Aaron Benton é um arquiteto experiente, especializado em soluções criativas para desenvolver aplicativos móveis inovadores. Ele tem mais de 10 anos de experiência em desenvolvimento de pilha completa, incluindo ColdFusion, SQL, NoSQL, JavaScript, HTML e CSS. Atualmente, Aaron é Arquiteto de Aplicativos da Shop.com em Greensboro, Carolina do Norte, e é um Campeão da comunidade do Couchbase.

FakeIt Série 4 de 5: Trabalhando com dados existentes
Até agora, em nosso Falsa vimos como podemos Gerar dados falsos, Compartilhar dados e dependênciase usar Definições para modelos menores. Hoje vamos examinar o último recurso importante da FakeIt, que é trabalhar com dados existentes por meio de entradas.
Raramente, como desenvolvedores, temos a vantagem de trabalhar em aplicativos novos, pois nossos domínios são, na maioria das vezes, compostos por diferentes bancos de dados e aplicativos legados. Como estamos modelando e criando novos aplicativos, precisamos fazer referência e usar esses dados existentes. Falsa permite que você forneça dados existentes aos seus modelos por meio de arquivos JSON, CSV ou CSON. Esses dados são expostos como uma variável de entrada em cada uma das funções *run e *build dos modelos.
Modelo de usuários
Começaremos com o nosso modelo users.yaml que atualizamos em nossa última atualização publicação recente para usar Endereço e Telefone definições.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 |
name: Users type: object key: _id data: min: 1000 max: 2000 properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: "`user_${this.user_id}`" doc_type: type: string description: The document type data: value: "user" user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() addresses: type: object description: An object containing the home and work addresses for the user properties: home: description: The users home address schema: $ref: '#/definitions/Address' work: description: The users work address schema: $ref: '#/definitions/Address' main_phone: description: The users main phone number schema: $ref: '#/definitions/Phone' data: post_build: | delete this.main_phone.type return this.main_phone additional_phones: type: array description: The users additional phone numbers items: $ref: '#/definitions/Phone' data: min: 1 max: 4 definitions: Phone: type: object properties: type: type: string description: The phone type data: build: faker.random.arrayElement([ 'Home', 'Work', 'Mobile', 'Other' ]) phone_number: type: string description: The phone number data: build: faker.phone.phoneNumber().replace(/[^0-9]+/g, '') extension: type: string description: The phone extension data: build: chance.bool({ likelihood: 30 }) ? chance.integer({ min: 1000, max: 9999 }) : null Address: type: object properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
Atualmente, nossos Endereço está gerando um país aleatório. E se o nosso site de comércio eletrônico oferecer suporte apenas a um pequeno subconjunto dos 195 países? Digamos que suportemos seis países para começar: US, CA, MX, UK, ES, DE. Poderíamos atualizar a propriedade country das definições para obter um elemento de matriz aleatório:
(Para fins de brevidade, as outras propriedades foram deixadas de fora da definição do modelo)
