Recentemente, quando estava explorando nossa documentação para me familiarizar com os recursos do Elasticsearch Connector 4.2, deparei-me com uma configuração chamada Pipeline. Fiquei curioso para explorar e entender o que isso significa e qual é a finalidade dessa solução. Ao fazer isso, experimentei o conector e sua configuração e gostaria de compartilhar minha experiência neste post.
Visão geral
Nesta postagem, abordaremos a replicação e a transformação de da amostra de viagem Conjunto de dados de referência do Couchbase para o Elasticsearch usando o conector do Elasticsearch e um pipeline de nó de ingestão do Elasticsearch.
Vamos dar uma olhada rápida nos diferentes componentes que usaremos ao longo desta postagem do blog.
Couchbase é um banco de dados de documentos JSON distribuído e de código aberto. Ele expõe um armazenamento de valores-chave com escalonamento horizontal, com cache gerenciado para operações de dados em sub-milissegundos, indexadores criados especificamente para consultas eficientes e um mecanismo de consulta avançado para executar consultas do tipo SQL.
Elasticsearch é um banco de dados NoSQL distribuído de texto completo com um poderoso mecanismo de busca e análise no coração do Elastic Stack. O Elasticsearch armazena documentos em índices (às vezes chamados de Indices?) que são análogos a tabelas no mundo sql.
Pipeline de nó de ingestão é uma ferramenta poderosa que o Elasticsearch oferece para pré-processar seus documentos antes de serem indexados. Um pipeline de nó de ingestão consiste em um ou mais processadores que são executados na ordem em que são declarados. O Elasticsearch vem com um conjunto de processadores prontos para uso, mas você também pode criar um processador personalizado conforme necessário. Para obter uma lista de todos os processadores, visite a documentação aqui.
Conector Elasticsearch é uma ferramenta criada pelo Couchbase que permite a replicação de dados do Couchbase para o Elasticsearch.
Kibana é uma interface de usuário gratuita e aberta que permite visualizar os dados do Elasticsearch e navegar no Elastic Stack. O Kibana também permite o gerenciamento e a avaliação de pipelines de nós de ingestão.
Pré-requisitos e premissas
Esta postagem pressupõe que você tenha um conhecimento básico de todos os componentes listados acima e que esteja usando um computador com macOS para percorrer a ilustração.
-
-
- Instale e configure o Couchbase Server com um conjunto de dados de amostra de viagem seguindo as instruções aqui.
- Instalar um compatível versão do java.
-
Começar a usar
Abra uma nova janela de terminal e navegue até o seu diretório de usuário localizado em /Users/. Crie um novo diretório chamado Conectores. Vamos nos referir a isso como "BASE_DIR" para o restante da postagem.
|
1 |
mkdir Connectors |
Instalar e iniciar o Elasticsearch e o Kibana
-
-
Baixar a versão mais recente do Elasticsearch e do Kibana e movê-los para o BASE_DIR. Você deverá ver dois arquivos Elasticsearch--darwin-x86_64.tar.gz e kibana--darwin-x86_64.tar.tz.
-
Descompacte os arquivos baixados e renomeie o diretório para es e kibana
-
Abra um novo terminal e navegue até BASE_DIR e depois tdigite os seguintes comandos (uma de cada vez)
|
1 |
tar -xzvf elasticsearch-7.8.0-darwin-x86_64.tar.gz && tar -xzvf kibana-7.8.0-darwin-x86_64.tar.gz |
|
1 |
mv elasticsearch-7.8.0-darwin-x86_64 es && mv kibana-7.8.0-darwin-x86_64 kibana |
3. Iniciar o Elasticsearch
Abra uma nova janela de terminal e navegue até o diretório BASE_DIR/es então tdigite o seguinte comando
|
1 |
bin/elasticsearch |
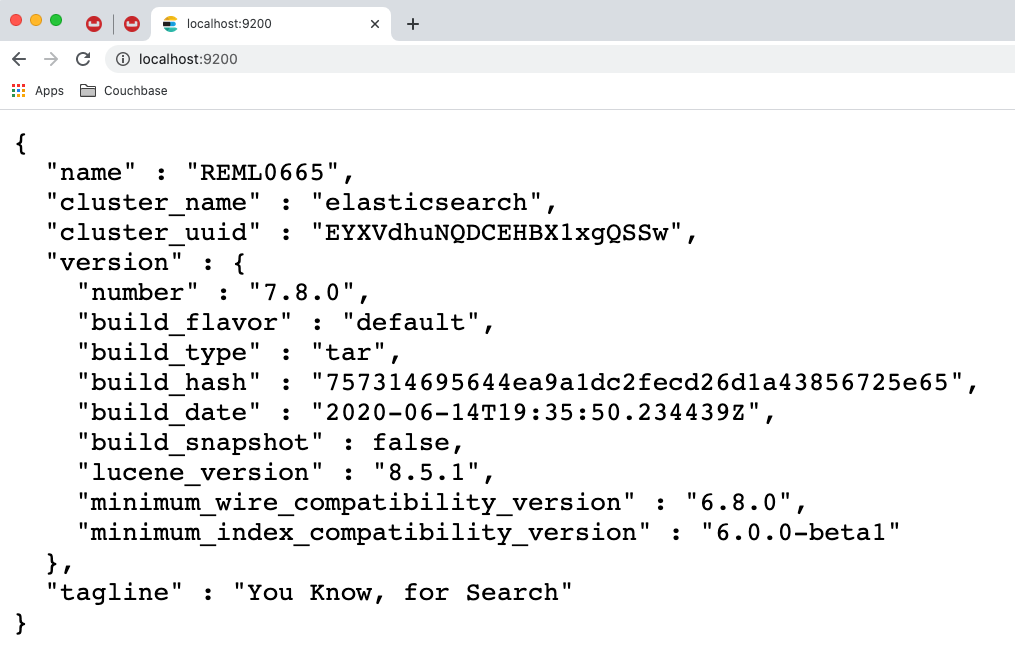
Agora, abra um navegador da Web e navegue até https://localhost:9200Você deverá ver uma resposta como a abaixo, indicando que o servidor Elasticsearch está disponível.
4. Iniciar o Kibana
Abra uma nova janela de terminal e navegue até o diretório BASE_DIR/kibana então tdigite o seguinte comando
|
1 |
bin/kibana |
Para ver o Kibana em ação, abra um navegador da Web e navegue até https://localhost:5601 .
