A matriz é O diferença entre o modelo relacional e o modelo JSON. - Gerald Sangudi
Resumo
A matriz JSON oferece flexibilidade quanto ao tipo de elementos, ao número de elementos, ao tamanho dos elementos e à profundidade dos elementos. Isso aumenta a flexibilidade dos bancos de dados JSON operacionais, como o Couchbase e o MongoDB. O desempenho de consultas com um predicado de matriz em bancos de dados operacionais depende dos índices de matriz. No entanto, os índices de matriz nesses bancos de dados vêm com limitações. Por exemplo, somente uma chave de matriz é permitida por índice. Os índices de matriz, mesmo quando criados, só podem processar predicados AND com eficiência. A próxima versão do Couchbase 6.6 remove essas limitações do JSON usando um índice invertido integrado para ser usado para indexar e consultar arrays no N1QL. Este artigo explica o histórico e o funcionamento dessa nova implementação.
Introdução
Uma matriz é um tipo básico incorporado ao JSON definido como Um matriz é uma coleção ordenada de valores. Uma matriz começa com [suporte esquerdo e termina com ]suporte direito. Os valores são separados por ,vírgula. Uma matriz lhe dá flexibilidade porque pode conter um número arbitrário de valores escalares, vetoriais e de objetos. Um perfil de usuário pode ter um array de hobbies, um perfil de cliente um array de carros, um perfil de membro um array de amigos. O Couchbase N1QL fornece um conjunto rico de operadores para manipular matrizes; o MongoDB tem uma lista de operadores para lidar com matrizes também.
Antes de começar a consultar, você precisa modelar seus dados em matrizes. Todos os bancos de dados de documentos JSON, como o Couchbase e o MongoDB, recomendam que você desnormalize seu modelo de dados para melhorar o desempenho e o desenvolvimento de aplicativos. Isso significa que você deve transformar sua relação 1:N em um único documento, incorporando o N em 1. No JSON, você faria isso usando uma matriz. No exemplo abaixo, o documento (1) contém 8 (N) curtidas. Em vez de armazenar uma referência de chave estrangeira para outra tabela, no JSON, armazenamos dados em linha.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
"public_likes": [ "Julius Tromp I", "Corrine Hilll", "Jaeden McKenzie", "Vallie Ryan", "Brian Kilback", "Lilian McLaughlin", "Sra. Moses Feeney", "Elnora Trantow" ], |
Os valores aqui são matrizes de strings. Em JSON, cada elemento pode ser de qualquer tipo válido de JSON: escalares (numérico, cadeia de caracteres etc.), objetos ou vetores (matrizes). Cada documento de hotel contém uma matriz de avaliações. Esse é o processo de desnormalização. Conversão de várias relações 1:N em um único objeto de hotel que contém N public_likes e M avaliações. Com isso, o objeto hotel incorpora duas matrizes: public_likes e avaliações. Pode haver qualquer número de valores de qualquer tipo nessas matrizes. Esse é o principal fator que contribui para a flexibilidade do esquema JSON. Quando você precisar adicionar novas curtidas ou avaliações, basta adicionar um novo valor ou um objeto a esse array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
"avaliações": [ { "autor": "Ozella Sipes", "content" (conteúdo): "Esta foi nossa segunda viagem aqui...", "data": "2013-06-22 18:33:50 +0300", "classificações": { "Limpeza": 5, "Localização": 4, "Geral": 4, "Quartos": 3, "Serviço": 5, "Valor": 4 } }, { "autor": "Barton Marks", "content" (conteúdo): "Encontramos o hotel ...", "data": "2015-03-02 19:56:13 +0300", "classificações": { "Serviço comercial (por exemplo, acesso à Internet)": 4, "Check-in / recepção": 4, "Limpeza": 4, "Localização": 4, "Geral": 4, "Quartos": 3, "Serviço": 3, "Valor": 5 } } ], |
Assim como o objeto hotel acima, você desnormaliza seu modelo de dados em JSON, podendo haver muitas matrizes para cada objeto. Os perfis têm matrizes para hobbies, carros, cartões de crédito, preferências etc. Cada uma dessas matrizes pode ser escalar (valores numéricos/string/booleanos simples) ou vetorial (matrizes de outras escalares, matrizes de objetos etc.).
