Desbloqueie o raciocínio avançado com um TCO menor para IA empresarial
Hoje, temos o prazer de compartilhar que o DeepSeek-R1 agora está integrado ao Capella AI Services, disponível em versão prévia! Esse poderoso modelo destilado, baseado no Llama 8B, aprimora sua capacidade de criar aplicativos agênticos com raciocínio avançado e, ao mesmo tempo, garante a conformidade com a privacidade.
Neste blog, demonstraremos como aproveitar esses modelos criando um chatbot para aprimorar a pesquisa empresarial e o gerenciamento de conhecimento. Com as poderosas habilidades de inferência do DeepSeek, as organizações podem melhorar:
-
- Análise jurídica e de conformidade
- Automação do suporte ao cliente
- Solução de problemas técnicos
Para esta demonstração, estamos usando DeepSeek Distill-Llama-3-8Bmas a Capella AI Services no GA planeja introduzir variantes de parâmetros mais altos do modelo para expandir ainda mais seus recursos.
🚀 Interessado em testar o DeepSeek-R1? Confira Serviços de IA da Capella ou Inscreva-se no Prévia privada.
Entendendo o modelo do DeepSeek
Abordagem de destilação
DeepSeek Distill-Llama-3-8B é treinado usando destilação de conhecimento, onde a modelo de professor maior (DeepSeek-R1) orienta o treinamento de um modelo de aluno menor e mais eficiente (Llama 3 8B). Isso resulta em um modelo compacto e potente que mantém recursos sólidos de raciocínio e, ao mesmo tempo, reduz os custos computacionais.
Conjunto de dados: benchmarking com o BEIR
Estamos avaliando os recursos de raciocínio do modelo usando o Conjunto de dados BEIRum padrão de referência do setor para raciocínio baseado em recuperação. O conjunto de dados consiste em 75K documentos em vários domínios, estruturados da seguinte forma:
|
1 2 3 4 5 6 |
{ "_id": "632589828c8b9fca2c3a59e97451fde8fa7d188d", "title": "A hybrid of genetic algorithm and particle swarm optimization for recurrent network design", "text": "An evolutionary recurrent network which automates the design of recurrent neural/fuzzy networks using a new evolutionary learning algorithm is proposed in this paper...", "query": "what is gappso?" } |
A capacidade do modelo é testada determinando-se quais documentos contêm as respostas corretas para consultas específicasdemonstrando sua força de raciocínio.
Primeiros passos: implementando o DeepSeek no Capella AI Services
Etapa 1: ingestão dos documentos
Agora você pode gerar embeddings de vetores para documentos estruturados e não estruturados usando os serviços de IA da Capella. Primeiro, vamos importar os documentos estruturados do conjunto de dados BEIR para uma coleção couchbase antes de implantar um fluxo de trabalho de vetorização.
Configure um cluster de banco de dados operacional de 5 nós (ou maior!) no Couchbase Capella com as funções de pesquisa e eventos ativadas. Você pode aproveitar uma opção de implementação de vários nós pré-configurada ou criar uma configuração personalizada.

Depois que o cluster for implantado, vá para o diretório Importação na guia Ferramentas de dados e clique na opção de importação. Para grandes conjuntos de dados, você pode usar a opção cb-importação função.
