Você certamente já ouviu isso antes: "O que é medido é feito."
É verdade: o que você observa e mede é o que pode melhorar.
A chave para qualquer melhoria é identificar primeiro o que para medir e, em seguida, coletar as métricas relacionadas. Usando essas métricas, você pode ajustar o trabalho subjacente e analisar a eficácia de quaisquer alterações. Em seguida, repita o ciclo até que você tenha melhorado o suficiente.
Na Couchbase, precisávamos melhorar algumas de nossas operações cotidianas, por isso criamos painéis de observabilidade para nos ajudar a identificar problemas e acompanhar as melhorias. Usamos uma combinação de Prometeuque simplifica o armazenamento e a consulta de dados de séries temporais, e Grafanaque pode ser usado para fazer visualizações de dados impressionantes. Além disso, usamos o Couchbase para armazenar dados históricos para uso posterior com seu Pesquisa de texto completo e Análises ferramentas.
Neste artigo, mostraremos como criar seu próprio painel de observabilidade usando o Prometheus, o Grafana e o Couchbase.
Seus pipelines internos de fontes de dados podem variar, assim como seu software de visualização de dados. No entanto, as etapas que mostraremos a você hoje devem ser aplicáveis a várias ferramentas e implementações.
Painel de observabilidade genérico: Projeto e arquitetura
Para criar uma ferramenta reutilizável e dimensionável, é melhor trabalhar com designs e modelos comuns como primeira etapa. A partir daí, você pode personalizar conforme necessário. Com essa abordagem, é rápido e fácil desenvolver painéis futuros.
O diagrama abaixo mostra a arquitetura genérica dos painéis de observabilidade que criaremos juntos:
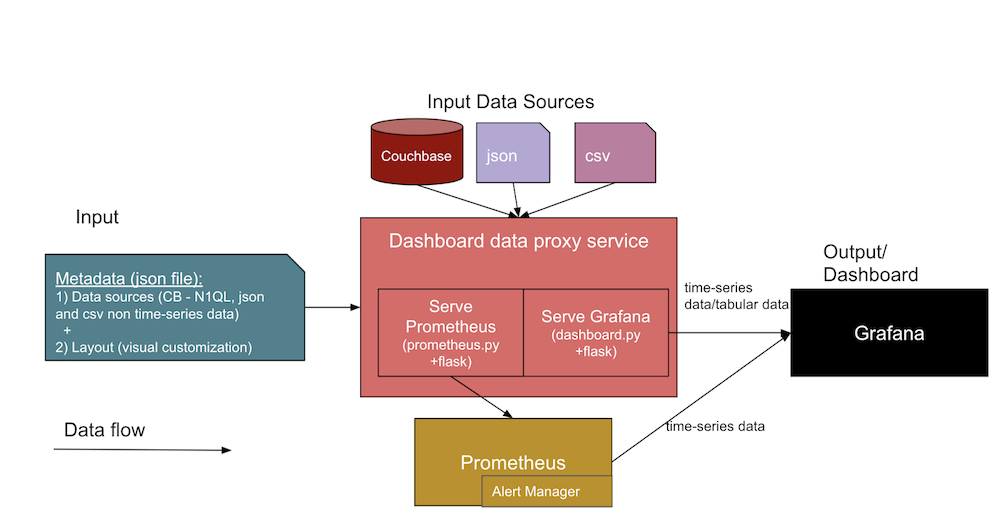
Nessa arquitetura, duas entradas de dados diferentes formam uma interface para o serviço de painel. Vamos dar uma olhada mais detalhada em cada uma delas a seguir.
- Metadados JSON sobre o painel
- Definições de fonte de dados, incluindo informações sobre as fontes de dados (como URL do banco de dados, SQL, credenciais), os caminhos de arquivo e URLs de artefatos do Jenkins.
- O modelo de layout do Grafana (ou visualização de painel visual), que projetaremos primeiro e depois usaremos como modelos para painéis em nossos painéis posteriores.
- Os arquivos de fonte de dados reais de
.jsone.csve do Couchbase.- O design desses painéis de observabilidade é compatível com várias fontes de dados, como o Couchbase Server, e arquivos diretos, como Documentos JSON e arquivos CSV (Comma Separated Values, valores separados por vírgula). Você pode estender o código do serviço de proxy do databoard (em
dashboard.py) para analisar outros formatos de dados, conforme necessário.
- O design desses painéis de observabilidade é compatível com várias fontes de dados, como o Couchbase Server, e arquivos diretos, como Documentos JSON e arquivos CSV (Comma Separated Values, valores separados por vírgula). Você pode estender o código do serviço de proxy do databoard (em
O resultado esperado será uma interface de usuário do painel do Grafana e métricas coletadas de séries temporais do Prometheus a partir das duas entradas listadas acima. A parte central do diagrama acima mostra os diferentes serviços na coleção que dão suporte à criação dos painéis.
Vamos dar uma olhada mais de perto nas diferentes facetas e serviços incluídos no diagrama de arquitetura:
- Serviço de proxy do painel:
- Este é um serviço genérico de aplicativo da Web do Python Flask (
dashboard.py) que interage com o serviço Grafana para servir os dados tabulares e outras APIs como/consulta,/adicionar,/importare/exportarendpoints. Você pode desenvolver um modelo semelhante para ter um modelo genérico (JSON) para os painéis no Grafana e anexar os pontos de dados do gráfico e os pontos de dados tabulares como JSON de destino para exibição em seu painel do Grafana.
- Este é um serviço genérico de aplicativo da Web do Python Flask (
- Serviço de exportação Prometheus:
- Esse é um exportador personalizado do Prometheus (digamos
prometheus.py) Serviço de aplicativo Web do Flask que se conecta às fontes de dados e atende às solicitações do próprio Prometheus. Em um alto nível, ele atua como uma ponte entre o Prometheus e as fontes de dados. Observe que esse serviço é necessário somente quando a fonte de dados deve ser mantida para séries temporais (muitas tendências precisam disso).
- Esse é um exportador personalizado do Prometheus (digamos
- Serviço Grafana:
- Essa é a própria ferramenta regular do Grafana que você usa para criar painéis e exibi-los como painéis.
- Serviço Prometheus:
- Essa é a própria ferramenta normal do Prometheus que mantém suas métricas como dados de série temporal.