|
1 2 3 4 5 6 |
... country: type: string description: The country code data: build: faker.random.arrayElement(['US', 'CA', 'MX', 'UK', 'ES', 'DE']); |
Embora isso funcione, e se tivermos outros modelos que dependam dessas mesmas informações de país, teremos que duplicar essa lógica. Podemos fazer a mesma coisa criando um arquivo countries.json e adicionando uma propriedade inputs à propriedade data, que pode ser um caminho absoluto ou relativo para a nossa entrada. Quando o modelo for gerado, nosso arquivo countries.json será exposto a cada uma das funções de criação de modelos por meio do argumento inputs como inputs.countries
(Para fins de brevidade, as outras propriedades foram deixadas de fora da definição do modelo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Users type: object key: _id data: min: 1000 max: 2000 inputs: ./countries.json properties: ... definitions: ... country: type: string description: The country code data: build: faker.random.arrayElement(inputs.countries); countries.json [ "US", "CA", "MX", "UK", "ES", "DE" ] |
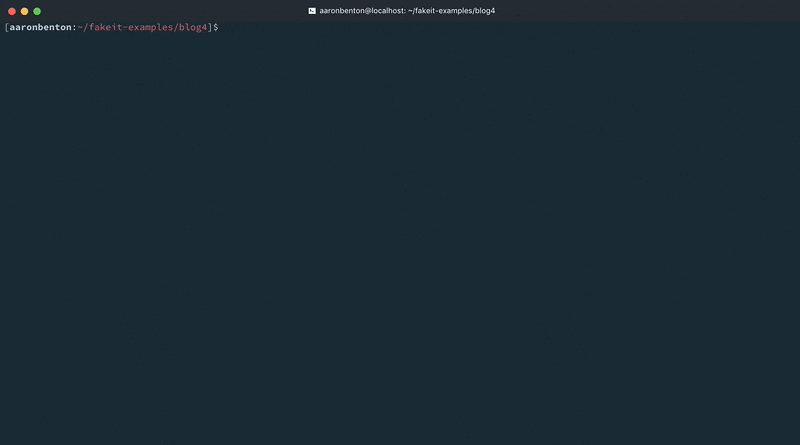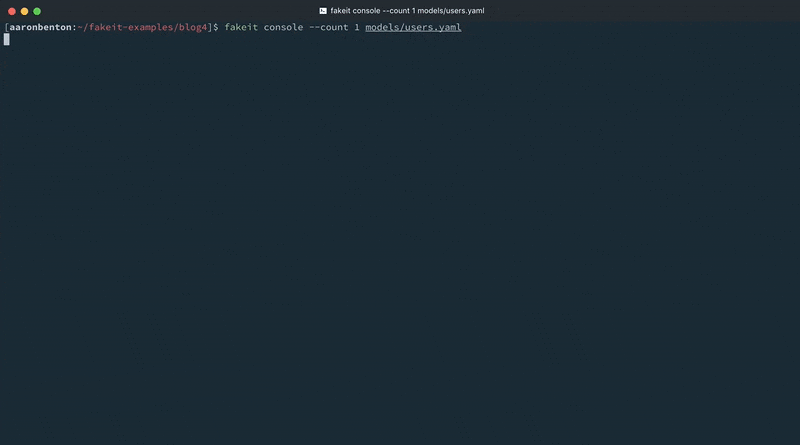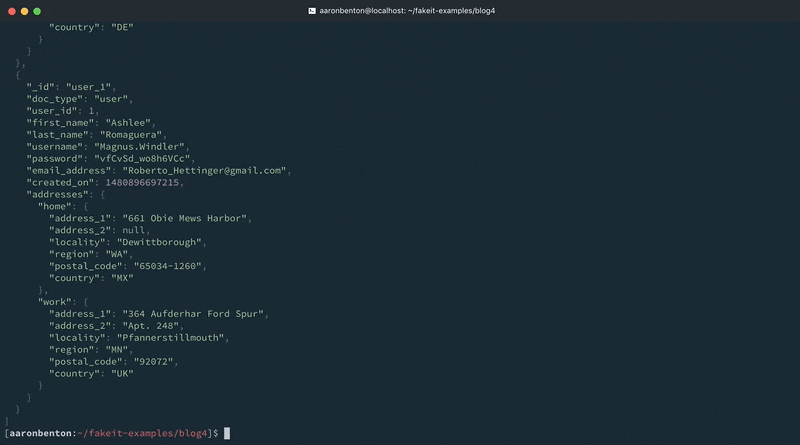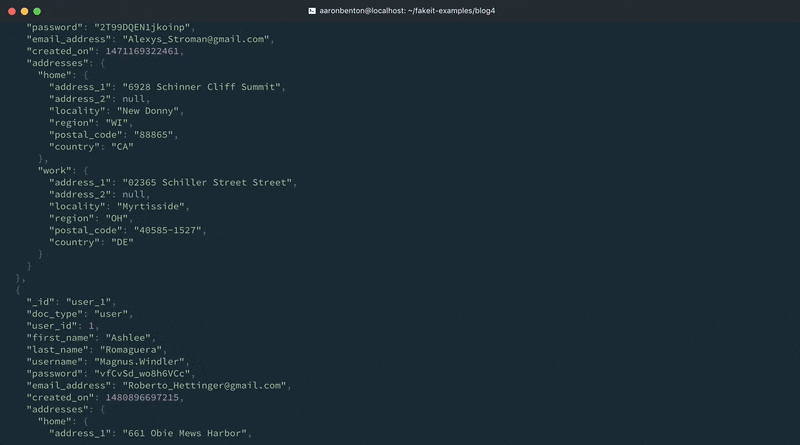
Ao alterar uma linha existente e adicionar outra linha no modelo, fornecemos dados existentes ao nosso modelo de Usuários. Ainda podemos gerar um país aleatório, com base nos países que nosso aplicativo suporta. Vamos testar nossas alterações usando o seguinte comando:
|
1 |
fakeit console --count 1 models/users.yaml |
Modelo de produtos
Nosso aplicativo de comércio eletrônico está usando um sistema separado para categorização. Precisamos expor esses dados aos nossos produtos gerados aleatoriamente para que possamos usar informações de categoria válidas. Começaremos com o products.yaml que definimos na seção FakeIt Série 2 de 5: Dados compartilhados e dependências postar.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
products.yaml name: Products type: object key: _id data: min: 4000 max: 5000 properties: _id: type: string description: The document id data: post_build: `product_${this.product_id}` doc_type: type: string description: The document type data: value: product product_id: type: string description: Unique identifier representing a specific product data: build: faker.random.uuid() price: type: double description: The product price data: build: chance.floating({ min: 0, max: 150, fixed: 2 }) sale_price: type: double description: The product price data: post_build: | let sale_price = 0; if (chance.bool({ likelihood: 30 })) { sale_price = chance.floating({ min: 0, max: this.price * chance.floating({ min: 0, max: 0.99, fixed: 2 }), fixed: 2 }); } return sale_price; display_name: type: string description: Display name of product. data: build: faker.commerce.productName() short_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(1) long_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(5) keywords: type: array description: An array of keywords items: type: string data: min: 0 max: 10 build: faker.random.word() availability: type: string description: The availability status of the product data: build: | let availability = 