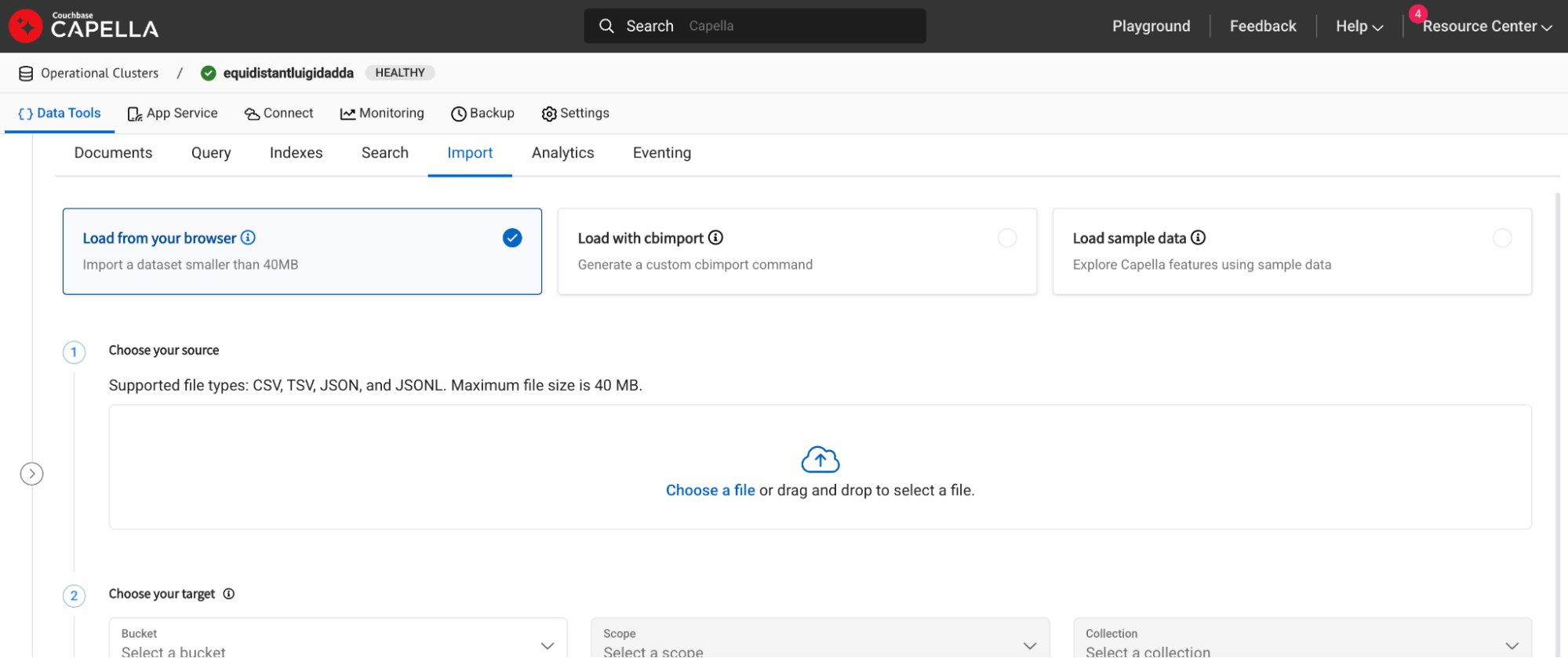

Etapa 2: Configurar um modelo de incorporação
Volte para a guia de modelos na guia de serviços do Capella AI. Clique no ícone Serviço de modelo antes de selecionar as opções a seguir:
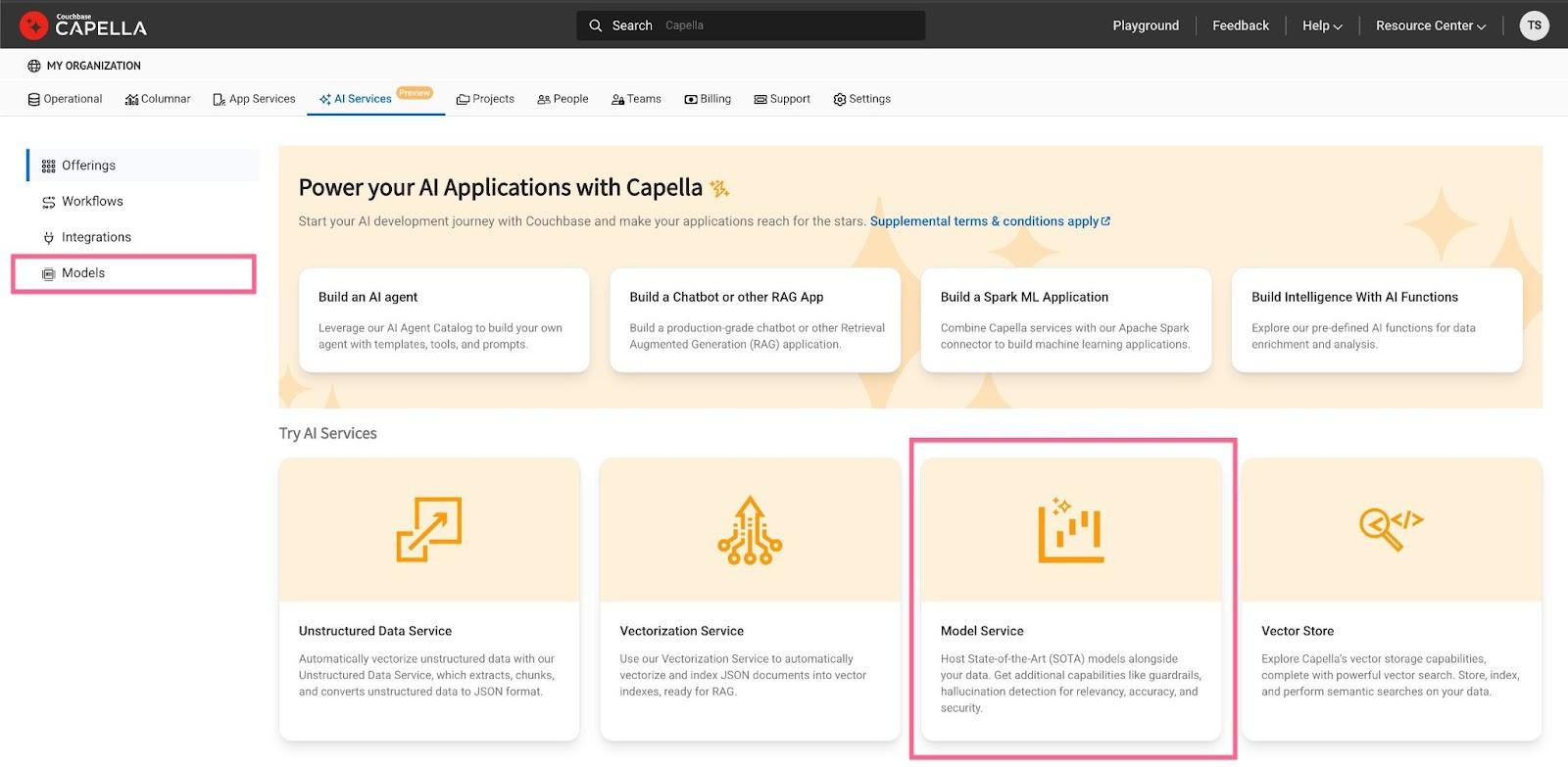

Etapa 3: Configurar um fluxo de trabalho de vetorização
Agora que os documentos foram ingeridos, consulte esta postagem para obter detalhes sobre como implantar um fluxo de trabalho de vetorização.
Dê um nome ao seu fluxo de trabalho e especifique a coleção que contém os documentos ingeridos.

Selecione o modelo de incorporação implantado na etapa anterior.