- Gerenciador de alertas:
- O Alert Manager tem regras de alerta personalizadas que recebem alertas quando determinados limites são atingidos.
- Outros serviços:
- Couchbase: Talvez você já esteja usando isso NoSQL mas, caso contrário, é possível instalá-lo por meio de um contêiner ou diretamente em um host diferente. O Couchbase armazena seus dados como documentos JSON, ou você pode fazer com que ele armazene os campos obrigatórios como documentos separados para tendências históricas enquanto prepara seus dados de saúde ou de tendências.
- Docker: Você precisará instalar o software docker agent no host para usar essa implantação de serviço em contêiner.
Exemplo de estrutura JSON do painel
Na tabela abaixo, você verá uma amostra da estrutura dos metadados de entrada e da fonte de dados de entrada.
| Estrutura JSON de metadados de entrada: | Estrutura das fontes de dados de entrada: |
{ |
//Fonte doouchbase |
Implantação dos serviços do Observability Dashboard
Use o docker-compose abaixo para exibir todos os serviços necessários - por exemplo, proxy de painel, Grafana, Prometheus, exportador, gerenciador de alertas - que aparecem no diagrama de arquitetura acima para nossos painéis de observabilidade. Você pode instalar o Couchbase em um host diferente para armazenar seus dados de alto volume em crescimento.
Para falar sobre isso: docker-compose up
Em seguida, visite http://host:3000 para a página do Grafana.
Para derrubar: docker-compose down
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
versão: "2" serviços: painel de controle: reiniciar: a menos que-interrompido construir: ../../ portos: - 5001:5000 ambiente: - GRAFANA_HOST=http://admin:password@grafana:3000 volumes: - ./configuração/alvos.json:/aplicativo/alvos.json grafana: imagem: grafana/grafana:8.0.1 reiniciar: a menos que-interrompido volumes: - ./configuração/grafana:/var/lib/grafana ambiente: GF_INSTALL_PLUGINS: "simpod-json-datasource,marcusolsson-csv-datasource,ae3e-plotly-panel" GF_AUTH_ANONYMOUS_ENABLED: "true" (verdadeiro) GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS: "ae3e-plotly-panel" GF_RENDERING_SERVER_URL: http://renderer:8081/render GF_RENDERING_CALLBACK_URL: http://grafana:3000/ portos: - 4000:3000 renderizador: imagem: grafana/grafana-imagem-renderizador:mais recente prometeu: reiniciar: a menos que-interrompido imagem: baile/prometeu volumes: - ./configuração/prometeu.yml:/etc/prometeu/prometeu.yml - ./configuração/alerta.regras.yml:/etc/prometeu/alerta.regras.yml exportador: reiniciar: a menos que-interrompido construir: ../../exportador volumes: - ./configuração/consultas.json:/aplicativo/consultas.json gerenciador de alertas: reiniciar: a menos que-interrompido imagem: baile/gerenciador de alertas portos: - 9093:9093 volumes: - ./configuração/gerenciador de alertas.yml:/etc/gerenciador de alertas/gerenciador de alertas.yml - ./configuração/alert_templates:/etc/gerenciador de alertas/modelos |
O conteúdo dos arquivos de referência de serviço acima - ou trechos, para ser breve - pode ser encontrado em a seção de implementação abaixo.
Com essas ferramentas, você pode criar uma grande variedade de painéis para atender às suas necessidades. Vamos analisar três tipos de painéis de exemplo para que você tenha uma ideia do que é possível fazer.
Exemplos de painéis: Visão geral
| # | Painel de controle | Medidas | Métricas |
| 1 | Painéis de ciclos de teste de regressão funcional | Tendências entre os ciclos de teste de regressão funcional, tanto no nível de construção quanto no nível de componente | total de testes, aprovados, reprovados, abortados, tempo total, tempo de execução novo, etc. |
| 2 | Painéis de uso de Infra VMs, incluindo VMs estáticas e VMs dinâmicas | Histórico e utilização de recursos | contagem ativa, contagem disponível, cálculo de horas/máximo/criadas por dia, semana, mês |
| 3 | Painéis de integridade de VMs de infraestrutura, servidores estáticos, VMs escravas do Jenkins | Monitoramento da integridade da VM, alertas e rastreamento do histórico das VMs | ssh_fail, pool_os vs real_os, usos de cpu-memory-disk-swap, descritores de arquivos, regras de firewall, pool_mac_address vs real_mac_address, dias de inicialização, processos totais e de produtos, versões de aplicativos e serviços instalados etc. |
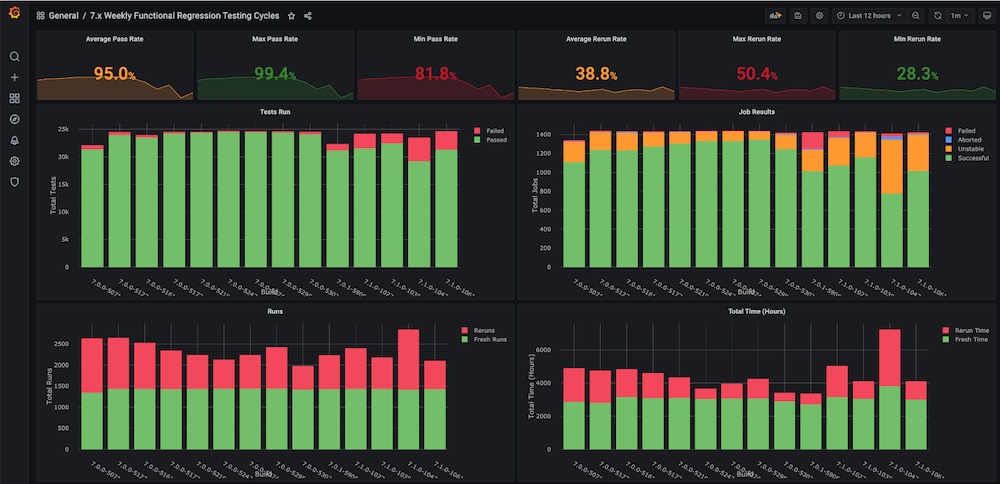
Painel #1: Painel de ciclos de teste de regressão funcional
Problema: Antes de criarmos esse painel para nós mesmos, não havia gráficos de tendências sobre os ciclos de teste de regressão com métricas como tempo total gasto, taxa de aprovação, novas execuções versus repetições (por exemplo, devido a problemas de infraestrutura), número inconsistente de abortos e falhas, e também não havia tendências separadas em nível de componente ou módulo.
