Introdução
O Couchbase Full Text Search (FTS) é uma ótima opção para indexar várias matrizes e executar consultas com vários predicados de filtro em matrizes. Neste artigo, demonstrarei as vantagens de usar o FTS em vez do GSI (Índice Secundário Global) para indexação de matrizes, enquanto trabalho em um caso de uso de exemplo que exige a consulta de várias matrizes. Criaremos um índice FTS de várias matrizes e consultaremos o índice com N1QL usando a nova função SEARCH() introduzida no Couchbase Server 6.5.
Balde de amostras de viagem
Neste artigo, faremos referência ao Conjunto de dados de amostra de viagens disponível para instalação em qualquer instância do Couchbase Server. O bucket de amostra de viagem tem vários tipos de documentos distintos: companhia aérea, rota, aeroporto, ponto de referência e hotel. O modelo de documento para cada tipo de documento contém:
- Uma chave que atua como uma chave primária
- Um campo de id que identifica o documento
- Um campo de tipo que identifica o tipo de documento
Os exemplos deste artigo usarão os documentos de hotel. O exemplo de documento abaixo lhe dá uma ideia da estrutura de um documento de hotel:

Figura 1 - Exemplo de documento de hotel
O problema
Nosso exemplo é um caso de uso em que um usuário pode pesquisar hotéis que tenham sido avaliados ou curtidos por uma pessoa com um nome específico. Para isso, é necessário consultar os documentos do hotel em curtidas e avaliações públicas, que são matrizes no modelo de documento do hotel:

Figura 2 - As matrizes "public_likes" e "reviews" no documento de exemplo de hotel
Primeiro, vamos dar uma olhada na implementação desse caso de uso com N1QL e GSI (Global Secondary Index). Para encontrar hotéis que alguém chamado Ozella tenha gostado ou avaliado, a consulta poderia ser assim:
|
1 2 3 4 5 6 |
SELECT name, address, city, country, phone, public_likes, reviews FROM `travel-sample` WHERE type="hotel" AND (ANY l IN public_likes SATISFIES l LIKE "%Ozella%" END OR ANY r IN reviews SATISFIES r.author LIKE "%Ozella%" END); |
Precisamos criar um índice apropriado para essa consulta. Talvez algo como isto, que indexa ambas as matrizes de interesse para documentos de hotéis:
|
1 2 3 4 |
CREATE INDEX idx_hotel_public_likes_review_author ON `travel-sample` (DISTINCT ARRAY `l` FOR l IN `public_likes` END, DISTINCT ARRAY `r`.`author` FOR r IN `reviews` END) WHERE `type` = 'hotel'; |
Isso não funciona, e obtemos o erro mostrado na Figura 3:
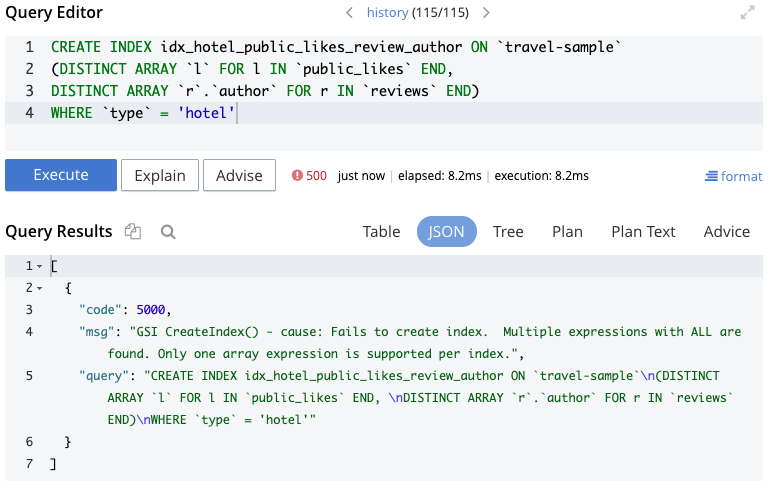 Figura 3 - Erro ao criar índice com várias matrizes
Figura 3 - Erro ao criar índice com várias matrizes
Como Keshav Murthy escreveu em sua postagem no blog Busca e resgate: 7 razões para os desenvolvedores de N1QL (SQL) usarem o Search (problema #6), com N1QL no Couchbase, "Para obter o melhor desempenho ao pesquisar dentro de matrizes, você precisa criar índices com chaves de matriz. O índice de matriz vem com uma limitação: cada índice de matriz só pode ter uma chave de matriz por índice. Portanto, quando você tem um objeto de cliente com vários campos de matriz, não é possível pesquisar todos eles usando um único índice... o que causa consultas caras." Como Keshav observa nesse artigo, essa é uma limitação dos índices b-tree nos bancos de dados em geral.
