 Full-Text Search refers to techniques for searching text content within a document or a collection of documents that hold textual content. A Full-Text search engine examines all the textual content within documents as it tries to match a single search term or several terms, text analysis being a pivotal component.
Full-Text Search refers to techniques for searching text content within a document or a collection of documents that hold textual content. A Full-Text search engine examines all the textual content within documents as it tries to match a single search term or several terms, text analysis being a pivotal component.
You’ve probably heard of the most well-known Full-Text Search engine: Lucene with Elasticsearch built on top of it. Couchbase’s Full-Text Search (FTS) Engine is powered by Bleve, and this article will showcase the various ways to analyze text within this engine.
Bleve is an open-sourced text indexing and search library implemented in Go, developed in-house at Couchbase.
Couchbase’s FTS engine supports indexes that subscribe to data residing within a Couchbase Server and indexes data that it ingests from the server. It’s a distributed system – meaning it can partition data across multiple nodes in a cluster and searches involve scattering the request and gathering responses from across all nodes within the cluster before responding to the application.
The FTS engine distributes documents ingested for an index across a configurable number of partitions and these partitions could reside across multiple nodes within a cluster. Each partition follows the same set of rules that the FTS index is configured with – to analyze and index text into the full-text search database.
The text analysis component of a Full-Text search engine is responsible for breaking down the raw text into a list of words – which we’ll refer to as tokens. These tokens are more suitable for indexing in the database and searching.
Couchbase’s FTS Engine handles text indexing for JSON documents. It builds an index for the content that is analyzed and stores into the database – the index along with all the relevant metadata needed to link the tokens generated to the original documents within which they reside.
An Inverted index is the data structure chosen to index the tokens generated from text, to make search queries faster. This index links every token generated to documents that contain the token.
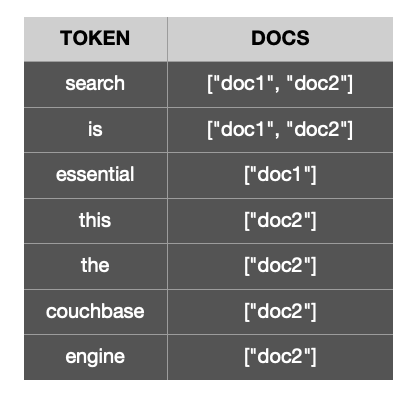
For example, take the following documents ..

The inverted index for the tokens generated from the 2 documents above would resemble this..
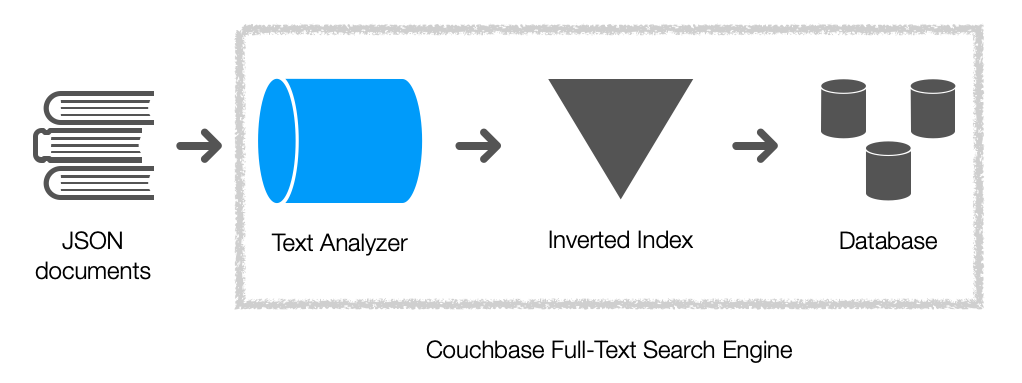
Here’s a diagram highlighting the components of the full-text search engine ..
