지난 몇 년 동안 머신러닝은 기업이 대규모로 투자해야 할 기술로 입증되었으며, X사가 프로세스에 일정 수준의 AI를 추가하여 엄청난 비용을 절감한 방법에 관한 수십 개의 논문을 쉽게 찾을 수 있습니다.
놀랍게도 여전히 많은 업계에서 회의적인 반응을 보이고 있고, "멋지다"고 생각하지만 아직 아무것도 염두에 두지 않는 업계도 있습니다.
이러한 불협화음의 원인은 두 가지 주요 요인 때문이라고 생각합니다: 많은 기업이 AI가 비즈니스에 어떻게 적용되는지 모르고 있으며, 대부분의 개발자에게는 여전히 검은 마법처럼 들립니다.
그래서 오늘은 거의 노력하지 않고도 머신러닝을 시작할 수 있는 방법을 보여드리고자 합니다.
선형 회귀
머신 러닝의 가장 기본적인 수준에는 선형 회귀라는 것이 있는데, 이는 대략 일련의 특징에 가중치를 부여하여 숫자를 '설명'하려는 알고리즘으로, 몇 가지 예를 살펴 보겠습니다:
- 집의 가격은 크기, 위치, 침실 및 욕실 수 등으로 설명할 수 있습니다.
- 자동차의 가격은 모델, 연식, 주행거리, 상태 등으로 설명할 수 있습니다.
- 주어진 작업에 소요되는 시간은 하위 작업의 수, 난이도, 작업자 경험 등을 통해 예측할 수 있습니다.
선형 회귀(또는 다른 회귀 유형)를 사용할 수 있는 사용 사례는 많지만, 첫 번째 주택 가격과 관련된 사례에 초점을 맞춰 보겠습니다.
우리가 특정 지역에서 부동산 회사를 운영하고 있는데, 오래된 회사이기 때문에 과거에 어떤 주택이 얼마에 팔렸는지에 대한 데이터 기록이 있다고 가정해 보겠습니다.
이 경우 기록 데이터의 각 행은 다음과 같이 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "id": 7129300520, "date": "20141013T000000", "price": 221900, "bedrooms": 3, "bathrooms": 1, "sqft_living": 1180, "sqft_lot": 5650, "floors": 1, "waterfront": 0, "view": 0, "condition": 3, "grade": 7, "sqft_above": 1180, "sqft_basement": 0, "yr_built": 1955, "yr_renovated": 0, "zipcode": 98178, "lat": 47.5112, "long": -122.257, "sqft_living15": 1340, "sqft_lot15": 5650 } |
문제 - 집값 책정 방법
이제 막 회사에 입사했는데 다음 집을 팔아야 한다고 가정해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "id": 1000001, "date": "20150422T000000", "bedrooms": 6, "bathrooms": 3, "price": null, "sqft_living": 2400, "sqft_lot": 9373, "floors": 2, "waterfront": 0, "view": 0, "condition": 3, "grade": 7, "sqft_above": 2400, "sqft_basement": 0, "yr_built": 1991, "yr_renovated": 0, "zipcode": 98002, "lat": 47.3262, "long": -122.214, "sqft_living15": 2060, "sqft_lot15": 7316 } |
얼마에 판매하시겠습니까?
과거에 비슷한 집을 판매한 적이 없다면 위의 질문은 매우 어려울 것입니다. 다행히도 이 작업에 적합한 도구가 있습니다: 바로 선형 회귀입니다.
