Esta é a Parte 2 de uma série focada em aproveitar os recursos arquitetônicos de alta disponibilidade e os recursos do Couchbase Server no Google Cloud Platform (GCP). Os conceitos do Couchbase discutidos aqui podem ser aplicados universalmente a qualquer ambiente de nuvem em que você implante seu cluster, mas as etapas e os comandos são específicos do GCP.
Parte 1 abordou como obter a resiliência do nó e do serviço do Couchbase (consulta, índice, dados, pesquisa, eventos, análise, backup). Mostramos como fazer isso alocando serviços a nós específicos espalhados por zonas de disponibilidade específicas do GCP em uma região. Você pode ler esse blog aqui.
Nesta postagem do blog, habilitamos Cruzamento Replicação de data center (XDCR) entre dois clusters do Couchbase em execução no GCP em duas regiões diferentes. Isso implementa o banco de dados Alta disponibilidade (HA)recuperação de desastres ou aplicação de dados de geolocalização. O XDCR não é novo no Couchbase e está disponível imediatamente em todos os clusters do Couchbase instalados. O XDCR pode ser usado entre quaisquer duas versões do Couchbase Server (desde a versão 2.5).
Os cinco cenários da prevenção de perda de dados
A arquitetura do Couchbase Server oferece resiliência de dados (por exemplo, prevenção de perda de dados) em vários níveis diferentes, desde o nível de mutação de dados individuais até o nível de cluster. Estes são cinco desses níveis em mais detalhes:
Gravação de níveis de falha e durabilidade
Dados Escrever para os buckets do Couchbase podem ser atribuídos requisitos de durabilidade. Por exemplo, o Couchbase pode ser instruído a atualizar o documento especificado em vários nós (em locais de memória e/ou disco em todo o cluster) antes de considerar a gravação a ser confirmada. Quanto maior for o número de locais de memória/disco especificados nos requisitos, maior será o nível de durabilidade alcançado. Você pode ler mais sobre a definição desses diferentes níveis em esta página de documentação do produto.
Falha e failover de nó
O Couchbase Dados, Índice e Pesquisa de texto completo permitem a criação de réplicas nos níveis de documento e índice para que, quando um nó que executa um desses serviços falhar, outra réplica possa ser usada. Por exemplo, as réplicas existentes que vivem nos nós ainda em execução para esses serviços tornam-se disponíveis para que seus aplicativos ainda possam funcionar plenamente. Você pode ler em detalhes sobre como a arquitetura subjacente do Couchbase oferece suporte a essa capacidade neste blog, Bancos de dados distribuídos: Uma visão geral.
Disponibilidade de nuvem e falhas de zona de rack
Alavancagem Dimensionamento multidimensional (MDS) e Conscientização do grupo de servidores protege seus aplicativos contra a perda de acesso aos dados devido a uma falha física rack ou nuvem zona de disponibilidade falha. A Parte 1 desta série do blog abordou como separar os serviços do Couchbase em nós independentes dentro de um cluster que está sendo executado em diferentes racks físicos em um data center ou em zonas de disponibilidade de provedores de nuvem.
Falhas na região da nuvem e no data center
A replicação é a chave para fornecer alta disponibilidade e tolerância a falhas no nível do cluster. O XDCR é uma tecnologia de replicação de memória para memória, de alto desempenho, usada para replicar dados entre dois clusters do Couchbase. Isso complementa a replicação intracluster por trás de nossa fragmentação automática de dados incorporada à arquitetura do Couchbase. O XDCR fornece replicação assíncrona e mantém a consistência dos dados entre os sites por meio da consistência eventual. Neste blog, mostraremos como implementar esse recurso entre dois clusters separados do Couchbase em diferentes regiões do GCP.
"Falha no "seu mundo
Backups de cluster! Às vezes, os clientes perguntam: "Por que preciso fazer backup se já tenho disponibilidade de 100%?" A melhor resposta para essa pergunta é outra pergunta: "O que você faria se dados corrompidos fossem introduzidos em seu cluster a partir de um sistema ou aplicativo upstream?" Essa é uma das poucas desvantagens da replicação de memória para memória: os dados corrompidos provavelmente infestarão outros clusters rapidamente, portanto, você precisará restaurar um backup pontual não corrompido. Esse cenário é muito raro e esperamos que nunca seja encontrado por nossos clientes, mas você deve avaliar suas práticas e programações atuais de backup do Couchbase, para garantir. No Couchbase 7, introduzimos o recurso Serviço de backup para facilitar ainda mais a automação de sua estratégia de backup e restauração. Você pode ler sobre isso aqui.