'In-Stock'; if (chance.bool({ likelihood: 40 })) { availability = faker.random.arrayElement([ 'Preorder', 'Out of Stock', 'Discontinued' ]); } return availability; availability_date: type: integer description: An epoch time of when the product is available data: build: faker.date.recent() post_build: new Date(this.availability_date).getTime() product_slug: type: string description: The URL friendly version of the product name data: post_build: faker.helpers.slugify(this.display_name).toLowerCase() category: type: string description: Category for the Product data: build: faker.commerce.department() category_slug: type: string description: The URL friendly version of the category name data: post_build: faker.helpers.slugify(this.category).toLowerCase() image: type: string description: Image URL representing the product. data: build: faker.image.image() alternate_images: type: array description: An array of alternate images for the product items: type: string data: min: 0 max: 4 build: faker.image.image() |
Nossos dados de categorias existentes foram fornecidos em formato CSV.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
categories.csv "category_id","category_name","category_slug" 23,"Electronics","electronics" 1032,"Office Supplies","office-supplies" 983,"Clothing & Apparel","clothing-and-apparel" 483,"Movies, Music & Books","movies-music-and-books" 3023,"Sports & Fitness","sports-and-fitness" 4935,"Automotive","automotive" 923,"Tools","tools" 5782,"Home Furniture","home-furniture" 9783,"Health & Beauty","health-and-beauty" 2537,"Toys","toys" 10,"Video Games","video-games" 736,"Pet Supplies","pet-supplies" |
Agora precisamos atualizar nosso modelo products.yaml para usar esses dados existentes.
(Para fins de brevidade, as outras propriedades foram deixadas de fora da definição do modelo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Products type: object key: _id data: min: 4000 max: 5000 inputs: - ./categories.csv pre_build: globals.current_category = faker.random.arrayElement(inputs.categories); properties: ... category_id: type: integer description: The Category ID for the Product data: build: globals.current_category.category_id category: type: string description: Category for the Product data: build: globals.current_category.category_name category_slug: type: string description: The URL friendly version of the category name data: post_build: globals.current_category.category_slug ... |
Há alguns aspectos a serem observados sobre como atualizamos nosso modelo products.yaml.
- inputs: é definido como uma matriz e não como uma cadeia de caracteres. Embora estejamos usando apenas uma única entrada, você pode fornecer quantos arquivos de entrada forem necessários para o seu modelo.
- Uma função pre_build é definida na raiz do modelo. Isso ocorre porque não podemos pegar um elemento de matriz aleatório para cada uma de nossas três propriedades de categoria, pois os valores não corresponderiam. Toda vez que um documento individual for gerado para o nosso modelo, essa função pre_build será executada primeiro.
- Cada uma de nossas funções de construção de propriedades de categoria faz referência à variável global definida pela função pre_build em nosso modelo.
