 A pesquisa de texto completo refere-se a técnicas de pesquisa de conteúdo de texto em um documento ou em uma coleção de documentos que contêm conteúdo textual. Um mecanismo de pesquisa de texto completo examina todo o conteúdo textual dos documentos ao tentar corresponder a um único termo de pesquisa ou a vários termos, sendo a análise de texto um componente essencial.
A pesquisa de texto completo refere-se a técnicas de pesquisa de conteúdo de texto em um documento ou em uma coleção de documentos que contêm conteúdo textual. Um mecanismo de pesquisa de texto completo examina todo o conteúdo textual dos documentos ao tentar corresponder a um único termo de pesquisa ou a vários termos, sendo a análise de texto um componente essencial.
Você provavelmente já ouviu falar do mais conhecido mecanismo de pesquisa de texto completo: Lucene com Elasticsearch construído sobre ele. O Pesquisa de texto completo (FTS) Motor é alimentado por Blevee este artigo mostrará as várias maneiras de analisar textos dentro desse mecanismo.
O Bleve é uma biblioteca de indexação e pesquisa de texto de código aberto implementada em Go, desenvolvida internamente no Couchbase.
O mecanismo FTS do Couchbase oferece suporte a índices que se inscrevem em dados que residem em um Servidor Couchbase e indexa os dados que ingere do servidor. É um sistema distribuído, o que significa que pode particionar dados em vários nós de um cluster e as pesquisas envolvem a dispersão da solicitação e a coleta de respostas de todos os nós do cluster antes de responder ao aplicativo.
O mecanismo do FTS distribui os documentos ingeridos para um índice em um número configurável de partições, e essas partições podem residir em vários nós de um cluster. Cada partição segue o mesmo conjunto de regras com as quais o índice FTS está configurado, para analisar e indexar o texto no banco de dados de pesquisa de texto completo.
O análise de texto O componente de um mecanismo de pesquisa de texto completo é responsável por dividir o texto bruto em uma lista de palavras, que chamaremos de tokens. Esses tokens são mais adequados para indexação no banco de dados e para pesquisa.
O mecanismo FTS do Couchbase lida com a indexação de texto para documentos JSON. Ele cria um índice para o conteúdo que é analisado e armazena no banco de dados - o índice junto com todos os metadados relevantes necessários para vincular os tokens gerados aos documentos originais nos quais eles residem.
Um Índice invertido é a estrutura de dados escolhida para indexar os tokens gerados a partir do texto, para tornar as consultas de pesquisa mais rápidas. Esse índice vincula todos os tokens gerados aos documentos que contêm o token.
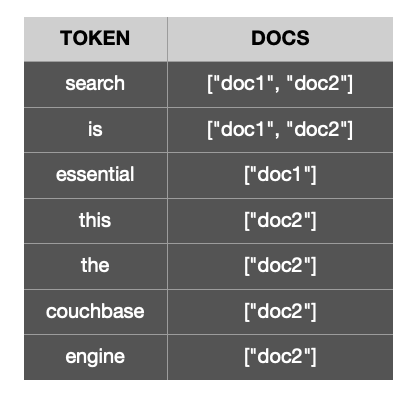
Por exemplo, veja os seguintes documentos...

O índice invertido para os tokens gerados a partir dos 2 documentos acima seria semelhante a este.