Então, agora vamos tentar dois índices de matriz separados. Os índices para dar suporte a essa consulta podem se parecer com estes, que foram criados usando o comando Consultor de índice N1QL do Couchbaseum novo recurso (DP) no Couchbase 6.5:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX adv_DISTINCT_public_likes_type ON `travel-sample`(DISTINCT ARRAY `l` FOR l in `public_likes` END) WHERE `type` = 'hotel'; CREATE INDEX adv_DISTINCT_reviews_author_type ON `travel-sample`(DISTINCT ARRAY `r`.`author` FOR r in `reviews` END) WHERE `type` = 'hotel'; |
Com esses dois índices implementados, nossa consulta é executada com sucesso com 5 resultados (hotel_26020, hotel_10025, hotel_5081, hotel_20425, hotel_25327) e o seguinte plano de execução:

Figura 4 - Plano de execução usando vários índices (GSI)
O mesmo plano em JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 |
{ "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "1.321µs" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "3.034µs", "servTime": "1.037859ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "2.235µs" }, "~children": [ { "#operator": "UnionScan", "#stats": { "#itemsIn": 1646, "#itemsOut": 904, "#phaseSwitches": 5107, "execTime": "1.32474ms", "kernTime": "113.495553ms" }, "scans": [ { "#operator": "DistinctScan", "#stats": { "#itemsIn": 4004, "#itemsOut": 813, "#phaseSwitches": 9641, "execTime": "1.381997ms", "kernTime": "69.065425ms" }, "scan": { "#operator": "IndexScan3", "#stats": { "#itemsOut": 4004, "#phaseSwitches": 16021, "execTime": "19.678094ms", "kernTime": "30.973177ms", "servTime": "17.461885ms" }, "index": "adv_DISTINCT_public_likes_type", "index_id": "288083a758973630", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "range": [ { "high": "[]", "inclusion": 1, "low": "\"\"" } ] } ], "using": "gsi", "#time_normal": "00:00.037", "#time_absolute": 0.037139979000000004 }, "#time_normal": "00:00.001", "#time_absolute": 0.0013819969999999998 }, { "#operator": "DistinctScan", "#stats": { "#itemsIn": 4104, "#itemsOut": 833, "#phaseSwitches": 9881, "execTime": "2.475034ms", "kernTime": "80.914158ms" }, "scan": { "#operator": "IndexScan3", "#stats": { "#itemsOut": 4104, "#phaseSwitches": 16421, "execTime": "8.610445ms", "kernTime": "52.02497ms", "servTime": "22.586149ms" }, "index": "adv_DISTINCT_reviews_author_type", "index_id": "cca7f912cab1a4c6", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "range": [ { "high": "[]", "inclusion": 1, "low": "\"\"" } ] } ], "using": "gsi", "#time_normal": "00:00.031", "#time_absolute": 0.031196594 }, "#time_normal": "00:00.002", "#time_absolute": 0.002475034 } ], "#time_normal": "00:00.001", "#time_absolute": 0.00132474 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 904, "#itemsOut": 904, "#phaseSwitches": 3733, "execTime": "2.887995ms", "kernTime": "8.826606ms", "servTime": "170.010321ms" }, "keyspace": "travel-sample", "namespace": "default", "#time_normal": "00:00.172", "#time_absolute": 0.172898316 }, { "#operator": "Parallel", "#stats": { "#phaseSwitches": 1, "execTime": "6.134µs" }, "copies": 2, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "3.621µs" }, "~children": [ { "#operator": "Filter", "#stats": { "#itemsIn": 904, "#itemsOut": 5, "#phaseSwitches": 1824, "execTime": "279.461548ms", "kernTime": "85.245883ms" }, "condition": "(((`travel-sample`.`type`) = \"hotel\") and (any `l` in (`travel-sample`.`public_likes`) satisfies (`l` like \"%Ozella%\") end or any `r` in (`travel-sample`.`reviews`) satisfies ((`r`.`author`) like \"%Ozella%\") end))", "#time_normal": "00:00.279", "#time_absolute": 0.279461548 }, { "#operator": "InitialProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "7.156613ms", "kernTime": "357.453351ms" }, "result_terms": [ { "expr": "(`travel-sample`.`name`)" }, { "expr": "(`travel-sample`.`address`)" }, { "expr": "(`travel-sample`.`city`)" }, { "expr": "(`travel-sample`.`country`)" }, { "expr": "(`travel-sample`.`phone`)" }, { "expr": "(`travel-sample`.`public_likes`)" }, { "expr": "(`travel-sample`.`reviews`)" } ], "#time_normal": "00:00.007", "#time_absolute": 0.007156613 }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "12.167µs", "kernTime": "98.849µs" }, "#time_normal": "00:00.000", "#time_absolute": 0.000012167 } ], "#time_normal": "00:00.000", "#time_absolute": 0.000003621 }, "#time_normal": "00:00.000", "#time_absolute": 0.000006134 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0000022349999999999998 }, "#time_normal": "00:00.001", "#time_absolute": 0.0010408930000000002 }, { "#operator": "Stream", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "939.145µs", "kernTime": "182.523171ms" }, "#time_normal": "00:00.000", "#time_absolute": 0.000939145 } ], "~versions": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#time_normal": "00:00.000", "#time_absolute": 0.000001321 } |
No cluster de nó único que está sendo usado para esses exemplos, o tempo decorrido da consulta é de cerca de 190-200 milissegundos para retornar os 5 documentos resultantes. Como você pode ver no plano, há dois operadores IndexScan3 que usam cada um dos dois índices de matriz que criamos, seguidos por um DistinctScan para os resultados de cada varredura de índice e, em seguida, um UnionScan. O UnionScan mostra um valor #itemsIn de 1646 documentos e um valor #itemsOut de 904 documentos, o operador Fetch também obtém 904 documentos e, finalmente, com o operador Filter, obtemos um valor #ItemsOut de 5. A busca de 904 documentos é um desperdício, considerando que acabamos com 5 documentos retornados pela consulta e, de fato, cerca de 170 milissegundos do tempo total decorrido são gastos na busca de 905 documentos quando apenas 5 são necessários.