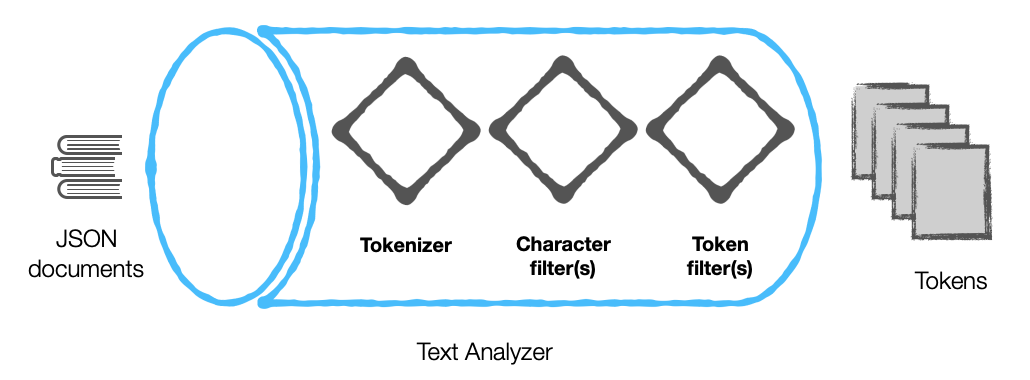
A Text Analyzer
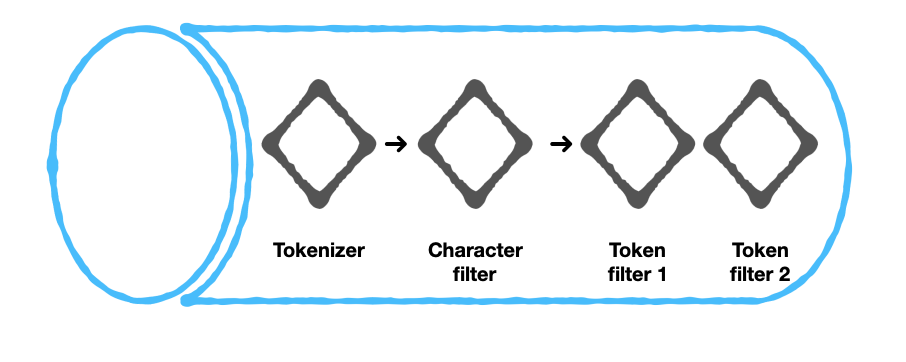
The components of a text analyzer can broadly be classified into 2 categories:
-
- Tokenizer
- Filters
Couchbase’s engine further categorizes filters into:
-
- Character filters
- Token filters
Before we dive into the function of each of these components, here’s an overview of a text analyzer ..
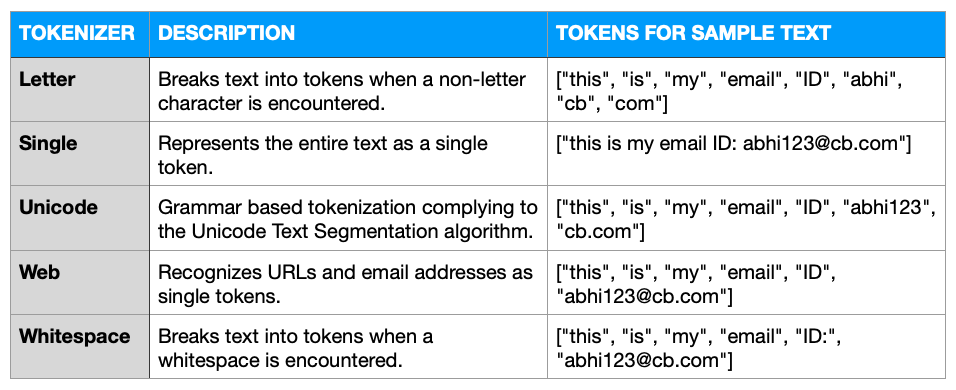
Tokenizer
A tokenizer is the first component to which the documents are subjected to. As the name suggests, it breaks the raw text into a list of tokens. This conversion will depend on a rule-set defined for the tokenizer.
Stock tokenizers ..
Take this sample text for an example: “this is my email ID: abhi123@cb.com”
A couple of configurable tokenizers ..
-
- Exception .. This tokenizer allows the user to enter exception patterns (regular expressions) over the stock tokenizers.
- Regexp .. This tokenizer extracts text that matches the pattern (a regular expression) as tokens.
For example:

Character filter
Character filters are to remove or replace undesirable characters.
Stock character filters ..

A configurable character filter ..
-
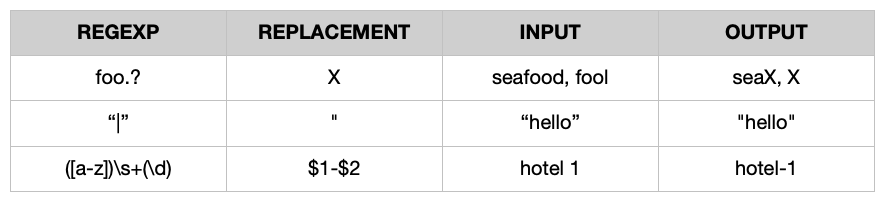
- Regexp .. Accepts a valid regular expression and a replace string to replace the pattern matched.