Solução: O plano era criar um script de análise de execução que analisasse os dados de teste que já estão armazenados no bucket do Couchbase. Depois disso, obtemos os dados da série temporal do último n número de compilações e métricas direcionadas para cada compilação.
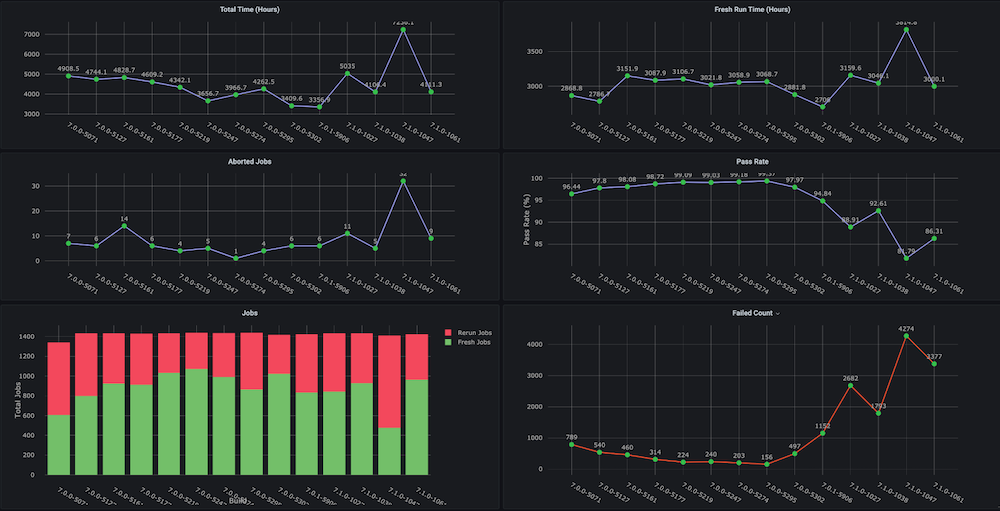
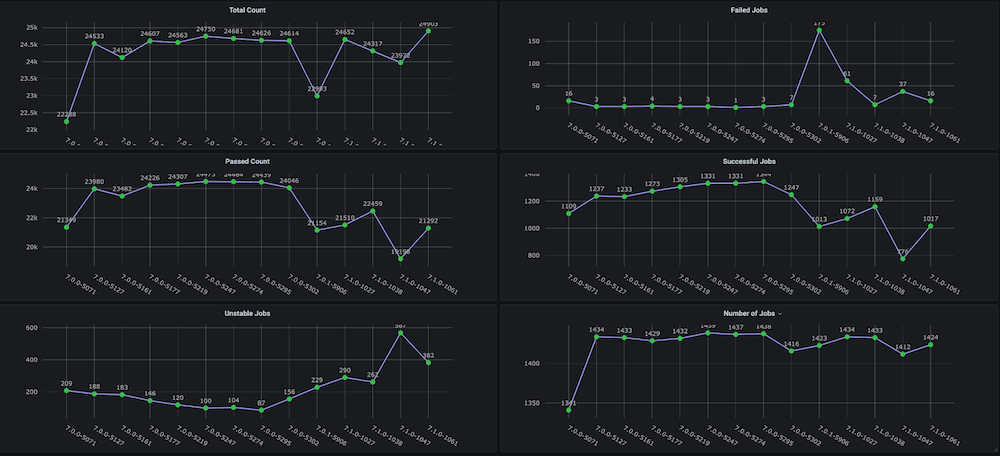
Instantâneos do painel:
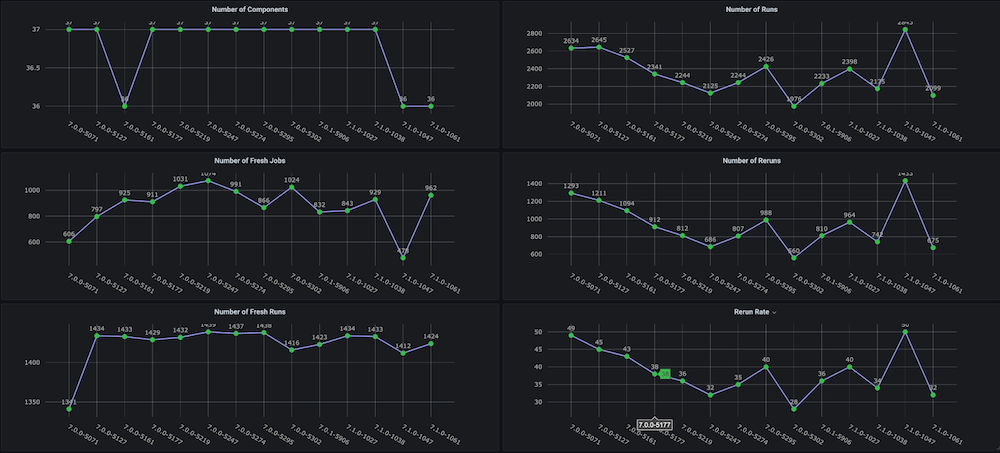
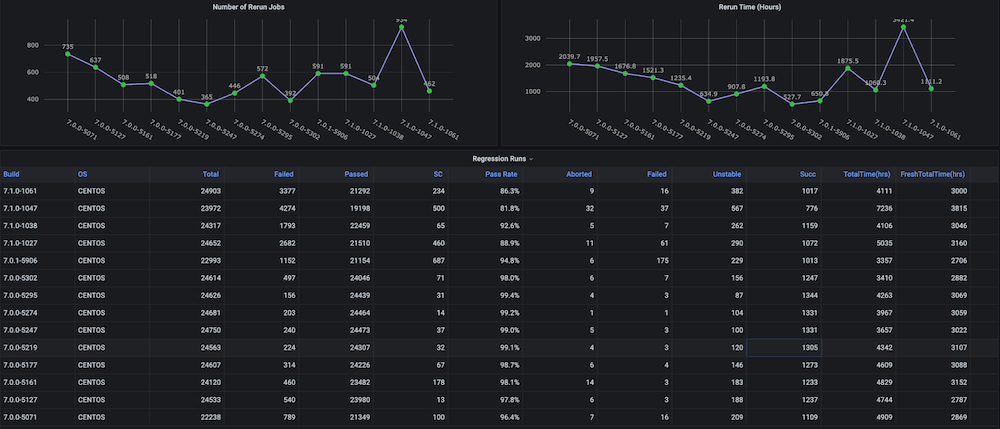
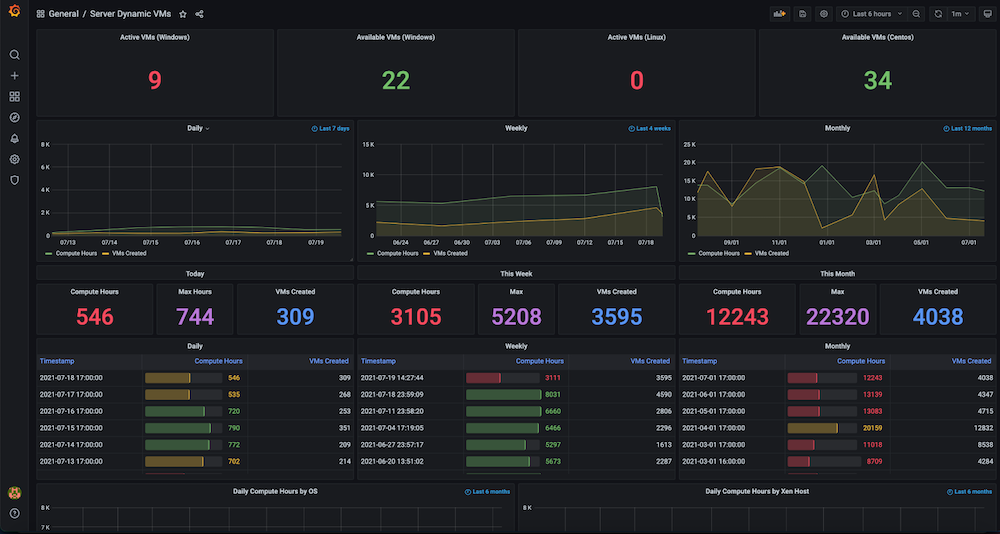
Dashboard #2: Painel de uso de recursos de infraestrutura / VMs
Problema: Antes de criar esse painel, tínhamos um grande número de máquinas virtuais estáticas e dinâmicas, mas não havia nenhum controle de como os recursos de hardware eram utilizados. Não tínhamos informações sobre métricas como VMs ativas usadas no momento, contagem disponível, tempo de máquina usado ou horas de computação diária, semanal ou mensalmente.
Solução: Nosso plano era primeiro coletar os dados de todas as VMs, como IPs alocados e liberados dinamicamente, horários exatos de criação e liberação, bem como quaisquer agrupamentos, como pools, etc. A maioria desses dados já existia em Servidor Couchbase (gerenciados pelos respectivos gerentes de serviço). Usando a flexibilidade de a linguagem de consulta SQL++ (também conhecido como N1QL), conseguimos extrair esses dados em um formato adequado para os gráficos que queríamos mostrar nesse painel de observabilidade.
