Com a introdução do pesquisa vetorialos usuários agora podem armazenar matrizes de vetores grandes-(muitas vezes compostos por números aparentemente arbitrários) em seus documentos. Como esses dados não são necessários para a maioria das consultas padrão, os usuários agora podem aproveitar atributos estendidos (XATTRs), que fazem parte dos metadados do documento, para armazenar vetores e outros conteúdos volumosos. Ao fazer isso, o desempenho é aprimorado, mantendo os dados pesados fora do caminho da consulta principal. Esta postagem explicará o que são XATTRs, destacará seus benefícios e demonstrará como eles podem ser usados na pesquisa.
Onde estão XATTRs?
Os XATTRs são os metadados de um documento que um usuário pode modificar ou alterar sem alterar o conteúdo do documento. Isso permite que o documento seja separado em duas partes. Os serviços que exigem os documentos os buscarão no Key Value Store (KV), que obtém o conteúdo dos XATTRs somente quando necessário.
Vejamos um exemplo em que o usuário está tentando indexar dados de hotel em que a estrutura do documento é semelhante à seguinte:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "título": "Gillingham (Kent)", "name" (nome): "Albergue da Juventude de Medway", "endereço": "Capstone Road, ME7 3JE", "direções": nulo, "telefone": "+44 870 770 5964", "tollfree": nulo, "email": nulo, "fax": nulo, "url": "http://www.yha.org.uk", "checkin": nulo, "checkout": nulo, "price" (preço): nulo, "geo": { "lat": 51.35785, "longo": 0.55818, "precisão": "RANGE_INTERPOLATED" }, "id": 10025, "país": "Reino Unido", "cidade": "Medway", "estado": nulo,, "vaga": verdadeiro, "description" (descrição): "Albergue de verão com 40 leitos a cerca de 5 km de Gillingham, instalado em uma distinta Oast House convertida em um ambiente semi-rural.", "description_vector": [0.9293051,...(108 mais float32s)...,0.41247833], "pets_ok": verdadeiro, "free_breakfast" (café da manhã gratuito): verdadeiro, "free_internet": falso, "free_parking" (estacionamento gratuito): verdadeiro } |
Essa estrutura de documento inclui todos os campos necessários para um hotel, juntamente com uma descrição vetorizada usada para encontrar hotéis com descrições semelhantes. O vetor de descrição (linha 25), que é um vetor de 110 dimensões, ocupa cerca de 1.400 bytes, enquanto o restante do documento tem cerca de 1.400 bytes de tamanho.
Em casos de uso comuns, quando um usuário executa uma consulta não vetorial usando o SQL++ sem um índice de cobertura, o documento inteiro é obtido. Isso significa que, embora o vetor, que tem quase a metade do tamanho do documento, não seja necessário, ele ainda é recuperado com o restante do documento, o que acaba desperdiçando recursos.
Imaginemos uma situação em que o usuário não use XATTRs e tenha todos os dados dentro do conteúdo do documento e nenhum deles dentro de XATTRs. Qualquer serviço, como consulta e pesquisa, que tente buscar documentos terá que processar todo o conteúdo do documento para obter o que deseja.
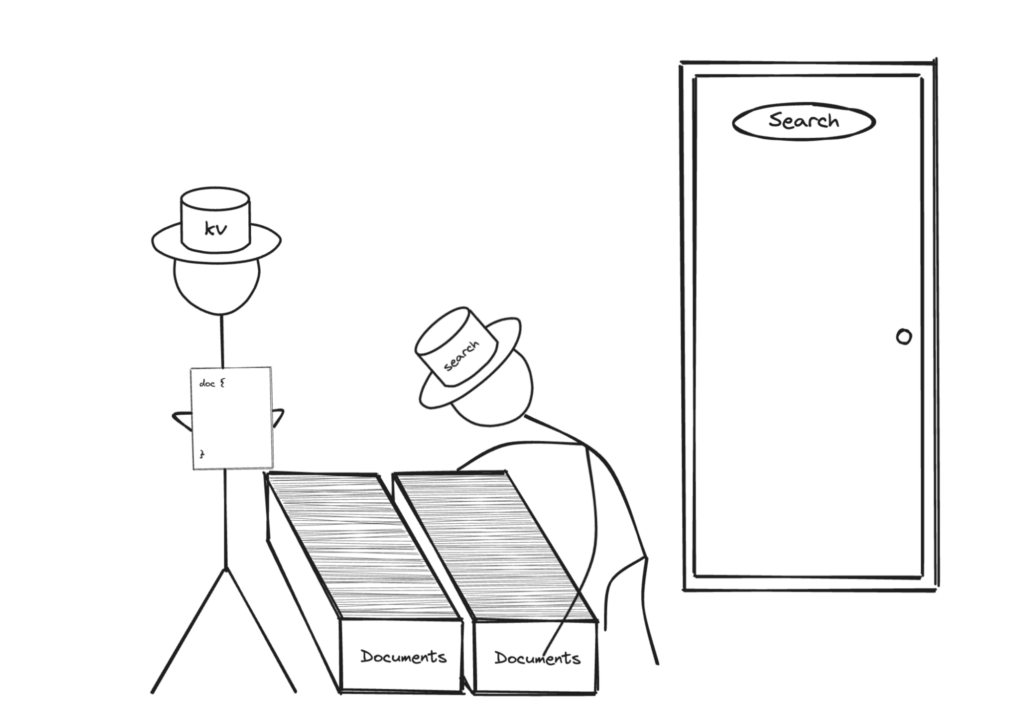
Uma maneira melhor de estruturar esse documento seria armazenar o vetor como parte dos XATTRs. Isso significaria que os serviços que procuram os dados não vetoriais só passarão pelo conteúdo do documento não XATTRs, reduzindo pela metade o volume de dados transferidos.
