O Couchbase melhora ainda mais a alta disponibilidade para implementações de missão crítica e reduz a intervenção do operador. O Couchbase aprimora a detecção de falhas comuns de disco e faz o failover automático do nó com discos defeituosos, economizando tempo e energia dos operadores. Ele também lida com várias falhas de servidor com base na contagem de réplicas para evitar a perda de dados e pode fazer o failover de um grupo inteiro de servidores se um rack ou zona não estiver disponível.
Os usuários agora podem configurar o failover automático para disco, vários nós e todo o grupo de servidores (rack-zone) em Servidor Couchbase 5.5.
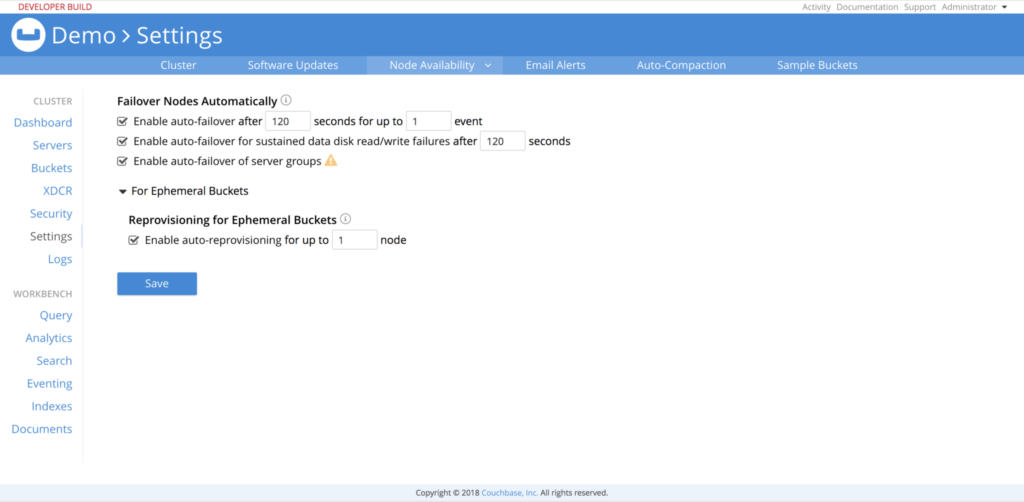
Vamos dar uma olhada em cada um desses aprimoramentos em detalhes.
Auto-FailOver em problemas de disco
Antes do Couchbase Server 5.5, o gerenciador de cluster não fazia failover automaticamente quando encontrava problemas relacionados ao disco em um nó. O nó continuava a operar por algum tempo, até ficar sem memória ou encontrar algum outro problema.
No entanto, o gerenciador de cluster tem alertas integrados para "quando a falha do disco é detectada durante a persistência dos dados no disco" e "O espaço em disco usado para armazenamento persistente atingiu pelo menos 90% de capacidade".

No Couchbase Server 5.5, os usuários poderão definir as seguintes configurações nas Configurações de disponibilidade do nó no Console da Web do Couchbase ou por meio da API CLI/REST.
-
- Ativar o failover automático para falhas contínuas de leitura/gravação no disco de dados
- Habilite o failover automático do nó para ativar esse recurso
- Ele estará desativado por padrão.
- O período de tempo em segundos
- O mínimo pode ser definido como 5 segundos, o máximo como 3600 segundos e o padrão é 120 segundos.
- Ativar o failover automático para falhas contínuas de leitura/gravação no disco de dados
Como isso funciona?
O gerenciador de cluster do Couchbase continua monitorando duas estatísticas
- Número de falhas ao tentar gravar itens no disco.
- Número de falhas durante a tentativa de leitura de um disco.
Se essa estatística continuar a aumentar durante o tempo limite do failover automático e a opção "failover automático em problemas de disco" estiver ativada, o gerenciador de cluster fará o failover automático do nó.
As estatísticas acima estão disponíveis na página Estatísticas como -
- Falhas de leitura de disco do #
- Falhas de gravação de disco do #
Observação - É possível que uma estatística aumente e a outra não. Por exemplo, quando o disco estiver cheio, as gravações falharão, fazendo com que as "falhas de gravação" aumentem, mas as leituras ainda poderão ser feitas.
