Este artigo apresenta as estruturas de dados e como elas funcionam com os recursos de escopos e coleções do Couchbase Server 7.0.
O que são estruturas de dados?
O Couchbase Data Structures é um recurso de API que alinha a linguagem da interface do banco de dados com uma linguagem de programação.
As estruturas de dados ajudam a simplificar os modelos de dados para os desenvolvedores de sistemas NoSQL. Elas são unidades básicas de gerenciamento de dados para armazenar e recuperar dados de forma rápida e eficiente. Os bancos de dados de documentos e outros bancos de dados de valores-chave geralmente oferecem suporte à indexação desses dados para casos de uso de consulta.
Simplificando o desenvolvimento de aplicativos NoSQL
A interação com documentos JSON completos não é necessária. Se tudo o que o desenvolvedor de software precisa, por exemplo, é de um único item em uma lista. Após autenticar a conexão com o banco de dados, uma simples função get ou set deve ser tudo o que é necessário.
Uma série de funções de estrutura de dados fornece acesso a esses objetos de programação nativos:
- Documentos - suporte completo a documentos hierárquicos JSON
- Subdocumentos - subconjuntos de objetos em um documento
- Contadores - um único número inteiro de incremento
- Maps - mapeamentos de dicionário de valores-chave
- Listas/coleções - listas de itens indexadas e ordenadas
- Conjuntos - conjuntos de valores exclusivos de itens da lista
- Filas - acesso primeiro a entrar, primeiro a sair aos itens da lista
Métodos de acesso direto aos dados
O Couchbase gerencia seus dados como documentos JSON flexíveis que podem ser expostos como partes atômicas de dados por meio de funções simples. Por exemplo, você pode fgravar um subcomponente do documento, criar um item numerado em uma lista ou adicionar em uma lista ordenada. Os documentos de dados podem ser chamados diretamente por seus nomes de ID depois de serem persistidos e distribuídos para o cluster.
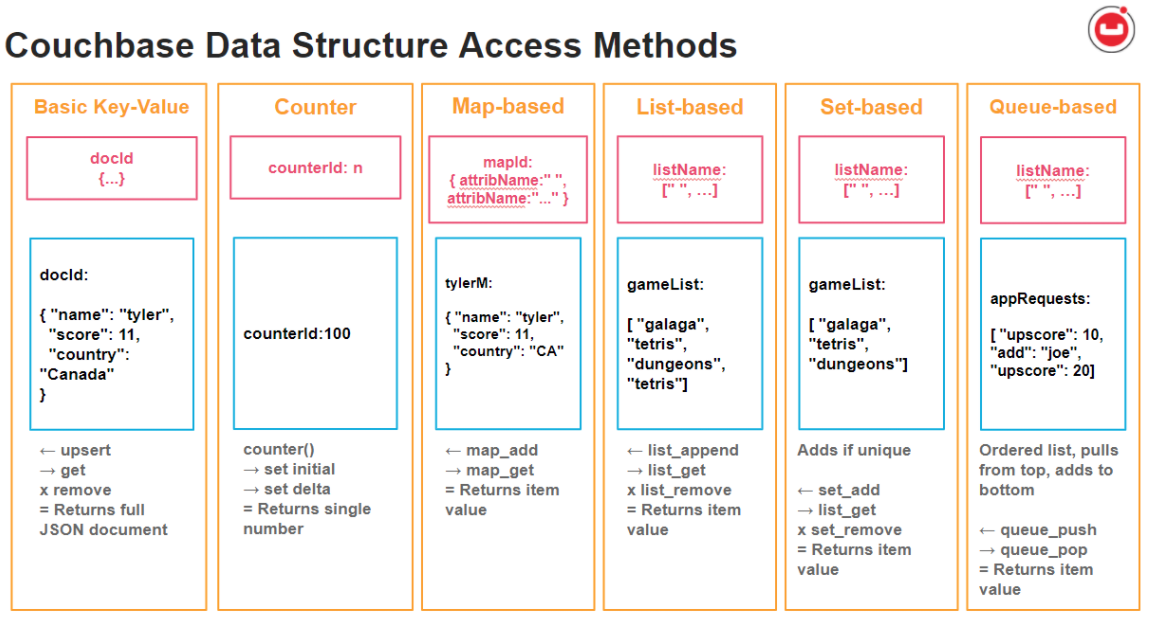
Resumo dos tipos de estrutura de dados do Couchbase e amostras de JSON.
Python são usados para mostrar o uso básico desses tipos de estrutura de dados, embora todas as linguagens do SDK sejam compatíveis. Consulte o exemplo de código completo no final desta postagem para ver o código do preâmbulo, as importações etc.
