Seja no local ou na nuvem pública, os clientes do Couchbase têm um conjunto distinto de necessidades: Transações ACID, gravações de alta durabilidade, alta disponibilidade e alto desempenho. A arquitetura do Couchbase ajuda a atender a essas necessidades e, ao mesmo tempo, reduz o incômodo para DevOps e DBAs (talvez para fazer uma pausa para o café ou uma noite de folga relaxante!). Em particular, o design assíncrono e orientado por eventos oferece suporte a uma cópia ativa e até três réplicas, além de failover automático em uma região. Da mesma forma, Grupos de servidores é um recurso integrado que pode ser amplamente usado no nível do rack ou até mesmo no nível da zona de disponibilidade em uma nuvem pública para fornecer alta disponibilidade, gravações persistentes e alto desempenho. Todos esses recursos se combinam para oferecer flexibilidade e resiliência prontas para uso.
Como combinar clusters e aproveitar os grupos de servidores
Este blog mostra como usar grupos de servidores para combinar clusters em um banco de dados com sharded automático para uma região dividida em zonas de disponibilidade. A combinação de clusters em três grupos de servidores distintos em um cluster tem várias vantagens:
-
- A distribuição de cargas de trabalho em mais nós ajuda a lidar com mais tráfego e maior capacidade de dados.
- Permite que você atenda ao modelo de zona de disponibilidade de redundância de failover e evita problemas de cérebro dividido.
- Aproveitando o recurso de failover automático incorporado do Couchbase, os grupos de servidores off-line ou as zonas de disponibilidade sofrerão failover automaticamente.
- A combinação de clusters significa uma cópia ativa de dados ou documentos com transações de vários documentos. Se houver várias gravações e leituras no mesmo documento/documentos de vários clientes, não haverá necessidade de resolução de conflitos. Se necessário, as gravações e leituras podem ser consistentes com a réplica e a camada persistente e garantir transações ACID.
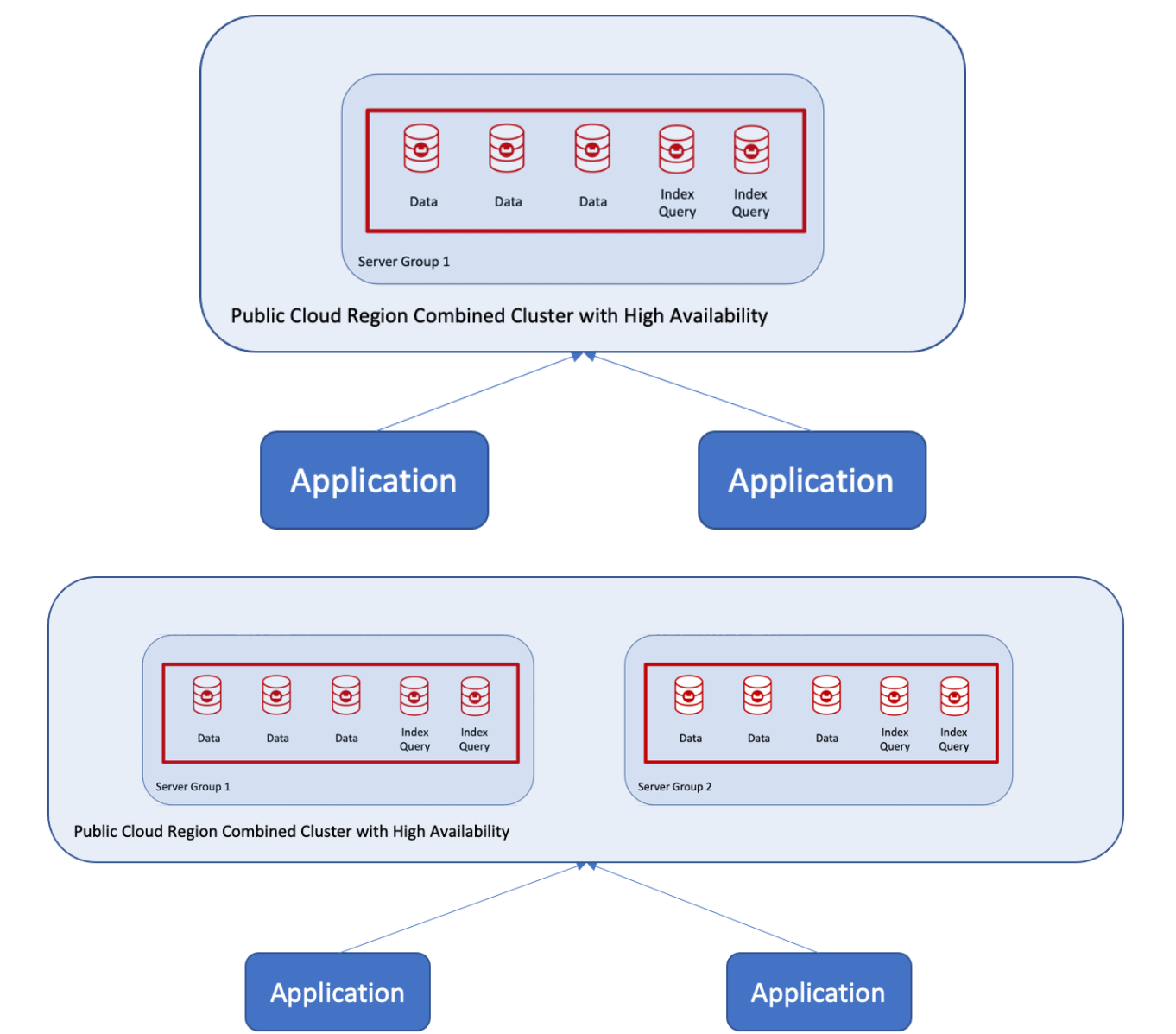
Recentemente, tive a oportunidade de ajudar um cliente a migrar de dois clusters com dois aplicativos interagindo com clusters separados para um altamente disponível, mas com gravações duráveis na réplica e no disco. O desafio era que cada aplicativo gravasse em uma cópia ativa dentro do cluster com garantias de gravação, conforme ilustrado abaixo. 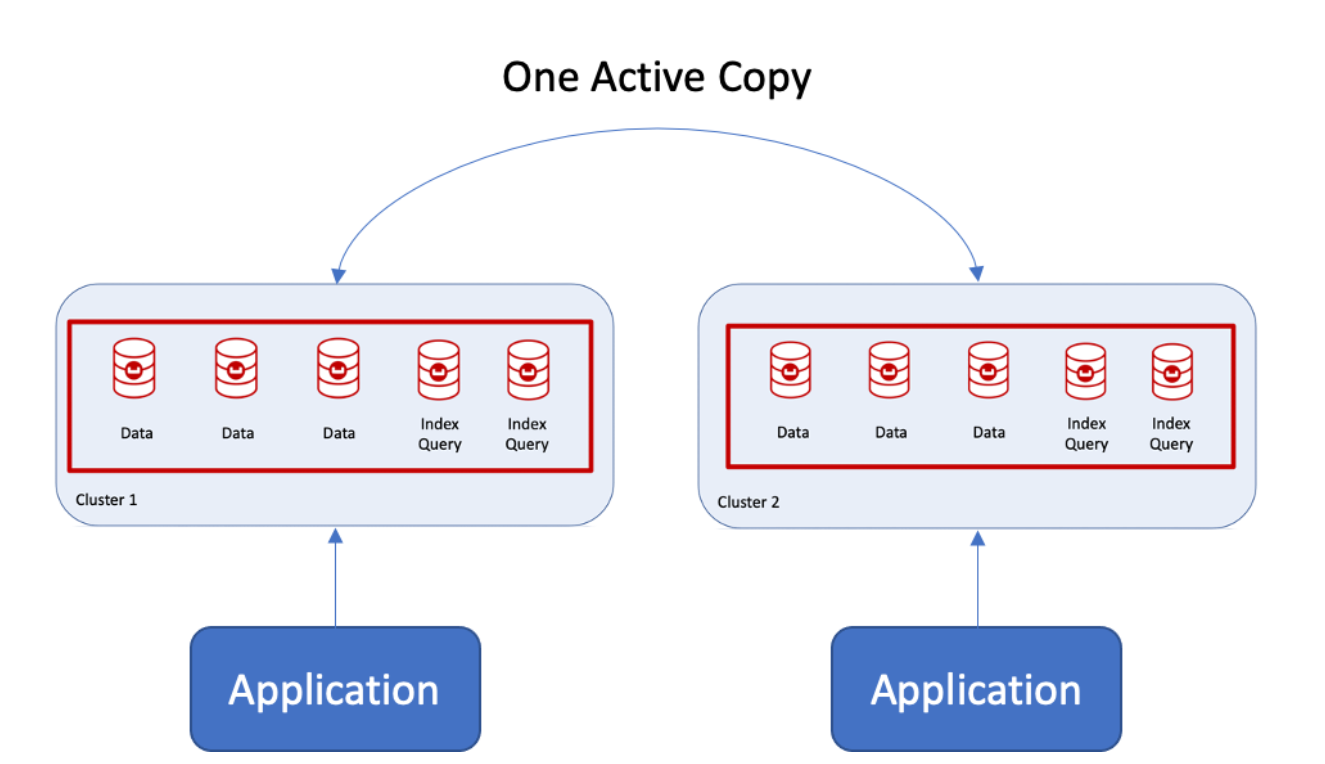
