As compilações e atualizações de índice acabam de receber uma grande melhoria de desempenho com a introdução de escopos e coleções no Couchbase 7.
A versão 7.0 do Couchbase Server introduz a separação dos dados do Bucket em Escopos lógicos e coleções sobre o banco de dados de documentos JSON. Essa separação permite organizar seus dados em diferentes esquemas e tabelas, conceitos com os quais a maioria dos usuários de RDBMS já está familiarizada. Além disso, Os escopos e as coleções permitem um controle de acesso mais refinado baseado em funções para os dados que você armazenou no Couchbase.
Observação: A introdução de escopos e coleções não significa que os dados de um determinado tipo deve ser separado e armazenado em sua própria coleção. Na verdade, é o oposto: uma coleção é, antes de tudo uma coleção de documentos JSONe, dessa forma, você mantém toda a flexibilidade de um banco de dados sem esquema. Ou melhor, você crie o esquema que seu aplicativo exige.
Com essas otimizações do Serviço de Índice, você pode decidir migrar do modelo de Bucket para o novo modelo de Coleções - ou talvez já tenha um Couchbase cluster. Neste artigo, mostrarei algumas maneiras de otimizar o Serviço de Índice para ajudá-lo a decidir o que é melhor para a sua implantação. Vamos nos aprofundar.
O pipeline de índice para o modelo de balde
O diagrama abaixo mostra o pipeline de criação de índice no modelo do Couchbase Bucket.
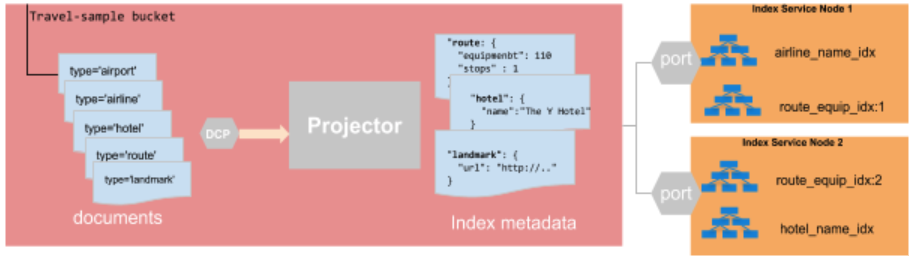
- O processo do projetor no Serviço de dados é o único responsável pela transmissão dos dados do Bucket para o Serviço de indexação.
- O projetor usa um único fluxo de protocolo de alteração de banco de dados (DCP) para avaliar todas as mutações e determinar se um documento deve ser transmitido para o serviço de índice, com base nos metadados do índice.
- O projetor transmite apenas as colunas específicas que o Serviço de Índice mantém para seus índices.
Caso não tenha ficado claro no diagrama acima, o projetor deve considerar todos Mutações de balde para todos dos índices no cluster.
O pipeline de índice para o modelo de coleção
No novo modelo de Coleção do Couchbase 7.0, o fluxo de DCP entre o Serviço de Dados e o Serviço de Índice está no nível da Coleção. Embora essa alteração implique mais fluxos de DCP, na verdade ela beneficia o processamento downstream quando o projetor decide para qual Serviço de Índice enviará as mutações.
Há uma pequena diferença em como isso funciona para a criação inicial do índice em relação às atualizações do índice. Primeiro, vamos dar uma olhada no processo de criação do índice inicial no novo modelo Collections.
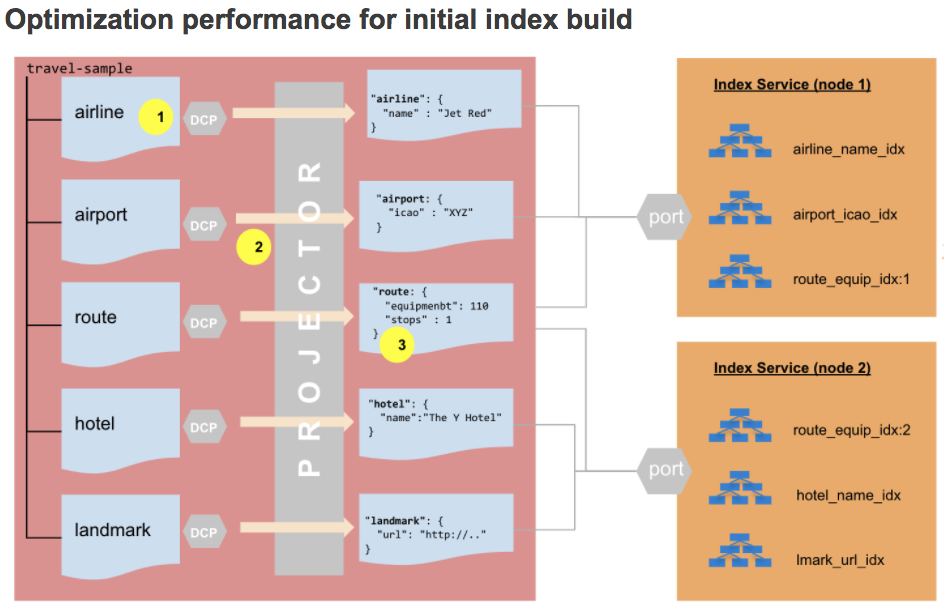
- Os índices são criados por coleção.