Acesso a valores-chave
Geral Operações de KV incluir obter e definir/upsert funções. Os documentos compatíveis com JSON são salvos ou atualizados com um ID de documento específico.
|
1 2 3 |
>>> db.upsert("docId", { "name": "tyler", "score": 11, "country": "CA" }) >>> sb.get("docId").content '{ "name": "tyler", "score": 11, "country": "CA"}' |
Contadores
Ainda mais simples é um nomeado contador objeto que armazena um valor inteiro único. Quando o item é chamado, um valor inicial é definido e, em seguida, incrementado. Esse método simples é perfeito para um número de incremento global em todos os aplicativos.
|
1 2 3 4 5 |
>>> db.counter("currentScore",delta=1,initial=0).value # Creates at 0 0 >>> db.counter("currentScore").value # Adds 1 1 |
Acesso baseado em mapas
Os mapas (também conhecidos como dicionários) atribuem uma chave de objeto a um valor. O valor de a entrada do mapa pode ser qualquer objeto compatível com JSON. É possível criar uma nova combinação de mapa e valor em uma única chamada e salvá-la em seu próprio documento.
Por exemplo, um mapa de perfil de usuário pode ter o ID de um nome de usuário. Esse perfil de usuário também pode ter vários mapeamentos com nomes exclusivos dentro dela como nome ou endereço. Cada um pode ser gerenciado independentemente dos outros.
|
1 2 3 |
>>> db.map_add("tylerM","name","Tyler", create=True) >>> db.map_add("tylerM","country","Canada") |
Nesse caso, a ID do mapa também pode ser acessada por meio da função básica de obtenção do KV.
|
1 2 3 |
>>> db.get("tylerM").content {'name': 'Tyler', 'country': 'Canada'} |
Há também funções específicas do mapa para verificar se ele existe e remover ou buscar itens.
Acesso baseado em listas
Outros Objetos e valores JSON podem ser armazenados em uma estrutura de lista simples sem a necessidade de usar JSON. As funções de lista adicionam itens a uma lista e permitem que você os retire usando um número de índice.
Você fornece um ID de lista e o novo valor em uma única etapa. A remoção ou recuperação requer o ID da lista e o número de índice do item. A lista completa também pode ser acessada com o KV obter função.
|
1 2 3 4 5 6 7 8 9 10 11 |
>>> db.list_append("gameList","galaga",create=True) >>> db.list_append("gameList","tetris") >>> db.list_append("gameList","dungeons") >>> db.list_get("gameList",0) 'galaga' >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'tetris'] |
Observe que valores de itens duplicados na lista são aceitáveis e um list_prepend também está disponível.
Acesso baseado em conjuntos
Estruturas de dados de "conjunto" facilitam o gerenciamento de valores exclusivos em uma lista. Novos valores são adicionados somente se ainda não existirem. Isso reduz a necessidade de recuperar e comparar valores com a lista existente; em vez disso, isso é feito em uma única chamada.
|
1 2 3 4 |
>>> db.set_add("gameList","tetris") # Trying to add tetris twice is ignored >>> db.get("gameList").content ['galaga', 'tetris', 'dungeons', 'horizon'] |
Acesso baseado em filas
Estruturas de dados de filas são outro tipo de lista que mantém os itens em uma ordem específica. Um aplicativo pode facilmente adicionar um novo item, que vai para o final da lista. Um item da lista pode então ser retirado do topo da lista e, posteriormente, removido da lista.
Você pode entender por que elas são chamadas de filas - por exemplo, algum tipo de programa de gerenciamento de trabalho pode estar processando solicitações, pois elas podem ser "enfileiradas" em uma lista e precisam operar em um cenário FIFO (first-in-first-out, primeiro a entrar, primeiro a sair), como um aplicativo chama.
Cada valor pode ser qualquer objeto JSON, portanto, eles podem incluir outro mapa, lista etc.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
>>> db.queue_push("appRequests",{"updatescore":10},create=True) >>> db.queue_push("appRequests",{"adduser":"joe"}) >>> db.queue_push("appRequests",{"updatescore":20}) >>> db.get("appRequests").content [{'updatescore': 20}, {'adduser': 'joe'}, {'updatescore': 10}] >>> db.queue_pop("appRequests") # Value is returned as it is removed from list {'updatescore': 10} >>> db.get("appRequests").content # First value is now removed [{'updatescore': 20}, {'adduser': 'joe'}] |
Talvez você queira usar conjuntos ou filas por conveniência em alguns casos, mas sempre poderá voltar e usar funções de lista ou KV para adicionar/remover e gerenciar mais diretamente com seu código, conforme necessário.
One Step Deeper - Subdocumentos
O que fazer quando se deseja consultar um subobjeto específico em um documento JSON hierárquico mais profundo? As funções map e list não podem extrair de subitens em uma única chamada de documento. É possível, é claro, solicitar o documento inteiro e processá-lo em seu aplicativo, mas isso seria desnecessariamente ineficiente.