For example:
Token filter
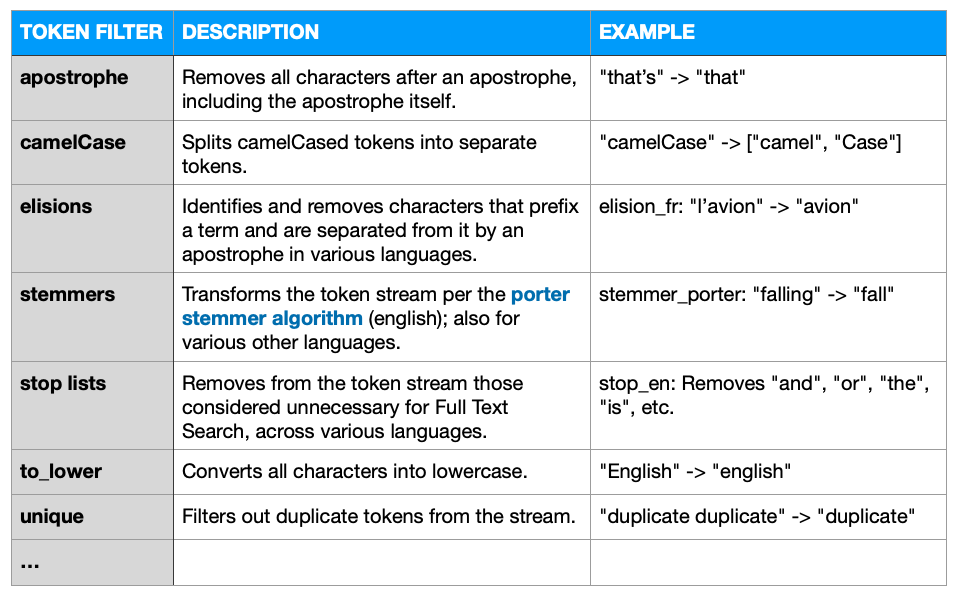
Token filters accept a token stream provided by a tokenizer and make modifications to the tokens in the stream. Most common forms of token filtering are normalizing and stemming.
Several stock token filters, here are a few prominent ones ..
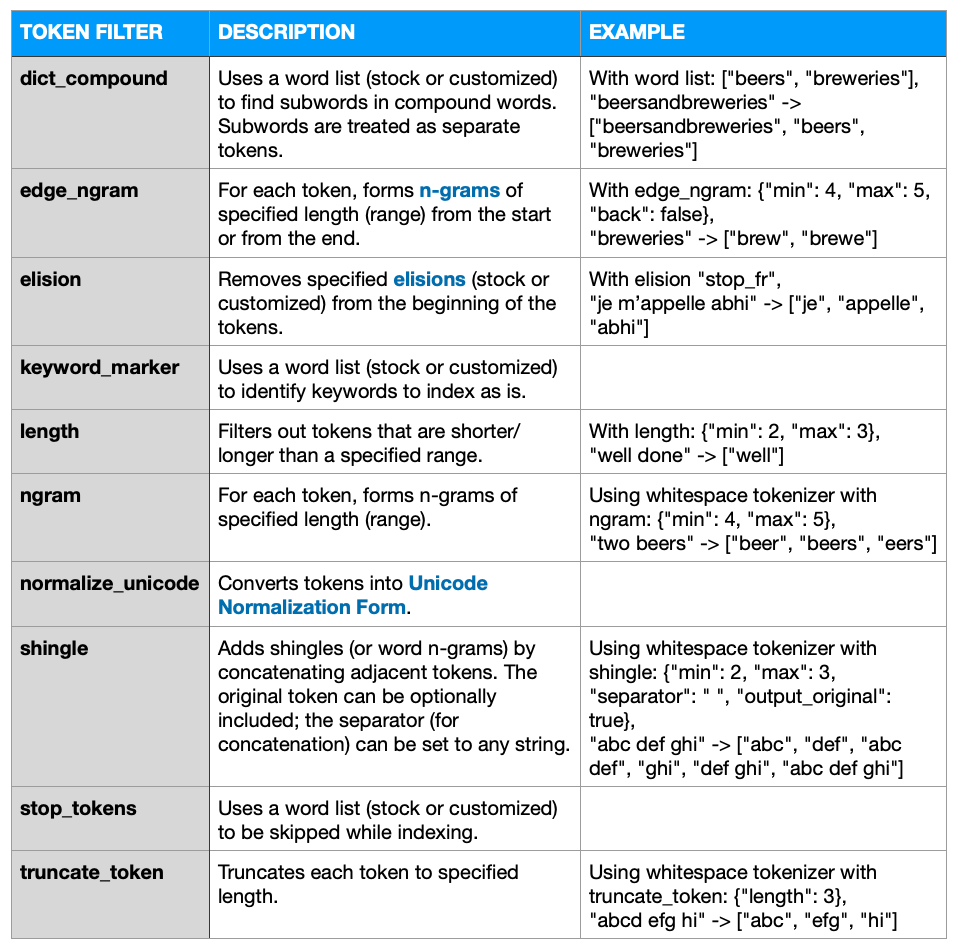
Configurable token filters ..