Depois de modelar e armazenar os dados, você precisa processá-los - selecionar, unir, projetar. Couchbase N1QL (SQL para JSON) oferece uma linguagem expressiva para fazer isso e muito mais. Veja a seguir os casos de uso comuns.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
1. Localizar todos o documentos com a simples valor pode ser feito por ou de o seguintes consultas. SELECIONAR * DE `viagem-amostra ONDE tipo = "hotel" E QUALQUER p IN public_likes SATISFAÇÕES p = "Vallie Ryan" FIM SELECIONAR t DE `viagem-amostra t INÚTIL t.public_likes AS p ONDE t.tipo = "hotel" E p = "Vallie Ryan" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
2. Localizar todos o documentos que partida a alcance. Em este caso, nós tentar para encontrar todos o documentos que ter pelo menos um classificação tem "Geral" > 4 SELECT COUNT(1) DE `viagem-amostra ONDE tipo = "hotel" E QUALQUER r IN revisões SATISFAÇÕES r.ratings.Overall > 4 FIM SELECT COUNT(1) DE `viagem-amostra t INÚTIL revisões AS r ONDE t.tipo = "hotel" E r.ratings.Overall > 4 GRUPO BY t.tipo |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
3. Localizar todos o documentos onde todos classificação para "Geral" > 4 SELECT * DE `viagens-amostra` ONDE tipo = 'hotel' E QUALQUER E TODOS r em revisões SATISFAÇÕES r.Geral > 4 FIM SELECIONAR CONTAGEM(1) DE `viagens-amostra` ONDE tipo = "hotel" E QUALQUER E TODOS r IN revisões SATISFAÇÕES r.classificações.Geral > 4 FIM SELECIONAR revisões[*].classificações[*].Geral DE `viagens-amostra` ONDE tipo = "hotel" E QUALQUER E TODOS r IN revisões SATISFAÇÕES r.classificações.Geral > 4 FIM limite 10; [ { "Geral": [ 5 ], "name" (nome): "A cabeça do touro" }, { "Geral": [ 5, 5, 5, 5, 5 ], "name" (nome): "La Pradella" }, { "Geral": [ 5, 5, 5 ], "name" (nome): "Culloden House Hotel" }, { "Geral": [ 5 ], "name" (nome): "Auberge-Camping Bagatelle" }, { "Geral": [ 5, 5 ], "name" (nome): "Avignon Hotel Monclar" } ] |
Indexação de matrizes:
As matrizes de indexação são um desafio para os índices baseados em árvore B. No entanto, o banco de dados JSON precisa fazer isso para atender aos requisitos de desempenho: O MongoDB faz isso; O Couchbase faz isso. No entanto, ambos têm limitações. Você só pode ter uma chave de matriz em um índice. Isso é verdadeiro do MongoDBIsto é verdadeiro do Couchbase N1QL. O principal motivo dessa limitação é que, quando você indexa elementos de uma matriz, precisa de entradas de índice separadas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
Considere o matriz: Documento chave: "bob" { "Id": "bob123" "A": [1, 2, 3, 4] "B": [521, 4892, 284] } Indexação de o campo "id" simplesmente requer 1 entrada em o índice: "bob123":bob Indexação de o campo "a" requer 4 entradas em o índice: "1":"bob", 2:"bob", 3:"bob", 4:"bob" Indexação de o composto índice (id, a) requer 4 entradas: "bob123", 1: bob "bob123", 2: bob "bob123", 3: bob "bob123", 4: bob Indexação de o composto índice (id, a, b) requer o seguintes 12 entradas: "bob123", 1, 521: bob "bob123", 1,4982: bob "bob123", 1, 284: bob "bob123", 2, 521: bob "bob123", 2,4982: bob "bob123", 2, 284: bob "bob123", 3, 521: bob "bob123", 3,4982: bob "bob123", 3, 284: bob "bob123", 4, 521: bob "bob123", 4,4982: bob "bob123", 4, 284: bob |
O tamanho do índice cresce exponencialmente conforme o número de chaves da matriz no índice e o número de elementos da matriz no índice. Daí a limitação. As implicações dessa limitação são:
- Empurre apenas um predicado de matriz para a varredura de índice e trate os outros predicados após a varredura de índice.