정답 - 선형 회귀를 이용한 주택 가격 예측
계속 진행하기 전에 다음 항목을 설치해야 합니다:
- 카우치베이스 서버 5
- Spark 2.2
- SBT (스칼라를 사용하여 실행 중이므로)
데이터 세트 로드
Couchbase Server를 실행한 상태에서 관리 포털(일반적으로 https://127.0.0.1:8091)로 이동하여 다음과 같은 새 버킷을 만듭니다. 주택_가격
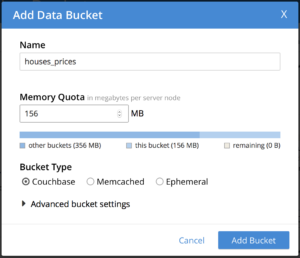
이제 튜토리얼 코드를 복제해 보겠습니다:
|
1 |
git clone https://github.com/couchbaselabs/couchbase-spark-mllib-sample.git |
루트 폴더에는 다음과 같은 파일이 있습니다. 집_가격_열차_데이터.zip의 오래된 머신 러닝 강좌에서 빌려온 데이터 세트입니다. Coursera. 압축을 푼 다음 다음 명령을 실행하세요:
|
1 |
./cbimport json -c couchbase://127.0.0.1 -u YOUR_USER -p YOUR_PASSWORD -b houses_prices -d <PATH_TO_UNZIPED_FILE>/house_prices_train_data -f list -g key::%id% -t 4 |
팁: 익숙하지 않은 경우 cbimport 제발 이 튜토리얼을 확인하세요.
명령이 성공적으로 실행되었다면, 다음과 같은 메시지가 표시됩니다. 주택_가격 버킷이 채워졌습니다:
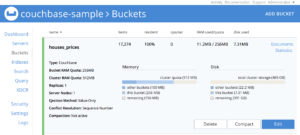
또한 기본 인덱스를 빠르게 추가해 보겠습니다:
|
1 |
CREATE PRIMARY INDEX ON `houses_prices` |
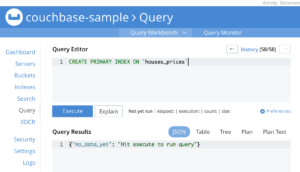
코딩할 시간입니다!
환경이 준비되었으니 이제 코딩할 시간입니다!
에서 선형 회귀 예제 클래스에서 버킷 자격 증명을 사용하여 Spark 컨텍스트를 생성하는 것으로 시작합니다:
|
1 2 3 4 5 6 7 8 9 |
val spark = SparkSession .builder() .appName("SparkSQLExample") .master("local[*]") // use the JVM as the master, great for testing .config("spark.couchbase.nodes", "127.0.0.1") // connect to couchbase on localhost .config("spark.couchbase.bucket.houses_prices", "") // open the houses_prices bucket with empty password .config("com.couchbase.username", "YOUR_USER") .config("com.couchbase.password", "YOUR_PASSWORD") .getOrCreate() |
를 클릭한 다음 데이터베이스에서 모든 데이터를 로드합니다:
|
1 |
val houses = spark.read.couchbase() |
Spark는 지연 방식을 사용하기 때문에 데이터가 실제로 필요할 때까지 로드되지 않습니다. 따라서 카우치베이스 커넥터 위의 예제에서는 아무런 노력 없이 JSON 문서를 Spark 데이터프레임으로 변환했습니다.
예를 들어 다른 데이터베이스에서는 데이터를 특정 형식의 CSV 파일로 내보내고, 컴퓨터에 복사하고, 로드하고, 데이터 프레임으로 변환하기 위해 몇 가지 추가 절차를 수행해야 합니다(생성된 파일이 너무 큰 경우는 말할 것도 없고요).
실제 환경에서는 모든 데이터를 가져오는 대신 일부 필터링을 수행해야 하는데, 이 경우에도 커넥터를 사용하면 일부 N1QL 쿼리를 실행할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//loading documents by its type val airlines = spark.read.couchbase(EqualTo("type", "airline")) //loading data using N1QL // This query groups airports by country and counts them. val query = N1qlQuery.simple("" + "select country, count(*) as count " + "from `travel-sample` " + "where type = 'airport' " + "group by country " + "order by count desc") val schema = StructType( StructField("count", IntegerType) :: StructField("country", StringType) :: Nil ) val rdd = spark.sparkContext.couchbaseQuery(query).map( r => Row(r.value.getInt("count"), r.value.getString("country"))) spark.createDataFrame(rdd, schema).show() |
팁: Couchbase 커넥터 사용 방법에 대한 많은 예제가 있습니다. 여기.
