Os clientes usam XDCR para vários casos de uso, desde alta disponibilidade até localidade de dados, recuperação de desastres e migração para a nuvem e implantações de nuvem híbrida. Para atender a esses casos de uso, há várias circunstâncias em que se deseja replicar apenas um subconjunto de dados para um cluster diferente. Introduzimos a filtragem baseada em chaves há alguns anos para permitir a replicação filtrada. Com a versão 6.5, estamos ampliando essa funcionalidade para oferecer recursos avançados de filtragem com o XDCR. chaves, valores e metadados usando uma sintaxe semelhante à do N1QL, na qual você pode construir expressões de filtro para filtrar dados com base em sua lógica comercial.
A filtragem avançada oferece a capacidade de filtrar a replicação em duas categorias diferentes:
a. Filtragem baseada em expressões
As expressões de filtro são aplicadas aos dados do intervalo de origem. A filtragem avançada oferece suporte a várias construções de linguagem para criar filtros, como regex, operadores aritméticos, lógicos e relacionais, palavras-chave, expressões, funções numéricas, funções de data, lookahead negativo etc., em chaves, valores, metadados e CAS. Assim como o predicado das consultas N1QL, as expressões podem ser construídas usando as construções de linguagem compatíveis.
Acreditamos que essa filtragem baseada em expressões é extremamente útil para filtrar dados por meio da construção de expressões relevantes para a necessidade comercial, como casos de uso de cercas geográficas.
Abaixo mencionado está o campo em que você insere a expressão e o ID do documento para testar a expressão do filtro
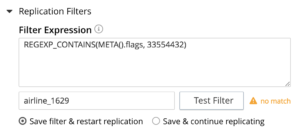
Depois de ter uma expressão de filtro, você pode testar a expressão especificando o ID do documento no campo mencionado acima. Se o documento específico corresponder à expressão do filtro, você será notificado. Caso contrário, você poderá usar outro ID de documento para validar. O objetivo aqui é fornecer uma validação básica para sua expressão. Se a expressão não corresponder, você será notificado de que não corresponde. Você pode modificar o filtro ou usar um ID de documento diferente para validar o filtro.
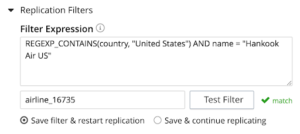
Se a expressão corresponder ao filtro, você será notificado sobre a correspondência, que é uma validação para a expressão do filtro.
Edição de expressão de filtro
Os filtros também podem ser editados em tempo real e a replicação continuará sem nenhuma pausa/retomada.
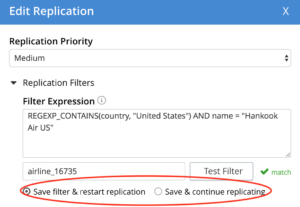
Depois que o filtro é editado, os clientes podem optar por reiniciar a replicação ou continuar a replicar sem reiniciar. O padrão é reiniciar a replicação.
O XDCR, por padrão, não descarregará nenhum compartimento quando os filtros forem modificados. Essa etapa deve ser executada manualmente pelo administrador, se necessário.
b. Filtragem de exclusão
Por padrão, o XDCR replica tudo, inclusive as exclusões, para manter a consistência. Com a filtragem avançada na versão 6.5, estamos oferecendo a capacidade de replicar filtrando exclusões/documentos com TTL ou eliminar os TTLs e a replicação para que os documentos de destino não tenham TTL. Você também pode optar por remover o TTL dos documentos e replicá-los.
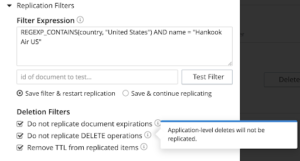
Esse recurso abre portas para novos casos de uso do XDCR, como um cluster quente e frio em que você deseja replicar apenas documentos ativos ou remover TTL e armazená-los para fins de arquivamento.
Se a sua versão do Couchbase for inferior a 6.5, você poderá filtrar apenas com base nas chaves.
Se estiver usando a versão 6.5 ou superior, você poderá filtrar com base em chaves, valores, metadados estendidos ou uma combinação dos três.
Ao replicar somente o que é necessário, os clientes podem ter uma melhor utilização dos recursos em termos de largura de banda, armazenamento e desempenho.
Recursos
Baixar
Faça o download do Couchbase Server 6.5
Documentação
Notas de versão do Couchbase Server 6.5
Couchbase Server 6.5 O que há de novo
Blogs
Blog: Anunciando o Couchbase Server 6.5 - O que há de novo e aprimorado
Blog: O Couchbase traz as transações ACID multi-documento distribuídas para o NoSQL
Oi Chaitra,
Você mencionou "Default is réplication restart". O que isso significa exatamente?
Agradecimentos