Podemos testar nossas alterações usando o seguinte comando:
|
1 |
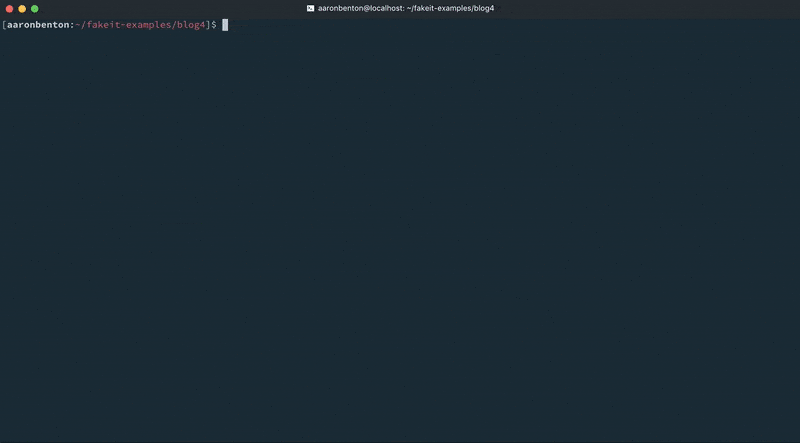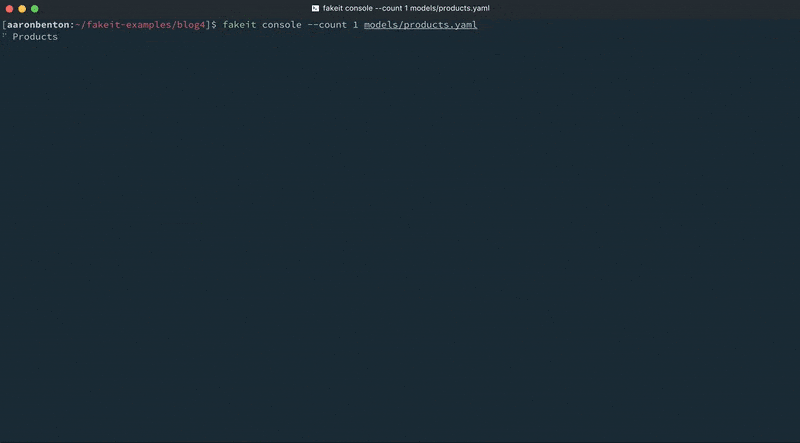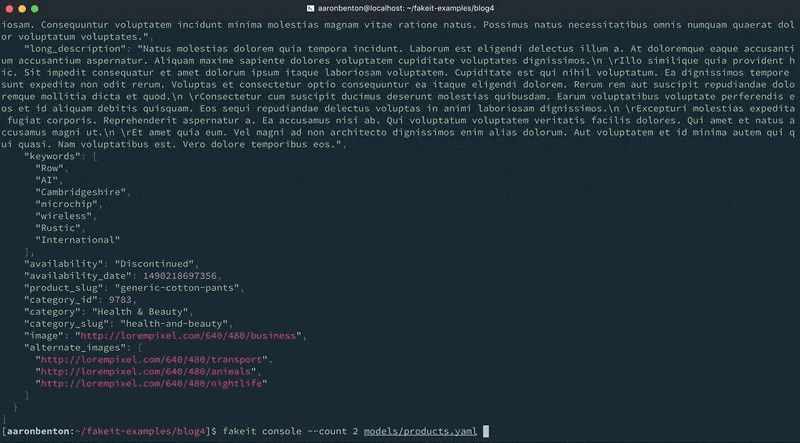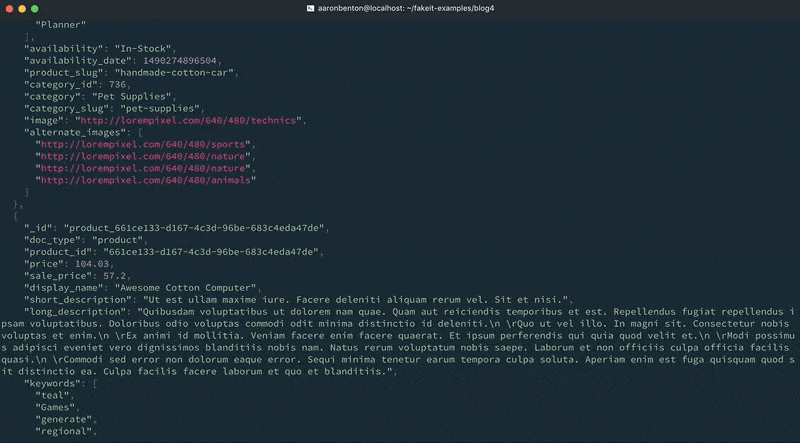
fakeit console --count 1 models/products.yaml |
Conclusão
A capacidade de trabalhar com dados existentes é um recurso extremamente poderoso do Falsa. Ele pode ser usado para manter a integridade de documentos gerados aleatoriamente para trabalhar com o sistema existente e pode até mesmo ser usado para transformar dados existentes e importá-los para o Couchbase Server.
Próximo
Anterior
- FakeIt Série 1 de 5: Geração de dados falsos
- FakeIt Série 2 de 5: Dados compartilhados e dependências
- Série FakeIt 3 de 5: Modelos Lean por meio de definições

Esta postagem faz parte do Programa de Redação da Comunidade Couchbase