- Um fluxo DCP é criado para cada coleção durante a criação do índice inicial, resultando em uma carga de trabalho menor para o projetor.
- O projetor não precisa mais avaliar o índice
ONDEpara determinar se uma mutação está qualificada para o índice.
Agora vamos dar uma olhada no novo processo de atualização do índice no Couchbase 7.0:
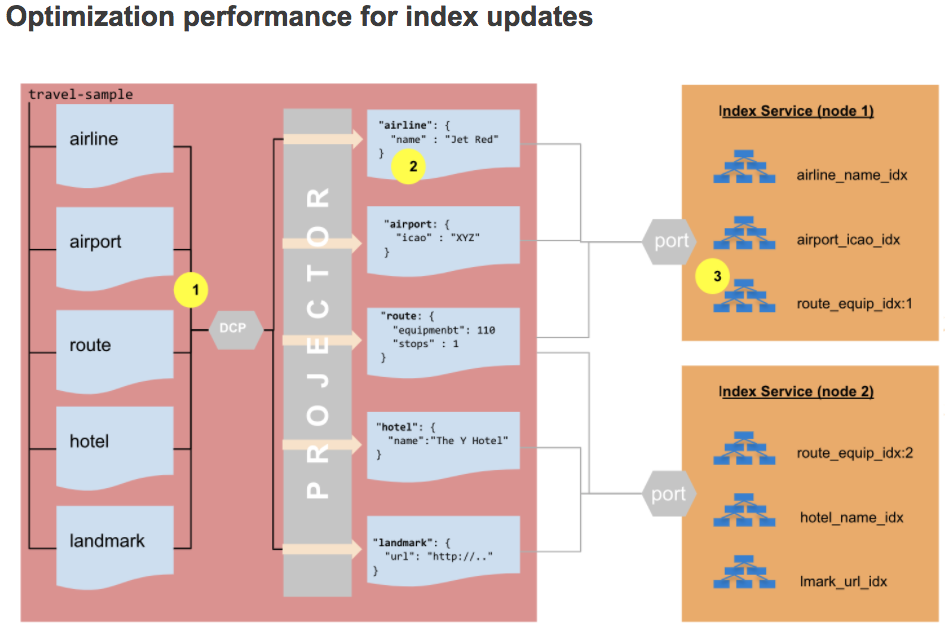
- Os dados do fluxo DCP agora são prefixados com
ID da coleçãopara que o projetor saiba para qual índice enviar a alteração. - O projetor não precisa mais avaliar o índice
ONDEcláusula. - A verificação da ingestão de índices é limitada aos índices definidos na coleção do documento atualizado, em vez de todos os índices no Bucket. Essa limitação resulta em uma economia significativa em termos de CPU e E/S de disco
Conclusão
Do ponto de vista da configuração, a introdução do Couchbase Collections não exige que você altere nada no Serviço de Índice. No entanto, você precisa especificar o nome da Coleção - em vez de apenas o nome do Bucket - ao criar índices em uma Coleção específica.
A versão 7.0 implementou essas alterações para lhe dar a vantagem de trabalhar com conjuntos de dados menores em vez de lidar com mutações em um Bucket inteiro. Esse benefício de dados pequenos permeia todos os estágios do Serviço de Índice, desde o projetor, passando pelo indexador, até a camada de armazenamento downstream.
Se você quiser saber mais sobre a versão 7.0 do Couchbase Server, Confira o que há de novo e/ou As notas da versão 7.0.
Experimente o Couchbase 7.0 hoje mesmo
Muito boa a postagem do blog, adorei!