Instalar o conector do Elasticsearch
-
-
Baixar a versão mais recente do conector Elasticsearch e mova-o para o diretório BASE_DIR. No momento em que este post foi escrito, a versão mais recente do conector disponível era a 4.2.2. Você deve ter baixado um arquivo que se parece com couchbase-elasticsearch-connector-<version>.zip.
-
Descompacte o arquivo baixado e renomeie o diretório para cbes.
-
Abra um novo terminal e navegue até BASE_DIR e tdigite os seguintes comandos (uma de cada vez). Quando solicitado, digite "A" para descompactar os arquivos
|
1 |
unzip couchbase-elasticsearch-connector-4.2.2.zip |
|
1 |
mv couchbase-elasticsearch-connector-4.2.2 cbes |
Agora vamos explorar alguns dos diretórios importantes dentro de cbes
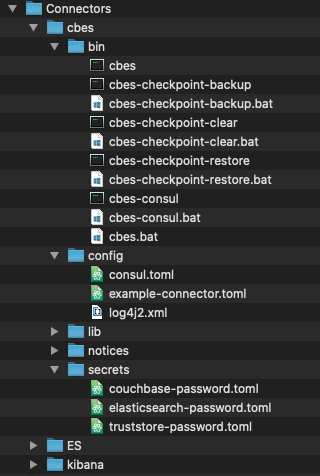
caixa - contém todos os utilitários de linha de comando necessários para ajudar a gerenciar os conectores.
configuração - contém o arquivo de configuração básico que pode ser usado como referência.
segredos - contém credenciais para conexão com os servidores Couchbase e Elasticsearch.
Criar pipeline de nó de ingestão do Elasticsearch
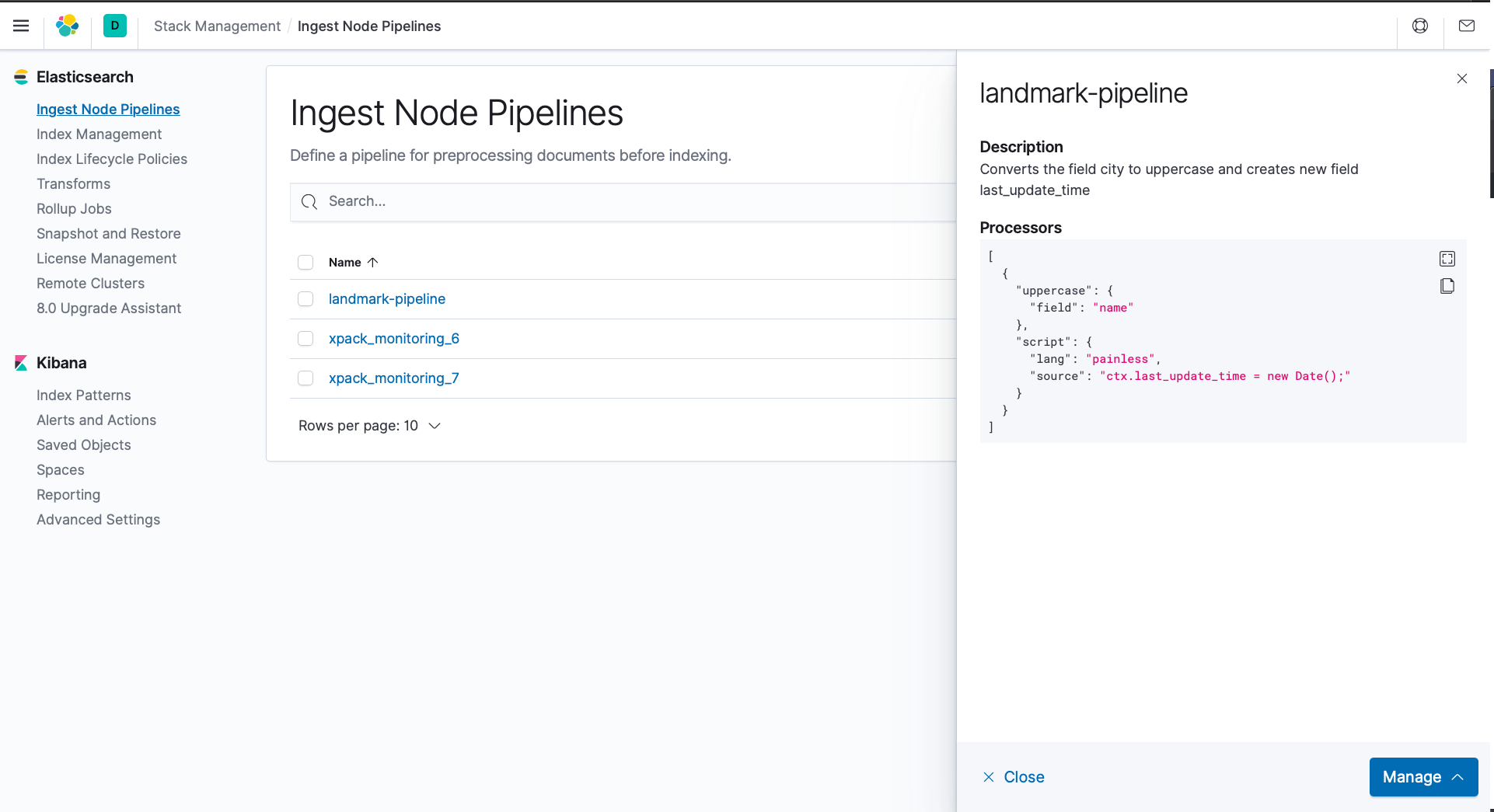
Vamos construir nosso pipeline. Vamos chamá-lo de "landmark-pipeline". Nosso pipeline irá
-
-
-
- Inserir um novo campo
last_update_time que será a data-hora atual. - Converter os dados em UPPERCASE para o campo
nome.
- Inserir um novo campo
-
-
Usaremos dois dos processadores existentes para criar nosso pipeline de ingestão.
Processador de scripts : Executa qualquer script definido pelo linguagem de script indolor.
Processador de letras maiúsculas : Converte o valor do campo especificado em UPPERCASE
1. Abra uma nova janela de terminal e execute o seguinte comando
|
1 2 3 4 5 |
curl -X PUT "localhost:9200/_ingest/pipeline/landmark-pipeline?pretty" -H 'Content-Type: application/json' -d' { "description" : "Converts the field name to uppercase and creates new field last_update_time ", "processors" : [ { "uppercase": { "field": "name" }, "script": { "lang": "painless", "source": "ctx.last_update_time = new Date();" } } ] }' |
O comando curl acima cria e salva uma definição de pipeline no banco de dados do Elasticsearch.