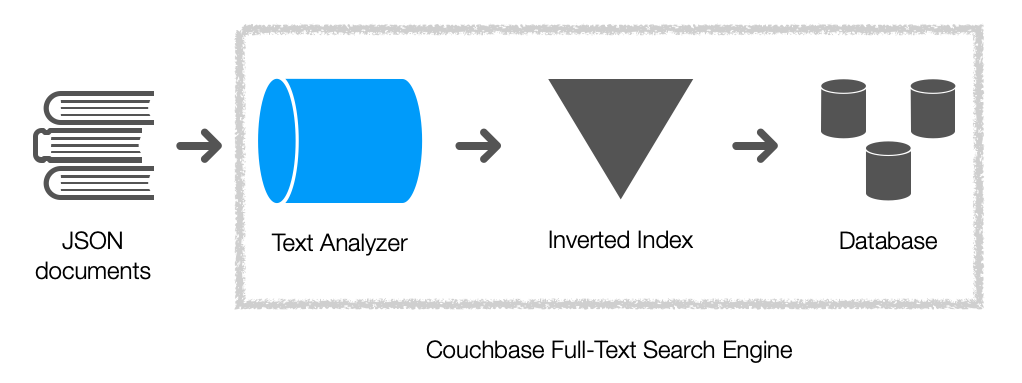
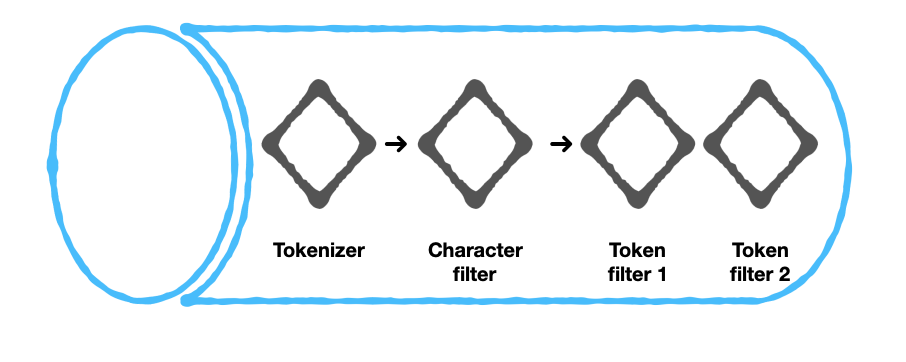
Aqui está um diagrama que destaca os componentes do mecanismo de pesquisa de texto completo.
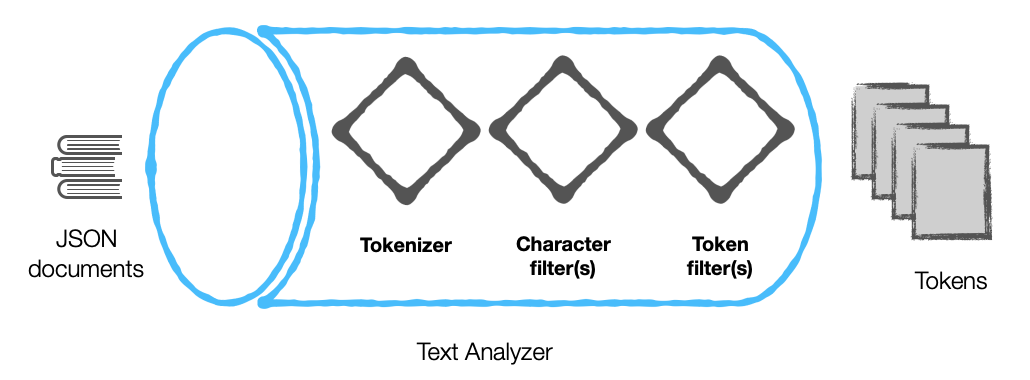
Um analisador de texto
Os componentes de um analisador de texto podem ser classificados em duas categorias:
-
- Tokenizador
- Filtros
O mecanismo do Couchbase categoriza ainda mais os filtros em:
-
- Filtros de caracteres
- Filtros de token
Antes de nos aprofundarmos na função de cada um desses componentes, apresentamos a seguir uma visão geral de um analisador de texto.
