A replicação de dados tradicional exigia o gerenciamento de muitas partes móveis em seu aplicativo. A replicação de dados moderna leva isso para a nuvem, onde os sistemas de back-end fazem a maior parte do trabalho pesado. Mas a replicação de dados na nuvem é mais do que apenas sincronizar dados ou fazer cópias de backup em servidores remotos. Este guia apresenta alguns casos de uso comuns para a replicação de dados na nuvem, analisa alguns métodos para implementá-la e identifica como ela é um divisor de águas para o desenvolvimento de aplicativos modernos.
O que é replicação de dados na computação em nuvem?
A replicação de dados é o processo de manutenção de cópias redundantes de dados primários. Isso é importante por vários motivos, incluindo tolerância a falhas, alta disponibilidade, aplicativos de leitura intensiva, latência de rede reduzida ou suporte a requisitos de soberania de dados.
Tolerância a falhas: A replicação de dados é necessária quando os aplicativos precisam preservar os dados em caso de falha de hardware ou de rede devido a causas que vão desde alguém tropeçar em um cabo de energia até um desastre regional, como um terremoto. Portanto, todo aplicativo precisa de replicação de dados para ter resiliência e consistência.
Alta disponibilidade: Os dados acessados com frequência por muitos usuários ou sessões simultâneas precisam de replicação de dados. Nesse caso, os dados replicados devem permanecer consistentes com seu líder e outras réplicas.
Reduzir a latência: A replicação de dados também ajuda os aplicativos modernos em nuvem a executar dados distribuídos em diferentes redes ou regiões geográficas que atendem melhor ao usuário final.
Em resumo, não se trata apenas de backup e gerenciamento de desastres, mas também do desempenho dos aplicativos. Vamos nos aprofundar em como a replicação funciona e entender um pouco mais essas necessidades.
Como funciona a replicação de dados?
Um plano de replicação adequado institui políticas que mantêm uma ou mais cópias de cada parte dos dados, de modo que, se uma única parte faltar, pelo menos uma alternativa, idealmente mais, estará disponível.
No nível do aplicativo, isso se parece com o armazenamento de alguns registros de dados em um local mestre e o sistema de back-end mantendo cópias desses dados como réplicas. Pode ser complicado criar um serviço personalizado para copiar todos os dados para outro local; mantê-los sincronizados é um grande desafio de engenharia. Da mesma forma, o armazenamento de todas as réplicas no mesmo local torna o sistema vulnerável a desastres nesse local, eliminando todas as réplicas.
Portanto, a replicação divide os conjuntos de dados primários em partes virtuais menores, conhecidas como partições. Cada partição é replicada, de preferência em diferentes locais no disco, em outras redes, em volumes de armazenamento redundantes ou usando várias plataformas de nuvem e diferentes servidores remotos em racks segregados.
O potencial de complexidade costuma ser o fator limitante para as empresas que buscam implementar práticas recomendadas de replicação de dados - é essencial ter sistemas de front e back-end que lidem com isso de forma transparente.
Replicação de dados na nuvem vs. replicação de dados tradicional
Há vários níveis de opções de replicação de dados - a replicação de dados na nuvem é uma delas. A replicação de dados tradicional tem algumas opções para replicar dados de e para outras fontes, como de um dispositivo móvel para um PC local ou de um PC local para um banco de dados em rede. Um banco de dados em rede também pode ser replicado em uma rede externa para fins de backup.
A maioria desses casos de uso era simples e destinava-se apenas a preservar os dados em caso de falha, mas exigiria trabalho manual para remontar as peças enquanto estivesse off-line. Em geral, as réplicas não eram acessíveis diretamente aos aplicativos até que os nós primários falhassem e as réplicas se tornassem "ativas" e assumissem o lugar do mestre.
A replicação de dados na nuvem eleva esse nível, permitindo que os aplicativos enviem dados para vários serviços de armazenamento ou dados baseados na nuvem que, por sua vez, enviam réplicas para outros recursos baseados na nuvem. Esses recursos imitam a replicação de dados tradicional em alguns aspectos, mas a estendem para a nuvem.
Vamos subir na pilha, dos cenários mais básicos aos mais avançados, para o planejamento de recursos na nuvem.
A replicação mais básica usaria várias máquinas baseadas na nuvem no mesmo data center, ou seja, um cluster de banco de dados com vários nós, talvez até no mesmo rack de servidor na mesma rede. Em seguida, a distribuição em nível de rack espalha os nós de dados por mais de um rack de hardware.
O próximo estágio espalha os dados em diferentes locais geográficos em uma rede, por exemplo, regiões ou zonas. Um banco de dados pode armazenar os dados mestres em São Francisco e réplicas em Nova York e Londres. Isso é Replicação entre centros de dadoscomo visto em sistemas como o Couchbase, que gerenciam a distribuição de nós nos bastidores.
O que é replicação de dados de nuvem para nuvem?