Cinco etapas para implementar a replicação entre datacenters (XDCR) com o Couchbase no GCP
Essas são as etapas de alto nível abordadas neste blog para implementar o XDCR entre clusters regionais do GCP Couchbase:
- Configurar 2 clusters separados do Couchbase em diferentes regiões da GCE
- Habilitar o amostra de viagem conjunto de dados no Cluster 1 que será a fonte de dados para uma replicação unidirecional
- Criar um bucket vazio no Cluster 2
- Criar um fluxo XDCR do Cluster 1 para o Cluster 2 para um cenário de HA ativa/passiva
- Crie um fluxo XDCR do Cluster 2 para o Cluster 1 para um cenário de HA ativo/ativo ou para impor a geolocalização dos dados
Etapa 1
Siga as instruções em Parte 1 para ativar dois clusters separados do Couchbase em diferentes regiões do GCP, como us-east1 e us-central1. Isso é semelhante à implantação do Couchbase em dois data centers diferentes em localizações geográficas diferentes para proteger seus ambientes contra falhas na infraestrutura de rede geográfica.
Etapa 2
Na interface do usuário do Couchbase para o GCP-WEST cluster, vá para o Configurações e clique na seção Baldes de amostra no canto superior direito da tela:
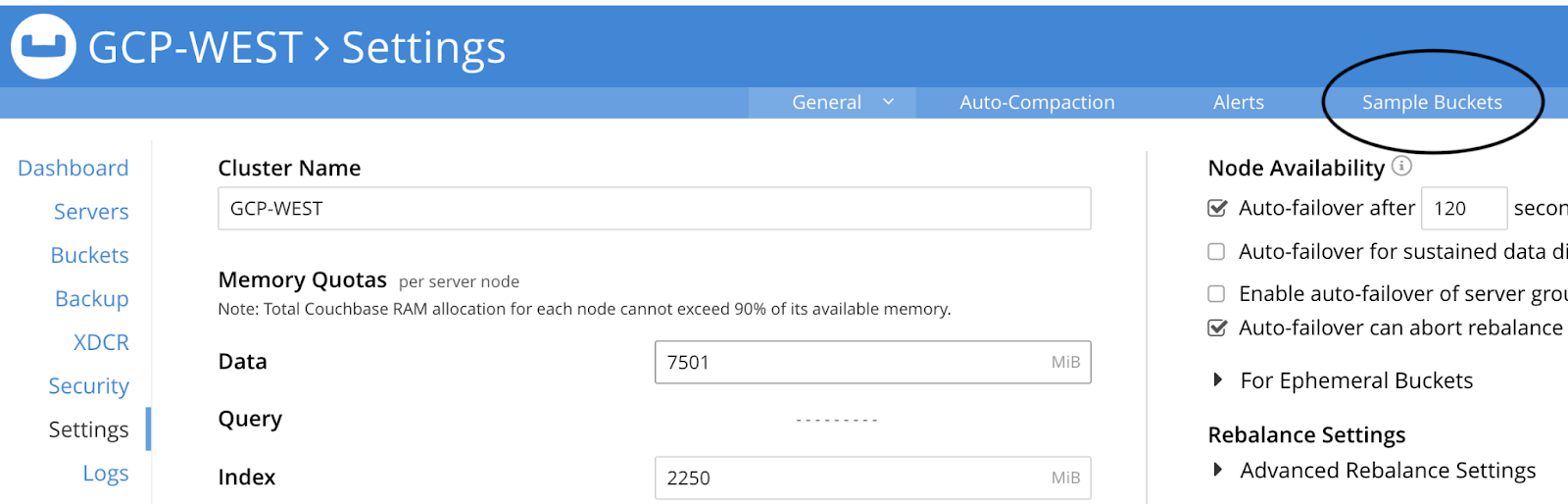
Em seguida, marque a caixa ao lado de amostra de viagem e clique em Carregar dados de amostra:
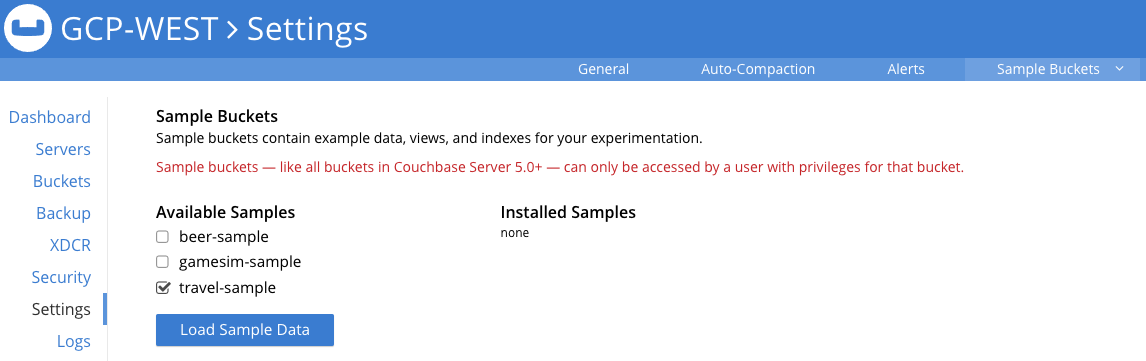
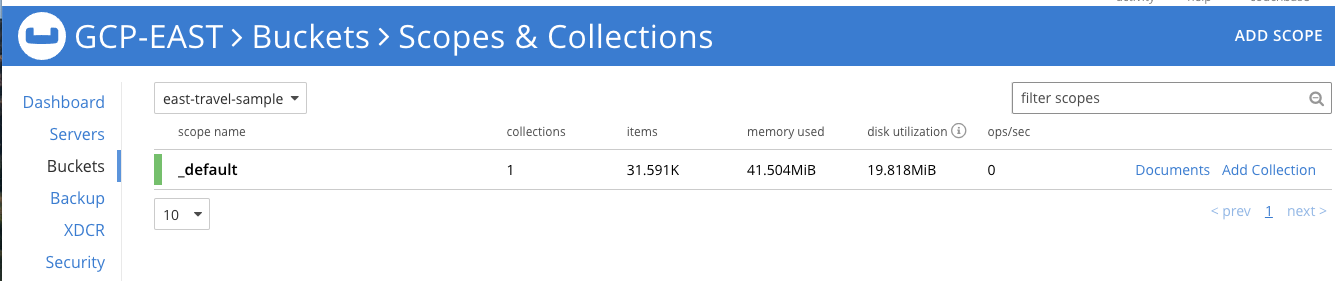
Aguarde alguns minutos para carregar o conjunto de dados e, em seguida, clique na seção Baldes na interface do usuário para ver o novo bucket chamado amostra de viagem. Todos os dados são carregados quando você vê a contagem de itens mostrada abaixo (versão 7.x):

Esse será o fonte para nosso fluxo XDCR entre o GCP Leste e Oeste clusters regionais. Antes de definirmos e habilitarmos um fluxo para replicar esses dados, precisamos criar um bucket vazio de destino no cluster de destino para receber os dados.
Etapa 3
No segundo cluster, GCP-EAST, na interface de usuário do administrador, vá para a seção Baldes e clique em ADICIONAR BALDE no canto superior direito:

Em seguida, você verá essa janela e poderá preencher os valores necessários para criar um bucket de destino vazio.