- Isso significa que as consultas com vários predicados de matriz podem ser lentas
- Evite índices compostos com chaves de matriz para evitar índices enormes.
- Isso significa que as consultas com predicados complexos em chaves de matriz serão lentas
Boas notícias do CAMPO ESQUERDO.
O índice de pesquisa de texto completo foi projetado para lidar com a pesquisa de padrões de texto com base na relevância. Isso é feito por meio da tokenização de cada campo. No exemplo abaixo, cada documento é analisado para obter tokens:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
"doc:1"->"desc": {"desc": "e appel a dia, mantém o médico longe."} "doc:2"->"desc": {"desc":"e appel a dia, mantém Projeto de lei Portões longe."} "doc:3"->"desc": {"desc": "e maçã a dia, mantém o maçã agricultor rico."} "doc:1"->"desc": ["maçã", "dia", "manter", "médico", "longe"] "doc:2"->"desc": ["maçã", "dia", "manter", "conta", "portões", "longe"] "doc:3"->"desc": ["maçã", "dia", "manter", "agricultor", "rico"] Isso então é combinados para obter a único matriz de tokens: ["maçã", "longe", "conta", "dia", "médico", "agricultor", "portões", "manter", "rico"] |
Para cada token, ele mantém a lista de documentos em que o token está presente. Essa é a estrutura de árvore invertida! Ao contrário de um índice baseado em árvore B, ele evita repetir o mesmo valor de token um número N de vezes, um para cada documento em que ele está presente. Quando se tem milhões ou bilhões de documentos, isso representa uma enorme economia.
O segundo aspecto a ser observado aqui é que o índice invertido usado para um conjunto de tokens! De fato, a estrutura de árvore invertida na pesquisa de texto completo é ideal para indexação e pesquisa de valores de matriz, especialmente quando esses valores têm duplicatas.
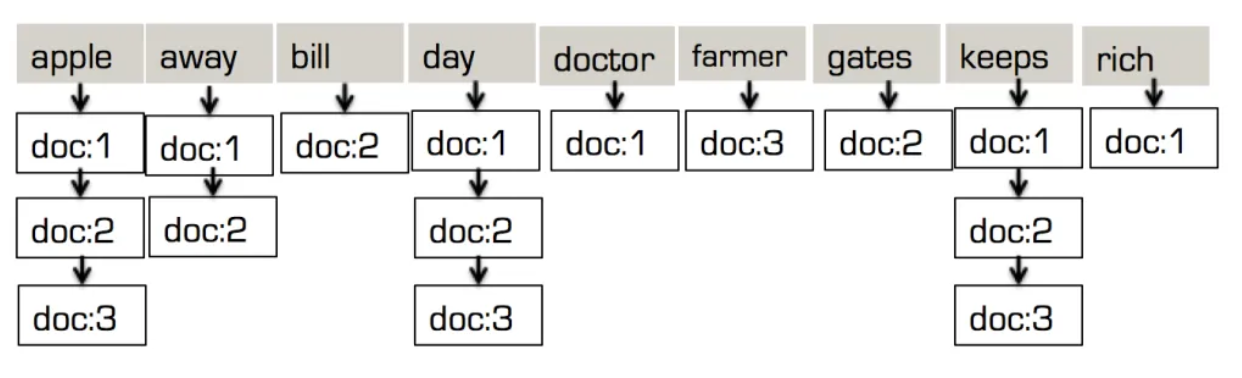
A indexação de matrizes usando o índice invertido será o mesmo processo, exceto pelo fato de não haver tokenização. Vamos revisitar a indexação do nosso documento "bob", com documentos adicionais, "Sam" e "Neill"
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Documento chave: "bob" { id": "bob123" "a": [1, 2, 3, 4] "b": [521, 4892, 284] } Documento chave: "sam" { "id": "sam456" "a": [1,3, 4, 9] "b": [521, 232, 284] } Documento chave: "neil" { "id": "neil987" "A"[1, 2, 4, 6] "b": [521, 4892, 543] } |
O Couchbase FTS tem um analisador chamado analisador de palavras-chave. Isso indexa os valores no estado em que se encontram, em vez de tentar encontrar sua raiz por meio de stemização. Basicamente, o valor é o token. Para indexação de valores de matriz, podemos usar esse índice e explorar as eficiências de um índice invertido. Vamos construir um índice FTS nos documentos bob, sam, neil. No caso da árvore invertida, cada campo recebe sua própria árvore invertida: uma para id, a e b. Como essas árvores são individuais, elas não crescem exponencialmente como o índice composto da árvore B. O número de entradas de índice é proporcional ao número de itens exclusivos em cada campo. Nesse caso, temos 14 entradas para os 3 documentos com três campos de um total de 24 valores. A criação de um índice de árvore B em (id, a, b) para o mesmo documento criará 36 inscrições!