Outra camada na escada de replicação é entre várias nuvens. A replicação de nuvem no AWS pode ser semelhante à do Google Cloud, mas aplicativos sofisticados podem se beneficiar significativamente com a replicação de serviços de dados entre mais de um provedor de serviços em nuvem.
Uma opção moderna de nuvem híbrida usa sua rede local como uma cópia mestre e vários serviços de nuvem ou regiões variadas em uma nuvem como parte da replicação. O ideal é que todos os nós desse projeto sejam acessíveis aos aplicativos (para leitura e gravação), mesmo quando não houver nenhum desastre em andamento.
Antes de entrarmos em mais detalhes, é importante saber que há muitas maneiras de projetar uma topologia de replicação para diferentes níveis de redundância e desempenho. Os diferentes projetos incluem unidirecional, bidirecional, hub e spoke, circular etc. Este guia não prescreve uma topologia específica em detalhes, mas compartilha alguns dos conceitos subjacentes a elas em geral.
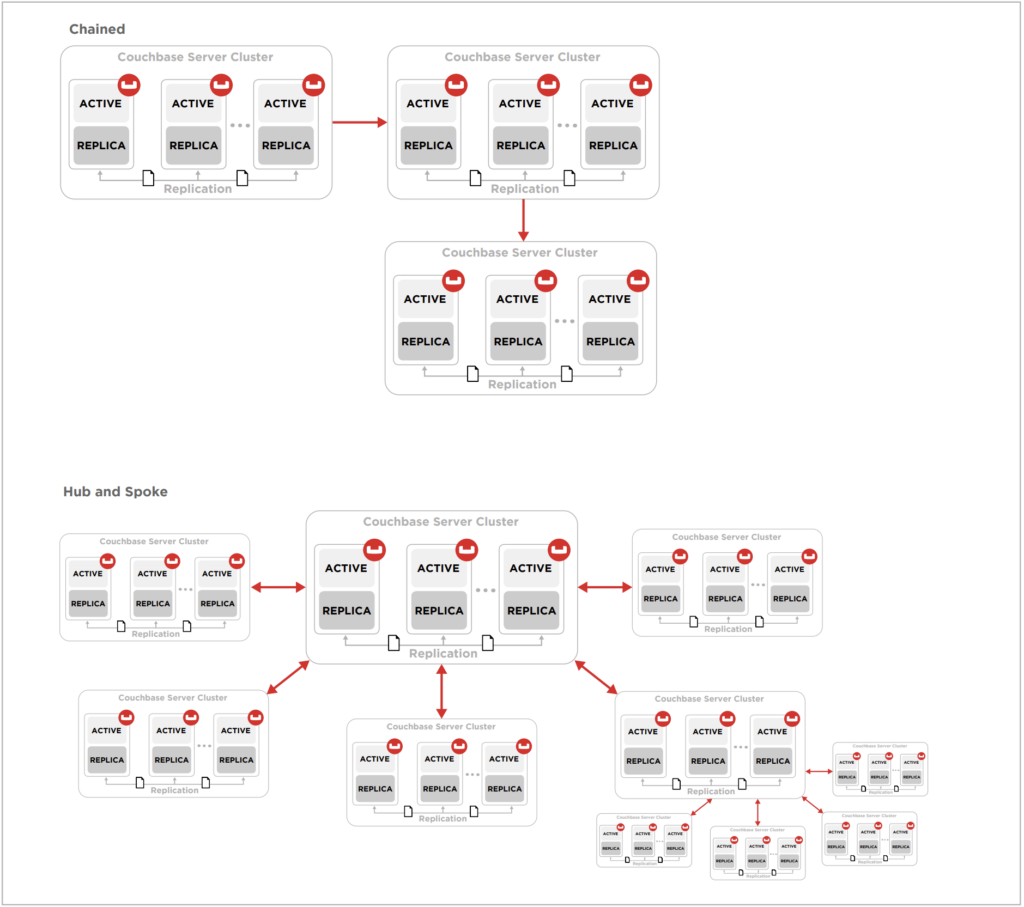
Algumas das topologias de replicação mais complexas
Por que replicar dados para a nuvem?
Há diferentes motivos para replicar dados na nuvem. A rede privada de uma empresa pode ser redundante, mas precisa de mais distribuição geográfica. A replicação na nuvem permite que a organização mantenha seus dados de rede privada, mas tenha redundância em caso de desastre. Os vários níveis de redundância baseada em nuvem descritos acima ajudam a evitar danos causados por diferentes níveis de desastres - locais, específicos do data center, falhas de rack etc.
A replicação na nuvem acrescenta outro nível de redundância, contribuindo para a alta disponibilidade, mas também ajuda a evitar o bloqueio de fornecedor. Se um provedor de serviços em nuvem tiver problemas, você poderá mudar rapidamente para outro com o mínimo de interrupção.
Benefícios do desempenho do aplicativo
Os cenários de desastres não são o único motivo para usar a replicação de dados na nuvem; ela também pode acelerar a execução de seus aplicativos, especialmente os aplicativos móveis. Os sistemas modernos permitem que os aplicativos usem réplicas como fontes de dados para aplicativos. Os métodos tradicionais as mantinham como meros backups que poderiam se tornar ativos se necessário, simplificando intencionalmente a sincronização por ter apenas uma cópia principal.