2. Abra um navegador da Web e navegue até o Kibana em https://localhost:5601. Você deve conseguir ver o pipeline que acabou de criar em Discover -> Ingerir pipelines de nós.
Configurar o conector do Elasticsearch
1. Abra uma nova janela de terminal e navegue até BASE_DIR/cbes/config
2. Copie o arquivo example-connector.toml e nomeá-lo como default-connector.toml executando o seguinte comando
|
1 |
cp example-connector.toml default-connector.toml |
O Connector pressupõe a existência de um arquivo de configuração default-connector.toml e lê esse arquivo para qualquer configuração. No entanto, você também pode especificar a configuração ao implantar o conector usando a opção de linha de comando - -config. Para esta postagem, usaremos a configuração padrão.
3. Abra default-connector.toml no editor de sua escolha e modifique as seguintes definições de configuração. aqui.
Se você quiser pular esta etapa, um arquivo de configuração modificado completo pode ser encontrado aqui.
Dica: se esta é a primeira vez que você trabalha com o formato de arquivo de configuração TOML, consulte o excelente artigo de Nate Finch Introdução ao TOMLou o especificação oficial.
a ) Sob o [grupo] defina a chave de nome como "landmark-example-group"
|
1 2 |
[group] name = 'landmark-example-group' |
b) Sob o [elasticsearch.docStructure] defina a chave documentContentAtTopLevel como "true"
|
1 2 |
[elasticsearch.docStructure] documentContentAtTopLevel = true |
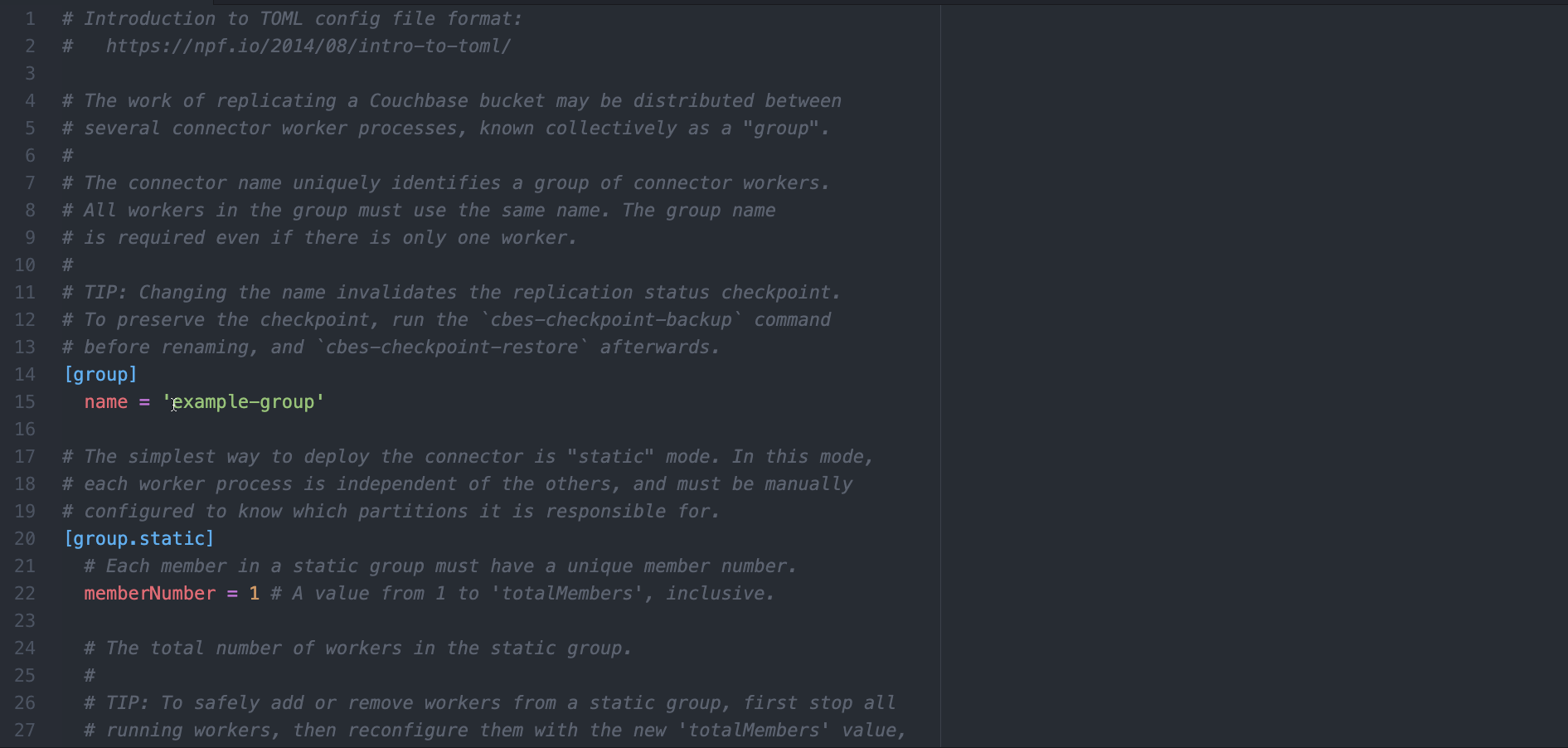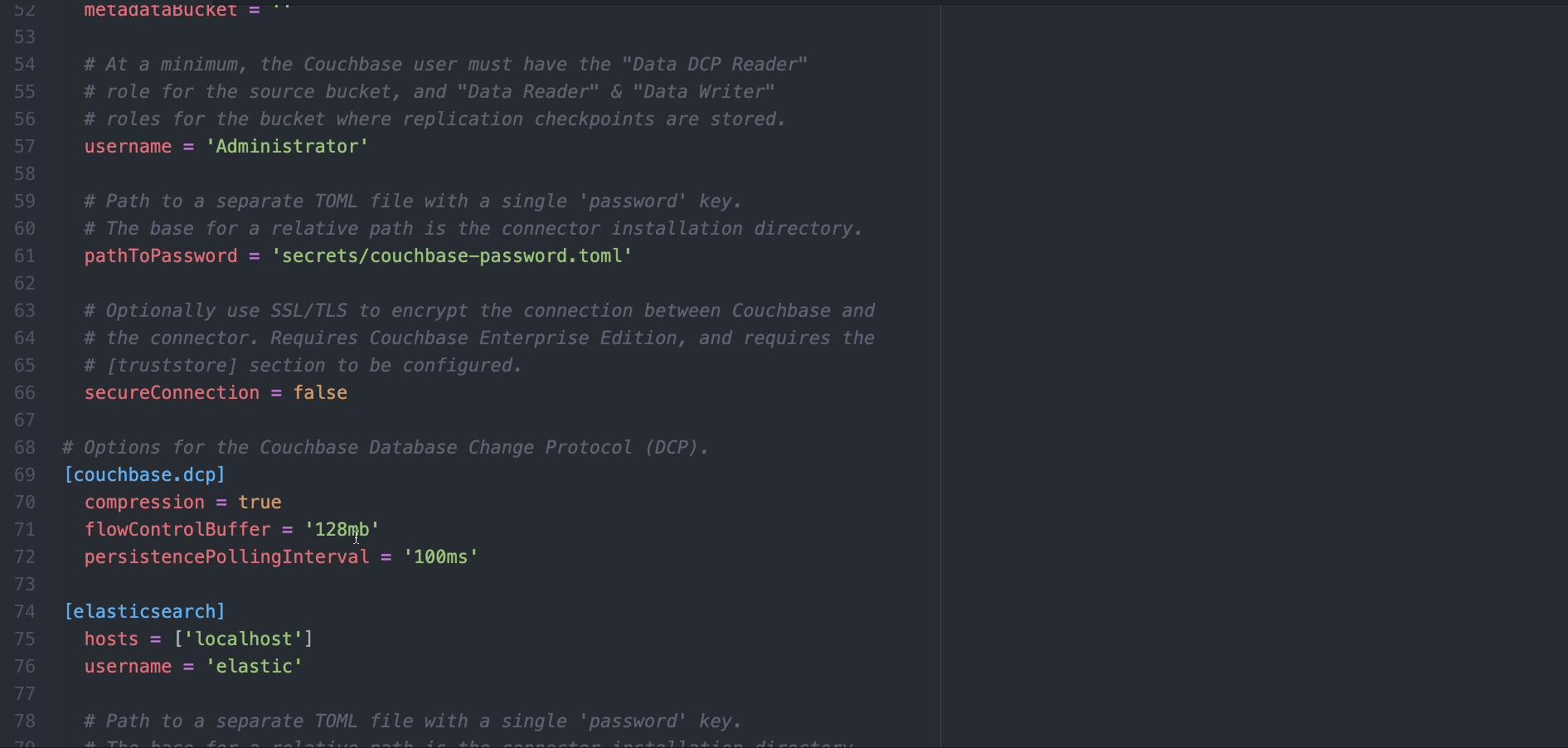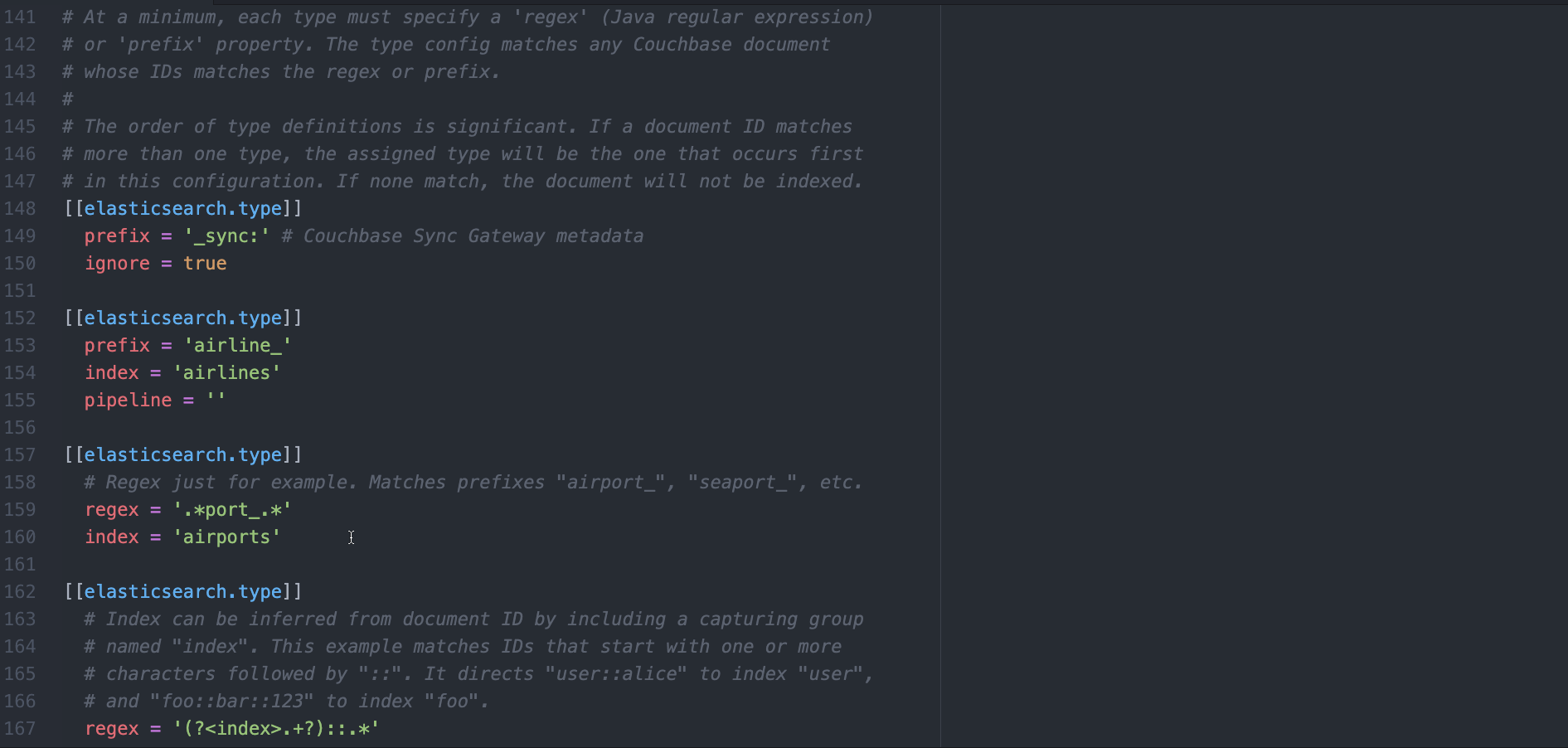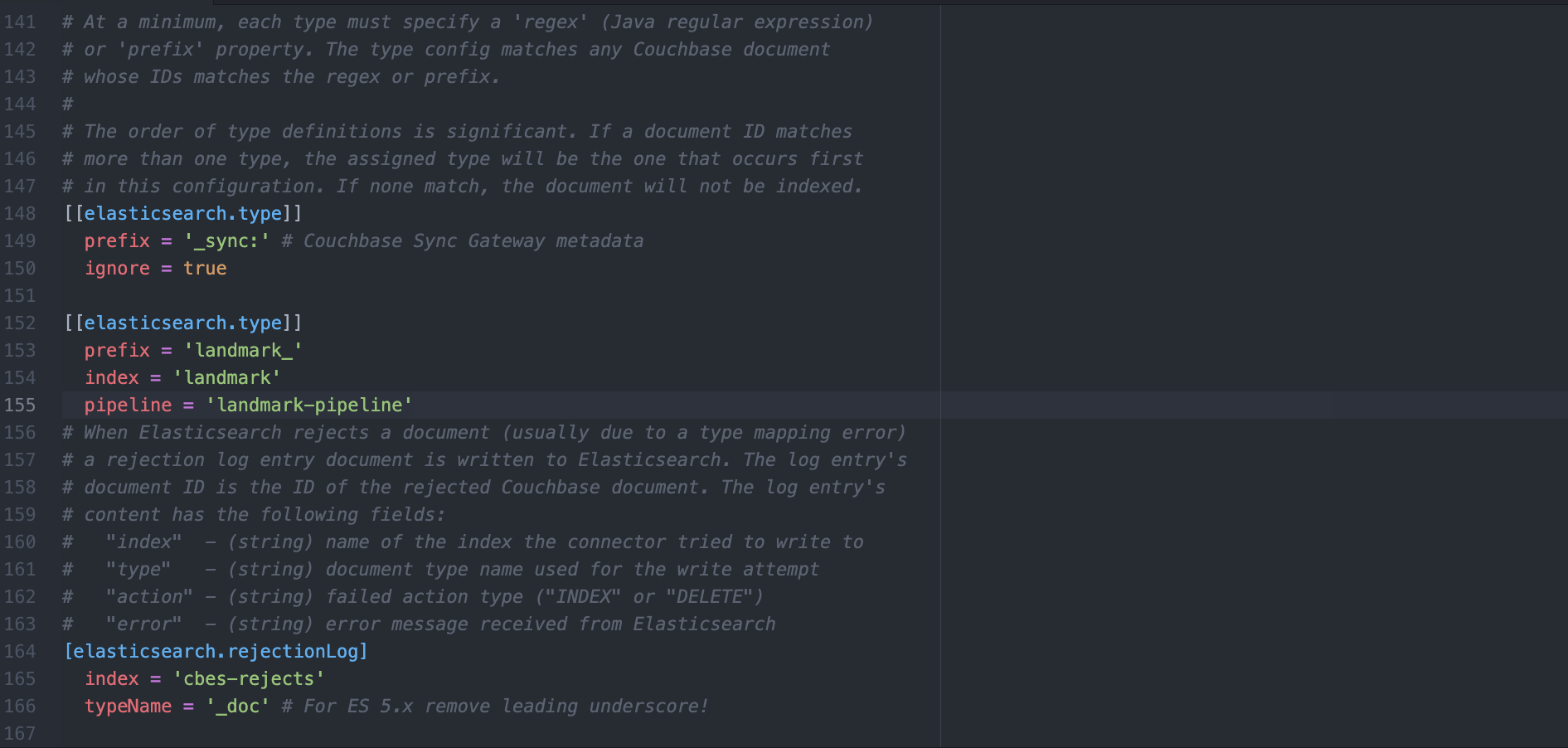
c) Remover qualquer [[elasticsearch.type]] e substituir pelo seguinte.
|
1 2 3 4 5 6 7 8 |
[[elasticsearch.type]] prefix = '_sync:' ignore = true [[elasticsearch.type]] prefix = 'landmark_' index = 'landmark' pipeline = 'landmark-pipeline' |
Implantar o conector do Elasticsearch
Está tudo pronto. Agora é hora de ver tudo isso em ação.
Os conectores do Elasticsearch podem ser implantados de três modos diferentes
Solo : Esse é o modo mais simples, em que o conector é executado como um processo autônomo. O modo solo é preferível em um ambiente de baixo tráfego ou em um ambiente de desenvolvimento.
Distribuído : Nesse modo, vários conectores são executados como processos diferentes. Em um cenário em que o tráfego é de moderado a alto, esse modo é recomendado. Ao contrário do modo solo, em que apenas um processo dedicado faz todo o trabalho, em um modo distribuído há mais de um processo e cada conector é configurado independentemente para compartilhar a carga de trabalho.
Modo de operações autônomas : Isso pode ser considerado como um modo distribuído gerenciado por um serviço coordenado. O serviço coordenado cuida da descoberta do serviço e do gerenciamento da configuração. Ao contrário do modo distribuído, em que os processos precisam ser interrompidos e reiniciados antes de adicionar e remover um processo conector, o serviço coordenado distribui automaticamente a carga de trabalho quando um processo de trabalho é adicionado ou removido, mesmo em casos de falha.
Para esta postagem, implantaremos o conector em um modo Solo. Antes de iniciar o conector, vamos verificar a contagem de documentos na origem no Couchbase.