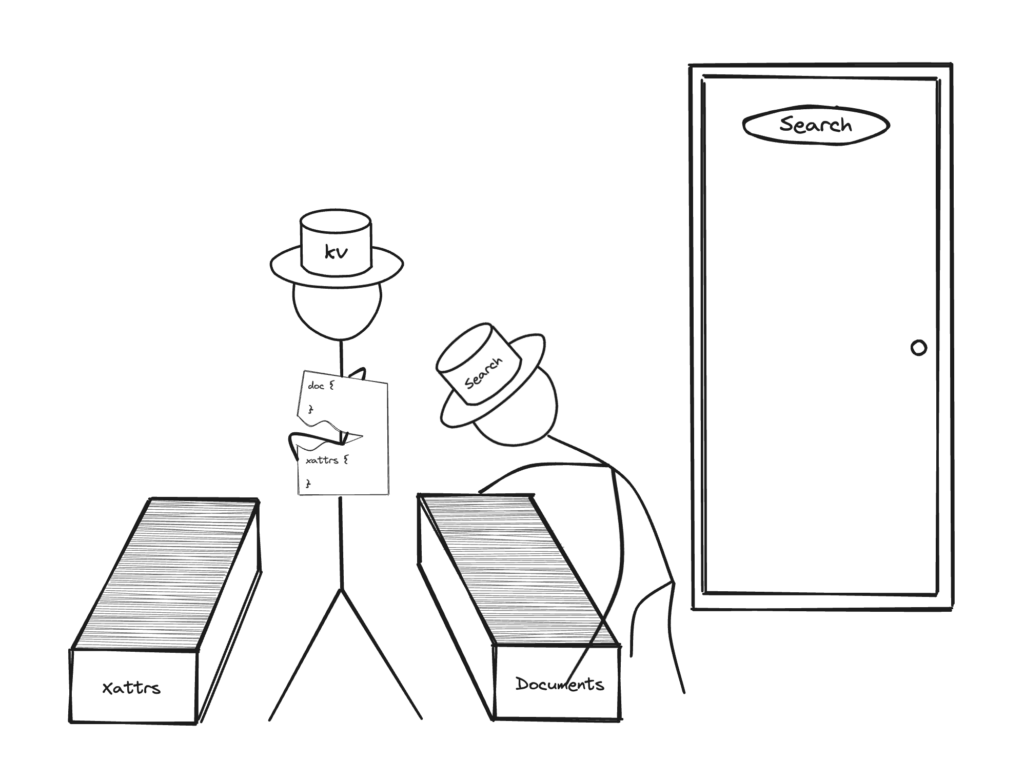
Os usuários podem até mesmo levar isso ao extremo adicionando outros campos pouco usados, como informações geográficas, detalhes de contato etc., também aos XATTRs. Isso reduz ainda mais a quantidade de dados desnecessários transferidos.

Como indexar o Couchbase XATTRs
A partir do Couchbase Server 7.6.2, o serviço de busca oferece aos usuários a capacidade de ingerir dados presentes em XATTRs somente quando exigido pelo mapeamento do índice durante o processo de criação do índice. Se os dados XATTRs não forem relevantes e um mapeamento XATTRs não estiver presente na definição do índice, os usuários poderão esperar uma taxa mais rápida de ingestão e indexação de dados porque uma carga útil mais leve será obtida do serviço de dados.