Instantâneos do painel:
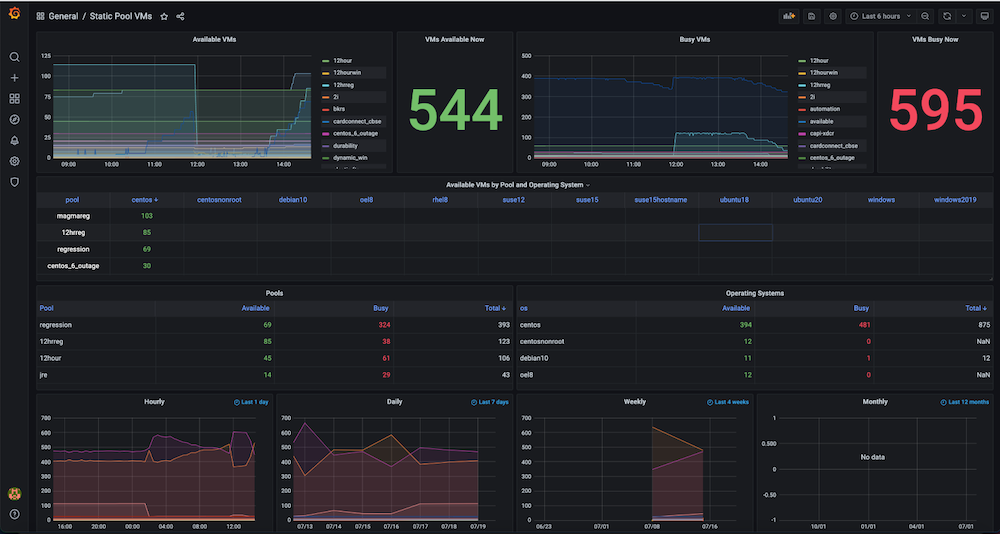
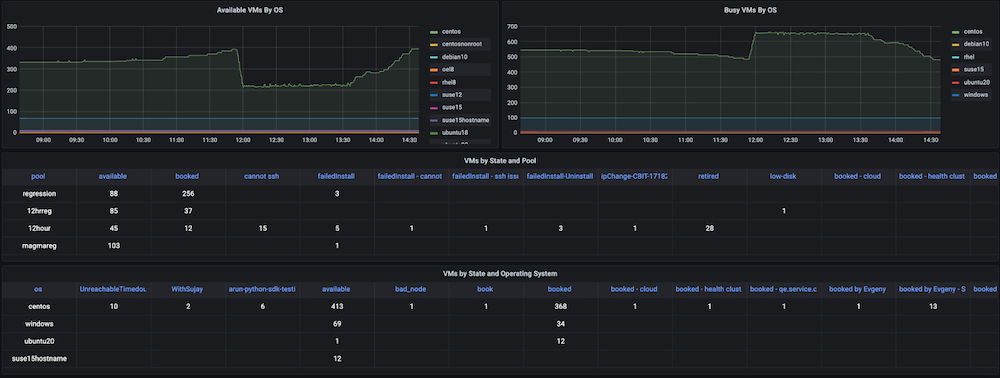
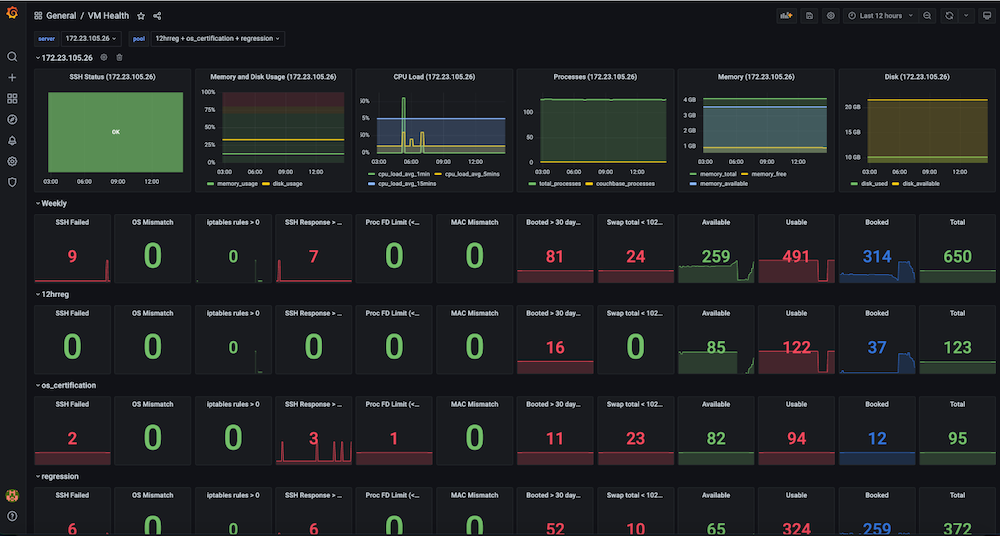
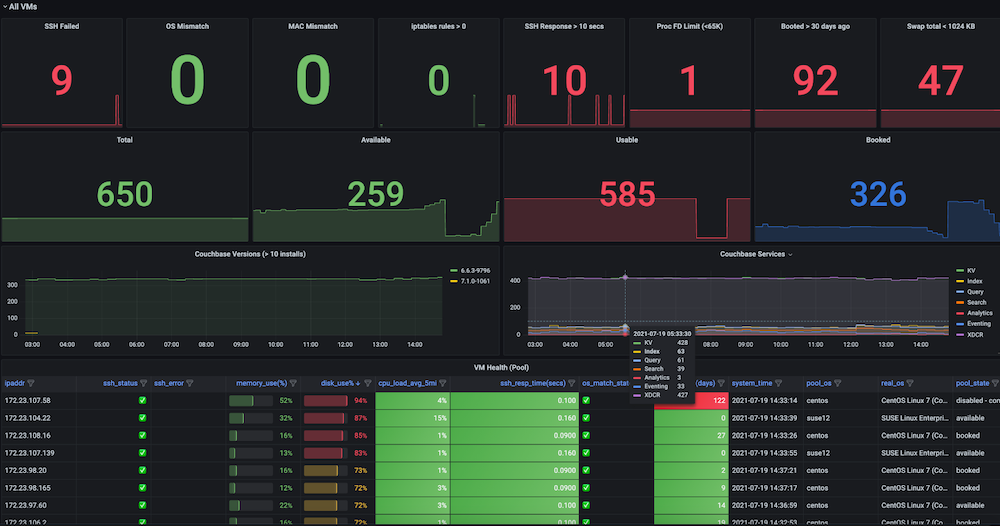
Dashboard #3: Painel de integridade das VMs de infraestrutura
Problema: Antes de termos esse painel, as execuções de testes de regressão estavam falhando de forma inconsistente, e havia problemas de baixa relevância com as VMs. Alguns dos problemas incluíam falhas de SSH, incompatibilidades de sistema operacional, trocas de IP de VM, muitos arquivos abertos, problemas de swap, necessidade de reinicialização, IPs duplicados entre várias execuções, alto uso de memória, disco cheio (/ ou /dados), regras de firewall que interrompiam a conexão do endpoint, problemas de slave devido à alta memória e uso de disco eram comuns. Não havia um painel de observação para analisar e observar essas métricas e também não havia verificações e alertas para a integridade da infraestrutura de teste.
Solução: Decidimos criar uma verificação de integridade periódica automática que captura dados de métricas para as VMs visadas, como ssh_fail, pool_os vs real_os, troca de disco de memória da cpu usos, descritores de arquivos, regras de firewall, endereço_mac_do_spool vs endereço_mac_realdias de inicialização, total de processos do Couchbase, versão e serviços do Couchbase instalados. (Em suma, capturamos cerca de 50 métricas). Essas métricas são expostas como