Por garantias de gravação, quero dizer que cada aplicativo gravaria na cópia ativa, bloquearia os dados e aguardaria a gravação da réplica e do disco antes de o outro aplicativo pode ler/gravar dados. Isso parece complicado? Na verdade, não é quando se usa o Couchbase e grupos de servidores.
O cliente queria um único cluster com failover automático usando a nuvem pública em uma região e com três zonas de disponibilidade, conforme mostrado aqui:
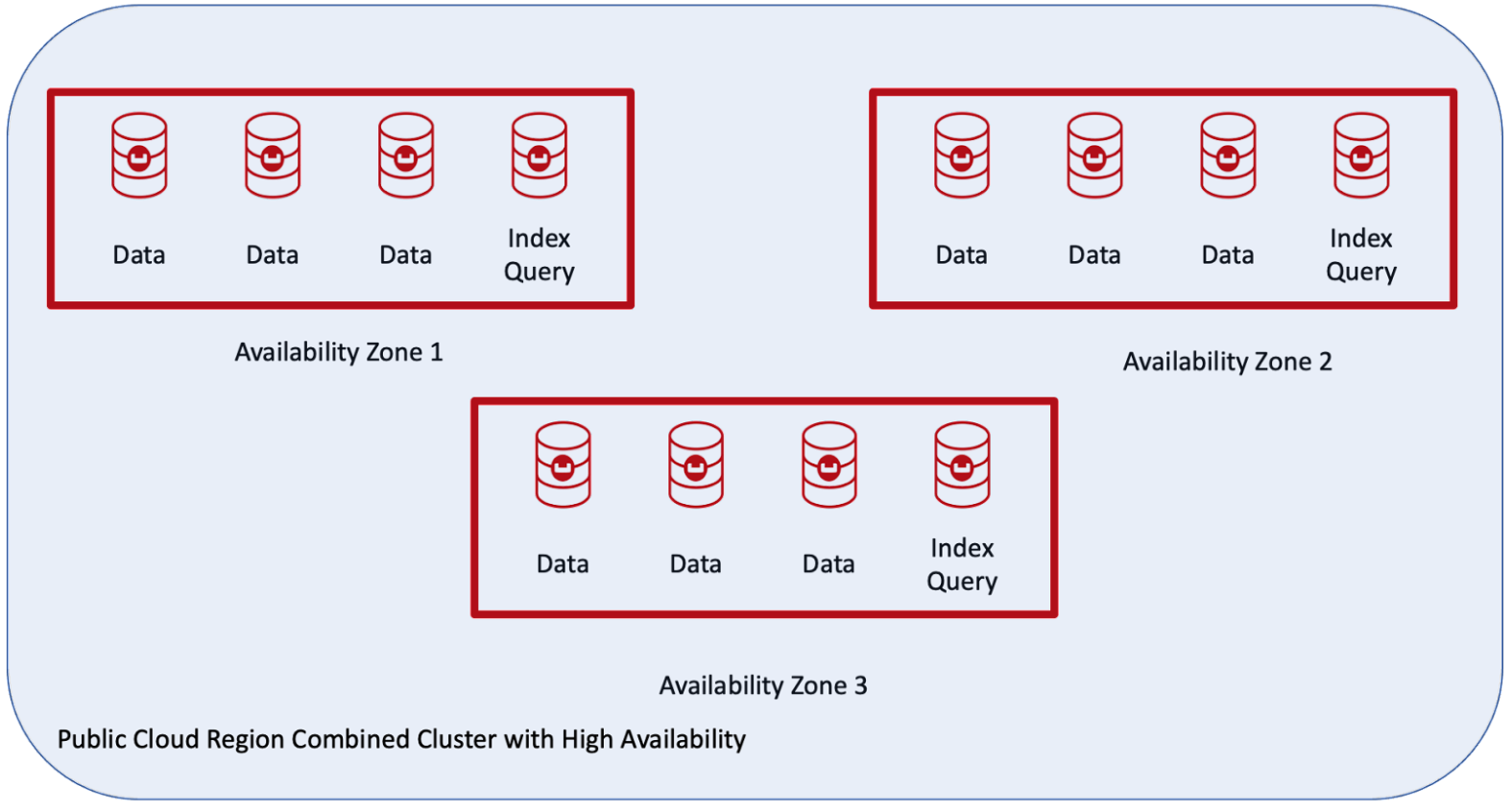
Benefícios dos grupos de servidores Couchbase
A topologia acima tem os seguintes recursos compatíveis:
-
- O recurso Auto-Failover está disponível.
- É possível ter uma cópia ativa dos dados e até três réplicas, dependendo do número de nós no cluster.
- Distribuição equilibrada e automática de cópias ativas e réplicas em todo o cluster.
- Os índices e as réplicas de índices são balanceados entre as zonas de disponibilidade.
Vamos ver como cada um desses recursos é suportado pelo Couchbase.
As regiões de nuvem pública (ou mesmo as implementações no local) exigem failover automático. Normalmente, com implementações no local, os clientes desejam distribuir suas máquinas em vários racks para evitar a perda de dados devido a uma falha no rack, como uma falha na fonte de alimentação.
Couchbase grupos de servidores é um recurso no qual cópias ativas e réplicas de dados são distribuídas uniformemente entre grupos de servidores. Mas os dados ativos não residem apenas em um grupo de servidores/zona de disponibilidade, mas abrangem todos os grupos de servidores. É garantido que a réplica resida em um grupo diferente para cada documento e índice ativo.
Não há necessidade de planejar e classificar os dados; a arquitetura do Couchbase faz o trabalho para você! Mas por que três grupos? Para evitar qualquer cenário de cérebro dividido se um grupo/zona de disponibilidade ficar inativo.
Como criar clusters de alta disponibilidade e alto desempenho
Qual é o procedimento recomendado para combinar dois clusters e adicionar um terceiro grupo de servidores? Na verdade, isso não é tão complicado com o Couchbase por causa da fragmentação automática, do gerenciamento de réplicas de índice e dos grupos de servidores. Conforme mostrado na figura a seguir, você usa os recursos de replicação entre datacenters (XDCR) de um cluster para outro (por exemplo, Cluster 2) e, em seguida, cria um novo grupo de servidores.