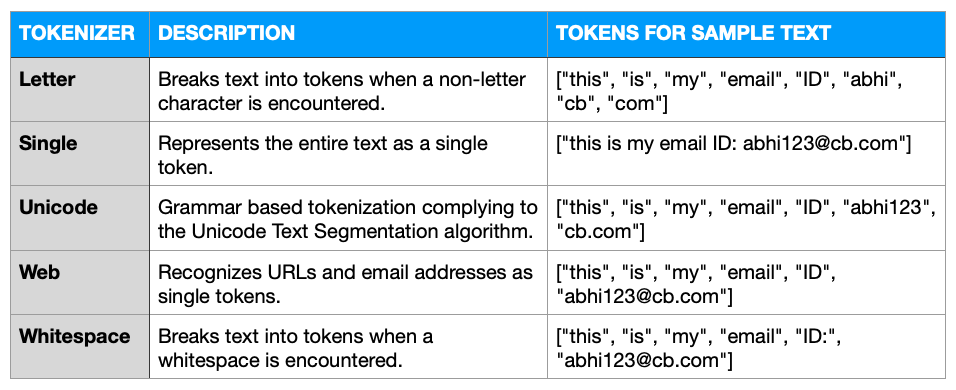
Tokenizador
Um tokenizador é o primeiro componente ao qual os documentos são submetidos. Como o nome sugere, ele divide o texto bruto em uma lista de tokens. Essa conversão dependerá de um conjunto de regras definido para o tokenizador.
Tokenizadores de ações ...
Veja este texto de amostra como exemplo: "Este é meu ID de e-mail: abhi123@cb.com"
Alguns tokenizadores configuráveis ...
-
- Exceção .. Esse tokenizador permite que o usuário insira padrões de exceção (expressões regulares) sobre os tokenizadores de estoque.
- Regexp .. Esse tokenizador extrai o texto que corresponde ao padrão (uma expressão regular) como tokens.
Por exemplo:

Filtro de caracteres
Os filtros de caracteres servem para remover ou substituir caracteres indesejáveis.
Filtros de caracteres de estoque ...

Um filtro de caracteres configurável ...
-
- Regexp .. Aceita uma expressão regular válida e uma cadeia de caracteres de substituição para substituir o padrão correspondente.
Por exemplo:
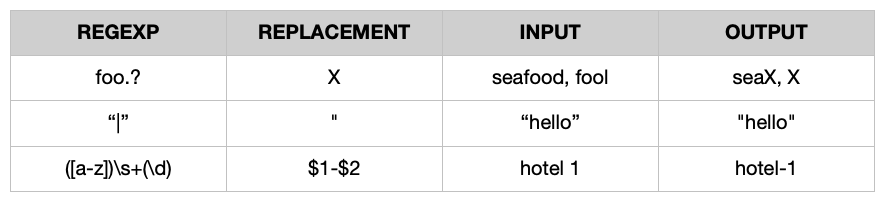
Filtro de token
Os filtros de token aceitam um fluxo de token fornecido por um tokenizador e fazem modificações nos tokens do fluxo. As formas mais comuns de filtragem de tokens são normalização e stemização.
Vários filtros de tokens de ações, aqui estão alguns dos mais importantes.
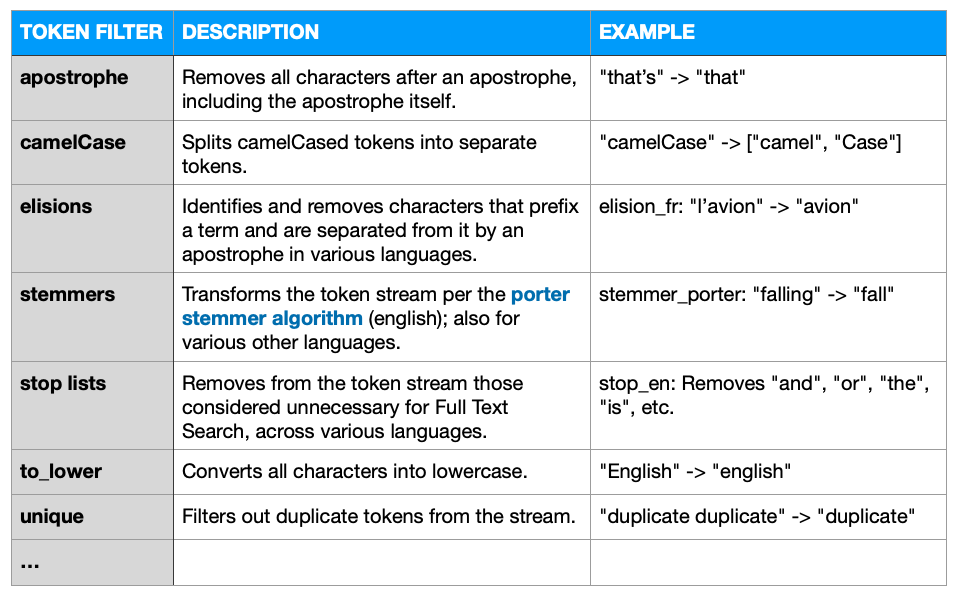
Filtros de token configuráveis ...
