Esta é a segunda postagem do blog de uma série de várias partes que explora a indexação de vetor composto no Couchbase. Confira a primeira postagem aqui.
A série abrangerá:
- Por que os índices vetoriais compostos são importantes, incluindo conceitos, terminologia e motivação do desenvolvedor. Um sistema inteligente de recomendação de compras será usado como exemplo.
- Como os índices de vetor composto são implementados no Serviço de Indexação do Couchbase.
- Como o pushdown ORDER BY funciona para consultas de vetor composto.
- Comportamento de desempenho no mundo real e resultados de benchmarking.
Implementação de índices de vetores compostos
O GSI usa a fábrica de índices FAISS. Uma string de índice como a mostrada abaixo será construída a partir do campo de descrição fornecido na DDL.
|
1 |
IVF{nlist}_HNSW,{PQ{M}x{N}|SQ{n} |
Exemplo: Com uma string de descrição como “IVF10000,PQ32x8”, será construída uma string de fábrica de índice FAISS como “IVF10000_HNSW,PQ32x8”.
No entanto, essa string de fábrica é usada apenas como um bloco de construção durante o treinamento e a configuração do índice. O GSI não depende do FAISS como um índice monolítico na memória para todo o conjunto de dados. Em vez disso, o FAISS é aplicado seletivamente em dados amostrados para aprender centroides e livros de códigos de quantização, enquanto o layout completo do índice, o armazenamento, o tratamento de mutação e a execução de consultas são gerenciados pelo Couchbase. Isso permite que o Couchbase dimensione a pesquisa vetorial de forma eficiente, integre a filtragem escalar e a semântica de consulta e ofereça suporte a atualizações contínuas - que vão muito além da invocação de um índice FAISS autônomo.
Embeddings
A camada de incorporação pega os campos de texto relevantes, envia-os por meio de um modelo de transformação e produz vetores semânticos que representam cada produto. Esses vetores alimentam a pesquisa ANN. O aplicativo deve armazenar essas incorporações junto com os dados do produto para que o índice vetorial possa usá-las e garantir que as incorporações armazenadas correspondam à definição do índice vetorial (por exemplo, dimensão fixa e tipo numérico) esperada pelo Couchbase.
|
1 2 3 4 5 6 7 8 |
{ "product_name": "almond butter", "sugar_100g": 15, "proteins_100g": 20, "description": "almond butter with chocolate chips", "text_vector": [0.12, -0.04, 0.33, 0.25, ...] ... } |
Criação e desenvolvimento de índices