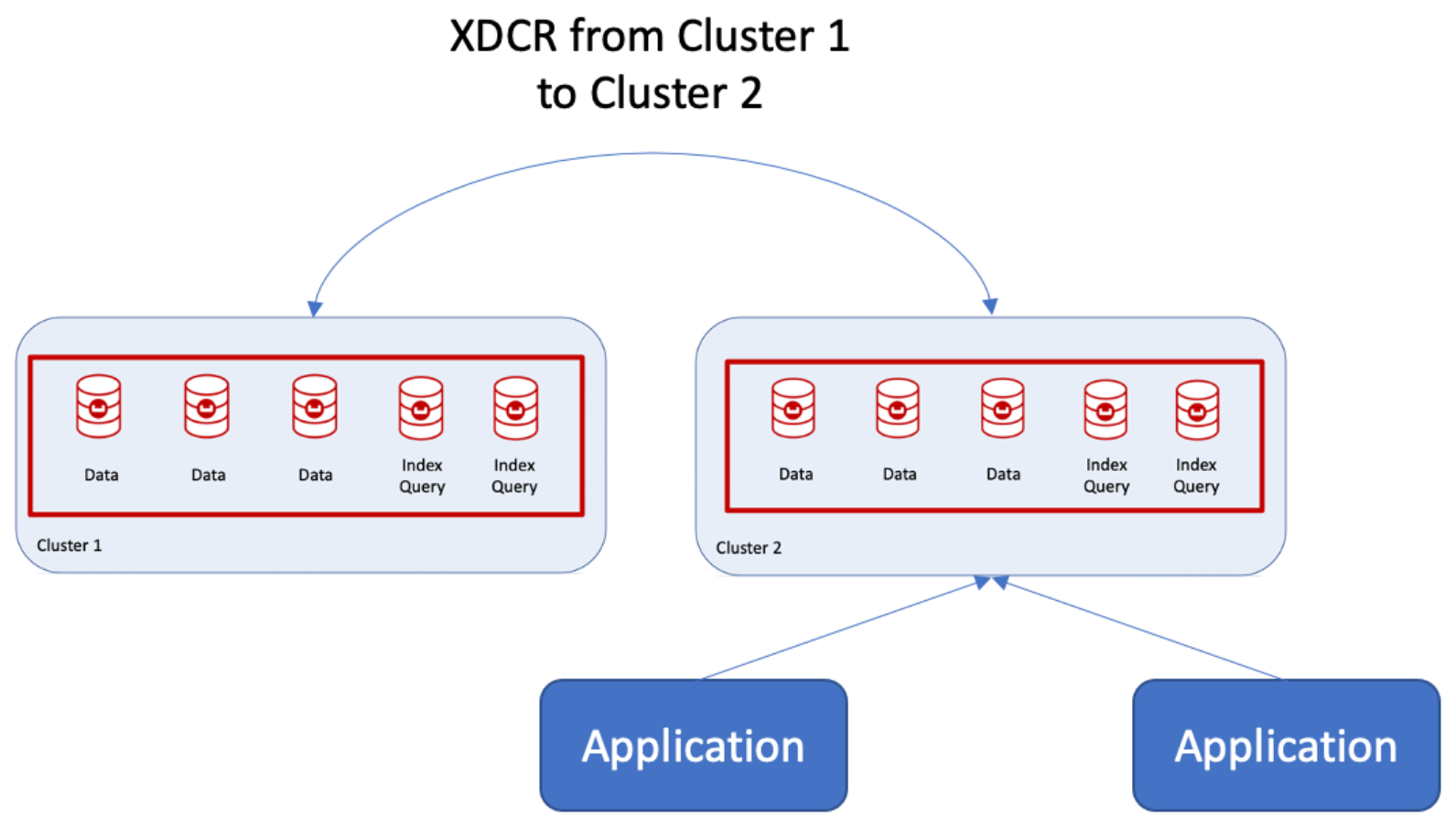
O cluster 2 se torna o cluster principal, e esses nós são declarados como Grupo de servidores 1o que o Couchbase pode fazer em tempo de execução! 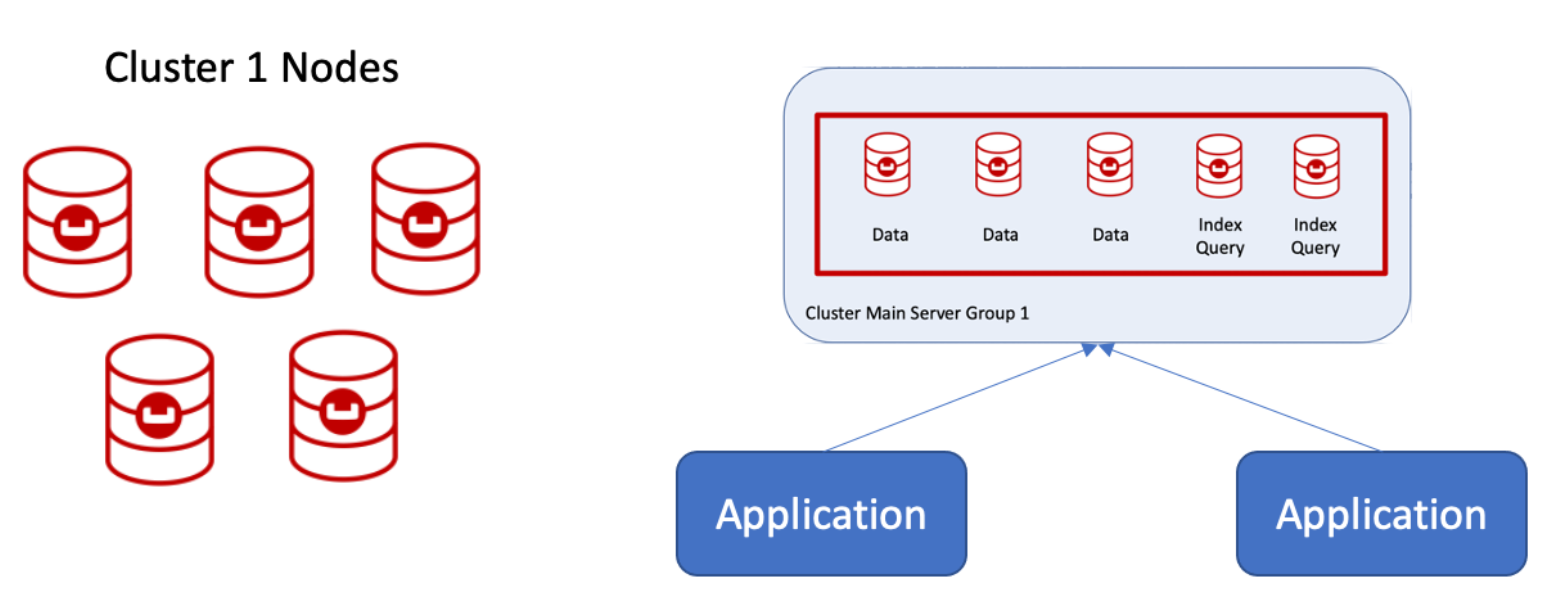 Os nós podem ser adicionados, um de cada vez, para criar o Grupo de Servidores 2. Se essa for uma implementação em nuvem pública, eles também podem ser declarados como Grupo de Disponibilidade 2.