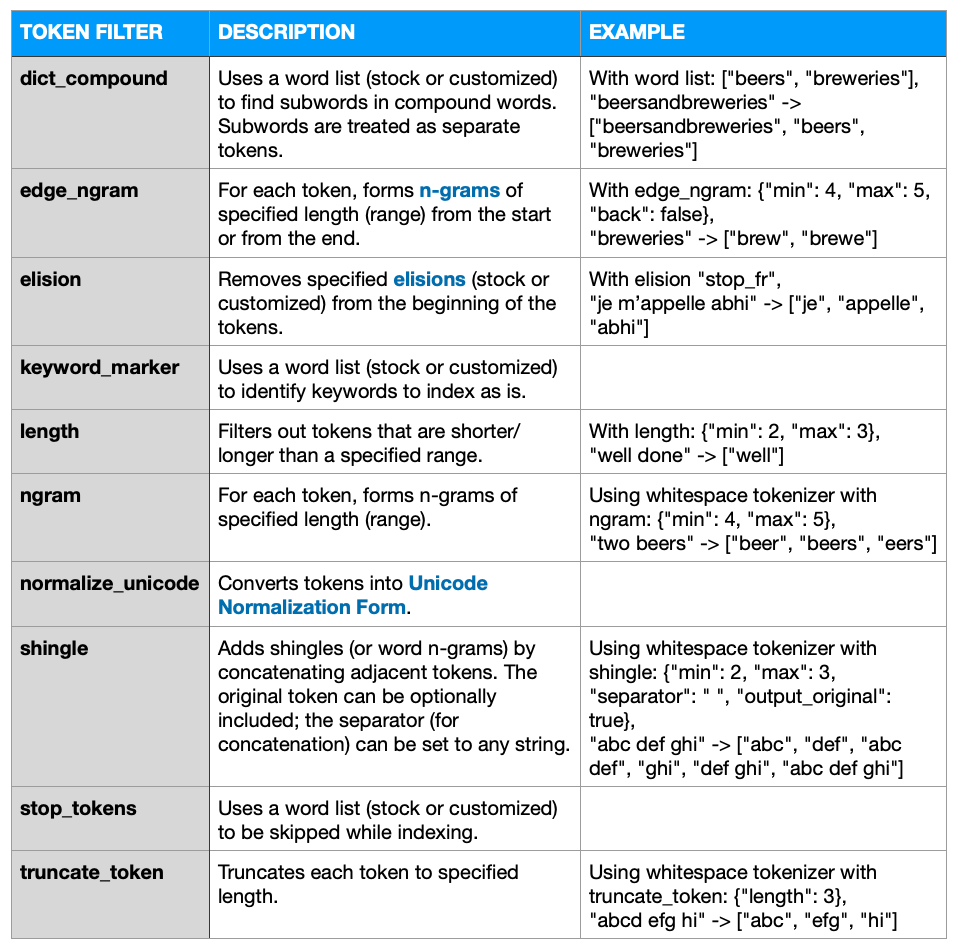
Analisadores de estoque
Com o mecanismo de pesquisa de texto completo do Couchbase, os analisadores e todos os seus componentes trabalham no texto que constitui os valores de campo nos documentos JSON. Eles não trabalham com nomes de campos.
Considere o documento JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "field1": "value1", "field2": "value2", "array_field3": [ "value3", "value4" ], "object_field4": { "field5": "value5", "field6": "value6" } } |
Para o documento, os analisadores podem ser definidos para trabalhar em "value1", "value2", "value3", "value4", "value5" e "value6".
O Couchbase oferece vários analisadores de ações.