O SDK do Couchbase fornece um subdocumento API para fazendo solicitações únicas de atualização/obtenção de valores em níveis mais profundos.
Por exemplo, um perfil do usuário pode ter um endereço mapeamento com subitens para rua, cidadee país. Eles não podem ser acessados com as funções normais de mapa, mas podem ser usados com a API de subdocumento.
Há várias funções potentes de subdocumento, mas apenas um exemplo de recuperação rápida é mostrado aqui usando a função lookup_in função.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
>>> import couchbase.subdocument as SD >>> db.map_add("tylerM","contact", {"address":{"country":"Canada","city":"Vancouver"}}) >>> country = db.lookup_in("tylerM",[SD.get("contact.address")]) >>> country.content_as[str](0) "{'country': 'Canada', 'city': 'Vancouver'}" >>> country = db.lookup_in("tylerM",[SD.get("contact.address.country")]) >>> country.content_as[str](0) 'Canada' |
Uso de escopos e coleções com estruturas de dados
A introdução de Escopos e coleções em Couchbase 7.0 permite níveis mais refinados de controle sobre todos os aspectos do gerenciamento de documentos. Os escopos são um subconjunto de todos os documentos no bucket e as coleções são um subconjunto de um escopo.
Para obter mais informações sobre esses tópicos em geral, consulte o blog Apresentando as coleções - Developer Preview no Couchbase Server 6.5.
O escopo e as coleções já devem existir - crie novos escopos usando as ferramentas na página de definição de bucket do console da Web.
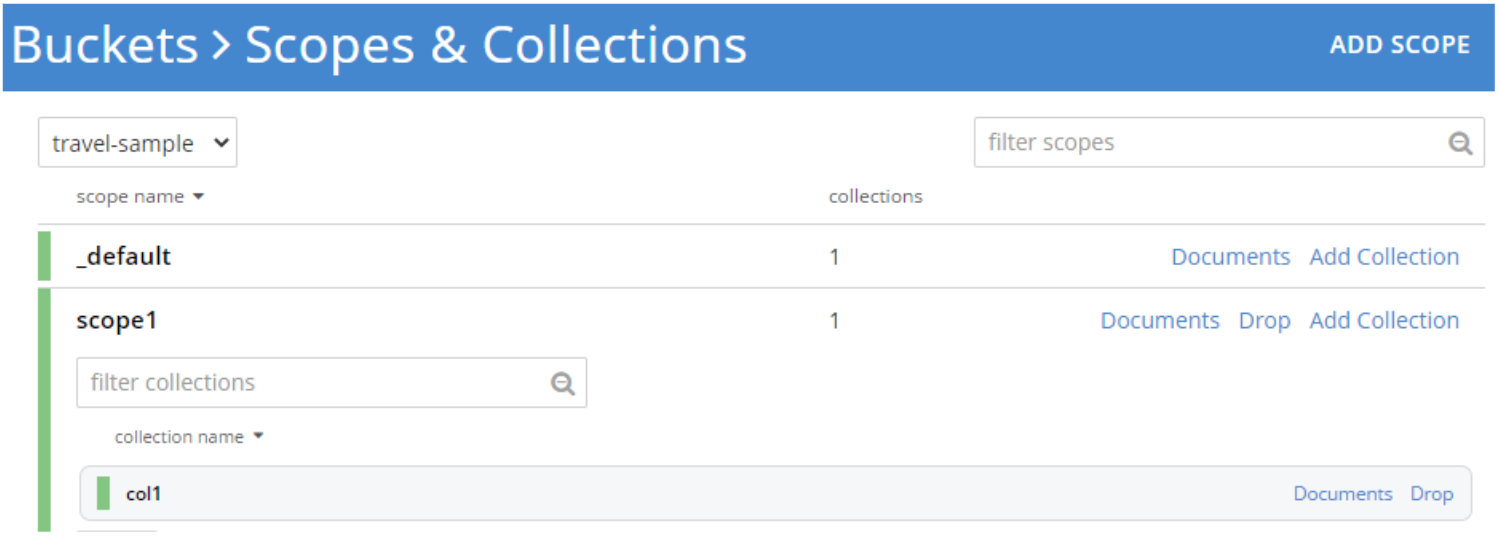
Os exemplos de código acima usaram um escopo padrão em vez de um escopo ou coleção específica. As conexões em nível de bucket definem os escopos/coleções a serem usados. Um link para um exemplo de código completo e comentado para escopos está incluído no final deste artigo. Aqui está um exemplo de especificação desses parâmetros:
|
1 |
dbscoped = cluster.bucket('travel-sample').scope('scope1').collection('col1') |
Em vez de selecionar a opção "default_collection" para o bucket, o código usa um escopo e uma coleção específicos. Em vez de usar a opção db use o objeto dbscoped para operações de dados.