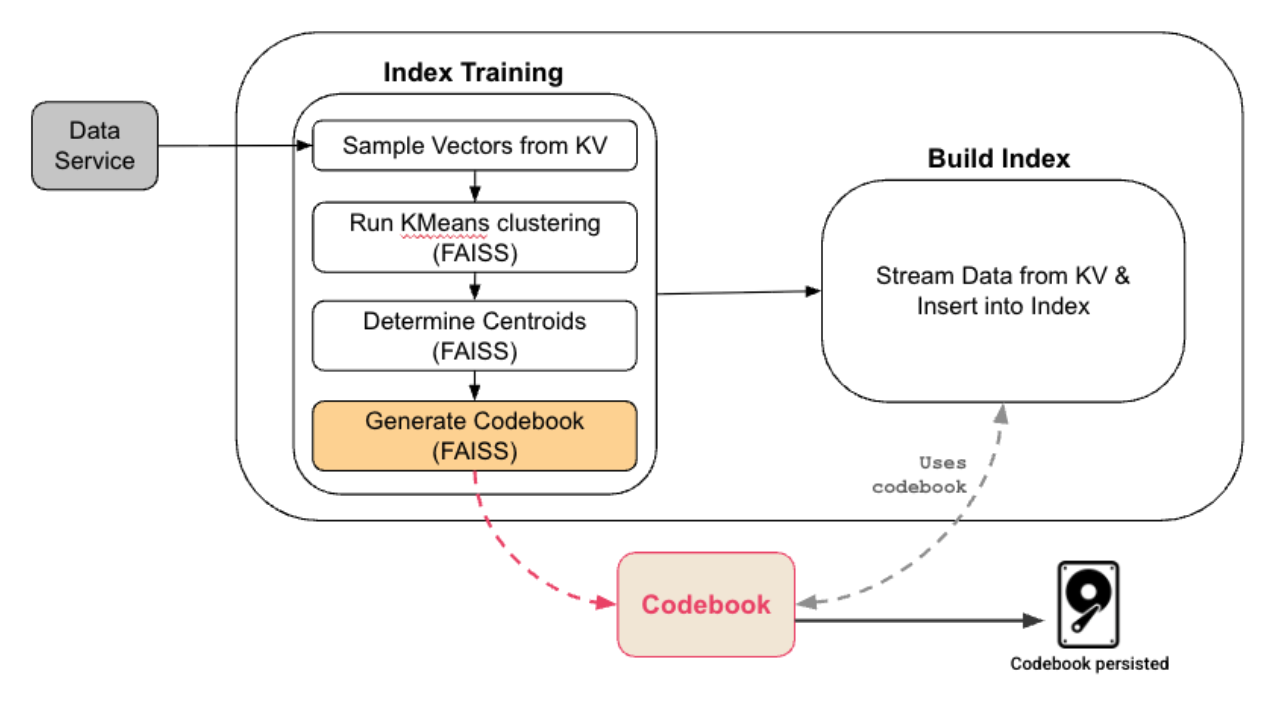
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE INDEX idx_vec_food ON food ( text_vector VECTOR, sugars_100g, proteins_100g, product_name ) WITH { "dimension": 384, "similarity": "L2", "description": "IVF,SQ8" }; |
Criar e desenvolver o fluxo
- Como o usuário tem um número suficiente de vetores armazenados, o GSI faz uma amostragem aleatória dos dados para criar um conjunto de dados representativo.
- Esse conjunto de dados representativo é usado para treinar o índice FAISS. Após o treinamento, o GSI mantém o livro de códigos que inclui uma lista invertida IVF e livros de códigos PQ:
- O IVF divide o espaço vetorial em n partições listadas e cada partição é representada por um centroide
- A quantização PQ ou SQ é usada por partição para compactar os vetores
- O gráfico HNSW dos centroides é criado; ele é útil quando o número de centroides é muito grande
- Os dados são transmitidos do Data Service usando o protocolo DCP e para cada documento recebido.
- O documento é atribuído à partição cujo centroide está mais próximo do vetor, ou seja, o centroide é C1
- Durante a indexação, o vetor de cada documento é atribuído ao centroide mais próximo, armazenado em uma forma codificada compacta otimizada para o cálculo rápido da distância e rastreado de forma eficiente para que futuras atualizações só reprocessem o vetor se ele realmente mudar.
Observação
Se a distribuição do vetor subjacente mudar significativamente, o índice deverá ser reconstruído para treinar novamente o índice. Isso pode ocorrer devido a:
- Uma alteração no modelo de incorporação (por exemplo, troca de modelos ou dimensões)
- Mudanças importantes na distribuição de dados (novas categorias de produtos, alterações de idioma ou desvio de domínio)
- Reincorporação de documentos existentes com incorporações atualizadas
Quantos documentos são necessários para treinar um índice vetorial?
Ao criar um índice vetorial, o Couchbase coleta automaticamente amostras de dados vetoriais para treinar o índice para uma pesquisa ANN eficiente e precisa.
Em geral, a coleção deve conter pelo menos tantos documentos quanto o número de centroides (nlist) configurados para o índice, pois cada centroide requer dados de treinamento.
Quando a quantização de produto (PQ) é usada, esse mínimo se torna max(nlist, 2^nbits) para garantir dados suficientes para o treinamento do quantizador, em que nbits é N de PQ{M}x{N}.