Com réplicas ativas disponíveis, os desenvolvedores de aplicativos podem escolher se desejam executar os dados em um local ou rede diferente. Isso é fundamental para reduzir a latência da rede para aplicativos de alto desempenho.
Os jogos, por exemplo, exigem operações de alta velocidade e alta largura de banda, portanto, os aplicativos são roteados para o servidor mais próximo sempre que possível. As réplicas dos dados ainda estão disponíveis globalmente, mas um local é preferido. Por exemplo, o acesso aos dados na América do Norte levaria mais tempo do que se uma cópia estivesse disponível na Ásia, onde o usuário mora.
Replicação de dados na nuvem para recuperação de desastres
Para atender às necessidades modernas de recuperação de desastres, é preciso haver mais do que simples cópias de dados espalhadas pelo mundo. Políticas de recuperação eficazes exigem que os dados sejam distribuídos de forma redundante para evitar desastres geográficos, mas também devem estar disponíveis para troca em tempo real quando ocorrer uma falha.
As empresas não podem se dar ao luxo de esperar até que ocorra uma falha para enviar sua equipe para repará-la. Em vez disso, os arquitetos projetam sistemas de dados que preveem falhas, atenuam-nas por meio de failover inteligente para novos nós e ajudam as equipes de DevOps a corrigir o problema o mais rápido possível. A intervenção manual geralmente significa tempo de inatividade, o que ninguém quer, portanto, back-ends automatizados para failover e recuperação são essenciais.
O que foi dito acima se aplica a dados locais e em nuvem, exceto pelo fato de que os sistemas podem usar recursos baseados em nuvem para ajudar a identificar e solucionar falhas de algumas maneiras diferentes.
A rede de back-end dos serviços em nuvem pode ajudar a manter os nós distribuídos atualizados uns com os outros devido à interconectividade robusta em suas redes. Vários nós no Google Cloud, por exemplo, mesmo que geograficamente distribuídos, podem tornar rápido e simples manter a sincronização sem acionar os servidores locais da empresa para enviar dados de volta a outros locais.
Suporte ao crescimento dos serviços de dados
Os serviços em nuvem também são projetados para serem elásticos e crescerem conforme necessário. Por exemplo, se o disco de um nó falhar, o serviço de nuvem poderá ativar um novo recurso, replicar os dados e remover o disco com falha. Os sistemas de nuvem automatizados podem fazer isso mais rapidamente do que um gerente de dados leva para perceber que há um problema.
Da mesma forma, como os recursos são praticamente ilimitados na nuvem, à medida que o uso de recursos/dados aumenta, o serviço de nuvem pode reajustar o particionamento e mudar para máquinas maiores ou adicionar mais nós, conforme necessário.
Como os serviços em nuvem existem globalmente, os aplicativos podem testar e descobrir quais réplicas de seus dados seriam as melhores para usuários específicos, dependendo de sua localização. Se um serviço de dados ficar indisponível ou a latência atingir um determinado limite, os aplicativos poderão se deslocar para outra região e continuar a operação.
Código personalizado para gerenciar a replicação
Como você pode ver, o potencial de replicação ininterrupta de dados tornou-se possível com os serviços baseados em nuvem. No entanto, codificar a inteligência em seu aplicativo pode ser um desafio, pois o maior potencial também aumenta a complexidade.
O desenvolvimento personalizado de uma solução robusta é caro e de manutenção complexa. O ideal é que seu backend de gerenciamento de dados cuide de tudo isso para você. Verifique se seus sistemas têm opções fáceis de usar para configurar réplicas em nós, racks, regiões etc. Caso contrário, considere a possibilidade de encontrar uma alternativa melhor antes de se comprometer com as milhares de horas necessárias para criar sua própria solução.
O Couchbase é um exemplo de banco de dados que ajuda a gerenciar tudo isso para você, oferecendo opções para escolher o equilíbrio entre alta disponibilidade e alto desempenho. Com essas opções, é possível implementar o planejamento de recuperação de desastres desde o primeiro dia e gerenciar os custos de infraestrutura no futuro.
Saiba mais
Em resumo, a replicação tradicional pode exigir servidores cada vez maiores, mas a replicação de dados na nuvem permite flexibilidade à medida que você cresce e oferece opções para manter tudo funcionando sem problemas. Leia nosso whitepaper: Alta disponibilidade e recuperação de desastres para dados distribuídos globalmente para obter mais informações sobre as várias topologias e abordagens que recomendamos.
Pronto para experimentar os benefícios da replicação de dados na nuvem com seus próprios aplicativos?
Comece a usar o Couchbase Capella:
-
- Comece sua teste gratuito e veja como é fácil começar a usar o Couchbase
- Saiba mais sobre o Capella e assista ao vídeo de demonstração
- Assista a mais vídeos sobre o Couchbase em nosso Canal do YouTube