Criando o índice de pesquisa correto e o ajuste de suas várias configurações é essencial para o bom funcionamento de qualquer Pesquisa de texto completo sistemas de produção. Esses aspectos operacionais desempenham um papel fundamental no aprimoramento do desempenho de indexação e consulta dos sistemas de pesquisa. Incentivamos todos os usuários do serviço de pesquisa a se familiarizarem com os conceitos abaixo de gerenciamento de índices e a usá-los criteriosamente em seus clusters. Portanto, você pode rolar a tela para explorar algumas dicas operacionais eficazes sobre o serviço Search, como cota de memória, partições de índice, réplicas, aliases e reequilíbrio de recuperação de failover.
1. Provisão de cota de memória suficiente
A cota de memória padrão para o serviço Search é de 512 MB e isso não é suficiente para dar suporte a qualquer sistema de pesquisa em escala de produção. Portanto, é recomendável revisar a cota de RAM do Search para valores mais significativos como parte do dimensionamento do cluster.
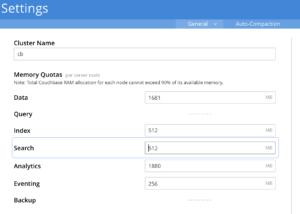
O serviço Search não exige nenhuma taxa mínima de memória residente para seu índice. No entanto, os usuários são aconselhados a reservar uma cota de memória de pesquisa suficiente para uma taxa de residência saudável do índice. Isso permite que o sistema tenha memória suficiente disponível para executar a indexação, a consulta ou outras operações de ciclo de vida, como rebalanceamentos etc.
Abaixo estão alguns sintomas para cota de memória insuficiente em um cluster de pesquisa,
- As consultas são rejeitadas devido ao código de erro HTTP 429 do servidor.
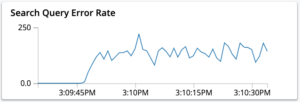
Essa limitação de taxa é aplicada para respeitar a cota de memória configurada para o serviço de pesquisa. Ele rejeita uma consulta de entrada quando não há memória suficiente disponível para atender à consulta sem exceder a cota de memória definida. Você pode notar um aumento na taxa de erro de consulta na página de monitoramento do índice.
- Um número crescente de consultas lentas no sistema.
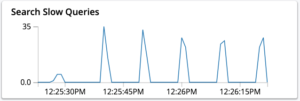
Os picos de consultas lentas também podem ocorrer devido à escassez de memória operacional no sistema.
- Aumento da latência média das consultas.
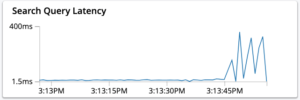
Um aumento gradual na latência da consulta também pode ocorrer devido à falta de memória operacional no sistema.
Todas as estatísticas de consulta acima podem ser monitoradas na página de estatísticas de índice integrada no servidor Couchbase.
2. Poupe memória suficiente para o cache do sistema de arquivos.
Outro aspecto importante ao configurar a cota de memória de pesquisa é deixar uma margem suficiente de RAM para que o sistema operacional gerencie a cache do sistema de arquivos. Nos bastidores, a biblioteca interna de indexação de texto do Search (sangrar) usa mapeamento de memória para os arquivos de índice. Portanto, ter uma quantidade suficiente de RAM reservada para o sistema operacional ajuda a manter as regiões quentes dos arquivos de índice na memória cache do sistema de arquivos. Isso ajuda a melhorar o desempenho da pesquisa.
A diretriz usual é definir a cota de memória de pesquisa para 60-70% da RAM disponível em um nó de pesquisa.
A configuração de memória RAM suficiente no sistema e a alocação de memória de cota de pesquisa suficiente são essenciais para o desempenho ideal da pesquisa.
Sintomas - O fato de o serviço de pesquisa ser eliminado pelo sistema operacional de forma recorrente durante o processo de indexação ou consulta também pode indicar uma falta de memória RAM no sistema.
3. Evite o multilocatário de serviços com nós de pesquisa
A hospedagem de vários serviços em um único nó apresenta o risco de possível contenção de recursos entre os serviços. Mesmo a definição de uma cota de recursos para cada serviço não ajudará a evitar completamente esse problema.
Por exemplo, o serviço de pesquisa depende muito da memória RAM disponível além da cota de memória configurada para melhorar o desempenho do mapeamento de memória. Mas outros serviços em execução no mesmo nó podem consumir essa RAM disponível e afetar o desempenho da pesquisa inadvertidamente. O mesmo vale para os núcleos de CPU.