|
1 2 3 |
dbscoped.list_append("newlist",1,create=True) dbscoped.list_append("newlist",2) |
Revise a página de documentos no console da Web e filtre por nomes de coleções para confirmar qual delas você está usando:
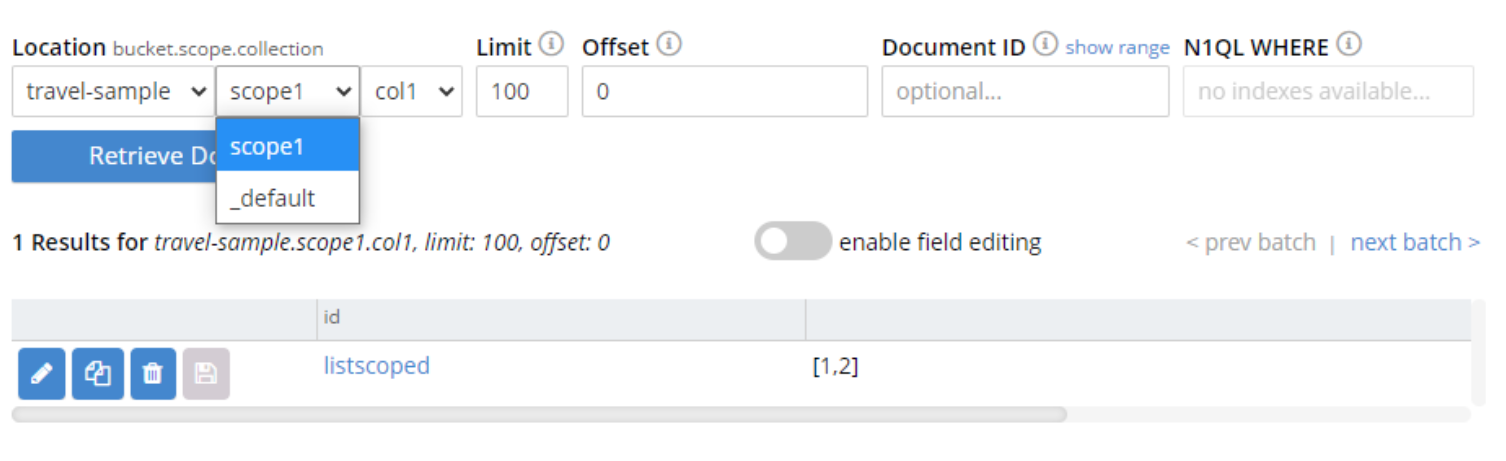
OBSERVAÇÃO: no momento em que este artigo foi escrito, a API Python para contadores não suportava o uso de escopos.
Estruturas de dados de indexação para SQL eficiente ou pesquisa de texto completo
O Couchbase é muito mais do que gerenciar estruturas de dados brutas por meio do mecanismo Key-value (KV) ou estruturas de dados JSON. Muitos aplicativos, especialmente os aplicativos NoSQL móveis e da Web voltados para o cliente, precisam de mais sofisticação para se integrar a outros aplicativos.
O Couchbase faz isso usando indexação de dados NoSQL e serviços de consulta baseados em SQL, bem como pesquisa de texto completo.
O que é indexação de banco de dados? Isso significa examinar partes dos dados e entender como encontrar esses elementos novamente nos documentos. A pesquisa ocorre por meio de uma consulta do tipo SQL ou de uma solicitação de pesquisa de texto completo.
Abordaremos esses dois cenários em postagens subsequentes com foco na indexação de coleções nativas em estruturas de dados do Couchbase.
Enquanto isso, veja esta postagem que aborda a indexação: Práticas recomendadas de indexação de banco de dados NoSQL.
Reunindo tudo isso
Como você pode ver, criar documentos, contadores e subcomponentes relacionados é muito simples, usando o Couchbase. Da mesma forma, com o uso estratégico de índices, há ainda mais maneiras de acessar o banco de dados.
As consultas N1QL e a pesquisa de texto completo são métodos comuns que também fazem uso de matrizes JSON básicas, strings etc. quando mapeadas corretamente.
Como o Couchbase é uma plataforma completa, a arquitetura do seu sistema pode ser bastante simplificada. Os desenvolvedores podem começar a trabalhar imediatamente, sem muito trabalho pesado ou gerenciamento de banco de dados.
- Faça o download do exemplo completo de código Python aqui
- Estruturas de dados Documentos da API: Java, .NET, Node.js, Ir, PHP, Python, C, Rubi, Scala
- Operações de subdocumentos docs (Python SDK)