
Traditional data replication required managing a lot of moving parts in your application. Modern data replication takes it to the cloud, where backend systems do most of the heavy lifting. But cloud data replication is more than just synchronizing data or making backup copies on remote servers. This guide presents some common use cases for cloud data replication, reviews some methods for implementing it, and identifies how it is a game changer for modern application development.
What is data replication in Cloud Computing?
Data replication is the process of maintaining redundant copies of primary data. This is important for several reasons, including fault tolerance, high availability, read-intensive applications, reduced network latency, or supporting data sovereignty requirements.
Fault Tolerance: Data replication is necessary when applications must preserve data in the case of hardware or network failure due to causes ranging from someone tripping over a power cable to a regional disaster such as an earthquake. Thus, every application needs data replication for resilience and consistency.
High Availability: Data frequently accessed by many users or concurrent sessions needs data replication. In this case, replicated data must remain consistent with its leader and other replicas.
Reduce Latency: Data replication also helps modern cloud applications run off distributed data in different networks or geographic regions that serve the end user better.
In short, it’s not only about backup and disaster management but also about application performance. Let’s dive into how replication works and understand these needs a little deeper.
How does data replication work?
A proper replication plan institutes policies that keep one or more copies of every piece of data so that if any single part goes missing, at least one, ideally more, alternatives are available.
At an application level, this looks like storing some records of data at a master location and the backend system maintaining copies of that data as replicas. It can be complicated to build a custom service to copy all the data to another site; keeping it in sync is a serious engineering challenge. Likewise, storing all replicas in the same location makes it vulnerable to disasters in that location, taking out all the replicas.
Therefore, replication breaks primary datasets into smaller, virtual pieces known as partitions. Each partition is replicated, ideally to different locations on disk, in other networks, on redundant storage volumes, or using several cloud platforms and different remote servers on segregated racks.
The potential for complexity is often the limiting factor for companies seeking to implement data replication best practices – having front and backend systems that handle it transparently is essential.
Cloud data replication vs. traditional data replication
There are several levels to data replication options–cloud data replication is one of them. Traditional data replication has a few options for replicating data to and from other sources, such as from a mobile device to a local PC or from a local PC to a networked database. A networked database may also replicate to an external network for backup purposes.
Most of these use cases were simple and meant only to preserve data in case of a failure, but would require manual work to reassemble the pieces while offline. Replicas were not usually accessible to applications directly until the primary nodes failed and replicas became “active” and took over for that master.
Cloud data replication takes it one level higher, allowing applications to send data to multiple cloud-based data or storage services that, in turn, send replicas to other cloud-based resources. These resources mimic traditional data replication in some ways but extend it to the cloud.
Let’s move up the stack from the most basic to the most advanced scenarios for cloud resource planning.
The most basic replication would use multiple cloud-based machines in the same data center–i.e., a database cluster with several nodes, maybe even in the same server rack in the same network. Next, rack-level distribution spreads data nodes across more than one hardware rack.
The next stage spreads data across different geographic locations on a network, e.g., regions or zones. A database may store the master data in San Francisco and replicas in New York and London. This is cross-data center replication, as seen in systems like Couchbase, that manage the distribution of nodes behind the scenes.
What is cloud-to-cloud data replication?
Yet another layer on the replication ladder is between multiple clouds. Cloud replication on AWS may look similar to Google Cloud, but sophisticated applications can significantly benefit by having data services replicated between more than one cloud service provider.
A modern hybrid cloud option uses your local network as a master copy and multiple cloud services or varying regions within one cloud as part of the replication. Ideally, all nodes in this design are accessible to applications (for reading and writing) even when no disaster is at play.
Before we get into some more of the details, it is important to know there are many ways to design a replication topology for different levels of redundancy and performance. Different designs include unidirectional, bidirectional, hub and spoke, circular, etc. This guide does not prescribe a specific topology in detail but shares some of the concepts underlying these in general.