A depuração e a identificação de problemas de desempenho ou o dimensionamento inicial do sistema de pesquisa se tornam muito mais fáceis com nós hospedados em um único serviço.
Portanto, os usuários são incentivados a começar pelo menos com nós de pesquisa de serviço único durante o período inicial de implementação.
4. Considerações sobre a topologia do índice
-
Número de partições de índice
Dependendo da quantidade de dados indexados, ajuste o número de partições de índice e sua distribuição entre os nós/núcleos da CPU para otimizar o desempenho do serviço.
Um número excessivo de partições aumenta o custo de coleta de dispersão, e um número muito pequeno de partições limitaria a paralelização da pesquisa.
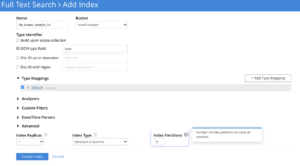
Não há uma contagem de partição de índice genérica predefinida que se adapte a todos os casos de uso. Os usuários precisam explorar isso empiricamente para cada um de seus SLAs de caso de uso.
Se o usuário tiver apenas alguns milhões de dados, é recomendável substituir a contagem de partições padrão de 6 por valores menores, como 1 ou 2.
Alguns pontos importantes que devem ser levados em conta com relação ao número de partições de índice são,
- Ajuda na melhor alocação de cargas de trabalho de indexação e consulta entre os nós disponíveis, dependendo do tamanho do cluster.
- Partições relativamente menores em vários nós ajudam a agilizar as operações de rebalanceamento.
- As partições ajudam a melhorar a utilização do núcleo da CPU.
- Dependendo da quantidade de dados que estão sendo indexados, é aconselhável ajustar a contagem de partições para que elas não sejam muito grandes.
-
Número de réplicas
A réplica serve apenas ao propósito de alta disponibilidade no Search Service hoje. Portanto, sempre que um nó ficar inativo por qualquer motivo, os usuários poderão executar um reequilíbrio de failover do nó defeituoso. Isso atenderia imediatamente ao tráfego ativo das partições de réplica e o serviço permaneceria ativo para os usuários finais sem problemas.
Os números de réplica precisam ser configurados explicitamente pelo usuário durante o tempo de criação do índice.
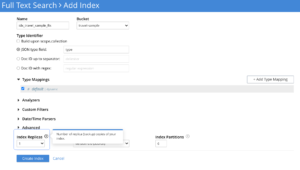
Por padrão, os serviços de pesquisa não ativam réplicas de partição durante a criação de índices.
Os usuários são incentivados a configurar uma contagem de réplicas de 1 ou mais, dependendo dos requisitos de alta disponibilidade.
-
Failover e recuperação
Se o usuário precisar retirar temporariamente um nó do cluster para qualquer operação de manutenção de hardware ou software, ele poderá tentar fazer o failing over do nó. Durante o failover de um nó de pesquisa, todos os dados da partição de índice que residem no nó são preservados.
Após o término das operações de manutenção, você poderá tentar a opção "Recover" para adicioná-lo novamente ao cluster. Como você está recuperando o mesmo nó aqui, o serviço de pesquisa poderá reutilizar todos os dados de partição de índice existentes que residem no nó recuperado. E isso resultaria em uma operação de recuperação de nó realmente mais rápida.

Com partições de réplica, o serviço de pesquisa deve ser capaz de fazer failover e recuperar nós para manutenção sem nenhum tempo de inatividade do serviço.
5. Política de mesclagem mais rigorosa para casos de uso intenso de atualizações
Um índice de pesquisa geralmente compreende vários arquivos de índice chamados segmentos. Esses segmentos são criados pelas mutações de documentos (inserir/atualizar/excluir) que ocorrem na fonte/bucket de dados. Ao atender a uma solicitação de pesquisa, o FTS precisa pesquisar todos esses segmentos sequencialmente. Portanto, quanto maior o número de segmentos, mais lentas serão as operações de pesquisa no índice.
Na camada de armazenamento do índice, um processo de mesclagem em segundo plano continua mesclando esses arquivos de segmentos de disco menores em um conjunto estável de segmentos maiores. Esse comportamento de mesclagem é controlado pela política de mesclagem que pode ser especificada na definição do índice. Uma fusão excessivamente agressiva pode roubar mais recursos (disco e CPU) de outros segmentos concorrentes do ciclo de vida ou das operações de consulta em um índice. Por isso, mantivemos a política de mesclagem padrão para ser genérica o suficiente para trabalhar com vários casos de uso.
Em um determinado momento, a política de mesclagem padrão tentaria resultar em um grupo de segmentos de índice que seguem um padrão de escada logarítmica de tamanhos de segmento crescentes, conforme abaixo.

