Agrupamento agregado é o título desta postagem do blog, mas não sei se é o melhor nome. Você já usou a função Função GROUP_CONCAT ou o PARA XML PATH('') solução alternativa no SQL Server? É basicamente sobre isso que estou escrevendo hoje. Com o Couchbase Server, a maneira mais fácil de fazer isso é com a função N1QL ARRAY_AGG mas você também pode fazer isso com uma visualização antiga do MapReduce.
Estou escrevendo este post porque um de nossos engenheiros de soluções estava trabalhando nesse problema para um cliente (que não terá seu nome revelado). Nenhum de nós conseguiu encontrar uma postagem de blog como esta com a resposta, portanto, depois de trabalharmos juntos para chegar a uma solução, decidi que escreveria sobre ela para o meu futuro eu (que é praticamente o principal motivo pelo qual escrevo qualquer coisa, na verdade. O outro motivo é descobrir se mais alguém conhece uma maneira melhor).
Antes de começarmos, disponibilizei algum material se você quiser acompanhar o processo. O código-fonte que usei para gerar os dados do "paciente" usados nesta postagem está disponível no GitHub. Se você não tiver conhecimento de .NET, poderá usar apenas cbimport em dados de amostra que eu criei. (Ou você pode usar o Área restrita N1QLmais informações sobre isso mais tarde). O restante desta postagem do blog pressupõe que você tenha um bucket de "pacientes" com esses dados de amostra.
Requisitos
Tenho um conjunto de documentos de pacientes. Cada paciente tem um único médico. O documento do paciente se refere a um médico por um campo chamado doctorId. Pode haver outros dados no documento do paciente, mas nosso foco principal é a chave do documento do paciente e o doctorId valor. Alguns exemplos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
key 01257721 { "doctorId": 58, "patientName": "Robyn Kirby", "patientDob": "1986-05-16T19:01:52.4075881-04:00" } key 116wmq8i { "doctorId": 8, "patientName": "Helen Clark", "patientDob": "2016-02-01T04:54:30.3505879-05:00" } |
Em seguida, podemos presumir que cada médico pode ter vários pacientes. Também podemos presumir que existe um documento do médico, mas não precisamos disso para este tutorial, portanto, vamos nos concentrar apenas nos pacientes por enquanto.
Por fim, o que queremos para o nosso aplicativo (ou relatório ou qualquer outro) é um agrupamento agregado dos pacientes com seus médicos. Cada registro identificaria um médico e uma lista/array/coleção de pacientes. Algo como:
| médico | pacientes |
|---|---|
|
58 |
01257721, 450mkkri, 8g2mrze2 ... |
|
8 |
05woknfk, 116wmq8i, 2t5yttqi ... |
|
... etc ... |
... etc ... |
Isso pode ser útil para um painel que mostre todos os pacientes atribuídos a médicos, por exemplo. Como podemos obter os dados nesse formato, com o N1QL ou com o MapReduce?
N1QL Agrupamento agregado
N1QL nos dá o ARRAY_AGG função para tornar isso possível.
Comece selecionando o doctorId de cada documento do paciente e a chave do documento do paciente. Em seguida, aplique ARRAY_AGG para o ID do documento do paciente. Por fim, agrupe os resultados pelo doctorId.
|
1 2 3 |
SELECT p.doctorId AS doctor, ARRAY_AGG(META(p).id) AS patients FROM patients p GROUP BY p.doctorId; |
Observação: não se esqueça de executar CREATE PRIMARY INDEX ON patients (criar índice primário em pacientes) para que este tutorial ative uma varredura de índice primário.
Imagine essa consulta sem o ARRAY_AGG. Ele retornaria um registro para cada paciente. Ao adicionar o ARRAY_AGG e o GRUPO PORele agora retorna um registro para cada médico.
Aqui está um trecho dos resultados do conjunto de dados de amostra que criei:
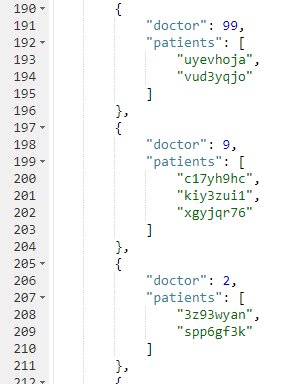
Se não quiser se dar ao trabalho de criar um bucket e importar dados de amostra, você também pode tentar isso no Sandbox do tutorial N1QL. Não há documentos de pacientes lá, portanto, a consulta será um pouco diferente.