A solução
Por outro lado, um índice invertido FTS pode ser facilmente criado para várias matrizes e é adequado para casos em que você precisa pesquisar campos em várias matrizes. Criaremos um índice FTS nos documentos do hotel para a matriz public_likes e o campo author na matriz reviews.
Etapas de criação do índice:
- Na interface de usuário da Pesquisa de texto completo, clique em "Add Index" (Adicionar índice).
- Especifique um nome de índice, por exemplo, "hotel_mult_arrays", e selecione o bucket de amostra de viagem.
- Como cada documento no bucket de amostra de viagem tem um campo "type" que indica o tipo de documento, deixe "JSON type field" definido como "type".
- Em mapeamentos de tipos:
- Clique em "+ Add Type Mapping" e especifique "hotel" como o nome do tipo, pois o requisito é pesquisar todos os documentos de hotéis.
- Uma lista de analisadores disponíveis pode ser acessada por meio do menu suspenso à direita do campo de nome do tipo. Para esse caso de uso, deixe a opção "inherit" selecionada para que o mapeamento de tipos herde o analisador padrão do índice.
- Como o requisito é pesquisar os gostos públicos do hotel e revisar os campos do autor, marque "indexar somente campos especificados". Com essa opção marcada, somente os campos especificados pelo usuário do documento serão incluídos no índice para o mapeamento do tipo de hotel (o mapeamento não será dinâmico, o que significa que todos os campos serão considerados disponíveis para indexação).
- Clique em OK.
- Passe o mouse sobre a linha com o mapeamento do tipo de hotel, clique no botão + e, em seguida, clique em "inserir campo filho". Isso permitirá que a matriz public_likes seja incluída individualmente no índice. Especifique o seguinte:
- campo: Digite o nome do campo a ser indexado, "public_likes".
- type (tipo): Deixe essa opção definida como text para a matriz public_likes.
- pesquisável como: Deixe-o igual ao nome do campo para o caso de uso atual. Pode ser usado para indicar um nome de campo alternativo.
- analisador: Como foi feito para o mapeamento de tipos, para esse caso de uso, deixe a opção "herdar" selecionada para que que o mapeamento de tipos herda o analisador padrão.
- caixa de seleção do índice: Deixe essa opção marcada para que o campo seja incluído no índice. Desmarcar a caixa removeria explicitamente o campo do índice.
- caixa de seleção da loja: Marque essa configuração para incluir o conteúdo do campo nos resultados da pesquisa, o que permite destacar as expressões correspondentes nos resultados. Isso é útil para testar o índice, mas não é recomendado no Prod se o destaque não for necessário, pois aumenta o tamanho do índice.
- Caixa de seleção "incluir no campo _all": Deixe-a marcada, pois o requisito do caso de uso é pesquisar vários campos.
- Caixa de seleção "incluir vetores de termos": Deixe-a marcada também durante o desenvolvimento e teste do nosso índice para permitir o destaque dos resultados.
- caixa de seleção docvalues: Desmarque essa configuração. Essa configuração armazena os valores de campo no índice, o que oferece suporte para as Facetas de pesquisa e para a classificação dos resultados de pesquisa com base nos valores de campo, nenhum dos quais precisamos neste caso de uso.
- Clique em OK.
- Passe o mouse sobre a linha com o mapeamento do tipo de hotel, clique no botão + e, em seguida, clique em "inserir mapeamento de filhos". Isso permitirá que a matriz de subdocumentos de revisão seja incluída no índice. Digite o nome da propriedade "reviews", deixe a opção "inherit" selecionada no menu suspenso do analisador, marque a opção "only index specified fields" e clique em OK.
- Passe o mouse sobre a linha com o mapeamento filho das revisões, clique no botão + e, em seguida, clique em "inserir campo filho". Isso permitirá que o campo de autor da matriz de subdocumentos de revisão seja incluído no índice. Especifique o seguinte:
- campo: Digite o nome do campo a ser indexado, "author" (autor).
- type (tipo): Deixe essa opção definida como texto para o campo de autor.
- pesquisável como: Deixe-o igual ao nome do campo para o caso de uso atual. Pode ser usado para indicar um nome de campo alternativo.