um endpoint do Prometheus que é exibido no Grafana, e as informações também são salvas no Couchbase para análise futura dos dados. Também foram criados alertas para monitorar as principais métricas de integridade em busca de problemas para permitir uma intervenção rápida e, por fim, obter maior estabilidade das execuções de teste.
Instantâneos do painel:
Implementação
Até agora, você viu a arquitetura de alto nível dos painéis de observabilidade, quais serviços são necessários, que tipo de painéis você pode precisar e também como implantar esses serviços. Agora, é hora de examinar alguns detalhes da implementação.
Nossa primeira parada é a coleta e o armazenamento de métricas e a visualização de dados dos painéis. A maioria das etapas de armazenamento e exibição de dados é semelhante para todos os casos de uso, mas a coleta de dados de métricas depende das métricas que você escolher como alvo.
Como obter dados de saúde para seus painéis
No caso de uso de monitoramento de infraestrutura, você precisa coletar várias métricas de integridade de centenas de VMs para criar uma infraestrutura estável.
Para essa etapa, criamos um script Python que faz a conexão SSH com as VMs em paralelo (pool de multiprocessamento) e coleta os dados necessários. No nosso caso, também temos um trabalho do Jenkins que executa periodicamente esse script e coleta os dados de integridade (CSV) e, em seguida, os salva no banco de dados do Couchbase.