Os nós podem ser adicionados, um de cada vez, para criar o Grupo de Servidores 2. Se essa for uma implementação em nuvem pública, eles também podem ser declarados como Grupo de Disponibilidade 2.
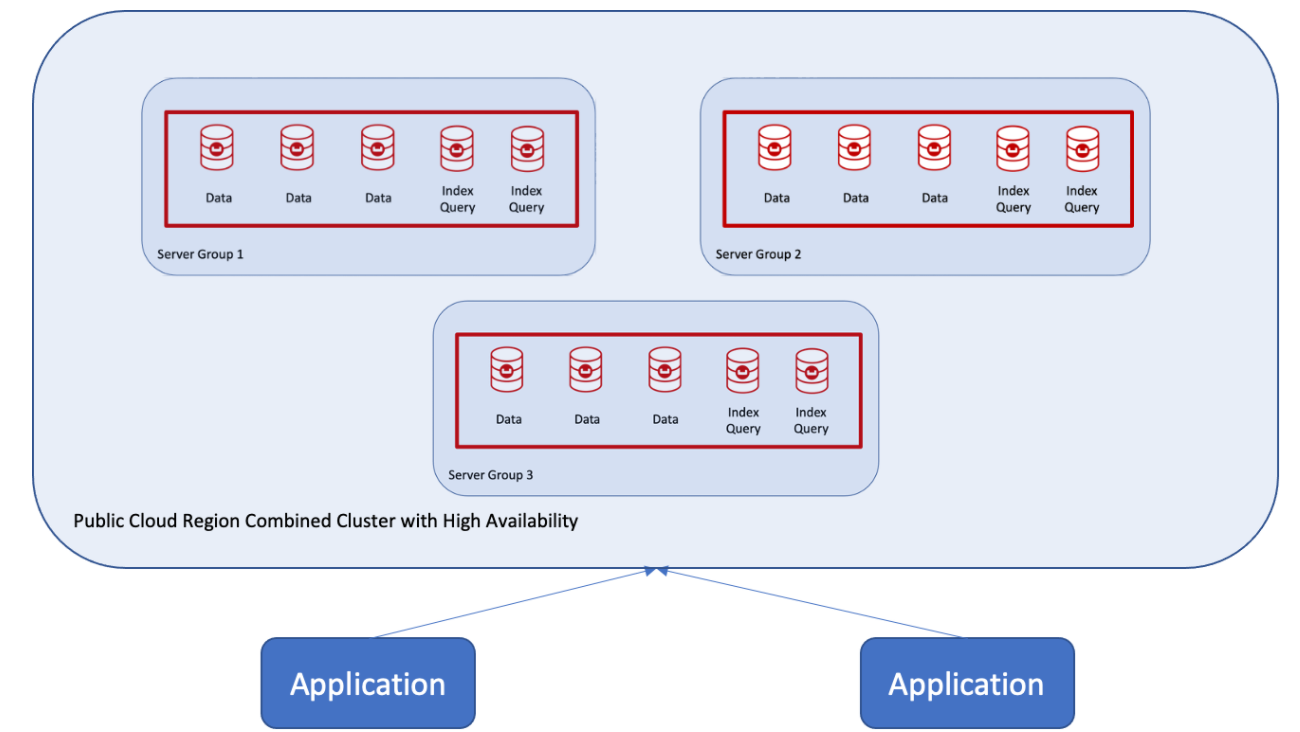 Por fim, adicione nós do Grupo de Servidores 3 ao cluster na Zona de Disponibilidade 3 se estiver em uma implantação de nuvem pública.