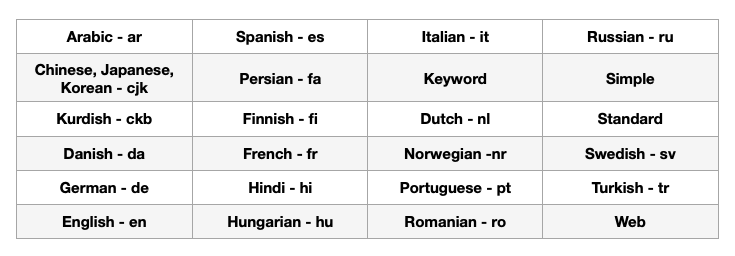
Aqui estão alguns exemplos...
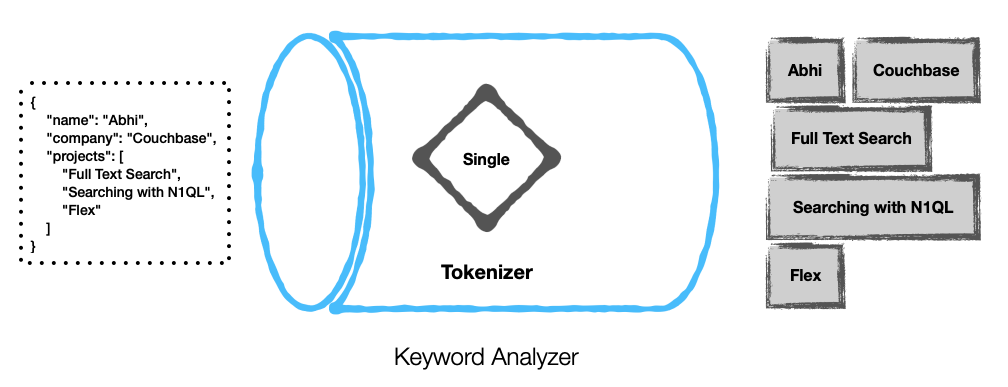
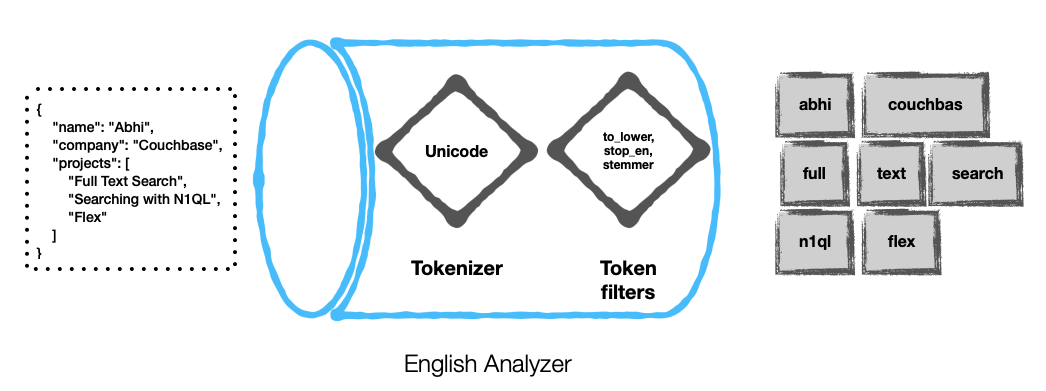
Configuração de um analisador personalizado
- O segredo para projetar um analisador personalizado não é apenas escolher o tokenizador e os filtros corretos, mas também aplicá-los na ordem correta.
- Portanto, a primeira etapa seria configurar quaisquer tokenizadores, filtros de caracteres e filtros de tokens personalizados (juntamente com listas de palavras personalizadas), se necessário.
- Em seguida, crie o analisador escolhendo o tokenizador, os filtros de caracteres e os filtros de tokens desejados. Se você tiver configurado algum filtro personalizado, ele será exibido na lista de opções disponíveis.
- A ORDEM dos filtros de caracteres e de tokens escolhidos pode fazer diferença no resultado obtido.
- Ao escolher um valor de campo para indexar, escolha o analisador desejado para ele. Caso contrário, um analisador será herdado para ele do mapeamento pai. As opções personalizadas serão exibidas na lista de opções disponíveis.