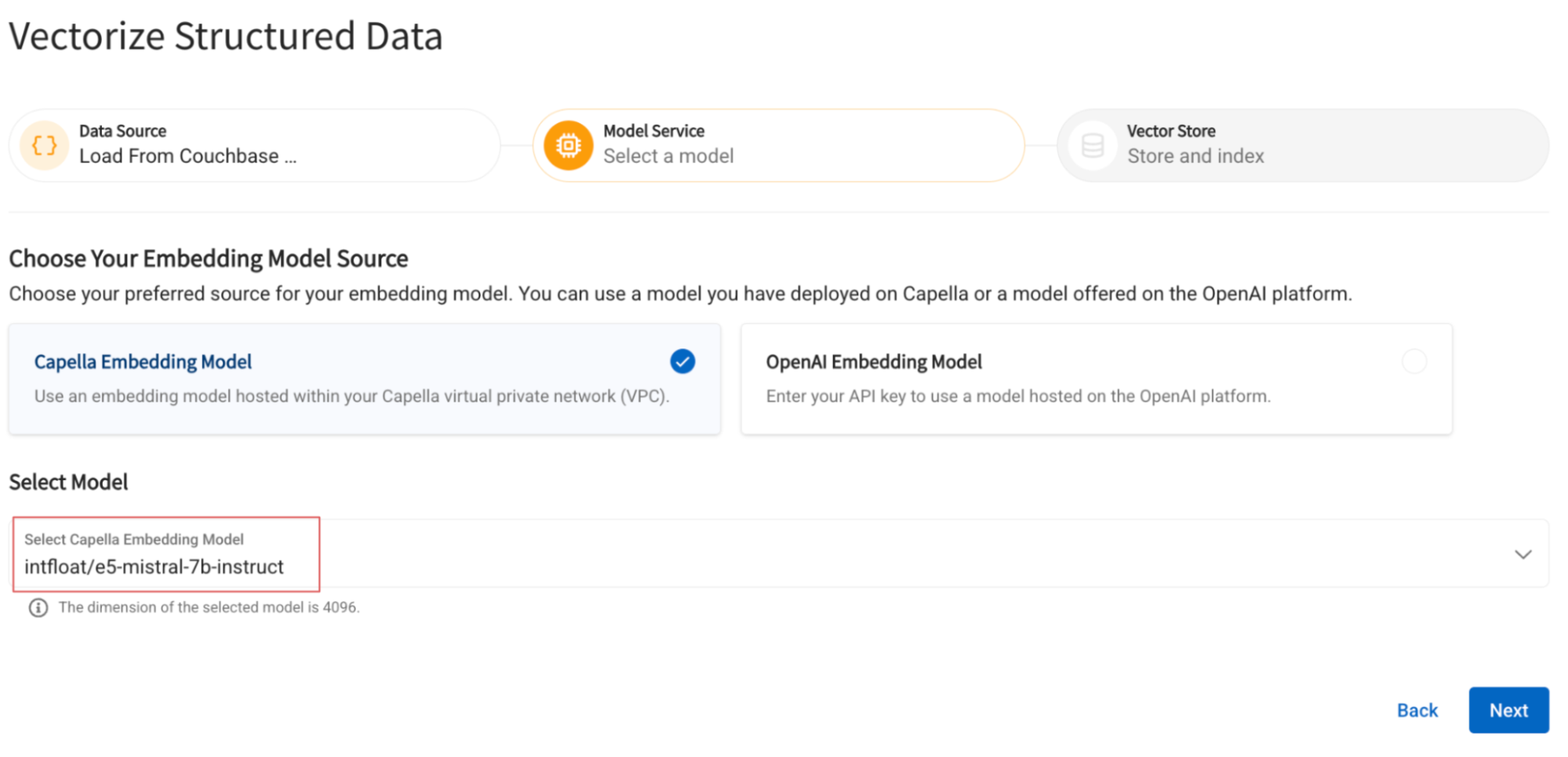
Especifique o nome do campo no qual os vetores gerados serão inseridos e o nome do índice a ser construído sobre ele:
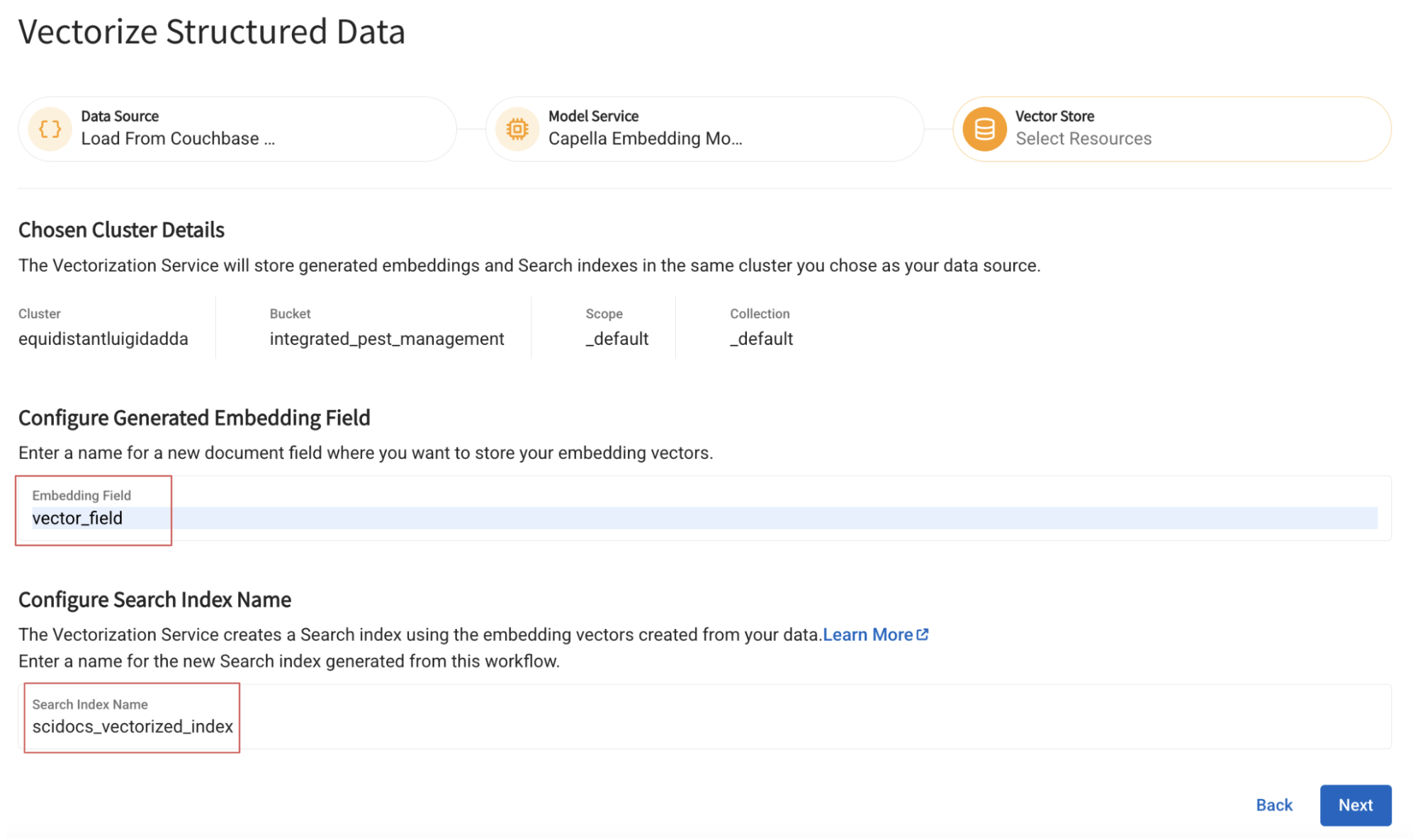
Etapa 4: Configure o modelo DeepSeek
Volte para a seção de serviços de IA da Capella, clique na guia modelos e clique no botão Serviço de modelo antes de selecionar as opções a seguir:
Selecione o cluster de banco de dados operacional criado anteriormente no menu suspenso, selecione o Capella Pequeno e o DeepSeek Distill-LLama-3-8B na lista suspensa de modelos.

Configure o cache selecionando um bucket-scope-collection e verificando a opção Cache de conversação caixa.

Criação de um aplicativo com o DeepSeek
Etapa 1: Defina as configurações para que o aplicativo acesse os dados
Certifique-se de que seu endereço IP esteja na lista de permissões para acessar os documentos em seu banco de dados operacional. Você pode fazer isso navegando até a seção Conectar do cluster operacional que foi criado anteriormente.

Etapa 2: Execute o aplicativo
Use o exemplo fornecido aqui para configurar um aplicativo que recupera os documentos do conjunto de dados BEIR armazenados em seu banco de dados operacional e, em seguida, gera uma resposta. Certifique-se de especificar corretamente suas credenciais de banco de dados codificadas em base64 e o ponto de extremidade do modelo. Você pode encontrar o ponto de extremidade do modelo navegando até a pasta Serviços de IA -> Modelos e, em seguida, clicando no botão de seta para baixo, que revelará as configurações do modelo.