Auto-FailOver em mais de um nó
Antes do Couchbase Server 5.5, a contagem de failover automático ou a cota era definida como 1, ou seja, apenas um nó pode sofrer failover automático antes de exigir intervenção do usuário. Essa era uma restrição para evitar uma falha de reação em cadeia de vários ou de todos os nós do cluster.
No entanto, o gerenciador de cluster forneceu o alerta interno "Node was auto-failed-over" no primeiro nó e "O número máximo de nós com falha automática foi atingido".

No Couchbase Server 5.5, os usuários poderão configurar o failover de várias instâncias se todos os buckets no cluster estiverem configurados com > 1 réplica, caso em que o máximo de 3 instâncias poderá sofrer failover automaticamente sem exigindo intervenção manual, como a redefinição da cota de failover automático.
Os usuários agora podem configurar as seguintes configurações nas Configurações de disponibilidade do nó no Console da Web do Couchbase ou por meio da API CLI/REST.
-
- Ativar o failover automático para até 1 evento padrão e um máximo de 3 eventos
- Isso ativará o recurso e poderá ser ativado somente quando o failover automático estiver ativado.
- Ele estará desativado por padrão.
- O período de tempo em segundos
- O mínimo pode ser definido como 5 segundos, o máximo como 3600 segundos e o padrão é 120 segundos.
- Pode ser editado pelo usuário a qualquer momento
- Ativar o failover automático para até 1 evento padrão e um máximo de 3 eventos
Como isso funciona?
O gerenciador de cluster valida o número de réplicas configuradas para todos os compartimentos no cluster. No caso de diferentes compartimentos com diferentes réplicas configuradas, o gerenciador de cluster considerará apenas as réplicas máximas configuradas em todos os compartimentos.
Por exemplo, se um cluster tiver
-
- um bucket com 1 réplica e outro com 2 réplicas e, em seguida, permitir o failover automático de até apenas 1 nó.
- dois buckets com 2 réplicas e, em seguida, permitir o failover automático de até 2 nós.
- três buckets com 2 réplicas, 2 réplicas e 3 réplicas configuradas e, em seguida, permitir o failover automático de até 2 nós.
A cota máxima de failover automático se aplica a todos os nós do cluster, incluindo os nós de dados, consulta, índice e pesquisa.
Se dois ou mais nós falharem exatamente ao mesmo tempo, o failover automático não funcionará (independentemente da contagem máxima definida pelo usuário), com exceção do failover automático do grupo de servidores discutido posteriormente. Essa restrição está em vigor para evitar que uma partição de rede faça com que duas ou mais metades de um cluster falhem uma na outra. Ela protege a integridade e a consistência dos dados.
Observação - Quando vários nós falham, isso aumenta a carga no cluster. Os usuários que desejam permitir o failover automático de mais de um nó precisam se certificar de que têm capacidade suficiente para lidar com as falhas.
Grupos de servidores Auto-FailOver (reconhecimento de zona de rack)
O Rack-Zone Awareness permite agrupamentos lógicos de servidores em um cluster em que cada grupo de servidores pertence fisicamente a um rack ou zona de disponibilidade.
No Couchbase Server 5.5, os usuários poderão definir as seguintes configurações nas Configurações de disponibilidade do nó no Console da Web do Couchbase ou por meio da API CLI/REST.
- Ativar o failover automático de grupos de servidores
- Habilite o failover automático do nó para ativar esse recurso
- Será desligado por padrão.
Como isso funciona?
Para que o failover automático de grupos de servidores funcione -
- Os clusters exigem um mínimo de 3 grupos de servidores no momento da falha. Essa restrição é necessária porque, se houver apenas dois grupos de servidores e houver uma partição de rede entre eles, os dois grupos de servidores poderão tentar fazer failover um do outro.
- Todos os nós do grupo de servidores falharam. Isso indica uma falha correlacionada que provavelmente afetou toda a zona ou o rack.
- Todos os nós com falha pertencem ao mesmo grupo de servidores. Isso evita que uma partição de rede faça com que duas ou mais metades de um cluster falhem uma na outra.
Recursos adicionais
- Faça o download do Couchbase Server 5.5
- Documentação do Couchbase Server 5.5
- Contêiner do Docker do servidor Couchbase 5.5
- Compartilhe suas ideias sobre o Fóruns do Couchbase
Quando estamos fazendo failover automático em mais de um nó. Estamos verificando o mínimo denominador comum da contagem de réplicas e, com base nisso, podemos fazer esse número de failovers de nós?