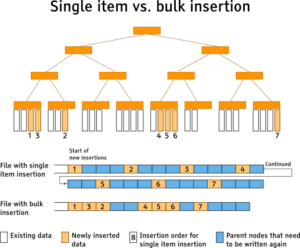
O nova versão de GeoCouch melhora muito o tempo de criação do índice espacial (até 10 vezes). Isso se deve ao uso de um novo algoritmo de inserção em massa. O índice espacial (um Árvore R) é implementado como uma estrutura de dados somente de acréscimo - assim como as árvores B do CouchDB - que se beneficia da natureza das inserções em massa, permitindo que grandes blocos do índice sejam acrescentados de uma só vez.
Implementação antiga
Nas versões anteriores do GeoCouch, cada entrada de geometria era inserida uma a uma. Isso gerava uma enorme quantidade de pequenas operações de disco, pois cada adição era gravada no índice. Aqui está um resumo do algoritmo antigo.
- Iniciar no nó raiz
- Encontre o primeiro filho cuja caixa delimitadora precise de menos expansão
- Percorrer a R-Tree até atingir a folha de destino
- Inserir o novo nó em um nó folha
- Reescreva todos os nós no caminho do nó recém-inserido até o nó raiz
As primeiras etapas são as etapas básicas necessárias para uma inserção em qualquer implementação de árvore R. O problema com esse método é que, ao usar uma estrutura de dados append-only, é necessário um grande número de gravações, pois todos os nós, desde o nó inserido até o nó raiz, precisam ser reescritos e anexados ao índice. Você pode encontrar mais informações sobre a natureza das estruturas de dados append-only em meu artigo Tutorial de criação de um novo indexador
Implementação atual
O índice espacial é implementado de forma semelhante às exibições; o índice é atualizado quando é feita uma solicitação para usá-lo, e não quando um novo documento é inserido. O resultado é que, quando o índice é acessado, ele precisa acompanhar o documento inserido mais recentemente. Assim que mais de um documento é alterado, faz mais sentido processá-lo em massa, reduzir as modificações no disco do índice e melhorar o desempenho geral da atualização.
Carregamento e inserção a granel
Há uma diferença entre carregamento em massa e inserção em massa. Carregamento significa a criação de uma nova estrutura de dados a partir do zero. Já a inserção em massa significa que vários itens novos são inseridos em uma estrutura já existente. A implementação do GeoCouch precisa de ambos e se baseia principalmente em dois documentos. Para a inserção Inserção em massa para árvores R por clustering semeado e para o carregamento em massa OMT: Algoritmo de carregamento em massa top-down com minimização de sobreposição para árvore R foi implementado (com pequenas modificações).
O algoritmo
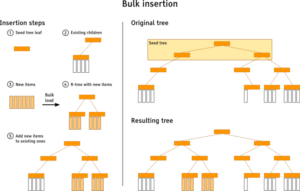
Para aqueles que não querem ler a descrição completa, aqui está um breve resumo do algoritmo de inserção em massa. A ideia básica é criar clusters a partir de toda a atualização em massa que correspondam à estrutura de índice existente no momento (ou seja, o árvore de destino). Em seguida, esses clusters são carregados em massa nas árvores R, sendo inseridos literalmente na árvore de destino.
Vamos dar uma olhada mais de perto em cada etapa. O algoritmo começa com o carregamento dos níveis superiores da árvore de destino na memória (no máximo 3, caso contrário, o consumo de memória está prestes a explodir), esse é o chamado árvore de sementes. As folhas são então usadas para realizar o agrupamento. Cada item da inserção em massa é incorporado à árvore semente com um algoritmo semelhante ao algoritmo normal de inserção da árvore R. A diferença é que os novos itens não são gravados no disco, mas mantidos temporariamente na memória enquanto o restante do processo de inserção em massa continua. A diferença é que os novos itens não são gravados no disco, mas mantidos temporariamente na memória enquanto o restante do processo de inserção em massa continua.
Depois que todos os itens forem processados, a travessia da árvore de sementes será iniciada. Descendo em profundidade em primeiro lugar algum processamento é devido quando um nó folha é alcançado. Todos os itens armazenados temporariamente do nó atual são carregados em massa em uma nova árvore R (o árvore de origem) usando o algoritmo OMT. Essa árvore é anexada aos nós filhos originais da folha da árvore semente. Mas há um problema. Uma árvore R é sempre altamente balanceada, mas a altura da árvore de origem pode não caber se ela for anexada como está. Há basicamente três casos:
- A árvore de origem se encaixa: A árvore pode ser inserida como está
- A árvore de origem é muito pequena: Uma nova árvore de sementes é criada. Seu nó raiz é o nó folha da árvore de origem atual. Proceder de forma recursiva.
- A árvore de origem é muito grande: use os nós filhos em vez do nó raiz da árvore de origem (recursivamente, desça até que a altura corresponda).
O nó raiz da árvore de origem pode cobrir a maior parte da área do nó em que é inserido, portanto, é feito um reempacotamento para melhorar o desempenho da consulta. Os filhos de todos os nós que cruzam o nó da árvore de origem e os filhos da árvore de origem são reorganizados para minimizar a área que cobrem (o algoritmo OMT é utilizado). Após a conclusão desse processo, os nós reempacotados são finalmente gravados no disco.
Os nós pai são gravados no disco sempre que uma subárvore é concluída. O resultado é que o processo de atualização do índice em massa economiza muitas gravações em disco físico em comparação com a estratégia tradicional de inserção de um único item, em que todos os nós pai até a raiz são reescritos em cada inserção.
Desafios da inserção em massa
Embora os algoritmos básicos sejam simples, algumas pessoas podem se perguntar por que parte do código necessário para alcançá-los é tão complexa. O maior desafio é manter a altura da árvore R resultante equilibrada e o número de filhos por nó abaixo do número máximo. Quando você insere em massa, pode haver inserções que resultem em um estouro (e, portanto, em divisões) e isso precisa ser realizado recursivamente até o topo da árvore.
Outro desafio é rastrear na memória a altura atual da árvore de destino, a posição atual dentro da árvore de destino/semente e a altura esperada da árvore de origem que será inserida. Isso precisa ser feito de forma eficiente para evitar o consumo excessivo de memória.
Melhorias futuras
A inserção em massa atual leva a um desempenho e a tamanhos de arquivo muito melhores em comparação com a inserção tradicional de um único item, por meio de uma combinação de reconstrução e balanceamento eficientes da árvore e da redução de gravações físicas no disco. A implementação geralmente precisa pesquisar os nós para obter sua caixa delimitadora, sem a necessidade de solicitar outras coisas (como seus filhos). As alterações na estrutura de dados atual (que são os primeiros fragmentos de código que foram escritos para o GeoCouch) poderiam levar a ainda menos pesquisas.
Olá, gostaria de saber se a API do cliente terá o método setBulk ou se o Couchbase Server executará a operação em massa.
Desde já, obrigado.