- analisador: Como foi feito para o mapeamento de tipos, para esse caso de uso, deixe a opção "herdar" selecionada para que que o mapeamento de tipos herda o analisador padrão.
- caixa de seleção do índice: Deixe essa opção marcada para que o campo seja incluído no índice. Desmarcar a caixa removeria explicitamente o campo do índice.
- caixa de seleção da loja: Marque essa configuração para incluir o conteúdo do campo nos resultados da pesquisa, o que permite destacar as expressões correspondentes nos resultados. Isso é útil para testar o índice, mas não é recomendado no Prod se o destaque não for necessário, pois aumenta o tamanho do índice.
- Caixa de seleção "incluir no campo _all": Deixe-a marcada, pois o requisito do caso de uso é pesquisar vários campos.
- Caixa de seleção "incluir vetores de termos": Deixe-a marcada também durante o desenvolvimento e teste do nosso índice para permitir o destaque dos resultados.
- caixa de seleção docvalues: Desmarque essa configuração. Essa configuração armazena os valores de campo no índice, o que oferece suporte para as Facetas de pesquisa e para a classificação dos resultados de pesquisa com base nos valores de campo, nenhum dos quais precisamos neste caso de uso.
- Clique em OK.
- Por fim, desmarque a caixa de seleção ao lado do mapeamento de tipo "padrão". Se o mapeamento padrão for deixado ativado, todos os documentos no intervalo serão incluídos no índice, independentemente de o usuário especificar ativamente os mapeamentos de tipo. Somente os documentos do hotel são necessários, e eles são incluídos pelo mapeamento de tipo de hotel adicionado anteriormente.
- Os valores padrão são suficientes para os painéis recolhidos restantes (Analyzers, Custom Filters, Date/Time Parsers e Advanced).
- As réplicas de índice podem ser definidas como 1, 2 ou 3, desde que o cluster esteja executando o serviço Search em n+1 nós. Com um ambiente de desenvolvimento de nó único, mantenha o valor padrão de 0.
- Para Tipo de índice, o valor padrão de "Versão 6.0 (Scorch)" é apropriado para todos os índices recém-criados. O Scorch reduz o tamanho do índice no disco e oferece desempenho aprimorado do MongoDB no operador para indexação e tratamento de mutação.
- As partições de índice podem ser deixadas com o valor padrão de 6.
- Nesse ponto, a página de índice de criação deve ter a seguinte aparência o último quadro capturado em Figura 5. Clique em "Create Index" para concluir o processo.
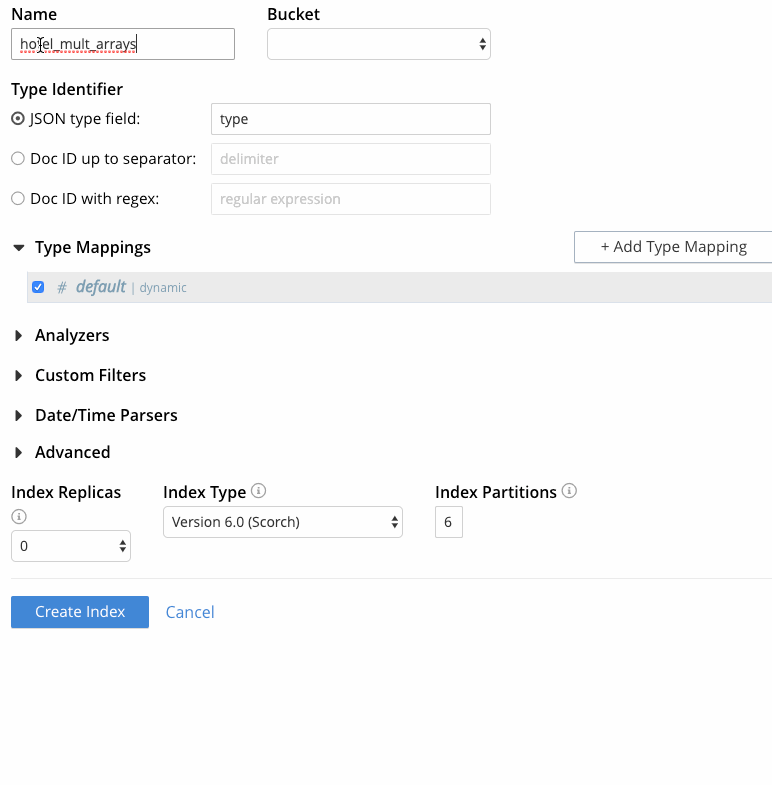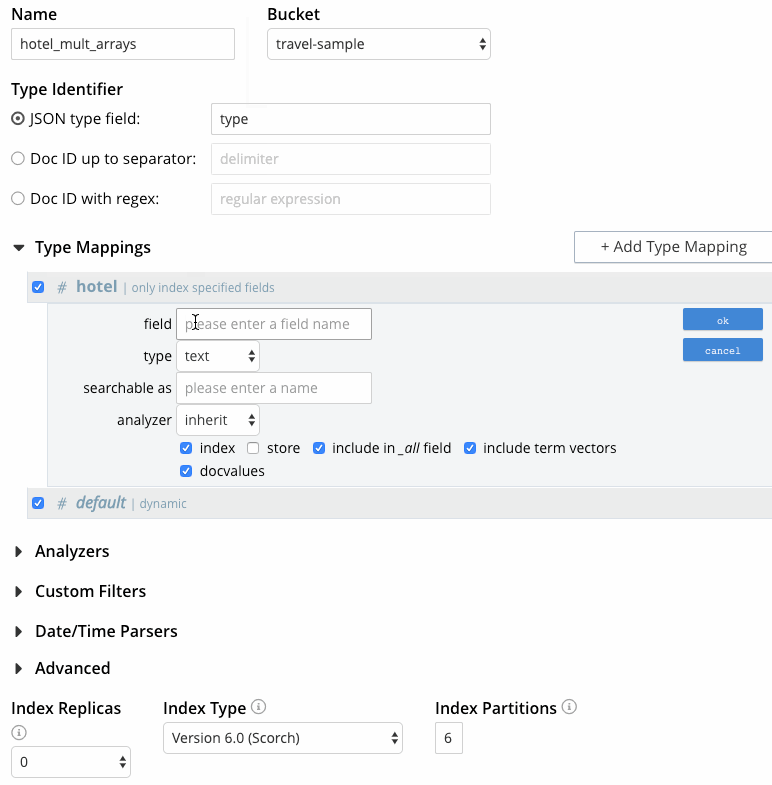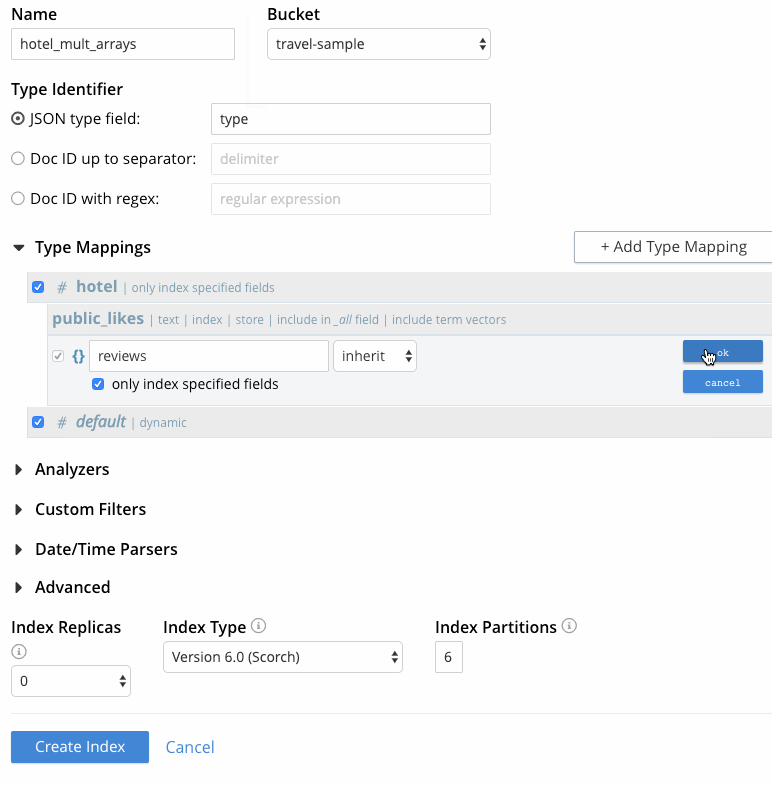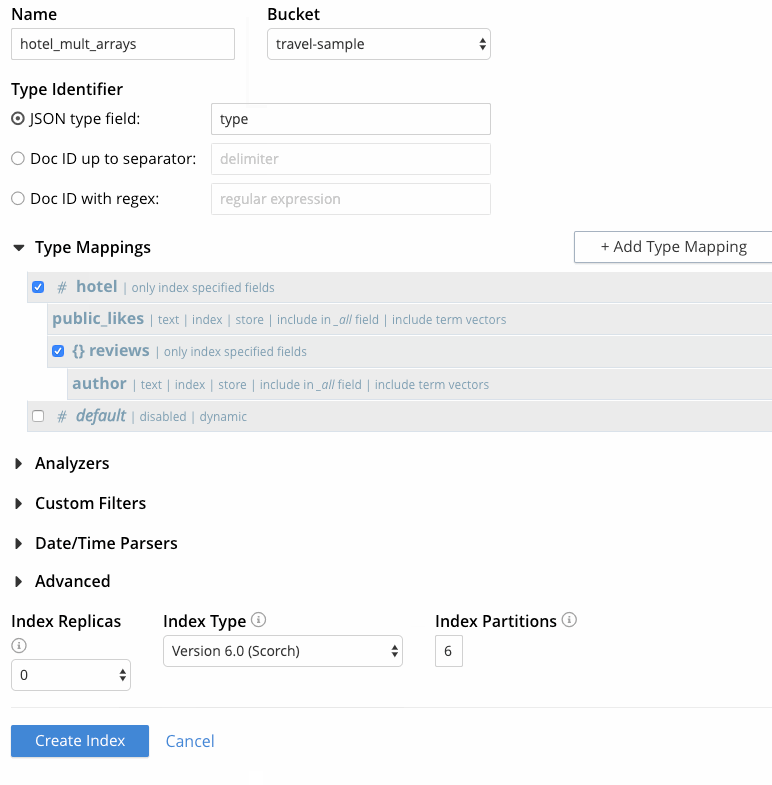
Figura 5 - Criação de índice FTS com várias matrizes
Observação: consulte o Apêndice para ver a carga útil JSON usada para criar esse índice por meio da API REST.