Stock Analyzers
With Couchbase’s Full-Text Search engine, the analyzers and all their components work on text that constitutes field values within JSON documents. They do not work on field names.
Consider the JSON document:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "field1": "value1", "field2": "value2", "array_field3": [ "value3", "value4" ], "object_field4": { "field5": "value5", "field6": "value6" } } |
For the document, analyzers can be defined to work on “value1”, “value2”, “value3”, “value4”, “value5” and “value6”.
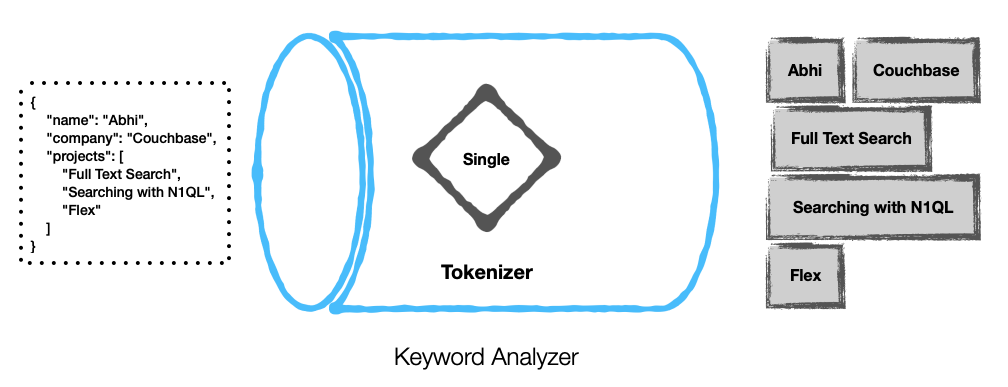
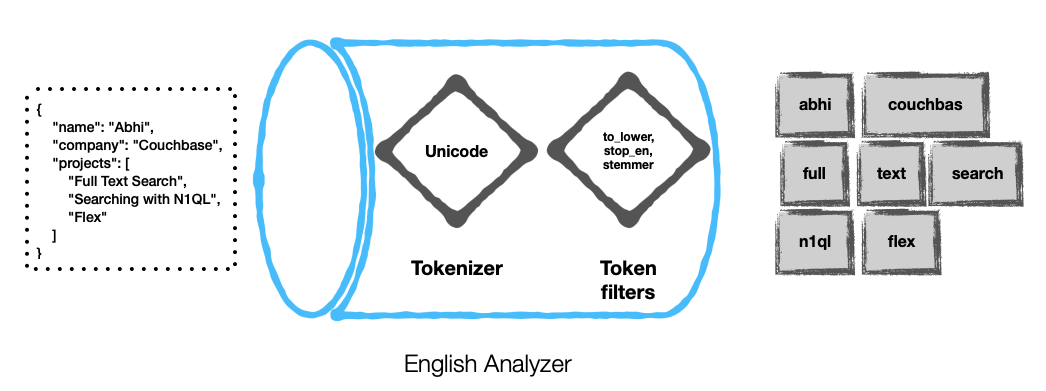
Couchbase offers several stock analyzers ..
Here are a couple of examples ..
Configuring a custom analyzer
- The key to designing a custom analyzer is not just picking the right tokenizer and filters, but also applying them in the correct order.
- So, the first step would be – to set up any customized tokenizers, character filters and token filters (along with custom word lists) if needed.