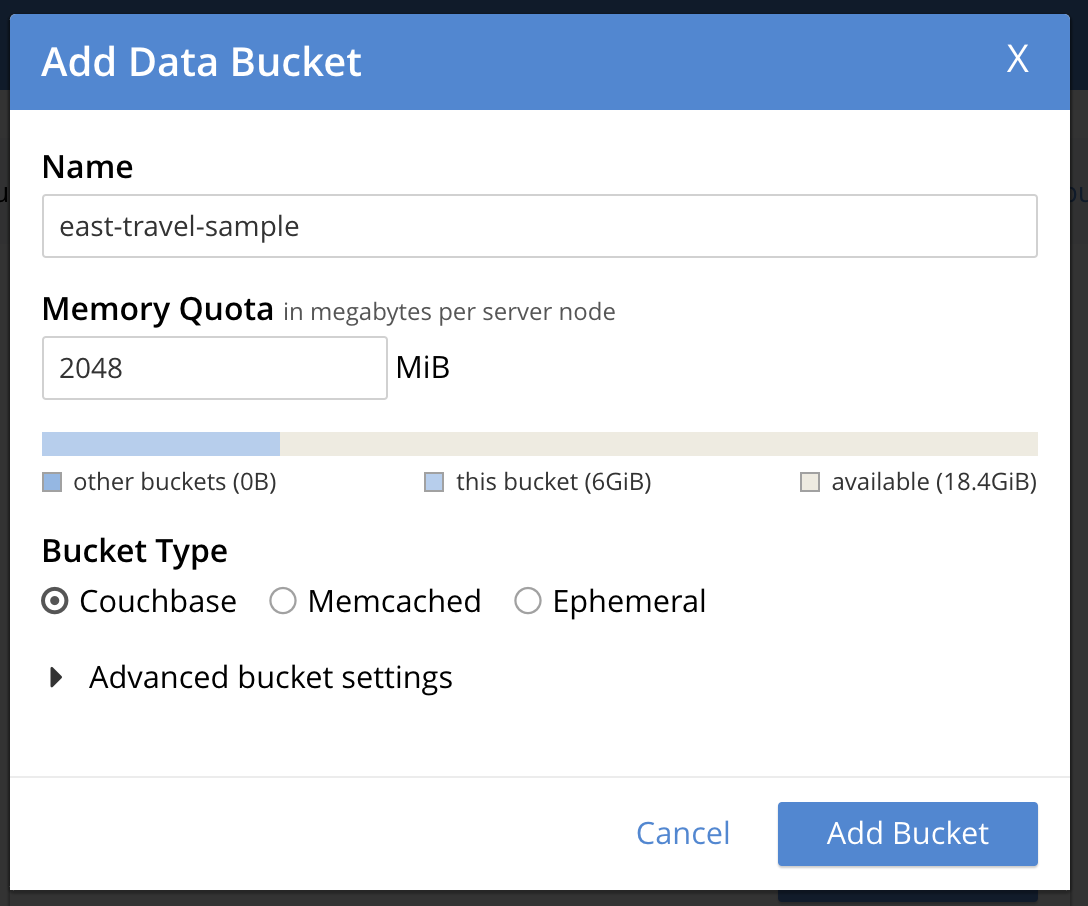
Quando você clicar em Adicionar balde você o verá listado imediatamente. Nomeei o bucket de forma diferente do bucket de origem para ajudar a saber de qual cluster são as capturas de tela. Na vida real, é provável que você queira nomeá-los da mesma forma para que os valores das cadeias de caracteres do seu aplicativo não precisem ser alterados caso você esteja alternando de um cluster para outro.

Etapa 4
Para implementar uma estratégia de cluster ativo/passivo, configuramos um fluxo XDCR unidirecional do nosso GCP-WEST agrupamento amostra de viagem balde para o nosso GCP-LESTE agrupamento amostra de viagem para o leste balde. Na interface de usuário do administrador para o GCP-WEST no cluster XDCR seção, clique em ADICIONAR REMOTO no canto superior direito. Isso abrirá outra janela pop-up.
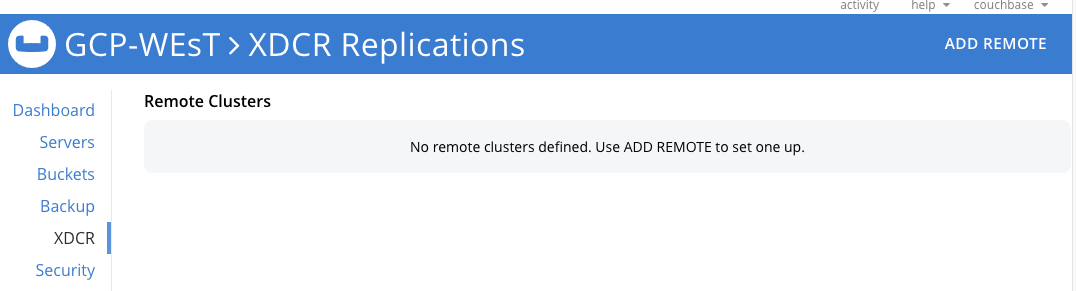
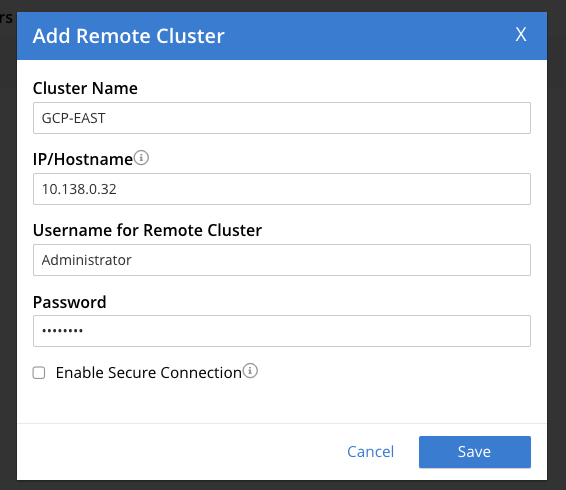
Clique em Salvar.