Teste de consultas no índice:
- Na UI de pesquisa de texto completo, aguarde até que o progresso da indexação mostre 100% e, em seguida, clique no nome do índice "hotel_mult_arrays".
- Para pesquisar todos os hotéis com curtidas ou avaliações de alguém chamado "Ozella", na caixa de texto "pesquisar este índice...", digite "Ozella" e clique em Pesquisar. O escopo de campo da pesquisa não é necessário porque ambos os campos indexados estão incluídos no campo padrão "_all".
- Os resultados são mostrados (semelhante à Figura 6) com a chave de cada documento correspondente e os campos correspondentes destacados. Os IDs de documentos retornados são os mesmos da nossa consulta N1QL anterior.
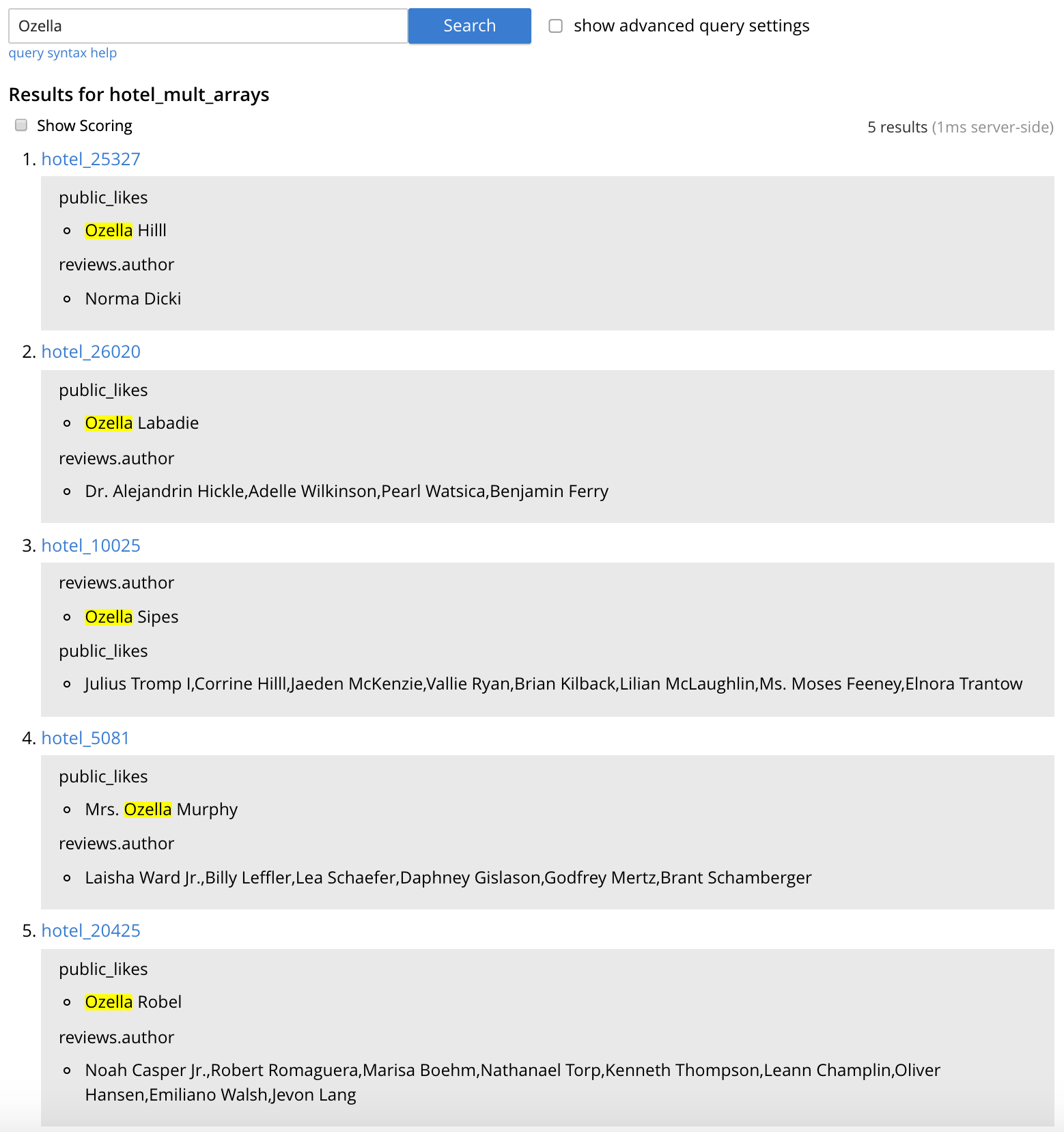
Figura 6 - Resultados da pesquisa do índice "hotel_mult_arrays" para "Ozella"
Esse é um índice único em 2 chaves de matriz, o que, conforme mencionado anteriormente, é algo que nunca poderia ser feito em um índice baseado em b-tree. Então, agora vamos aproveitar esse índice FTS em uma consulta N1QL usando a função SEARCH(). Nossa consulta poderia ter a seguinte aparência:
|
1 2 3 4 5 |
SELECT name, address, city, country, phone, public_likes, reviews FROM `travel-sample` AS t USE INDEX(hotel_mult_arrays USING FTS) WHERE t.type="hotel" AND SEARCH(t, {"query": {"match":"Ozella"}}, {"index":"hotel_mult_arrays"}); |
Alguns aspectos a serem observados sobre a consulta:
- A cláusula USE INDEX...USING FTS especifica que o índice FTS deve ser usado em vez de um índice GSI, portanto, essa consulta não usa o serviço de índice. (Documentação)
- Como nosso índice FTS usa um mapeamento de tipo personalizado, a consulta precisa ter o tipo correspondente especificado na cláusula WHERE (t.type="hotel").