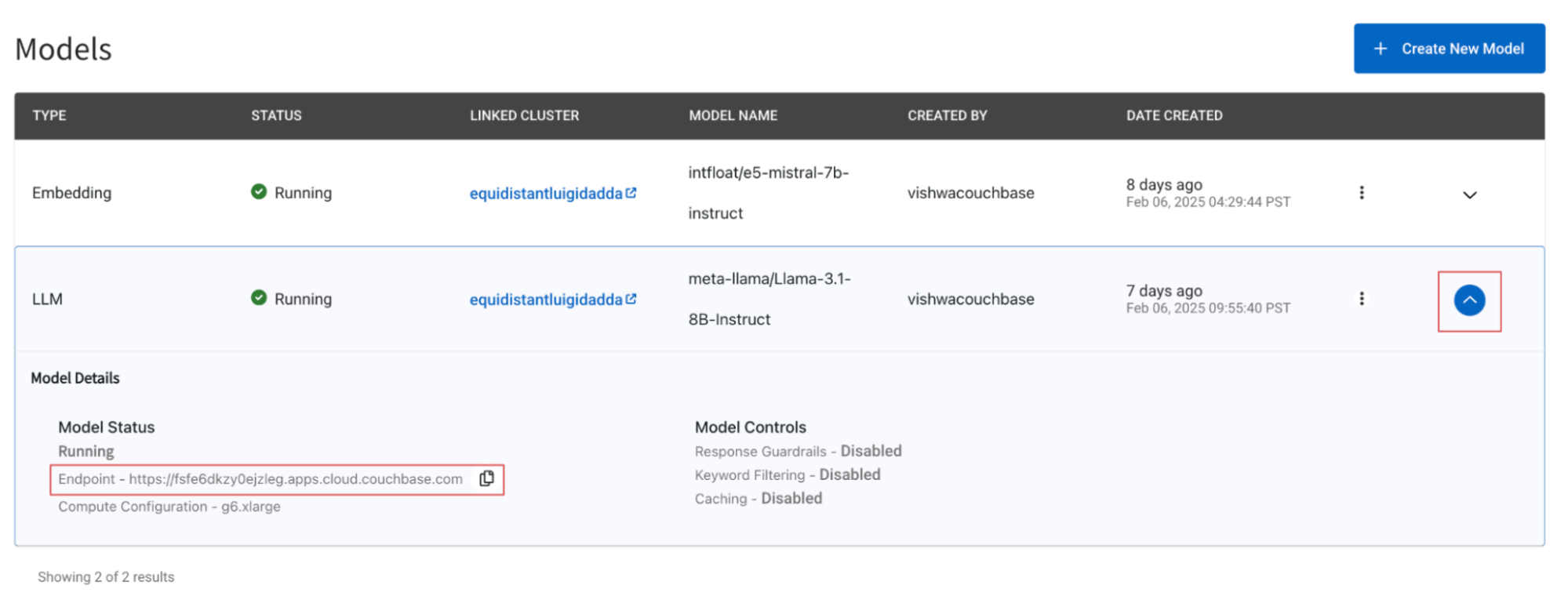
Etapa 3: Teste o DeepSeek-R1-Distill-Llama-8B
Envie uma consulta de exemplo para o modelo e verifique os resultados. Depois de verificar a resposta do modelo, você pode executar todo o conjunto de dados por meio do modelo.
Próximas etapas
-
- 🚀 Obtenha acesso antecipado ao DeepSeek-R1 - Participe da lista de espera
- 📖 Leia mais sobre os modelos do DeepSeek - Documento de pesquisa do DeepSeek
- 🔗 Explore o conjunto de dados BEIR - Repositório Oficial do BEIR
O Capella AI Services está aqui para ajudá-lo a criar aplicativos alimentados por IA com os melhores modelos da categoria. Vamos inovar juntos!