Mas pode haver situações em que vale a pena verificar a política de mesclagem e vamos explorá-las.
-
Recuperação mais rápida do espaço em disco com carga de trabalho rica em atualizações/exclusões.
O FTS tem "somente anexo", que marcaria as entradas de documentos nos segmentos existentes como excluídas/obsoletas pela inversão de um bit em qualquer operação de atualização/exclusão. A liberação real de espaço em disco ocorrerá somente quando esses segmentos forem mesclados/compactados durante o ciclo de mesclagem simultâneo. A política de mesclagem padrão do FTS favorecerá a mesclagem de segmentos menores em vez de segmentos maiores e gigantescos para otimizar a E/S do disco e a CPU. Isso pode deixar um longo período de espera para recuperar o espaço em disco dos documentos atualizados/tombados que pertenciam a esses segmentos maiores, já que os segmentos maiores são selecionados para operações de mesclagem com pouca frequência.
A quantidade de espaço em disco recuperável em qualquer instante é exposta aos usuários por meio de uma estatística chamada num_bytes_used_disk_by_root_reclaimable.
Se o usuário observar consistentemente valores significativos para a estatística acima, isso indica a necessidade de uma política de compactação mais rígida para o índice. Os botões de configuração de mesclagem também têm a disposição de favorecer a seleção de segmentos que tenham mais conteúdo obsoleto/excluído durante o processo de compactação/mesclagem.
-
Melhor desempenho de pesquisa para cargas de trabalho de leitura intensa.
Já aprendemos que cada solicitação de pesquisa é atendida depois de consultar cada um desses arquivos de segmento em um índice. Portanto, a sobrecarga de atender a uma pesquisa seria maior com um número maior de arquivos de segmentos.
Um número menor de segmentos ajuda a melhorar o desempenho da pesquisa. Portanto, é recomendável reduzir o número de arquivos de segmento sempre que possível. (fora do horário de pico)
A política de compactação pode ser substituída usando a definição de índice atualizar o ponto de extremidade de repouso. Por favor Entre em contato conosco para obter mais detalhes sobre como substituir a política de compactação padrão de um índice.
6. Uso de aliases de índice
Um alias de índice aponta para um ou mais índices de texto completo ou para aliases adicionais: sua finalidade é, portanto, comparável à de um link simbólico em um sistema de arquivos. As consultas em um alias de índice são realizadas em todos os alvos finais, e os resultados mesclados são fornecidos.
O uso de aliases de índice permite indireção na nomeação, em que os aplicativos se referem a um nome de alias que nunca muda, deixando os administradores livres para alterar periodicamente a identidade do índice real apontado pelo alias. Isso pode ser particularmente útil quando um índice precisa ser atualizado: para evitar tempo de inatividade, enquanto o índice atual permanece em serviço, um clone do índice atual pode ser criado, modificado e testado. Então, quando o clone estiver pronto, o alias existente poderá ser redirecionado, de modo que o clone se torne o índice atual; e o índice (agora) anterior poderá ser removido.
Os detalhes da criação do alias do índice podem ser encontrados aqui
7. Erros na atualização da definição do índice
Os usuários têm a opção de atualizar a definição do índice sempre que precisarem alterar as propriedades do índice relacionadas a mapeamentos de tipos, partições, réplicas, armazenamento ou persistência.
Uma coisa que se deve ter em mente ao atualizar uma definição de índice é que poucas atualizações resultariam na reconstrução do índice a partir do zero.
Atualizações de reconstrução do índice
Qualquer tipo de atualização relacionada a mapeamento ou contagem de partições sempre reconstrói o índice. Portanto, essas alterações afetariam o tráfego ativo. Mas, normalmente, esses tipos de atualizações de definição de índice ocorrem na fase inicial de implementação do cluster.
Atualizações não relacionadas à construção
As atualizações das propriedades de índice restantes seriam instantâneas. As atualizações resultariam apenas em uma reinicialização ou atualização dos componentes subjacentes. O índice deve estar ativo e em execução em um período de inatividade de apenas alguns segundos. Portanto, os usuários podem tentar isso durante as horas de tráfego fora do pico.
As atualizações da definição do índice, como a alteração das contagens de réplicas e das propriedades do mecanismo de armazenamento, pertencem a essa categoria.
Para qualquer dúvida relacionada ao sistema Search, os usuários podem entrar em contato conosco aqui.
Para obter dicas de consulta do FTS, os usuários podem verificar o seguinte blog,
Full-Text Search - 5 dicas para melhorar o desempenho de suas consultas
Ótimo artigo, Sreekanth.