- O nome do índice FTS é especificado no campo "index" na função SEARCH() como uma dica, mas isso é opcional, pois a cláusula USE INDEX tem precedência sobre uma dica fornecida no campo "index". (Documentação)
Usando o índice FTS que criamos, nossa consulta N1QL é executada com êxito e retorna 5 resultados (hotel_5081, hotel_26020, hotel_10025, hotel_20425, hotel_25327) e o seguinte plano de execução:

Figura 7 - Plano de execução usando vários índices (FTS)
O mesmo plano em JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
{ "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "18.8µs" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "32.1µs", "servTime": "3.421ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "122.8µs" }, "~children": [ { "#operator": "IndexFtsSearch", "#stats": { "#itemsOut": 5, "#phaseSwitches": 23, "execTime": "239.3µs", "kernTime": "84.5µs", "servTime": "3.9146ms" }, "as": "t", "index": "hotel_mult_arrays", "index_id": "7a28a8346fad6118", "keyspace": "travel-sample", "namespace": "default", "search_info": { "field": "\"\"", "options": "{\"index\": \"hotel_mult_arrays\"}", "outname": "out", "query": "{\"query\": {\"match\": \"Ozella\"}}" }, "using": "fts", "#time_normal": "00:00.004", "#time_absolute": 0.0041539 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "334.8µs", "kernTime": "4.4328ms", "servTime": "1.5272ms" }, "as": "t", "keyspace": "travel-sample", "namespace": "default", "#time_normal": "00:00.001", "#time_absolute": 0.001862 }, { "#operator": "Parallel", "#stats": { "#phaseSwitches": 1, "execTime": "21.1µs" }, "copies": 2, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "49.1µs" }, "~children": [ { "#operator": "Filter", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 26, "execTime": "6.8953ms", "kernTime": "14.8149ms" }, "condition": "(((`t`.`type`) = \"hotel\") and search(`t`, {\"query\": {\"match\": \"Ozella\"}}, {\"index\": \"hotel_mult_arrays\"}))", "#time_normal": "00:00.006", "#time_absolute": 0.0068953 }, { "#operator": "InitialProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "2.3597ms", "kernTime": "20.7458ms" }, "result_terms": [ { "expr": "(`t`.`name`)" }, { "expr": "(`t`.`address`)" }, { "expr": "(`t`.`city`)" }, { "expr": "(`t`.`country`)" }, { "expr": "(`t`.`phone`)" }, { "expr": "(`t`.`public_likes`)" }, { "expr": "(`t`.`reviews`)" } ], "#time_normal": "00:00.002", "#time_absolute": 0.0023597 }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "300µs", "kernTime": "375.9µs" }, "#time_normal": "00:00", "#time_absolute": 0 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0000491 }, "#time_normal": "00:00.000", "#time_absolute": 0.0000211 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0001228 }, "#time_normal": "00:00.003", "#time_absolute": 0.0034531 }, { "#operator": "Stream", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "1.3409ms", "kernTime": "14.8586ms" }, "#time_normal": "00:00.001", "#time_absolute": 0.0013409 } ], "~versions": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#time_normal": "00:00.000", "#time_absolute": 0.0000188 } |
No cluster de nó único que está sendo usado para esses exemplos, o tempo decorrido da consulta é de cerca de 20 milissegundos para retornar os mesmos 5 documentos. Como você pode ver no plano, há um operador IndexFtsSearch, mas não há operadores IndexScan3, DistinctScan, UnionScan ou IntersectScan. A consulta geral é muito mais eficiente sem esses caros operadores GSI. O operador IndexFtsSearch envia os 5 documentos correspondentes do índice FTS para o operador Fetch, que obtém apenas esses 5 documentos. A busca é muito mais eficiente aqui do que na consulta anterior, pois está buscando apenas 5 contra 904 documentos, e isso também pode ser observado na comparação dos tempos totais decorridos (e o servTime para os operadores de busca: 170ms na consulta 1 e 1,5ms na consulta 2) entre as consultas.