O motivo pelo qual criamos esse script personalizado - em vez do exportador de nós prontamente disponível fornecido pelo Prometheus - é que algumas das métricas necessárias não eram compatíveis. Além disso, essa solução era mais simples do que implantar e manter o novo software em mais de 1.000 servidores. O trecho de código abaixo mostra algumas das verificações que estão sendo feitas no nível da VM.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
def check_vm(nome_do_os, hospedeiro): cliente = Cliente SSHC() cliente.set_missing_host_key_policy(AutoAddPolicy()) ... cpus = get_cpuinfo(cliente) meminfo = get_meminfo(cliente) diskinfo = get_diskinfo(cliente) tempo de atividade = get_uptime(cliente) ... retorno ssh_status, '', ssh_resp_time, real_os_version, cpus, meminfo, diskinfo, tempo de atividade, uptime_days, tempo sistêmico, cpu_load, cpu_total_processes, fdinfo, \ iptables_rules_count, mac_address, informação de troca, cb_processos, cb_version, cb_running_serv, cb_ind_serv def get_cpuinfo(ssh_client): retorno ssh_command(ssh_client,"cat /proc/cpuinfo |egrep processor |wc -l") def get_meminfo(ssh_client): retorno ssh_command(ssh_client,"cat /proc/meminfo |egrep Mem |cut -f2- -d':'|sed 's/ //g'|xargs|sed 's/ /,/g'|sed 's/kB//g'") def get_diskinfo(ssh_client): retorno ssh_command(ssh_client,"df -ml --output=size,used,avail,pcent / |tail -1 |sed 's/ \+/,/g'|cut -f2- -d','|sed 's/%//g'") def get_uptime(ssh_client): retorno ssh_command(ssh_client, "uptime -s") def get_cpu_users_load_avg(ssh_client): retorno ssh_command(ssh_client, "uptime |rev|cut -f1-4 -d','|rev|sed 's/load average://g'|sed 's/ \+//g'|sed 's/users,/,/g'|sed 's/user,/,/g'") def get_file_descriptors(ssh_client): retorno ssh_command(ssh_client, "echo $(cat /proc/sys/fs/file-nr;ulimit -n)|sed 's/ /,/g'") def get_mac_address(ssh_client): retorno ssh_command(ssh_client, "ifconfig `ip link show | egrep eth[0-9]: -A 1 |tail -2 |xargs|cut -f2 -d' '|sed 's/://g'`|egrep ether |xargs|cut -f2 -d' '") def get_mac_address_ip(ssh_client): retorno ssh_command(ssh_client, "ip a show `ip link show | egrep eth[0-9]: -A 1 |tail -2 |xargs|cut -f2 -d' '|sed 's/://g'`|egrep ether |xargs|cut -f2 -d' '") |
O trecho de código abaixo mostra como se conectar ao Couchbase usando o Python SDK 3.x com operações de valor-chave, obtendo um documento ou salvando um documento no banco de dados.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
tentar: autônomo.cb_cluster = Aglomerado("couchbase://"+autônomo.cb_host, ClusterOptions(PasswordAuthenticator(autônomo.cb_username, autônomo.cb_userpassword), \ timeout_options=ClusterTimeoutOptions(kv_timeout=timedelta(segundos=10)))) autônomo.cb_b = autônomo.cb_cluster.balde(autônomo.cb_bucket) autônomo.cb = autônomo.cb_b.default_collection() exceto Exceção como e: impressão('Falha na conexão: %s ' % autônomo.cb_host) impressão(e) def get_doc(autônomo, chave_documento, tentativas=3): # .. retorno autônomo.cb.obter(chave_documento) def salvar_doc(autônomo, chave_documento, valor_doc, tentativas=3): #... autônomo.cb.upsert(chave_documento, valor_doc) #... |
Implementação do serviço de proxy do painel
Para os casos de uso de observabilidade de testes, os dados estão em um URL de artefato do Jenkins e também no Couchbase Server. Para unir essas várias fontes de dados (CSV, banco de dados), criamos um serviço de API proxy que aceitaria solicitações do Grafana e retornaria o formato de dados entendido pelo Grafana.
Os trechos de código abaixo fornecem os detalhes da implementação e da preparação do serviço.
dashboard.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Serviço de API do painel # @aplicativo.rota("/query", métodos=['POST']) def consulta(): """ /query responde a uma solicitação de dados do Grafana e é formatados como pontos de dados para dados de séries temporais ou linhas e colunas para dados tabulares """ para alvo em solicitação.json['alvos']: tipo_de_dados = alvo['tipo'] se tipo_de_dados == "timeseries": pontos de dados = calculate_datapoints(alvo) elif tipo_de_dados == "tabela": pontos de dados = calculate_rows_and_columns(alvo) ... def calculate_datapoints(alvo): """ Retorna dados em um formato de série temporal Os pontos de dados são formatados como uma lista de tuplas de 2 itens no formato [value, timestamp] """ ... se alvo['fonte'] == "couchbase": ... elif alvo['fonte'] == "json": ... elif alvo['fonte'] == "csv": |
Dockerfile
|
1 2 3 4 5 6 7 8 9 10 11 |
DE ubuntu:mais recente ENV DEBIAN_FRONTEND "não interativo" CORRER apto-obter atualização -y &lificador;&lificador; apto-obter instalar -y python3-dev python3-tubulação python3-ferramentas de configuração cmake construir-essenciais CORRER mkdir /aplicativo CÓPIA ./requisitos.txt /aplicativo WORKDIR /aplicativo CORRER pip3 instalar -r requisitos.txt CÓPIA ./painel de controle.py /aplicativo CÓPIA ./ponto de entrada.sh /aplicativo PONTO DE ENTRADA ["./entrypoint.sh"] |
ponto de entrada.sh
|
1 2 |
#!/bin/bash python3 painel de controle.py $GRAFANA_HOST |
requisitos.txt
|
1 2 3 |
couchbase==3.0.7 Frasco==1.1.2 solicitações==2.24.0 |
Como obter os dados tabulares no Grafana
O Grafana é uma ótima ferramenta para visualizar dados de séries temporais. No entanto, às vezes você deseja mostrar alguns dados que não são de séries temporais na mesma interface.
Atingimos esse objetivo usando o Plug-in Plotly que é uma biblioteca de gráficos em JavaScript. Nosso principal caso de uso era ilustrar tendências em uma variedade de métricas importantes para nossas execuções semanais de testes de regressão. Algumas das métricas mais importantes que queríamos acompanhar eram a taxa de aprovação, o número de testes, os trabalhos abortados e o tempo total gasto. Desde o lançamento do Grafana 8, há um suporte limitado para gráficos de barras. No momento em que este artigo foi escrito, a funcionalidade do gráfico de barras ainda estava na versão beta e não oferecia todos os recursos de que precisávamos, como o empilhamento.