Por fim, adicione nós do Grupo de Servidores 3 ao cluster na Zona de Disponibilidade 3 se estiver em uma implantação de nuvem pública.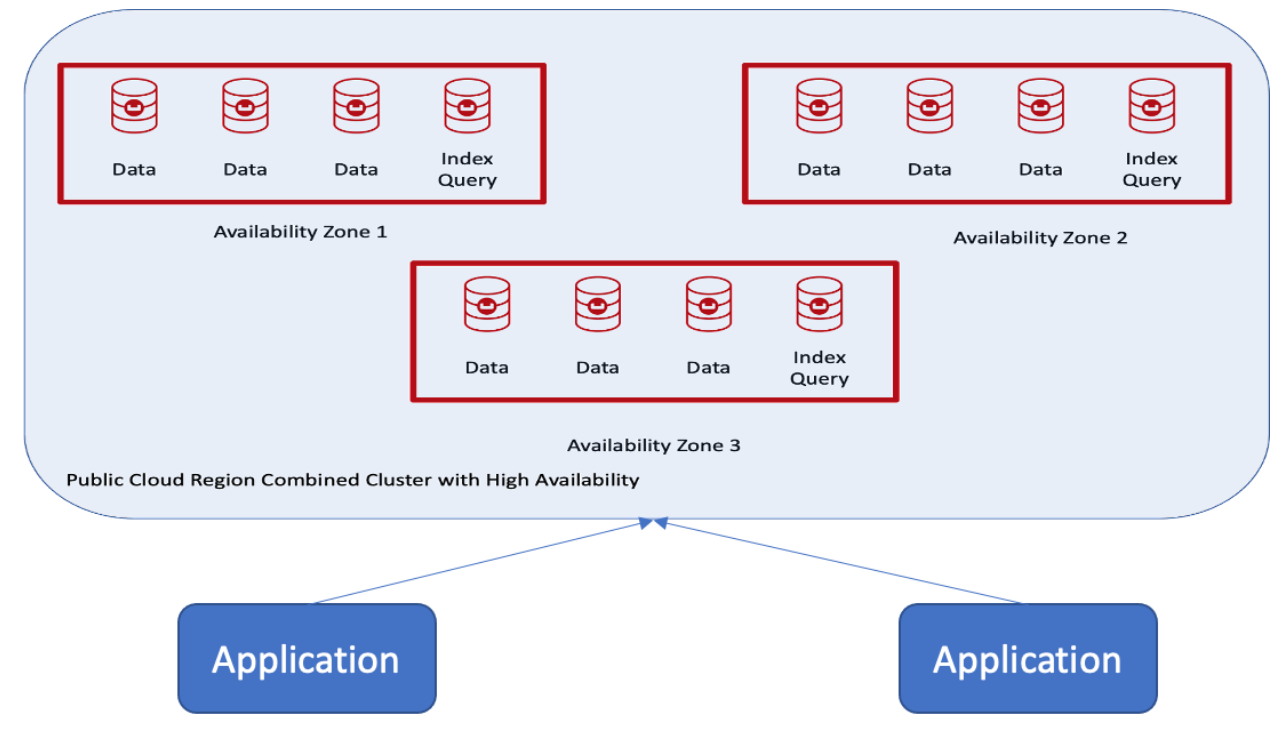
Isso pode ser feito de duas maneiras: nó por nó, com um rebalanceamento de cada vez após cada nó adicional. Ou usando o rebalanceamento após a adição de todos os nós.