Observe que, para três documentos com duas entradas de índice, a diferença é de 157%. À medida que o número de documentos e o número de matrizes aumentam, a economia com o uso de um índice invertido também aumenta.
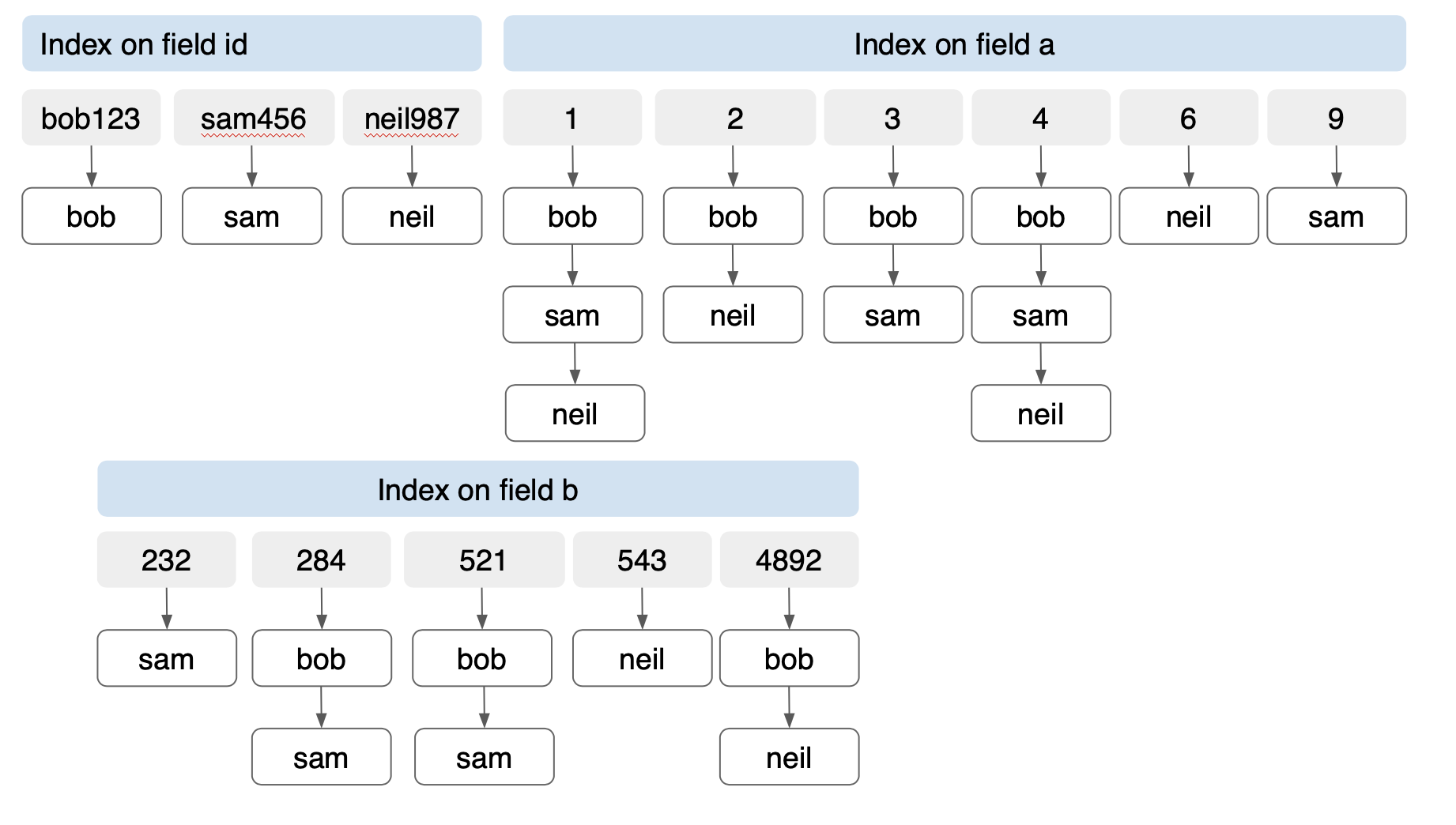
Índice invertido em três campos.