Vou agrupar os e-mails por idade. Comece selecionando a idade de cada documento e o e-mail de cada documento. Em seguida, aplique ARRAY_AGG para o e-mail. Por fim, agrupe os resultados por idade.
|
1 2 3 |
SELECT t.age AS age, ARRAY_AGG(t.email) AS emails FROM tutorial t group by t.age; |
Aqui está uma captura de tela de alguns dos resultados da área restrita:

Grupo agregado com MapReduce
Um agrupamento agregado semelhante também pode ser obtido com uma visualização do MapReduce.
Comece criando uma nova visualização. No Console do Couchbase, vá para Índices e depois para Visualizações. Selecione o bucket "patients" (pacientes). Clique em "Create Development View" (Criar visualização de desenvolvimento). Nomeie um documento de design (chamei o meu de "_design/dev_patient"). Crie uma visualização, chamei a minha de "doctorPatientGroup".
Precisaremos de um Map e de uma função Reduce personalizada.
Primeiro, para o mapa, queremos apenas o doctorId (em uma matriz, já que usaremos agrupamento) e o ID do documento do paciente.
|
1 2 3 |
function (doc, meta) { emit([doc.doctorId], meta.id); } |
Em seguida, para a função reduce, pegaremos os valores e os concatenaremos em uma matriz. Abaixo está uma maneira de fazer isso. Não tenho a pretensão de ser um especialista em JavaScript ou em MapReduce, portanto, pode haver uma maneira mais eficiente de lidar com isso:
|
1 2 3 4 |
function reduce(key, values, rereduce) { var merged = [].concat.apply([], values); return merged; } |
Depois de criar as funções map e reduce, salve o índice.
Por fim, ao chamar esse índice, defina group_level como 1. Você pode fazer isso na interface do usuário:
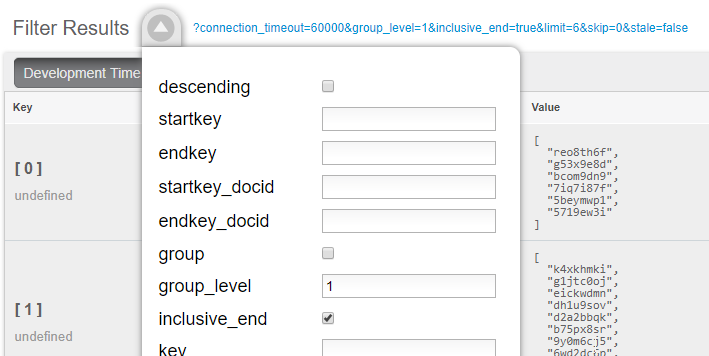
Ou você pode fazer isso a partir do URL do índice. Aqui está um exemplo de um cluster em execução em minha máquina local:
|
1 |
https://127.0.0.1:8092/patients/_design/dev_patients/_view/doctorPatientGroup?connection_timeout=60000&full_set=true&group_level=1&inclusive_end=true&skip=0&stale=false |
O resultado dessa exibição deve ser semelhante a este (truncado para ficar mais bonito em uma postagem de blog):
|
1 2 3 4 5 6 7 8 9 |
{"rows":[ {"key":[0],"value":["reo8th6f","g53x9e8d", ... ]}, {"key":[1],"value":["k4xkhmki","g1jtc0oj", ... ]}, {"key":[2],"value":["spp6gf3k","3z93wyan"]}, {"key":[3],"value":["qnx93fh3","gssusiun", ...]}, {"key":[4],"value":["qvqgb0ve","jm0g69zz", ...]}, {"key":[5],"value":["ywjfvad6","so4uznxx", ...]} ... ]} |
Resumo
Acho que o método N1QL é mais fácil, mas pode haver benefícios de desempenho ao usar o MapReduce em alguns casos. Em ambos os casos, é possível realizar o agrupamento agregado com a mesma facilidade (se não mais) que em um banco de dados relacional.
Interessado em saber mais sobre o N1QL? Não deixe de dar uma olhada na seção tutorial/sandbox completo do N1QL. Interessado em visualizações de MapReduce? Dê uma olhada na seção Documentação das visualizações do MapReduce para começar.
Você achou esta postagem útil? Tem sugestões para melhorar? Deixe um comentário abaixo ou entre em contato comigo em Twitter @mgroves.