1. Abra um navegador da Web e navegue até o cluster do Couchbase, por exemplo https://127.0.0.1:8091/ui/index.html
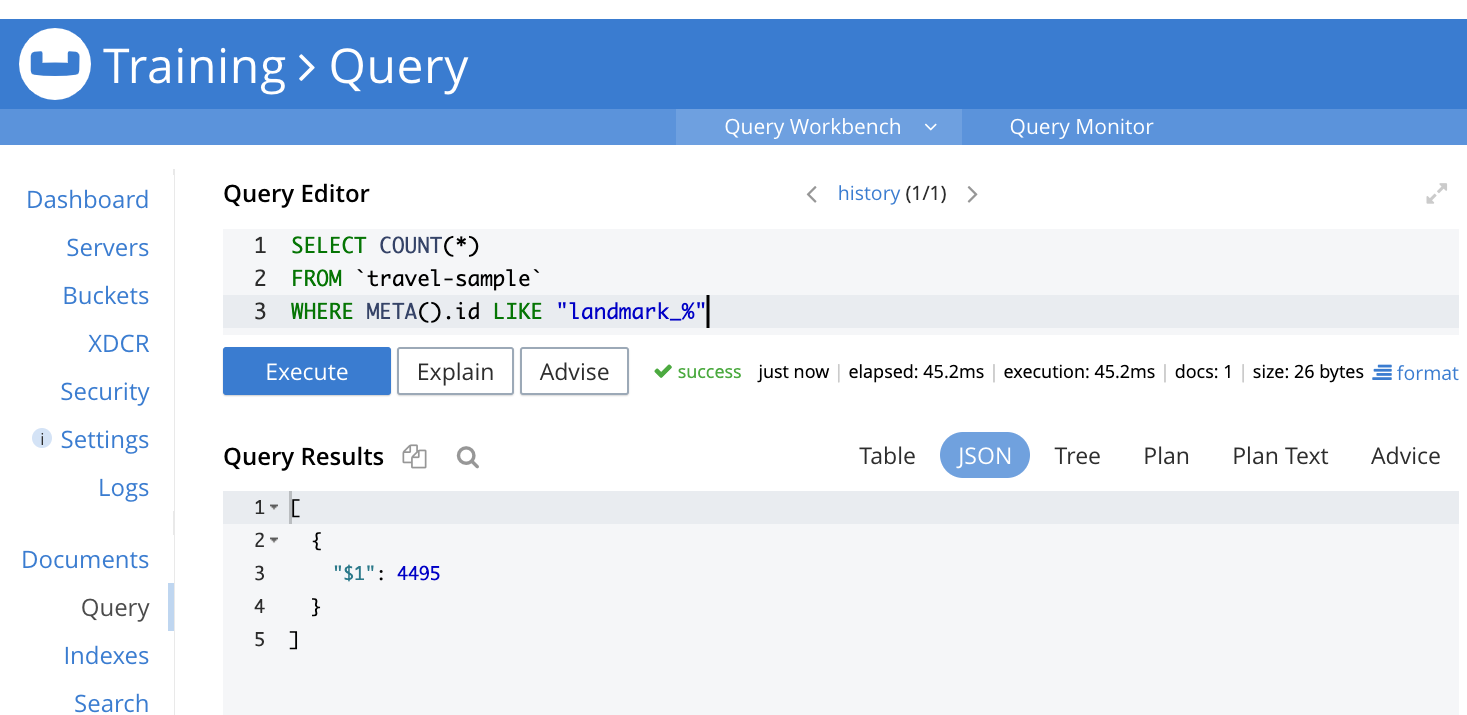
Vá para o menu Query (Consulta) e execute a seguinte consulta
|
1 2 3 |
SELECT COUNT(*) FROM `travel-sample` WHERE META().id LIKE ‘landmark_%’ |
Essa consulta deve retornar a contagem de documentos no intervalo de amostras de viagens em que a chave do documento começa com "landmark_". No nosso caso, a contagem é de 4.495 documentos.
2. Vamos iniciar nosso conector.
Abra uma nova janela de terminal e navegue até BASE_DIR/cbes diretório e tdigite o seguinte comando
|
1 |
bin/cbes |
O conector deve começar a copiar documentos (onde a chave do documento começa com "landmark_") do Couchbase amostra de viagem no Elasticsearch. Enquanto isso acontece, o pipeline do nó de ingestão converterá os valores do nome em maiúsculas e também criará um campo last_update_time.
3. Agora vamos verificar se as transformações desejadas foram aplicadas quando os documentos foram replicados.