Nosso objetivo era oferecer suporte a arquivos CSV/JSON genéricos ou a uma consulta SQL++ do Couchbase e visualizar os dados como uma tabela no Grafana. Para obter o máximo de portabilidade, queríamos ter um único arquivo que definisse as fontes de dados e o layout do modelo do Grafana juntos.
Para que os dados tabulares sejam exibidos, abaixo estão as duas opções viáveis.
- Escreva um plug-in de interface do usuário para o Grafana
- Forneça um proxy JSON usando o Plug-in de fonte de dados JSON
Escolhemos a opção 2 para nossa implementação, pois parecia mais simples do que tentar aprender as ferramentas de plug-in do Grafana e criar um plug-in de interface do usuário separado para a configuração.
Observe que, desde a conclusão desse projeto, um novo plug-in foi lançado e permite que você adicione dados CSV diretamente ao Grafana. Se a visualização de dados tabulares de um CSV for sua única exigência, esse plug-in é uma boa solução.
Implementação do Prometheus Service
prometheus.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Configuração global do # Prometheus global: intervalo de raspagem: 1m # Defina o intervalo de raspagem para cada 15 segundos. O padrão é a cada 1 minuto. tempo limite de coleta: 30s Configuração do Alertmanager do # alertas: gerentes de alerta: - static_configs: - alvos: - gerenciador de alertas:9093 rule_files: - "alert.rules.yml" - nome_do_emprego: "prometheus" static_configs: - alvos: ["localhost:9090"] - nome_do_emprego: "automation_exporter" static_configs: - alvos: ["exportador:8000"] |
alert.rules.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
grupos: - nome: alerta.regras regras: - alerta: PoolVMDown expr: vm_health_ssh_status == 0 para: 1m anotações: título: "Pool de servidores VM {{ $labels.ipaddr }} SSH Failed" (Falha no SSH) descrição: "{{ $labels.ipaddr }} SSH failed with error: {{ $labels.ssh_error }}." rótulos: severidade: "crítico" - alerta: PoolVMHighDiskUsage expr: disk_usage >= 95 para: 1m anotações: título: "VM do pool de servidores {{ $labels.ipaddr }} com alto uso de disco" descrição: "{{ $labels.ipaddr }} tem uso de disco de {{ $value }}%" rótulos: severidade: "crítico" |
Como obter métricas personalizadas por meio do Prometheus Exporter
Muitos serviços nativos da nuvem se integram diretamente ao Prometheus para permitir a coleta centralizada de métricas para todos os seus serviços.
Queríamos ver como poderíamos utilizar essa tecnologia para monitorar nossa infraestrutura existente. Se você tem serviços que não expõem diretamente um endpoint de métricas do Prometheus, a maneira de resolver isso é usar um exportador. De fato, existe até mesmo um exportador do Couchbase para expor todas as métricas importantes do seu cluster. (Observação: em Servidor Couchbase 7.0Se o Couchbase 7 estiver disponível, um ponto de extremidade do Prometheus estará disponível diretamente e, internamente, o Couchbase 7 usará o Prometheus para coleta e gerenciamento de estatísticas do servidor para atender a a interface do usuário da web).
Ao criar nossos painéis de observabilidade, tínhamos vários dados armazenados em arquivos JSON, em arquivos CSV e em buckets do Couchbase. Queríamos uma maneira de expor todos esses dados e mostrá-los no Grafana, tanto em formato tabular quanto como dados de série temporal usando o Prometheus.
O Prometheus espera uma saída de texto simples baseada em linhas. Aqui está um exemplo de nosso monitoramento de pool de servidores:
|
1 2 |
available_vms{piscina="12hrreg"} 1 available_vms{piscina="regressão"} 16 |
Vamos dar uma olhada mais de perto em como implementar fontes de dados de arquivos CSV e diretamente do Couchbase.
Arquivos CSV como sua fonte de dados
Cada vez que o Prometheus faz a sondagem do endpoint, buscamos o CSV e, para cada coluna, expomos uma métrica, acrescentando rótulos para várias linhas se um rótulo for fornecido na configuração.
No exemplo acima, o CSV tem a seguinte aparência:
|
1 2 3 |
piscina,disponível_contagem 12hrreg,1 regressão,16 |
Couchbase como sua fonte de dados
Cada vez que o Prometheus faz a sondagem do endpoint, executamos as consultas SQL++ definidas na configuração e, para cada consulta, expomos uma métrica, acrescentando rótulos para várias linhas se um rótulo for fornecido na configuração.
Abaixo está um exemplo de resposta SQL++ que produz as métricas acima:
|
1 2 3 4 5 6 7 8 |
[{ "piscina", "12hrreg", "contagem": 1 }, { "piscina", "regressão", "contagem": 16 }] |
Esse serviço Python exportador expõe um /metrics a ser usado no Prometheus. Essas métricas são definidas em consultas.json e definir quais consultas e colunas CSV devem ser expostas como métricas. Veja o trecho de JSON abaixo (reduzido para fins de brevidade) como um exemplo.