O Couchbase lida com o treinamento da seguinte forma:
- Conjuntos de dados pequenos (até cerca de 10.000 documentos):
- Todos os vetores são usados para treinamento, não é necessária nenhuma amostragem.
- Conjuntos de dados maiores:
- Por padrão, o Couchbase seleciona um conjunto de treinamento tomando o maior dos seguintes, enquanto limita o tamanho da amostra final a 1 milhão de vetores:
- 10% do conjunto de dados, e
- 10x o número de centroides (nlist)
- Essa abordagem equilibra a qualidade do treinamento com o tempo de criação do índice
- Por padrão, o Couchbase seleciona um conjunto de treinamento tomando o maior dos seguintes, enquanto limita o tamanho da amostra final a 1 milhão de vetores:
Melhores práticas: Para obter um treinamento estável e de alta qualidade, busque pelo menos 10 vetores por centroide, o que permite que o índice aprenda a distribuição do vetor subjacente de forma eficaz.
Controle avançado: Se necessário, você pode controlar explicitamente o número de vetores de treinamento especificando o parâmetro train_list ao criar o índice.
O Couchbase gerencia o processo de amostragem e treinamento automaticamente. Como usuário, o principal requisito é garantir que exista um número suficiente de documentos incorporados antes de criar o índice.
Varredura de índice
|
1 2 3 4 5 |
SELECT product_name FROM food WHERE sugars_100g < 20 AND proteins_100g > 10 ORDER BY APPROX_VECTOR_DISTANCE(text_vector, [query_embedding], 'L2') LIMIT 10; |
Fluxo de varredura
Quando chega uma consulta que contém uma pesquisa vetorial, o Couchbase segue uma sequência bem definida para encaminhá-la aos componentes certos e preparar a varredura.
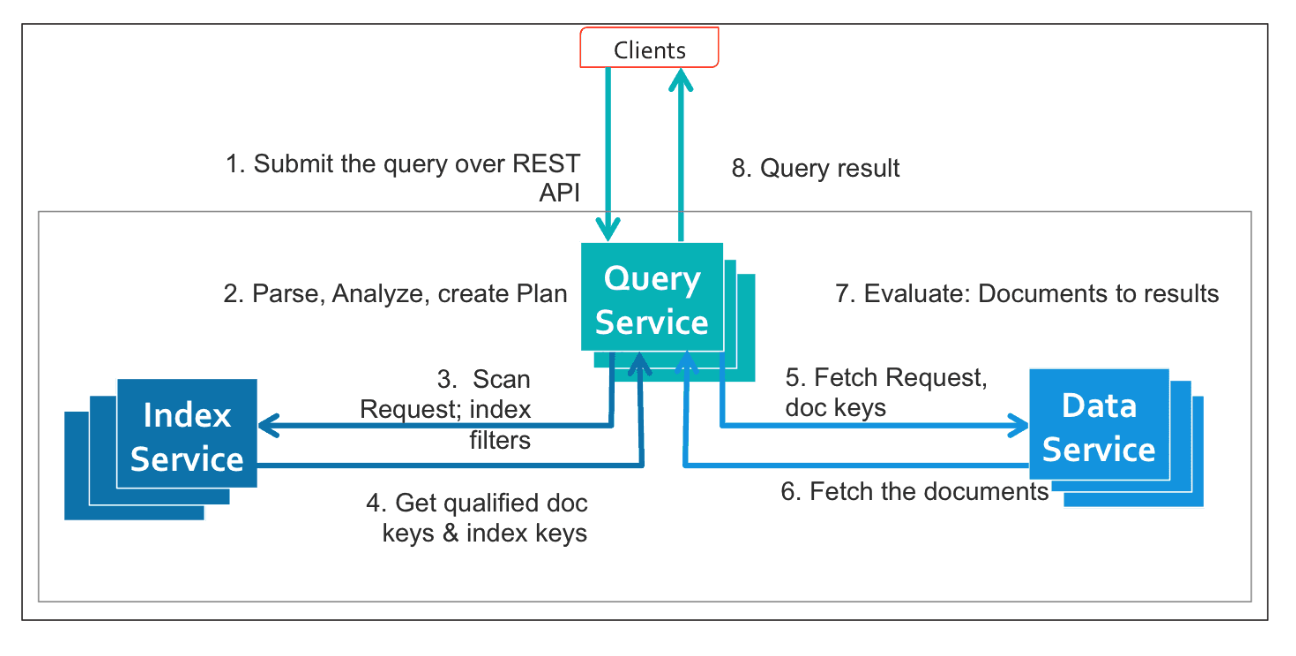
Se os índices vetoriais variáveis tiverem sido criados e estiverem ativos, o Query Service poderá usá-los para atender mais rapidamente às consultas ANN filtradas
O coordenador de varredura no processo do indexador recebe as entradas mencionadas abaixo junto com o nome do índice e os parâmetros de consistência:
- Filtros escalares em campos indexados
- Predicados de igualdade ou de intervalo, como sugars_100g < 20
- O vetor de consulta
- Incorporação da intenção de pesquisa do usuário
- O tamanho do resultado k
- Quantos itens semelhantes o usuário deseja recuperar
- Isso é fornecido no LIMIT
- O número de centroides mais próximos n
- Quanto do espaço vetorial queremos pesquisar
- O valor nprobes n é um parâmetro para DISTÂNCIA_APROXIMADA_DO_VETOR