No entanto, temos um problema. Como você processa os predicados?
|
1 2 3 4 5 6 7 |
ONDE id entre "ada" e "tate" E QUALQUER x IN a SATISFAÇÕES x = 3 FIM E QUALQUER y em b SATISFAÇÕES y = 521 FIM |
O índice B-Tree armazena todos os valores em (id, a e b) juntos, enquanto o índice invertido no FTS tem árvores distintas para cada campo. Portanto, aplicar vários predicados não é tão fácil. Isso se aplica ao nosso processamento de matriz, bem como ao processamento de texto. É comum no processamento de texto fazer perguntas como: search for all Californiano residentes com esqui como seus hobby.
Para processar isso, o FTS aplica o predicado em cada campo individualmente para obter a lista de chaves de documento para cada predicado. Em seguida, ele aplica o predicado booleano E em cima dela. Essa camada usa o famoso pacote de bitmap roaring para criar e processar o bitmap de ids de documentos para finalizar o resultado. Sim, há um processamento extra aqui em comparação com um índice mais simples baseado em B-TREE, mas isso torna possível indexar muitas matrizes e processar a consulta em um tempo razoável.

Árvore invertida: Uma árvore que continua presenteando!
O índice composto B-Tree combina a varredura e a aplicação do predicado AND. A abordagem de árvore invertida separa os dois. O índice e a varredura de cada campo são diferentes do processamento do predicado composto. Devido a essa separação, a camada de bitmap pode processar predicados OR, NOT juntamente com predicados AND. Alterar o AND no exemplo anterior para OR é simplesmente uma instrução para o processamento de bitmap na qualificação e deduplicação do documento
|
1 2 3 4 5 6 7 |
ONDE id ENTRE "ada" E "tate" OU QUALQUER x IN a SATISFAÇÕES x = 3 FIM OU QUALQUER y em b SATISFAÇÕES y = 521 FIM<b></b> |
Lançamento do COUCHBASE:
O Couchbase 6.6 oferecerá suporte ao uso de índices FTS para processar predicados de matriz complexos. Isso melhora o custo total de propriedade do manuseio de matrizes e permite que os desenvolvedores e designers usem, indexem e consultem matrizes conforme necessário, sem limitações. Aguarde os próximos anúncios, documentação, blogs de recursos, etc.
Referências
- Trabalhando com matrizes JSON no N1QL
- Utilização de matrizes: Modelagem, consulta e indexação
- Operadores de coleção N1QL do Couchbase
- MongoDB: Consultar um array
- Couchbase FTS
- GRÁTIS: Treinamento interativo do Couchbase
- FTS BLogs: https://www.couchbase.com/blog/tag/fts/
- Operadores de coleta
- Indexação ARRAY
- Aproveitando ao máximo suas matrizes... com a indexação de matrizes N1QL
- Aproveitamento máximo de suas matrizes com índices de matrizes de cobertura e muito mais.
- Indexação do Couchbase
- NEST e UNNEST: normalização e desnormalização de JSON em tempo real