Um gráfico para governar todos eles
Com o lançamento do Couchbase Autonomous Operator 2.0, os gráficos do Couchbase Operator e do Cluster foram consolidados em um único gráfico. Essa abordagem simplificada significa que agora é possível instalar o Autonomous Operator, o Admission Controller, o Couchbase Cluster e o Sync Gateway com um único comando.
Instalação aprimorada do CustomResource
O novo Couchbase Chart agora instala todos os CustomResourceDefinitions (CRDs) que são gerenciados pelo operador autônomo. Essa é uma melhoria em relação à versão anterior, que exigia que os usuários instalassem os CRDs como uma etapa separada antes de instalar o Couchbase Chart.
Primeiros passos
Para implementar rapidamente o controlador de admissão e o Operator, bem como um cluster do Couchbase Server:
Adicione o repositório do gráfico do couchbase ao helm:
|
1 2 |
$ leme repo adicionar couchbase https://couchbase-parceiros.github.io/leme-gráficos/ $ leme repo atualização |
Instale o gráfico:
|
1 |
$ leme instalar padrão couchbase/couchbase-operador |
Veja Documentação do Couchbase Helm para obter mais informações sobre como personalizar e gerenciar seus gráficos.
Pré-requisitos
Ao longo deste blog, usaremos exemplos de gráficos do repositório do github do Couchbase Partners. Antes de continuar, vamos clonar o repositório:
|
1 |
$ git clone https://github.com/couchbase-parceiros/leme-gráficos |
Também, Helm 3.1+ é necessário ao instalar o Couchbase Helm Chart oficial.
|
1 2 3 4 |
# linux wget https://obter.leme.sh/leme-v3.2.1-linux-amd64.tar.gz alcatrão -zxvf leme-v3.2.1-linux-amd64.tar.gz mv linux-amd64/leme /usr/local/caixa/leme |
Siga a Helm's etapas oficiais para instalação em seu sistema operacional específico.
Monitoramento com o Prometheus
As métricas do servidor Couchbase podem ser exportadas para o Prometheus e organizadas em vários painéis no Grafana. O Helm facilita muito os primeiros passos com uma pilha Couchbase-Prometheus, pois é possível agrupar vários componentes em um único gráfico.
O gráfico de monitoramento tem dependências para o Prometheus e o Grafana e, como estamos instalando diretamente de um repositório do github, a primeira etapa é criar o gráfico:
|
1 |
$ leme dependência construir couchbase-prometeu/ |
Agora o gráfico está pronto para ser instalado. O comando a seguir cria um cluster do Couchbase com cada nó exportando métricas para o Prometheus:
|
1 |
$ leme instalar monitor couchbase-prometeu/ |
A instalação retorna algumas informações sobre o gerenciamento do gráfico, juntamente com os comandos a serem executados para visualizar o painel do Grafana. Você deve ver:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
NOME: monitor NAMESPACE: padrão STATUS: implantado ... == Monitoramento # Prometheus kubectl porto-avançar --espaço de nome padrão prometeu-monitor-baile-prometeu-0 9090:9090 # abrir localhost:9090 # Grafana kubectl porto-avançar --espaço de nome padrão implantação/monitor-grafana 3000:3000 # abrir localhost:3000 # login admin:admin |
Execute o comando port-forward para o Grafana para visualizar as métricas do Couchbase:
|
1 |
$ kubectl porto-avançar --espaço de nome padrão implantação/monitor-grafana 3000:3000 |
Agora, abra o site http://localhost:3000 e faça login como admin:admin. Clique no botão Couchbase nas seções de painéis:
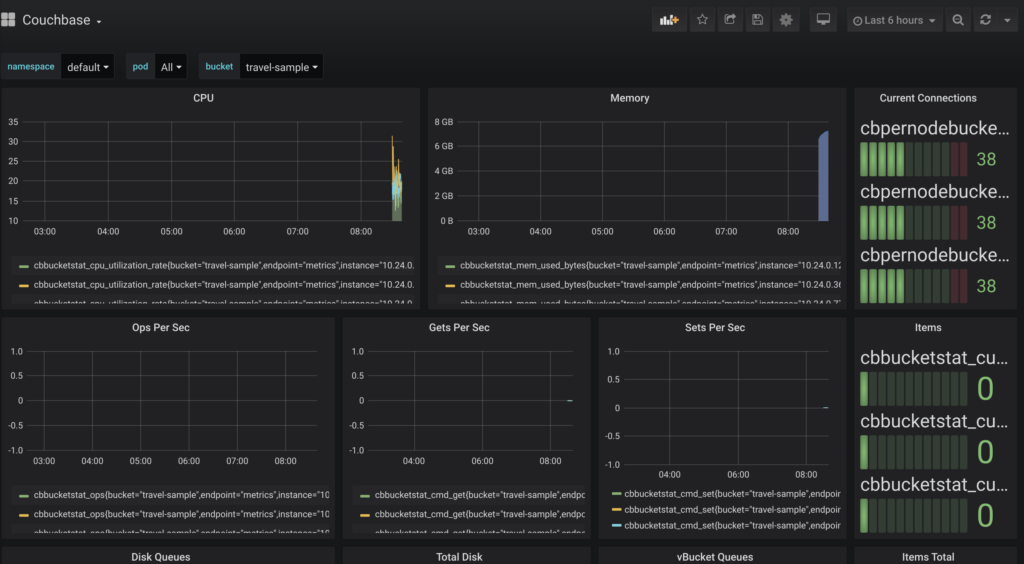
couchbase no grafana
Altere o intervalo de tempo de 6 horas para 5 minutos. Isso ajuda a visualizar as atualizações que ocorrem nos primeiros minutos de monitoramento:
Agora, preencha o cluster com os dados de viagem de amostra:
|
1 |
kubectl criar -f couchbase-prometeu/viagens-amostra.yaml |
Você deverá ver as operações definidas junto com o aumento do número de itens no Dashboard. Consulte a seção Exportador do Couchbase para descobrir estatísticas adicionais que podem ser adicionadas para personalizar ainda mais o painel.
O que vem a seguir
Existem tutoriais e blogs adicionais escritos por Daniel Ma.
Além disso, verifique a documentação do Gráfico do Couchbase Helm para ver outras maneiras pelas quais o Couchbase pode ser personalizado para sua implantação.
Agradecimentos
Agradecemos a Daniel Ma e Matt Ingenthron por contribuírem para esta postagem.
Oi Tommie, obrigado por compartilhar isso
Na sua opinião, quais seriam as principais métricas a serem monitoradas para o dimensionamento automático/manual do cluster do Couchbase, especialmente em um ambiente de nuvem.
Saudações
Obrigado, Purav,
A resposta realmente varia de acordo com os objetivos do seu aplicativo, mas, em geral, é sempre bom verificar a cota de bucket % usada. Quando esse valor se aproxima de 80% ou das marcas de água alta, o cluster começa a ejetar itens para o disco, o que leva a buscas que podem causar latência.
Para cargas de trabalho de consulta, você pode coletar estatísticas e calcular o valor do percentil 99 de consultas de longa duração como uma indicação de problemas de desempenho.