consultas.json
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
{ "clusters": { "static_vms": { "host": "", "nome de usuário": "Administrador", "senha": "xxxx" }, ... }, "consultas": [ { "name" (nome): "available_vms", "cluster": "static_vms", "query" (consulta): "SELECT poolId as `pool`, COUNT(*) AS count FROM (SELECT poolId FROM `QE-server-pool` WHERE IS_ARRAY(poolId)=FALSE and state='available' UNION ALL SELECT poolId FROM `QE-server-pool` UNNEST poolId where `QE-server-pool`.state = 'available' ) AS pools group by poolId", "description" (descrição): "VMs disponíveis para cada pool de servidores", "value_key": "count" (contagem), "rótulos": ["piscina"] }, ... ], "csvs": { "vm_health": "http:///lastSuccessfulBuild/artifact/vm_health_info.csv/", ... }, "colunas": [ { "name" (nome): "memory_usage", "csv": "vm_health", "description" (descrição): "Uso de memória", "coluna": "memory_use(%)", "rótulos": ["ipaddr"] }, { "name" (nome): "disk_usage", "csv": "vm_health", "description" (descrição): "Disk usage" (Uso de disco), "coluna": "disk_use%", "rótulos": ["ipaddr"] }, { "name" (nome): "cpu_load_avg_5mins", "csv": "vm_health", "description" (descrição): "Média de carga da CPU (5 minutos)", "coluna": "cpu_load_avg_5mins", "rótulos": ["ipaddr"] }, { "name" (nome): "vm_health_ssh_status", "csv": "vm_health", "description" (descrição): "Status do SSH", "coluna": "ssh_status", "rótulos": ["ipaddr", "ssh_error", "pool_state", "couchbase_version", "pool_ids"] }, ... ] } |
exportador.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
para opções em configurações['queries' (consultas)] + configurações["colunas"]: registro.informações("Coleção de métricas registradas para {}".formato(opções["nome])) def get_labels(fila, opções): renomear_mapa = opções.obter("rename" (renomear), {}) retorno ["{}=\"{}\"".formato(renomear_mapa[rótulo] se rótulo em renomear_mapa mais rótulo, fila[rótulo]) para rótulo em opções["rótulos"]] def collect_cb(agrupamentos, métricas, opções): linhas = agrupamentos[opções["cluster"]].consulta(opções["query" (consulta)]).linhas() para fila em linhas: se len(opções["rótulos"]) > 0: rótulos = get_labels(fila, opções) métricas.anexar("{}{{{}}} {}".formato( opções["name" (nome)], ",".unir-se(rótulos), fila[opções["value_key"]])) mais: métricas.anexar("{} {}".formato( opções["name" (nome)], fila[opções["value_key"]])) def collect_csv(métricas, opções) arquivo csv = solicitações.obter(csvs[opções["csv"]]).texto.linhas divisórias() leitor = DictReader(arquivo csv) para fila em leitor: se opções["coluna"] não em fila ou fila[opções["coluna"]] == "": continuar se len(opções["rótulos"]) > 0: rótulos = get_labels(fila, opções) métricas.anexar("{}{{{}}} {}".formato( opções["name" (nome)], ",".unir-se(rótulos), fila[opções["coluna"]])) mais: métricas.anexar("{} {}".formato( opções["name" (nome)], fila[opções["coluna"]])) @aplicativo.rota("/metrics") def métricas(): métricas = [] agrupamentos = {} para [nome do cluster, opções] em configurações['clusters'].itens(): se nome do cluster não em agrupamentos: tentar: agrupamentos[nome do cluster] = Aglomerado('couchbase://'+opções['host'], ClusterOptions( PasswordAuthenticator(opções['nome de usuário'], opções['senha']))) exceto Exceção como e: registro.aviso("Não foi possível conectar-se ao cluster {}".formato(e)) registro.depurar("Conectado a {}".formato(opções['host'])) para opções em configurações["consultas"] + configurações["colunas"]: registro.depurar("Coletando métricas para {}".formato(opções["name" (nome)])) tentar: se "cluster" em opções: collect_cb(agrupamentos, métricas, opções) elif "csv" em opções: collect_csv(métricas, opções) mais: aumentar Exceção("Invalid type" (Tipo inválido)) exceto Exceção como e: registro.aviso("Erro ao coletar {}: {}".formato( opções["name" (nome)], e)) retorno Resposta("\n".unir-se(métricas), tipo de imagem="text/plain") |
Implementação do serviço Alert Manager
O Prometheus também oferece suporte a alertas, nos quais ele rastreia métricas específicas para você ao longo do tempo. Se essa métrica começar a retornar resultados, ela acionará um alerta.
No exemplo acima, você poderia adicionar um alerta para quando o pool de regressão não tiver servidores disponíveis. Se você especificar a consulta como available_vms{pool="regression"} == 0 que retornará uma série quando houver 0 disponível. Depois de adicionado, o Prometheus rastreia isso para você (o padrão é a cada minuto). Se isso for tudo o que você faz, visite a interface do usuário do Prometheus e a guia alertas mostrará quais alertas estão sendo disparados.
Com o Alert Manager, você pode dar um passo adiante e conectar serviços de comunicação para que o Prometheus possa alertá-lo por e-mail ou por um canal do Slack, por exemplo, quando um alerta for disparado. Isso significa que você pode ser informado imediatamente pelo método de sua preferência quando algo der errado. No Couchbase, configuramos alertas para sermos notificados sobre o alto uso de disco nos servidores, bem como quando os servidores não puderam ser acessados via SSH. Veja o exemplo abaixo:
alertmanager.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
global: resolve_timeout: 1m smtp_from: qa@couchbase.com smtp_smarthost: correio-com.correio.proteção.perspectiva.com:25 rota: group_by: ["alertname" (nome de alerta)] group_wait: 10s group_interval: 10s repeat_interval: 24h receptor: "infra-email" combinadores: - nome de alerta =~ PoolVMDown|PoolVMOSMismatch|PoolVMHighDiskUsage|SlaveVMHighDiskUsage|Dados de uso de disco alto do SlaveVM receptores: - nome: "infra-email" email_configs: - para: jake.rawsthorne@couchbase.com,jagadesh.munta@couchbase.com |
Conclusão
Concluindo, esperamos que você possa aprender com nossa experiência na criação de painéis de observabilidade que o ajudem a aprimorar as métricas mais importantes em sua implementação ou caso de uso com o poder da visualização de dados.
Em nosso caso, esse esforço nos permitiu encontrar problemas de infraestrutura de servidor e estabilidade de teste. A criação de painéis também reduziu o número de testes com falha, bem como o tempo total de regressão para várias versões do produto.
Esperamos que este passo a passo o ajude a criar painéis de observabilidade melhores no futuro.
Além disso, gostaríamos de agradecer especialmente a Raju e à equipe de QE por seu feedback sobre o aprimoramento das métricas direcionadas.
Por que não criá-lo no Couchbase?

Olá, este blog é muito bom, mas parece estar incompleto em muitas etapas, como a execução. Por favor, me ajude com o código git, pois quero tentar essa execução. Há muito poucas informações sobre como usar o couchbase e qual formulário é usado para postar em seu código. Por favor, ajude ou sugira se você tiver o código git em algum repositório e instruções completas.