- Next, create the analyzer by choosing the desired tokenizer, character filters and token filters. If you’ve set up any customized ones, they’ll show in the list of available options.
- The ORDERING of the chosen character filters and token filters can make a difference in the output seen.
- While picking a field value to index, choose the desired analyzer for it. Otherwise, an analyzer will be inherited for it from the parent mapping. Customized options will show in the list of available options.
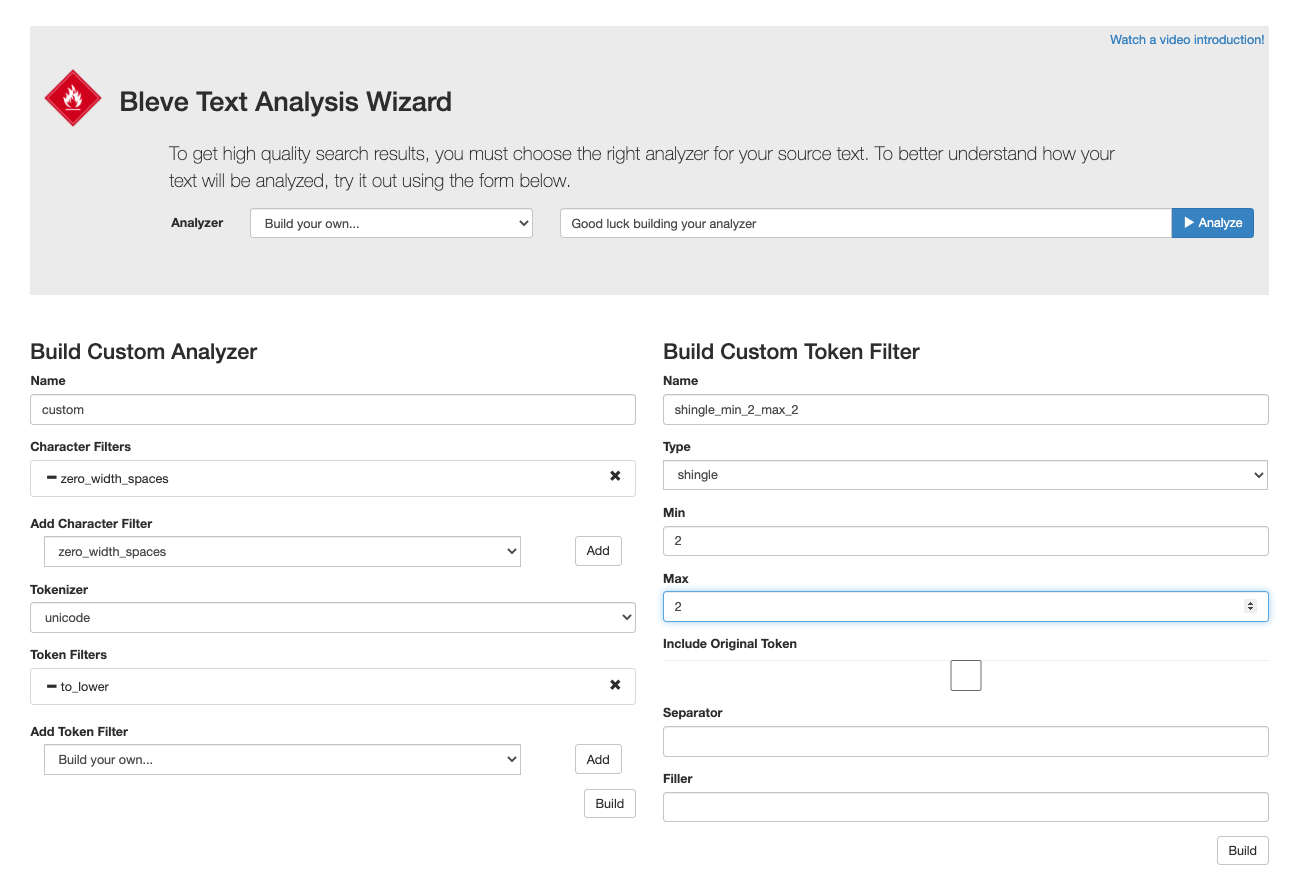
Text analysis playground
Test the behavior of our stock analyzers and your custom built analyzers here ..
https://bleveanalysis.couchbase.com
Here’s a good read on best practices while using Couchbase’s Full Text Search ..