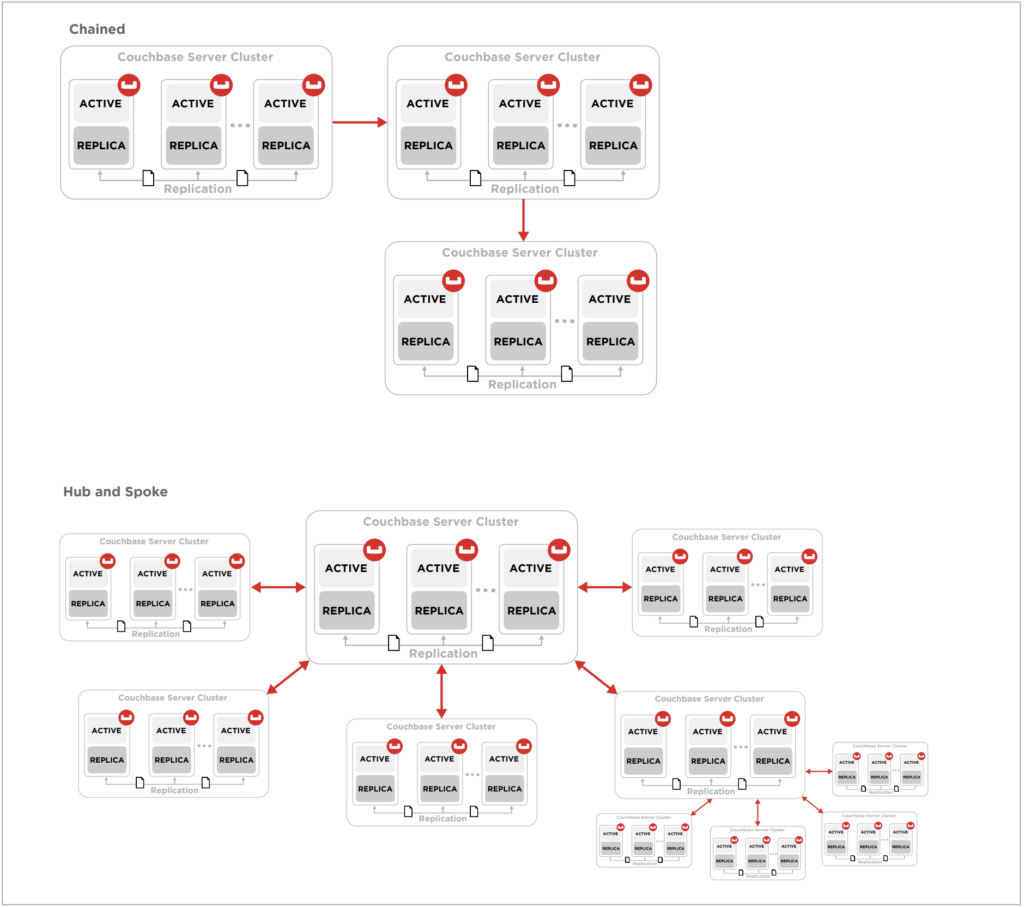
Why replicate data to the cloud?
There are different reasons for replicating data to the cloud. A company’s private network may be redundant but need more geographic distribution. Cloud replication allows the organization to maintain its private network data but has redundancy in the case of disaster. The various levels of cloud-based redundancy described above help prevent damage from different levels of disasters–local, datacenter specific, rack failures, etc.
Cloud replication adds another level of redundancy, contributing to high availability but also helps you avoid vendor lockin. If one cloud service provider has issues, you can quickly switch to another with minimal interruption.
Application performance benefits
Disaster scenarios are not the only reason to use cloud data replication, it can also make your applications run faster, especially mobile applications. Modern systems allow applications to use replicas as data sources for applications. Traditional methods kept them as mere backups that could become active if needed, intentionally simplifying synchronization by having only one master copy.
With active replicas available, application developers can choose whether to run on data in a different location or network. This is critical for reducing network latency for high-performance applications.
Gaming, for example, requires high speed and high bandwidth operations, so applications are routed to the nearest server whenever possible. Replicas of the data are still available globally, but one location is preferred. For example, accessing data in North America would take longer to access than if a copy was available in Asia, where the user lives.
Cloud data replication for disaster recovery
There needs to be more than just simple copies of data spread around the globe for modern disaster recovery needs. Effective recovery policies require that data is redundantly distributed to prevent geographic disasters, but it must also be available for real-time changeover when a failure occurs.
Businesses cannot afford to wait until a failure happens before sending their team to repair it. Instead, architects design data systems that anticipate failures, mitigate them by intelligently failing over to new nodes, and help DevOps teams fix the issue as soon as possible. Manual intervention often means downtime–which nobody wants, so automated backends for failover and recovery are essential.
The above applies to cloud and local data, except that systems can use cloud-based resources to help identify and address failures in a few different ways.
The backend networking of cloud services can help keep distributed nodes up to date with one another due to robust interconnectivity across their networks. Multiple nodes in Google Cloud, for example, even if geographically distributed, can make it fast and straightforward to keep synchronized without triggering local company servers to send data back out to other locations.
Supporting the growth of data services
Cloud services are also designed to be elastic and grow as needed. For example, if a node’s disk fails, the cloud service can spin up a new resource, replicate the data, and remove the failing one. Automated cloud systems can do this faster than it takes a data manager to notice there is a problem.
Likewise, because resources are virtually unlimited in the cloud, as resource/data usage grows, the cloud service can readjust the partitioning and switch over to larger machines or add more nodes as needed.
As cloud services exist globally, applications can test and discover which replicas of their data would be the best for specific users, depending on their location. If a data service becomes unavailable or latency reaches a certain threshold, applications can move to another region and continue operation.
Custom code to manage replication
As you can see, the potential for unbreakable data replication has become possible with cloud-based services. However, coding the intelligence into your application may be challenging as the increased potential also increases complexity.
Custom development of a robust solution is costly and complex to maintain. Ideally, your data management backend would handle it all for you. Check if your systems have easy-to-use options for setting up replicas across nodes, racks, regions, etc. If not, consider finding a better alternative before committing to the thousands of hours required to build your own.
Couchbase is one example of a database that helps manage all of this for you, providing options for choosing how to balance between high availability and high performance. Having these options makes it possible to implement disaster recovery planning from day one and manage infrastructure costs into the future.
Learning more
To sum up, traditional replication may mandate bigger and bigger servers, but cloud data replication allows flexibility as you grow and delivers options for keeping it all running smoothly. Read our whitepaper: High Availability and Disaster Recovery for Globally Distributed Data for more information on the various topologies and approaches that we recommend.
Ready to try the benefits of cloud data replication with your own applications?
Get started with Couchbase Capella:
- Begin your free trial and see how easy it is to get started with Couchbase
- Find out more about Capella and watch the demo video
- Dig into more Couchbase videos on our YouTube channel
Leave a comment
You must be logged in to post a comment.