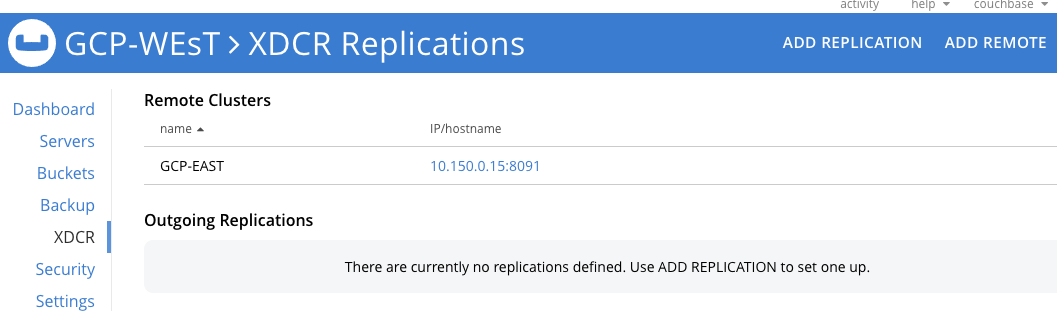
Agora, clique em ADICIONAR REPLICAÇÃO para chegar à tela onde podemos criar um fluxo unidirecional de GCP-WEST para GCP-LESTE.
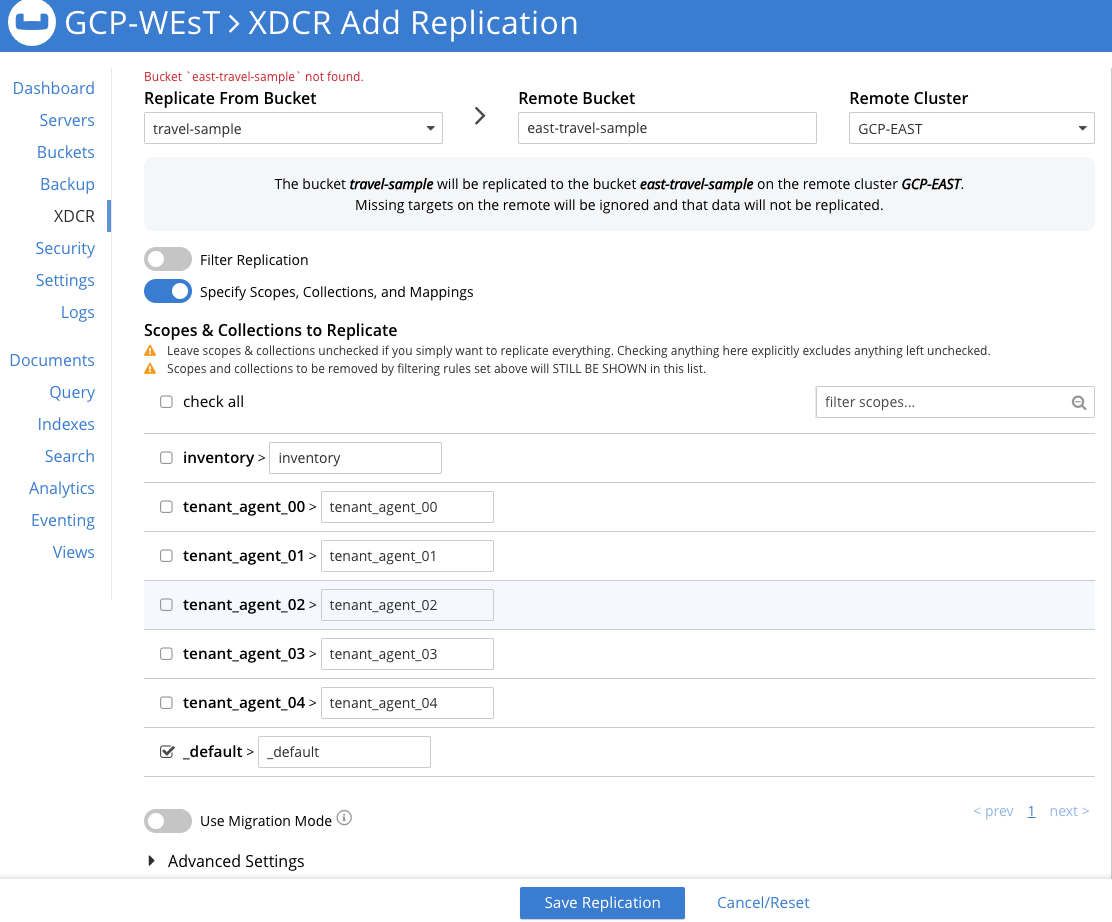
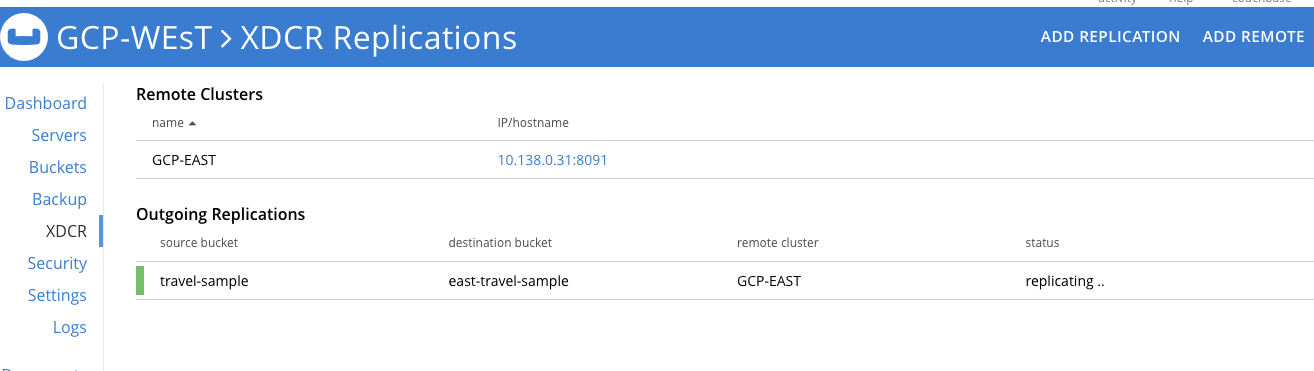
Depois de inserir todas as personalizações de seu fluxo, clique em Salvar replicação e o fluxo começará a mover os dados imediatamente para o GCP-LESTE e continuará à medida que as mutações ocorrerem no cluster amostra de viagem balde.
Optei por replicar apenas o padrão nesse fluxo para que você possa ver as diferentes opções disponíveis agora na versão 7 para dividir ou combinar escopos e coleções como parte de um fluxo de replicação. Você pode ler mais detalhadamente sobre essas opções nesta postagem: Apresentando o suporte XDCR para escopos e coleções no Couchbase 7.0.
Etapa 5
Se você quiser configurar uma estratégia de HA ativo-ativo para dois ou mais clusters do Couchbase, precisará criar um fluxo XDCR unilateral que vá do Cluster 1 para o Cluster 2 e, em seguida, um fluxo reverso paralelo do Cluster 2 para o Cluster 1 para o mesmo conjunto de dados. Por exemplo, conforme mostrado abaixo, configuramos um fluxo unilateral em cada cluster para que qualquer mutação que atinja um cluster seja replicada para o outro.