Depois de obter as informações acima, é formada uma solicitação de varredura, que passa pelas seguintes etapas:
- O instantâneo do índice é obtido com base nos parâmetros de consistência fornecidos.
- Se o usuário precisar de consistência de sessão, o indexador buscará o carimbo de data/hora mais recente do Data Service e aguardará que o indexador se atualize e gere instantâneos consistentes que possam atender à consulta.
- Se o usuário não tiver problemas com qualquer consistência, o indexador usará o instantâneo armazenado em cache sem esperar.
- O indexador aguarda os leitores de armazenamento necessários para atender à consulta.
- Como os recursos do indexador são limitados, ele é configurado com o número máximo de leitores que podem ser executados; portanto, se um sistema estiver ocupado, as varreduras deverão esperar que os leitores fiquem livres.
- O indexador obtém os livros de código para as partições que estão sendo examinadas para a consulta fornecida.
- Observe que o livro de códigos (lista invertida IVF e livros de códigos PQ) não muda após a fase inicial de treinamento, portanto, não há instantâneos para o livro de códigos.
- Usando os livros de códigos obtidos acima, o mais próximo nprobe centroides do vetor de consulta em cada partição necessária são obtidos para um determinado vetor de consulta.
- Para uma determinada partição de índice, os filtros escalares e os centróides mais próximos são combinados para formar intervalos de varredura não sobrepostos para ler dados do índice.
- Agora, o indexador configura um pipeline de varredura dedicado. Pense nesse pipeline como uma linha de montagem pequena e de curta duração criada especificamente para essa consulta. Os estágios do pipeline (leitura, acumulação e gravação) são executados em paralelo para acelerar o processo de consulta.
Pipeline de varredura
O próprio pipeline de varredura tem três estágios: leitura, agregação e gravação. Como qualquer pipeline, cada estágio é executado em paralelo e transmite sua saída para o próximo.

- Estágio de leitura => Varredura paralela + Filtragem escalar
- O estágio de leitura se espalha por vários trabalhadores de varredura.
- Cada trabalhador:
- Faz a varredura e lê o intervalo de índice atribuído.
- Aplica filtros escalares antecipadamente para eliminar itens irrelevantes.
- Encaminha apenas os documentos de qualificação para a próxima etapa.