Vamos supor que um usuário tenha criado um índice que indexa o conteúdo dos XATTRs. A definição do índice seria semelhante a esta, com XATTRs indexados nas linhas 10-27:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
{ "name" (nome): "example-index", "tipo": "fulltext-index", "params": { "mapeamento": { "default_mapping": { "habilitado": verdadeiro, "dinâmico": verdadeiro, "propriedades": { "_$xattrs": { "habilitado": verdadeiro, "dinâmico": verdadeiro, "propriedades": { "textField": { "habilitado": verdadeiro, "dinâmico": falso, "campos": [ { "name" (nome): "textField", "tipo": "texto", "loja": falso, "índice": verdadeiro, "include_term_vectors": falso, "include_in_all": falso, "docvalues": falso } ] } } } } }, "default_type": "_default", "default_analyzer": "padrão", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "store_dynamic": falso, "index_dynamic": verdadeiro, "docvalues_dynamic": falso }, "loja": { "indexType": "scorch" (queimar), "kvStoreName": "" }, "doc_config": { "mode" (modo): "type_field", "type_field": "tipo", "docid_prefix_delim": "", "docid_regexp": "" } }, "sourceType": "couchbase", "sourceName": "sample-bucket" (cesto de amostras), "sourceUUID": "602c579bc2a74e67dc1f051eb769e702", "sourceParams": {}, "planParams": { "maxPartitionsPerPIndex": 1024, "numReplicas": 0, "indexPartitions": 1 }, "uuid": "" } |
Após a criação do índice usando uma definição de índice como a acima, a pesquisa buscará todo o conteúdo do documento e o conteúdo dos XATTRs no serviço de dados.
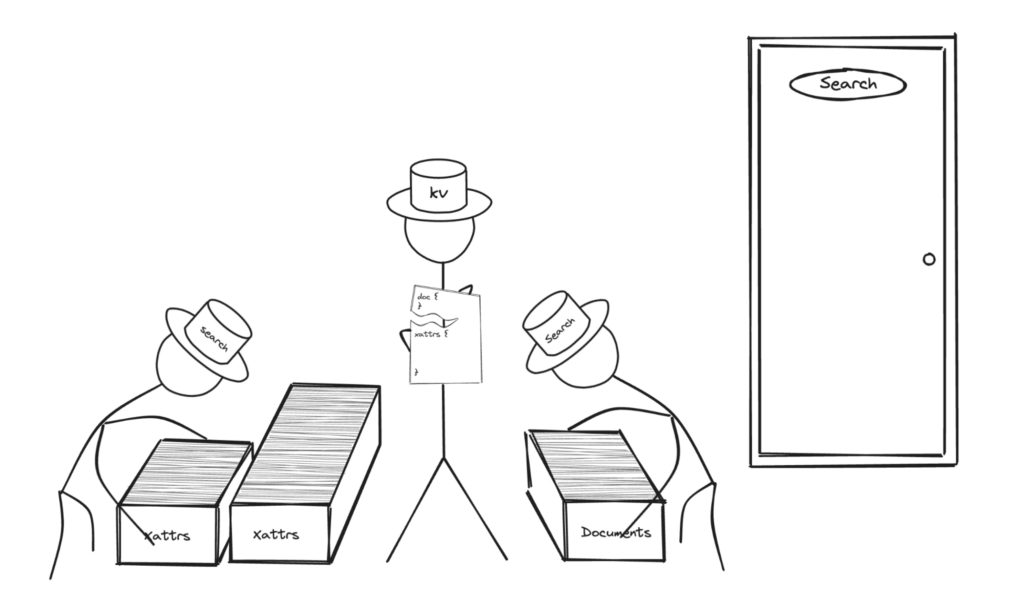
Nesse caso, depois de buscar o conteúdo, o serviço de busca combinará os dois em um único documento. Os dados presentes nos XATTRs serão mapeados para o conteúdo do documento em um mapeamento de campo especial denominado _$xattrs durante o processo de indexação.

Para consultar os campos presentes no conteúdo dos XATTRs, deve-se observar que esse conteúdo será colocado em um campo especial denominado _$xattrs e a consulta deve refletir isso. Há também uma restrição inerente ao tamanho do nome do campo XATTRs, que é de 12 caracteres.
Veja como fica a aparência ao criar uma consulta para um documento de amostra com XATTRs:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "explicar": verdadeiro, "campos": [ "*" ], "destaque": {}, "query" (consulta): { "query" (consulta): "_$xattrs.textField:*" }, "tamanho": 10, "de": 0 } |
Os XATTRs não se limitam ao armazenamento de vetores. Sempre que houver campos usados com pouca frequência, campos específicos apenas para o serviço de pesquisa ou campos volumosos, é recomendável adicioná-los aos XATTRs. Dessa forma, os serviços que não precisam desses campos precisam buscar menos dados do KV.
Próximas etapas
-
- Leia mais sobre Conceitos do Vector Search em nossos blogs, incluindo tutoriais e conceitos.
- Saiba mais sobre como usar XATTRs via SDKs por meio de nossa documentação.
- Avaliação gratuita do Couchbase Capella inclui pesquisa de vetores, entre muitos outros recursos. Experimente hoje mesmo.