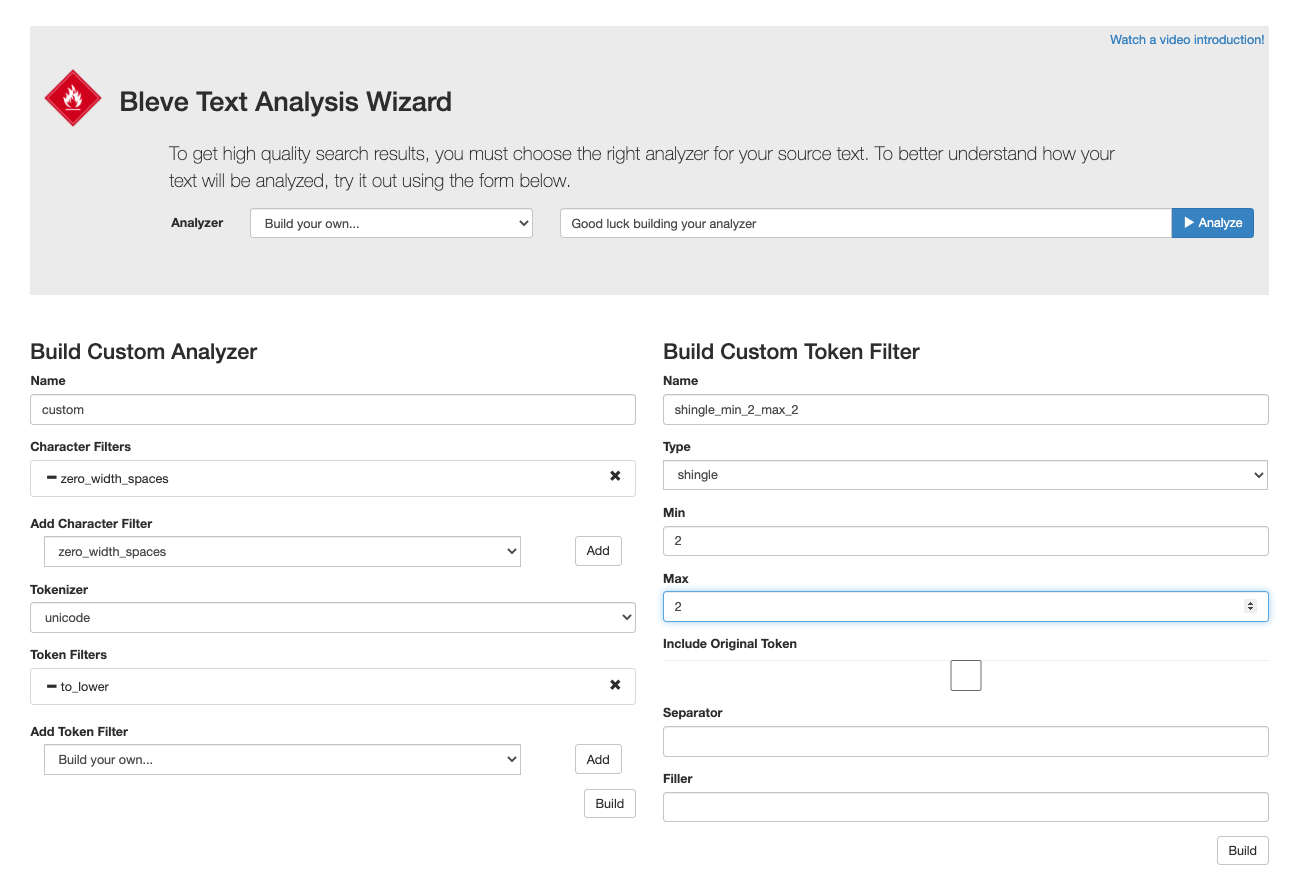
Playground de análise de texto
Teste o comportamento de nossos analisadores de estoque e de seus analisadores personalizados aqui.
https://bleveanalysis.couchbase.com
Aqui está uma boa leitura sobre as práticas recomendadas ao usar o Full Text Search do Couchbase.
Práticas recomendadas de indexação de pesquisa de texto completo por caso de uso