- Essa poda antecipada é fundamental; ela evita cálculos desnecessários de distância vetorial posteriormente.
- Estágio Agregado => Ordenação + Computação da Distância Vetorial
- O estágio agregado coleta resultados de todos os trabalhadores e realiza o “trabalho pesado”.”
- Ele mescla e ordena itens, se necessário.
- Ele substitui as distâncias aproximadas baseadas em centroides por distâncias computadas reais.
- Ele mantém uma pilha top-k para rastrear os melhores candidatos até o momento.
- Esse estágio é onde a lógica ANN encontra a filtragem escalar.
- Estágio de gravação => Transmissão de resultados de volta ao cliente GSI no serviço de consulta
- Por fim, o estágio de gravação transmite os resultados agregados para o serviço de consulta.
- Se o índice for distribuído em vários nós do indexador, os resultados de cada nó serão mesclados.
- A partir daí, o processador de consultas pode executar operações adicionais, como:
- Filtragem de granulação grossa
- JOINs
- Projeções ou classificação final
Por fim, o usuário recebe uma lista limpa e ordenada dos vizinhos mais próximos que satisfazem todas as condições escalares.
Comportamento avançado de consultas em varreduras de índices vetoriais compostos
Depois de entender como funciona um pipeline de varredura vetorial, há vários conceitos mais profundos que influenciam a eficiência da execução das consultas. Esses comportamentos estão ligados ao modo como o índice é definido e como os predicados escalares interagem com as partições de vetor.
Paralelismo de varredura
Cada consulta tem um limite natural de quanto paralelismo pode ser explorado. Esse paralelismo inerente vem de quantos intervalos de índices não sobrepostos podem ser gerados a partir dos predicados escalares e das nprobes. Mais intervalos disjuntos significam mais oportunidades de varredura em paralelo.
Mas as restrições de escala não são o único fator. O número real de trabalhadores que o sistema usa é o mínimo de:
- O grau de paralelismo inerente que a consulta pode expor
- Quantos centroides a consulta precisa pesquisar
- Quantos centroides o índice contém
- O máximo configurado de trabalhadores por varredura por partição
Isso evita que o sistema sobrecarregue a CPU ou crie threads desnecessários quando não houver trabalho paralelo adicional a ser feito.
Predicados-chave principais - Onde o paralelismo começa
Os predicados nas chaves principais do índice (os primeiros campos listados na definição do índice composto) determinam o grau de paralelismo que sua consulta pode explorar.
Se uma chave escalar principal tiver vários predicados de igualdade, cada um deles se tornará um intervalo de varredura independente, permitindo que o sistema se espalhe e os execute em paralelo.
Se a chave principal usar um predicado de intervalo, toda a consulta será colapsada em um grande intervalo de varredura, o que reduz o paralelismo.
Em resumo:
- Igualdade nas chaves principais → paralelismo máximo
- Intervalo nas teclas principais → uma grande varredura sequencial
A escolha das chaves principais corretas na definição do índice tem um impacto direto na latência.
Os predicados de vetor se comportam efetivamente como filtros de igualdade em IDs de centroides, selecionando um conjunto fixo de clusters para varredura.
Seletividade escalar - Quanto trabalho você não precisa fazer
A seletividade escalar mede quantos pontos de dados podem ser eliminados por um filtro escalar.
Um filtro altamente seletivo remove uma grande parte do conjunto de dados antes mesmo do início dos cálculos de distância vetorial.
Por exemplo:
- sugars_100g < 20 pode eliminar 70% de itens
- proteins_100g > 10 pode eliminar 90% de itens
Quanto mais seletivo for o escalar, menos vetores o índice deverá comparar.
O rendimento da varredura de índice de vetor composto aumenta proporcionalmente com a seletividade escalar, porque o pipeline gasta menos tempo lendo documentos e computando distâncias.
Paginação - Resultados de vetores ordenados
As varreduras de índice de vetor composto produzem uma ordem global para o conjunto de resultados.
