Customers use XDCR for various use cases from high availability to data locality to disaster recovery to cloud migration and hybrid cloud deployments. To meet these use cases, there are a number of circumstances where they would want to replicate only a subset of data to a different cluster. We introduced key based filtering a couple years ago to enable filtered replication. With 6.5, we are extending this functionality to provide advanced filtering capabilities with XDCR.This feature allows filtering based on keys, values and metadata using N1QL like syntax where you can construct filter expressions to filter data based on your business logic.
Advanced filtering is providing the ability to filter replication in two different categories:
a.Expression based filtering
Filter expressions are applied to the source bucket data. Advanced filtering supports various language constructs to build filters such as regex, arithmetic, logical and relational operators, keywords, expressions, number Functions, date functions, negative lookahead etc., on keys, values, metadata and CAS. Just like predicate of N1QL queries, expressions can be constructed using the supported language constructs.
These expressions based filtering we believe is extremely useful for filtering data by constructing expressions relevant to the business need such as geo-fencing use cases.
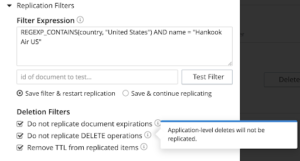
Below mentioned is the field where you enter the expression and the document ID to test the filter expression
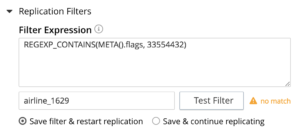
Once you have a filter expression, you can test the expression by specifying the document ID in the above mentioned field. If the particular document matches the filter expression, you will be notified of the same. If not, you can use another document ID to validate. The purpose here is to provide a basic validation for your expression.If the expression is not a match, you will be notified of not matching. You can modify the filter or use a different document id to validate the filter.
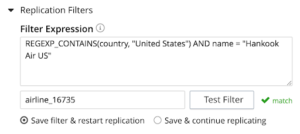
If the expression matches the filter, you will be notified of the match which is a validation for the filter expression.
Editing filter expression
The filters can also be edited on the fly and the replication will continue without any pause/resume.
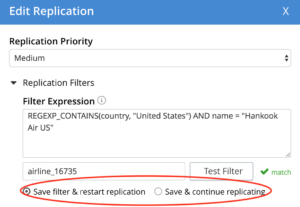
Once the filter is edited, the customers can choose to restart replication or continue to replicate without restart. Default is replication restart.
XDCR, by default, will not flush any buckets when filters are modified. This step should be manually executed by the administrator if necessary.
b. Deletion filtering
By design, XDCR replicates everything including deletes to maintain consistency. With advanced filtering in 6.5, we are providing the ability to replicate by filtering out deletes / documents with TTL or to eliminate the TTLs and replication so that the destination docs will not have TTL. You can also choose to strip the TTL from the documents and replicate them.
This capability opens doors to new use cases using XDCR, as a hot and cold cluster where you would want to replicate only active documents or remove TTL and store it for archival purposes.
If your version of Couchbase is less than 6.5, you will be able to filter only based on keys.
If you are using 6.5 or above, you can filter based on keys, values, extended metadata, or a combination of all three.
By replicating only what is necessary, customers can have better resource utilization in terms of bandwidth, storage and performance.
Resources
Download
Documentation
Couchbase Server 6.5 Release Notes
Couchbase Server 6.5 What’s New
Blogs
Blog: Announcing Couchbase Server 6.5 – What’s New and Improved
Blog: Couchbase brings Distributed Multi-document ACID Transactions to NoSQL
Hi Chaitra,
You mentioned “Default is réplication restart”. What exactly does that mean?
Thanks