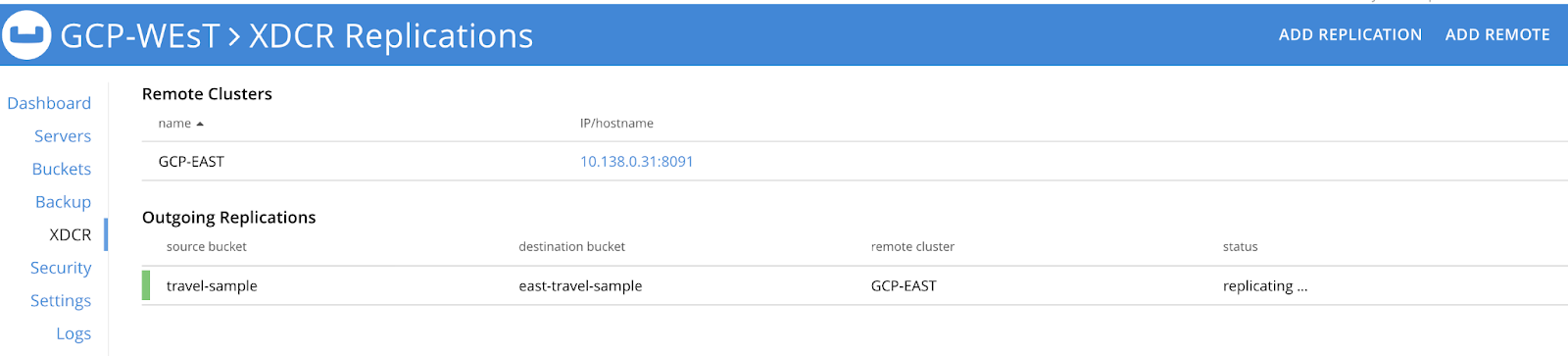
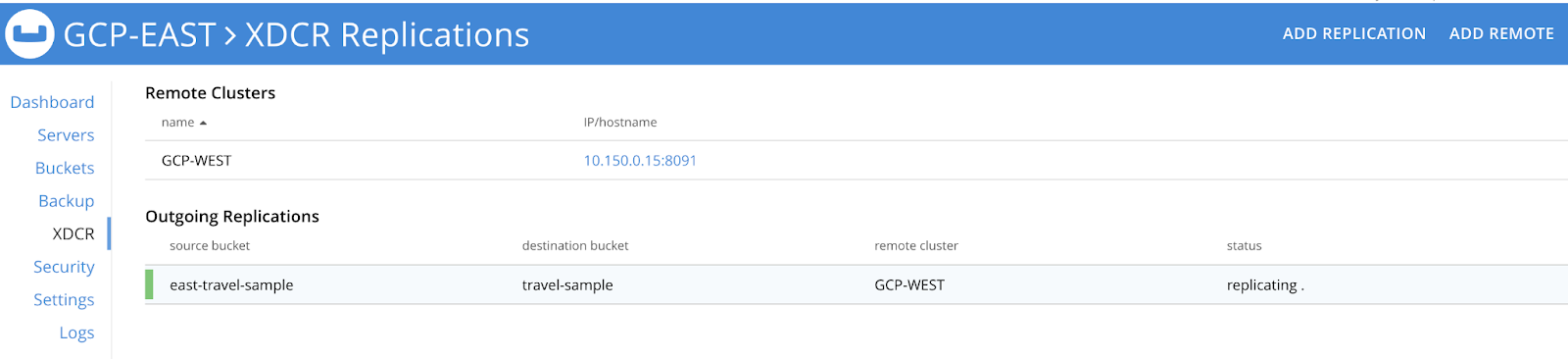
Se você quiser aplicar regras de filtragem para dar suporte a políticas de localidade de dados, leia sobre como implementar esses recursos aqui nesta página de documentação.
Conclusão
Você acabou de ver como pode usar o XDCR para implementar uma peça-chave da sua estratégia de HA do cluster do Couchbase, protegendo os aplicativos que usam o Couchbase de uma falha regional do data center ou da rede de nuvem.
Você pode saber mais sobre o XDCR nessas fontes:
- Entendendo a replicação entre data centers (XDCR) Parte 1
- XDCR: Replique em implementações de nuvem híbrida com facilidade e controle é de nossa Conferência de usuários do Couchbase Connect21O curso de XDCR, que abrange dicas e truques (incluindo novos recursos para escopos e coleções) para aproveitar ao máximo o XDCR no Couchbase Server versão 7, incluindo novos recursos incluídos para escopos e coleções.
Continue lendo estes recursos para começar a usar o Couchbase no GCP:
- Implementação do Couchbase para alta disponibilidade no Google Cloud Platform - Parte 1 - Conscientização do grupo de servidores
- Ofertas do Couchbase no GCP Marketplace
- Implantar o Couchbase Server usando o GCP Marketplace
- Práticas recomendadas para executar o Couchbase no Google Compute Engine