Abra um novo navegador e navegue até o Kibana em https://localhost:5601
-
-
-
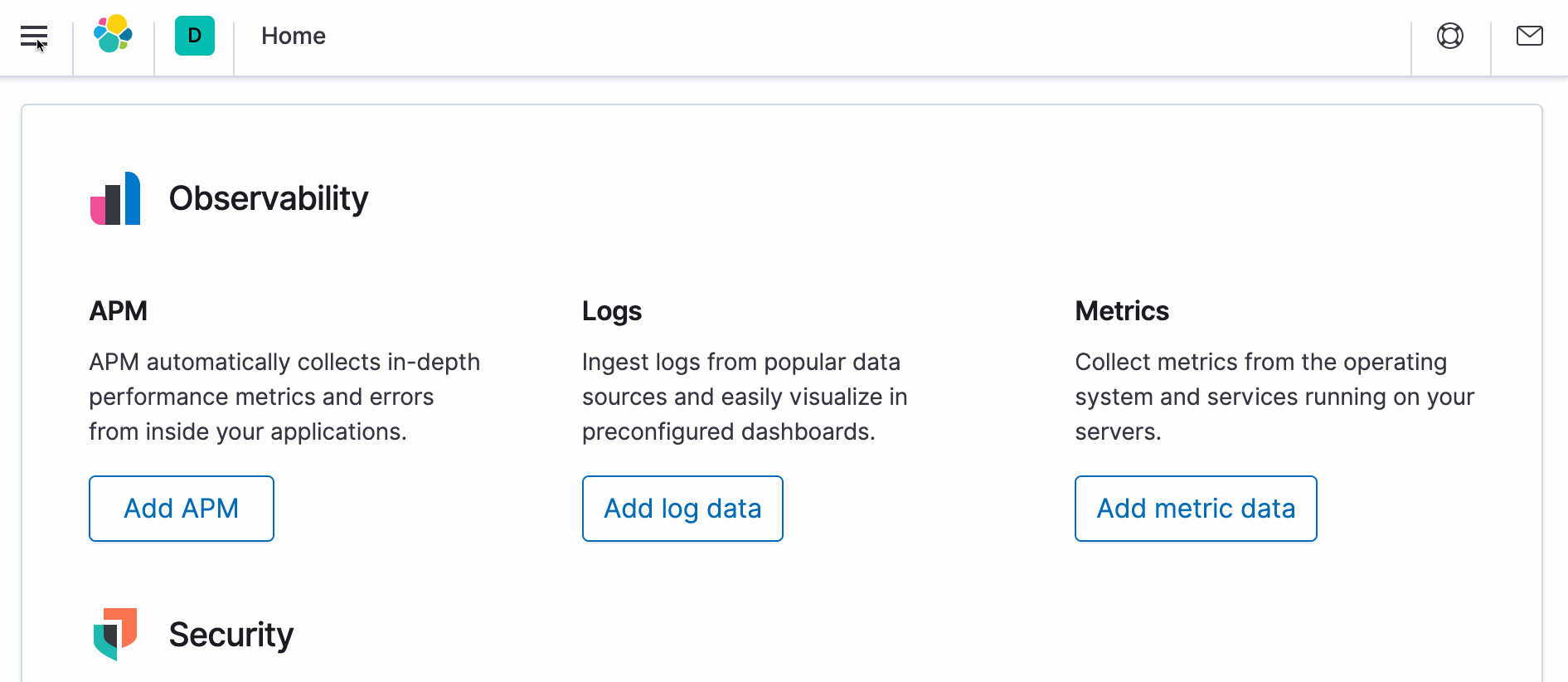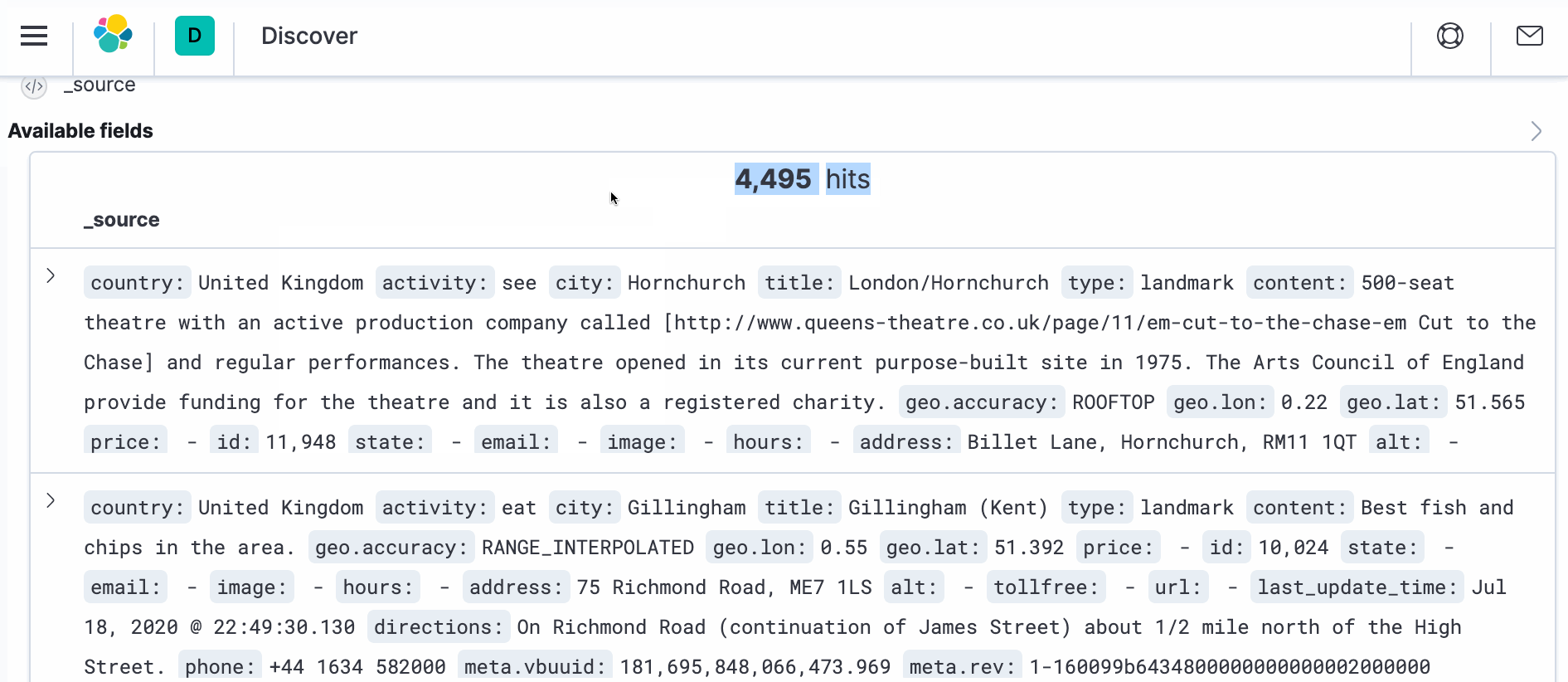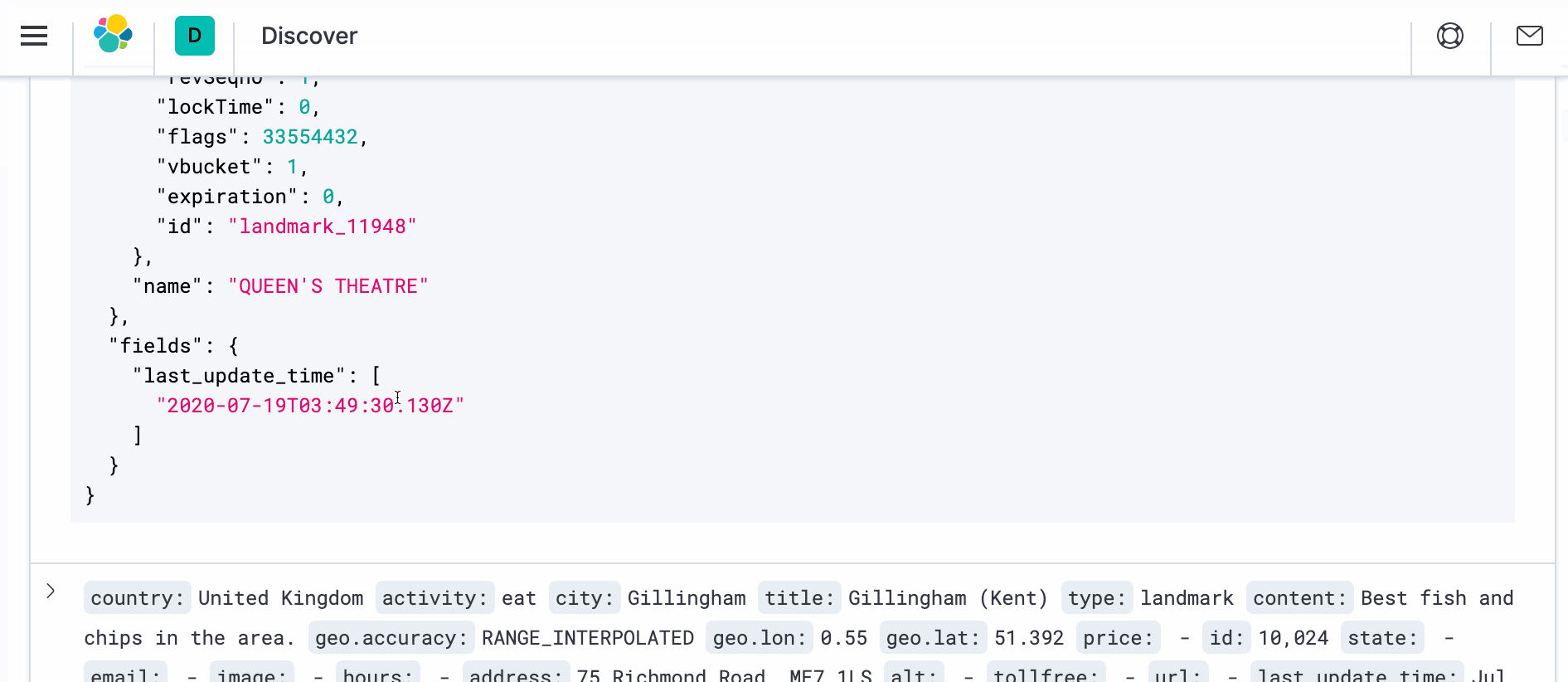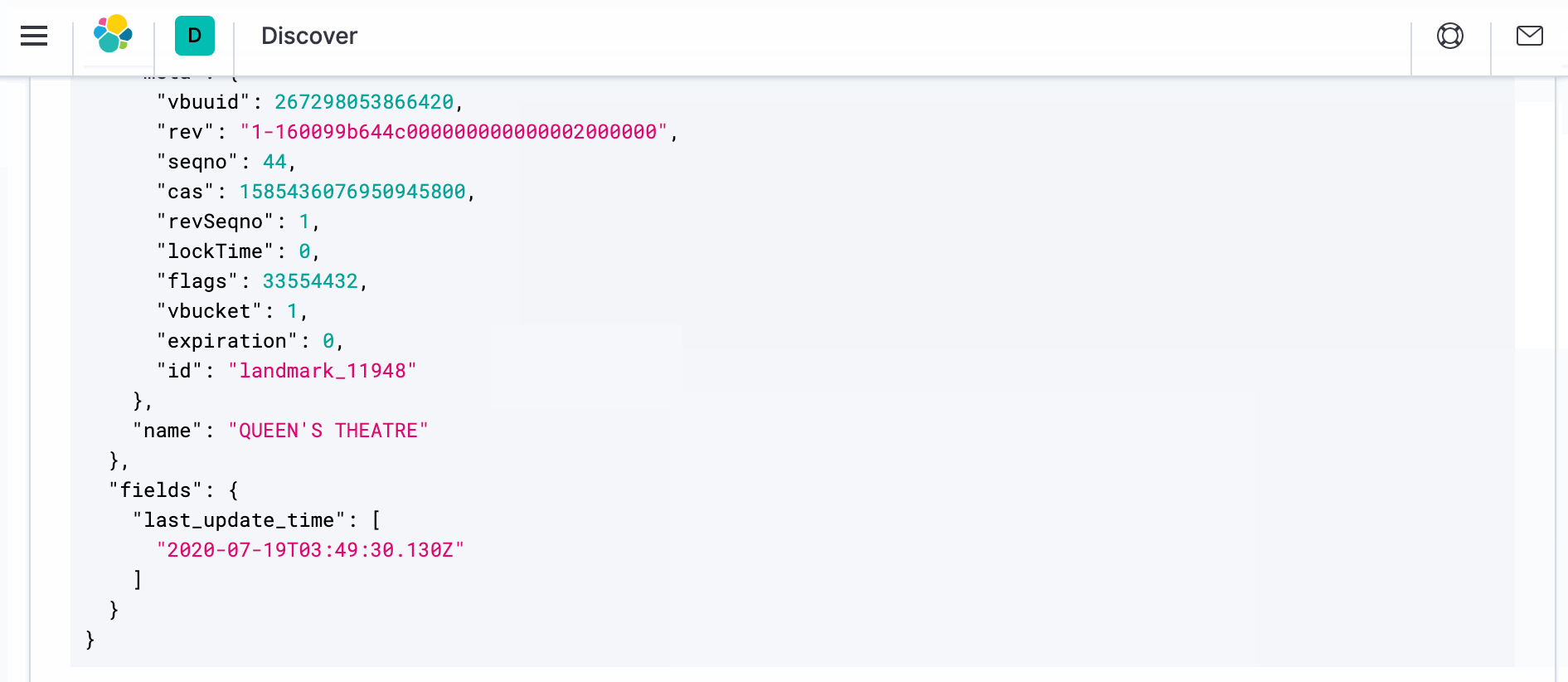
- Navegue até Descubra -> Padrões de índice e Defina um padrão de índice. Você deverá ver a opção landmark.
- Em seguida, navegue até Gerenciamento de índices em Descobrir -> Gerenciamento de índices. Ele deve mostrar a contagem de documentos desejada (4495).
- Para ver o documento real com a transformação, abra uma nova janela do navegador e navegue até o Kibana em https://localhost:5601. Navegue até Discover e, no lado direito, em _source, você deverá ver ">" símbolo. Clique nele e, em seguida, clique em JSON. Você deverá ver o documento como abaixo
-
-
Repetir
Se você quiser tentar o mesmo exemplo com o mesmo conjunto de dados, mas com um processador diferente, ou se tiver encontrado um erro e quiser começar tudo de novo, é muito simples. Tudo o que você precisa fazer é
-
-
-
Interromper o processo que está executando o Kibana (pressione control + C)
-
Exclua todos os dados do Elasticsearch iniciando um novo terminal e digite o seguinte comando
-
-
|
1 |
curl -X DELETE 'https://localhost:9200/_all' |
3. Interrompa o processo que está executando o conector do Elasticsearch (pressione control + C)
4. Cponto de verificação do conector lear, iniciando um novo terminal e digite o seguinte comando
|
1 |
cbes-checkpoint-clear |
5. Reinicie o Kibana, modifique o pipeline, modifique a configuração do conector conforme desejado e reinicie o conector.
Conclusão
Examinamos como usar o conector Couchbase Elasticsearch para replicar um conjunto de dados do Couchbase para o Elasticsearch em um modo solo usando um pipeline de nó de ingestão. Agora você está pronto para explorar diferentes processadores de pipeline e definições de configuração no conector Elasticsearch.
Finalmente, um "MUITO OBRIGADO" Aos meus colegas Matt Ingenthron, David Nault e Jared Casey por me ajudarem a chegar à linha de chegada deste blog!
Se você gostou deste post ou tem alguma dúvida, deixe seus comentários.