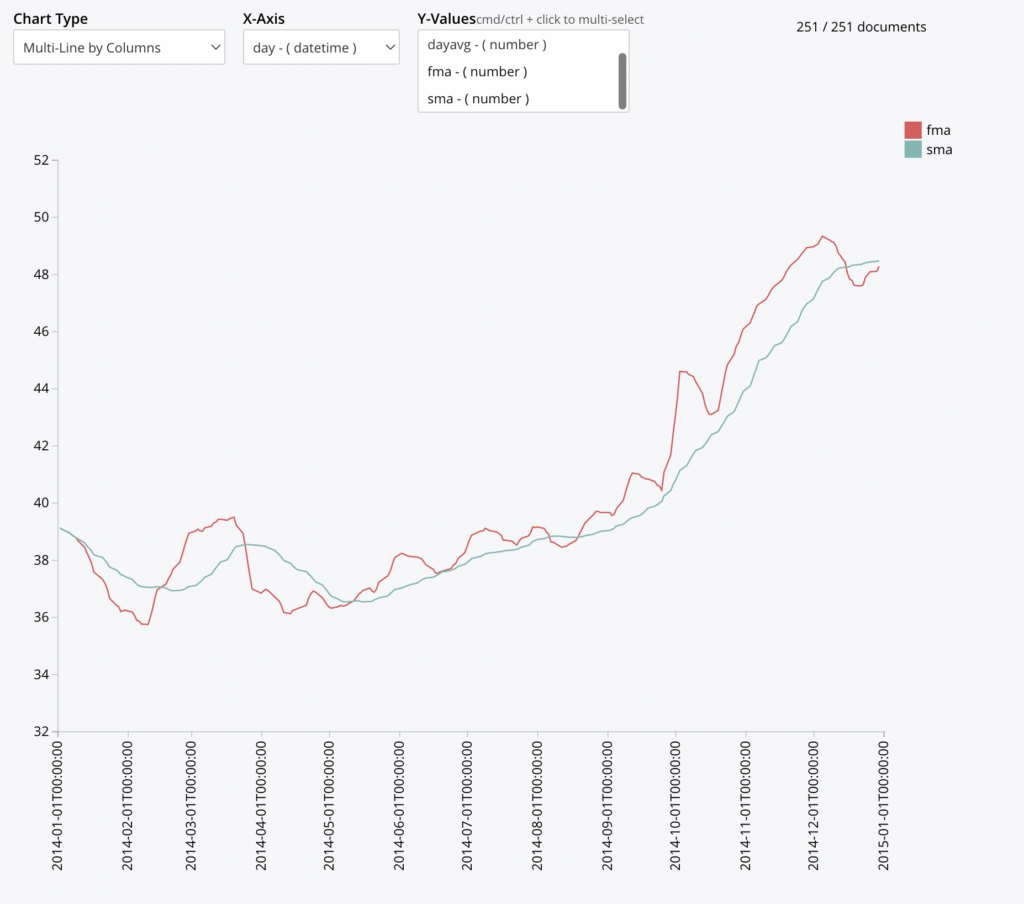
A ideia por trás dessa estratégia é identificar quando a tendência de curto prazo (FMA) está cruzando acima ou abaixo da de longo prazo (SMA). Quando a FMA cruza a SMA, é considerado um sinal de compra e, inversamente, um sinal de venda quando a FMA cruza abaixo da SMA.
Usar a expressão de tabela comum do SQL++ com dados de série temporal
Essa análise calcula o Índice de Força Relativa, ou seja, a velocidade e a variação dos movimentos do preço das ações para identificar quando uma ação está sobrecomprada ou vendida. Um valor de RSI > 70 pode indicar que a ação está sobrecomprada e deve ser corrigida. Por outro lado, quando o RSI é < 30, pode indicar que a ação está sobrevendida e deve se recuperar.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
WITH price_change AS ( SELECT t._t as date, t._v0 AS price, LAG(t._v0, 1) OVER (ORDER BY t._t) AS prev_price, ROW_NUMBER() OVER (ORDER BY t._t) AS rn FROM ts.s1.c3 AS d UNNEST _timeseries(d, {"ts_ranges":$ts_ranges}) AS t WHERE d.ticker = 'XYZ' AND ( $ts_ranges[0] BETWEEN d.ts_start AND d.ts_end OR (d.ts_start BETWEEN $ts_ranges[0] AND $ts_ranges[1] AND d.ts_end BETWEEN $ts_ranges[0] AND $ts_ranges[1] ) OR $ts_ranges[1] BETWEEN d.ts_start AND d.ts_end ) ), gain_loss AS ( SELECT pc.date, pc.price, pc.prev_price, CASE WHEN pc.price > pc.prev_price THEN pc.price - pc.prev_price ELSE 0 END AS gain, CASE WHEN pc.price < pc.prev_price THEN pc.prev_price - pc.price ELSE 0 END AS loss, pc.rn FROM price_change pc ), avg_gain_loss AS ( SELECT gl.date, AVG(gl.gain) OVER (ORDER BY gl.rn ROWS BETWEEN 13 PRECEDING AND CURRENT ROW) AS avg_gain, AVG(gl.loss) OVER (ORDER BY gl.rn ROWS BETWEEN 13 PRECEDING AND CURRENT ROW) AS avg_loss, gl.rn FROM gain_loss gl ), rsi AS ( SELECT agl.date, 100 - (100 / (1 + (agl.avg_gain / agl.avg_loss))) AS rsi_val FROM avg_gain_loss agl WHERE agl.rn >= 14 ), buy_sell_signals AS ( SELECT rsi.date, rsi.rsi_val, CASE WHEN rsi.rsi_val < 30 THEN 'buy' WHEN rsi.rsi_val > 70 THEN 'sell' END AS signal FROM rsi ) SELECT * FROM buy_sell_signals bss WHERE bss.signal IS NOT NULL; |
Resultados:
|
||
Principais conclusões
Armazenamento de dados - O armazenamento geral de dados para a série temporal do Couchbase dependerá de quantos pontos de dados você escolherá para empacotar na matriz. Se a análise for feita por hora, dia ou mês, empacote os pontos de dados de acordo com o período. Observe que o armazenamento também pode ser reduzido ainda mais se for usada uma série temporal regular em que o elemento de tempo na série temporal possa ser derivado e, portanto, não exija o armazenamento do elemento de tempo da época.
Elemento de dados e retenção de dados com TTL - O tamanho máximo do documento JSON no Couchbase é de 20 MB. Embora isso possa significar que você pode empacotar um grande número de pontos de dados na matriz de série temporal, você também deve estar ciente de que a configuração Time To Live está no nível do documento, e não no nível do elemento da matriz.
Ingestão de dados - O aplicativo é responsável pela estratégia de ingestão de dados. Como empacotar o ponto de dados da série temporal nas matrizes e o tamanho da matriz. Isso significa que ele precisa decidir se vai anexar a um documento existente ou iniciar um novo.
Para saber mais, consulte o Documentação de séries temporais do Couchbase.