Conclusão
Com o GSI, é possível misturar e combinar vários índices de matriz em uma única consulta, mas com o FTS é possível misturar e combinar várias matrizes em um único índice FTS (e com o FTS não há problema de chave principal como no GSI em relação à ordem dos campos no índice). Como mostramos neste exemplo simples de consulta a 2 matrizes nos documentos do hotel, a utilização da nova função SEARCH() no N1QL pode resultar em consultas a matrizes mais simples e de melhor desempenho. O mesmo conceito poderia ser aplicado a consultas que utilizam várias matrizes, o que teria resultados ainda mais favoráveis em relação às consultas N1QL que utilizam vários índices de matriz GSI. Essa abordagem usa menos recursos do sistema e oferece maior rendimento, o que resulta em um aumento na eficiência geral do sistema.
Esse é apenas um exemplo dos benefícios da integração entre o N1QL e o FTS, e outros benefícios estão documentados nas publicações do blog na seção de referências abaixo.
Referências
- Recursos de pesquisa do Couchbase: https://www.couchbase.com/products/full-text-search
- Documentação do Couchbase FTS: https://docs.couchbase.com/server/current/fts/full-text-intro.html
- Documentação de pesquisa N1QL do Couchbase: https://docs.couchbase.com/server/current/n1ql/n1ql-language-reference/searchfun.html
- Publicações do blog do Couchbase FTS: https://www.couchbase.com/blog/category/full-text-search/
- Treinamento on-line do Couchbase FTS: https://learn.couchbase.com/store/509465-cb121-intro-to-couchbase-full-text-search-fts
Apêndice
Definição do índice JSON: hotel_mult_arrays
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
{ "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "18.8µs" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "32.1µs", "servTime": "3.421ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "122.8µs" }, "~children": [ { "#operator": "IndexFtsSearch", "#stats": { "#itemsOut": 5, "#phaseSwitches": 23, "execTime": "239.3µs", "kernTime": "84.5µs", "servTime": "3.9146ms" }, "as": "t", "index": "hotel_mult_arrays", "index_id": "7a28a8346fad6118", "keyspace": "travel-sample", "namespace": "default", "search_info": { "field": "\"\"", "options": "{\"index\": \"hotel_mult_arrays\"}", "outname": "out", "query": "{\"query\": {\"match\": \"Ozella\"}}" }, "using": "fts", "#time_normal": "00:00.004", "#time_absolute": 0.0041539 }, { "#operator": "Fetch", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "334.8µs", "kernTime": "4.4328ms", "servTime": "1.5272ms" }, "as": "t", "keyspace": "travel-sample", "namespace": "default", "#time_normal": "00:00.001", "#time_absolute": 0.001862 }, { "#operator": "Parallel", "#stats": { "#phaseSwitches": 1, "execTime": "21.1µs" }, "copies": 2, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "49.1µs" }, "~children": [ { "#operator": "Filter", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 26, "execTime": "6.8953ms", "kernTime": "14.8149ms" }, "condition": "(((`t`.`type`) = \"hotel\") and search(`t`, {\"query\": {\"match\": \"Ozella\"}}, {\"index\": \"hotel_mult_arrays\"}))", "#time_normal": "00:00.006", "#time_absolute": 0.0068953 }, { "#operator": "InitialProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 25, "execTime": "2.3597ms", "kernTime": "20.7458ms" }, "result_terms": [ { "expr": "(`t`.`name`)" }, { "expr": "(`t`.`address`)" }, { "expr": "(`t`.`city`)" }, { "expr": "(`t`.`country`)" }, { "expr": "(`t`.`phone`)" }, { "expr": "(`t`.`public_likes`)" }, { "expr": "(`t`.`reviews`)" } ], "#time_normal": "00:00.002", "#time_absolute": 0.0023597 }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 17, "execTime": "300µs", "kernTime": "375.9µs" }, "#time_normal": "00:00", "#time_absolute": 0 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0000491 }, "#time_normal": "00:00.000", "#time_absolute": 0.0000211 } ], "#time_normal": "00:00.000", "#time_absolute": 0.0001228 }, "#time_normal": "00:00.003", "#time_absolute": 0.0034531 }, { "#operator": "Stream", "#stats": { "#itemsIn": 5, "#itemsOut": 5, "#phaseSwitches": 13, "execTime": "1.3409ms", "kernTime": "14.8586ms" }, "#time_normal": "00:00.001", "#time_absolute": 0.0013409 } ], "~versions": [ "2.0.0-N1QL", "6.5.0-4960-enterprise" ], "#time_normal": "00:00.000", "#time_absolute": 0.0000188 } |