Se você adicionar um nó ao cluster e remover um nó durante o mesmo rebalanceamento, o Couchbase Server fará um "rebalanceamento de swap", que pode ser uma operação que consome muitos recursos, pois os dados e os índices são movidos durante esse processo. Consulte os documentos de rebalanceamento e atualização para obter mais informações sobre isso. Isso deve ser feito com cuidado em um período de pouco tráfego. Isso pode levar algum tempo, portanto, planeje adequadamente.
Mas será que precisamos de todos os dois nós de índice e de consulta em cada região? Na verdade, isso depende do tráfego de consultas. Mas se o tráfego de consultas não for intenso, é possível usar um nó de consulta de índice por grupo de servidores.
Metas do Couchbase para alta disponibilidade
-
- O Couchbase foi projetado para estar operacional 100% do tempo, ou seja, sem tempo de inatividade.
- O Couchbase é um verdadeiro banco de dados com armazenamento automático, o que significa que a distribuição de dados no cluster durante a transição operacional não é um trabalho intenso para DevOps ou administradores de banco de dados.
- O recurso Grupos de servidores foi criado para Zonas de disponibilidade - o Couchbase garante que as cópias ativas e réplicas de dados e índices não estejam no mesmo grupo de servidores.
- Três grupos de servidores em três zonas de disponibilidade habilitam o recurso de failover automático do Couchbase com base em um cronômetro predefinido. O failover automático declarará um nó ou grupo de servidores como falho e tomará as medidas adequadas para criar réplicas e enviar o mapa do cluster para os clientes.
Próximas etapas e recursos
O Couchbase tem autonomia incorporada à arquitetura; portanto, a movimentação de dados e índices é simplificada e automática. Vimos por que a combinação de clusters é uma boa ideia e como torná-los tolerantes a falhas. O Couchbase é poderoso porque não há interrupção das operações - o cluster fica operacional o tempo todo. Os aplicativos não precisam de nenhuma alteração no código para interagir com o cluster. As alterações no cluster são tratadas pelo mapa de cluster interno do SDK, sendo que todas as alterações são transparentes para o próprio aplicativo.
A equipe de design e a arquitetura do Couchbase têm visão de futuro e incluem autonomia operacional e fragmentação automática para criar o banco de dados tolerante a falhas ideal para quase todos os casos de uso.
A próxima evolução da automação é o Operador autônomo para Kubernetes e OpenShift. Imagine um cluster de autocorreção e autogerenciamento com a ajuda de um operador fazendo o trabalho. Esse é o Operador Autônomo do Couchbase. Todo o processo descrito acima pode ser executado com o operador e um arquivo YAML do novo cluster final. É realmente simples assim.
Recursos
Leia os documentos e as páginas a seguir para saber mais sobre clusters de alta disponibilidade, rebalanceamento e muito mais:
-
- Documentos de conscientização do grupo do Couchbase Server
- Documentos sobre o rebalanceamento do Couchbase
- Usar a API REST do administrador para reequilibrar um cluster do Couchbase
- Couchbase Operador autônomo para Kubernetes
- DBaaS NoSQL do Couchbase Cloud totalmente gerenciado (teste gratuito fácil disponível)