Isso acontece porque o índice substitui as IDs de centroide por distâncias de vetor reais, fornecendo a cada candidato uma métrica de distância precisa.
Você pode usar LIMIT e OFFSET para paginar os resultados, desde que existam itens qualificados suficientes dentro dos n centroides selecionados.
Isso torna os índices vetoriais compostos adequados para UIs que exigem rolagem infinita ou navegação de produtos página por página.
Flexibilidade na definição do índice - Adapte o índice à carga de trabalho
A DDL de índice de vetor composto oferece controle total sobre a ordenação das chaves de índice.
Essa ordem afeta diretamente a forma como a filtragem é realizada, o que, por sua vez, afeta o desempenho da consulta.
Essa flexibilidade permite várias estratégias de poda:
- Poda centrada no vetor
- Inicie o índice com a chave do vetor, seguida pelos escalares:
- CREATE INDEX idx ON food(text_vector, sugars_100g, proteins_100g)
- Ideal para cargas de trabalho orientadas principalmente pela similaridade de vetores.
- Inicie o índice com a chave do vetor, seguida pelos escalares:
- Poda centrada em escalar
- Coloque os campos escalares altamente seletivos primeiro e depois a chave vetorial:
- CREATE INDEX idx ON food(sugars_100g, proteins_100g, text_vector)
- Esse é o padrão mais comum e mais eficiente porque os escalares seletivos são podados de forma agressiva antes do início da avaliação do vetor.
- Coloque os campos escalares altamente seletivos primeiro e depois a chave vetorial:
- Poda somente de vetor
- Criar um índice somente na chave do vetor:
- CREATE INDEX idx ON food(text_vector)
- Isso é útil quando os campos escalares têm pouca seletividade e não ajudam a reduzir o espaço de pesquisa.
- Criar um índice somente na chave do vetor:
- Poda somente escalar
- Criar um índice tradicional não vetorial para consultas que não usam similaridade vetorial.
Suporte a consultas somente escalares e varreduras de cobertura
Quando os predicados escalares em uma consulta são escalonáveis em relação às chaves escalares de um índice de vetor composto, o índice pode ser usado para atender a consultas puramente escalares - mesmo quando nenhuma condição de similaridade de vetor estiver presente. Nesses casos, o índice de vetor composto se comporta como um índice secundário tradicional e pode atuar como um índice de cobertura, permitindo que a consulta seja satisfeita inteiramente a partir do índice sem buscar documentos no Data Service.
A consulta somente escalar:
|
1 2 3 |
SELECT product_name FROM food WHERE sugars_100g < 20 AND proteins_100g > 10; |
Está disponível para:
|
1 2 |
CREATE INDEX idx_vec_food ON food(sugars_100g, proteins_100g, text_vector VECTOR, product_name); |
E não para:
|
1 2 |
CREATE INDEX idx_bad ON food(text_vector VECTOR, sugars_100g, proteins_100g); |
Isso se deve ao fato de que:
- A chave principal é um vetor
- O GSI não pode procurar ou fazer varredura de alcance nele
- O índice não pode ser usado de forma eficiente para predicados escalares
Até este ponto, vimos como os índices de vetores compostos combinam a poda escalar com a similaridade vetorial de forma eficiente. Mas a similaridade por si só raramente é suficiente em aplicativos reais. O que acontece quando você deseja obter resultados semanticamente próximos de uma consulta e ordenados de acordo com sinais específicos do aplicativo, como nutrição, preço ou frescor, sem puxar grandes conjuntos de resultados de volta para a camada de consulta?
Na próxima parte desta série, vamos nos aprofundar em Pesquisa ANN filtrada com índices de vetores compostos e mostrar como o Couchbase transfere a semântica complexa de ORDER BY e LIMIT diretamente para o indexador, permitindo que a similaridade baseada em distância e a ordenação escalar sejam avaliadas juntas em um único caminho de execução eficiente.