데이터 프레임은 여전히 데이터베이스에 있던 것과 똑같습니다:
|
1 |
houses.show(10) |

여기에는 두 가지 유형의 데이터가 있습니다."스칼라 숫자"와 같은 욕실 그리고 sqft_living 및 "범주형 변수"와 같은 우편번호 그리고 yr_renovated. 이러한 범주형 변수는 단순한 숫자가 아니라, 예를 들어 우편번호의 경우 집의 위치를 나타내는 등 속성을 설명하기 때문에 훨씬 더 깊은 의미를 가집니다.
선형 회귀는 이러한 종류의 범주형 변수를 좋아하지 않으므로 선형 회귀에서 우편 번호를 사용하려면 집 가격을 예측하는 데 관련성이 있는 필드인 것 같으므로 이를 더미 변수를 클릭하는 것은 매우 간단한 과정입니다:
- 대상 열의 모든 값을 구분합니다. Ex: SELECT DISTINCT(ZIPCODE) FROM HOUSES_PRICES
- 각 행을 열로 변환합니다. Ex: 우편번호_98002, 우편번호_98188, 우편번호_98059
- 우편번호 콘텐츠의 값에 따라 새 열을 1과 0으로 업데이트합니다:
Ex:
![]()
위의 표는 다음과 같이 변환됩니다:
![]()
이것이 바로 아래 라인에서 저희가 하고 있는 일입니다:
|
1 |
val df = transformCategoricalFeatures(houses) |
범주형 변수를 변환하는 것은 매우 표준적인 절차이며, 스파크에는 이미 이 작업을 수행할 수 있는 몇 가지 유틸리티가 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def transformCategoricalFeatures(dataset: Dataset[_]): DataFrame = { val df1 = encodeFeature("zipcode", "zipcodeVec", dataset) val df2 = encodeFeature("yr_renovated", "yr_renovatedVec", df1) val df3 = encodeFeature("condition", "conditionVec", df2) encodeFeature("grade", "gradeVec", df3) } def encodeFeature(featureName: String, outputName: String, dataset: Dataset[_]): DataFrame = { val indexer = new StringIndexer() .setInputCol(featureName) .setOutputCol(featureName + "Index") .fit(dataset) val indexed = indexer.transform(dataset) val encoder = new OneHotEncoder() .setInputCol(featureName + "Index") .setOutputCol(outputName) encoder.transform(indexed) } |
참고: 최종 데이터 프레임은 이미 최적화되어 있으므로 위에 표시된 예시와 정확히 일치하지는 않습니다. 스파스 매트릭스 문제.
이제 사용하려는 필드를 선택하고 다음과 같은 벡터로 그룹화할 수 있습니다. 기능이 선형 회귀 구현은 다음과 같은 필드를 기대하기 때문에 레이블의 이름을 변경해야 합니다. 가격 열 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//just using almost all columns as features, no special feature engineering here val features = Array("sqft_living", "bedrooms", "gradeVec", "waterfront", "bathrooms", "view", "conditionVec", "sqft_above", "sqft_basement", "sqft_lot", "floors", "yr_built", "zipcodeVec", "yr_renovatedVec") val assembler = new VectorAssembler() .setInputCols(features) .setOutputCol("features") //the Linear Regression implementation expect a feature called "label" val renamedDF = assembler.transform(df.withColumnRenamed("price", "label")) |
이러한 기능을 원하는 대로 제거/추가해보고 나중에 예를 들어 "sqft_living' 기능을 통해 알고리즘의 성능이 어떻게 훨씬 떨어지는지 확인할 수 있습니다.
마지막으로, 선형 회귀가 주어진 특징 집합으로 가격을 예측하는 방법을 '학습'하게 하는 것이 전체 목표이므로 가격이 0이 아닌 주택만 사용하여 머신 러닝 알고리즘을 훈련할 것입니다.
|
1 |
val data = renamedDF.select("label", "features").filter("price is not null") |
여기서 마법이 일어나는데, 먼저 데이터를 트레이닝으로 분할합니다(80%) 및 테스트(20%), 그러나 이 글의 목적상 테스트 데이터는 무시하고 LinearRegression 인스턴스를 생성하고 fit 데이터를 수집합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//let's split our data into test and training (a common thing during model selection) val splits = data.randomSplit(Array(0.8, 0.2), seed = 1L) val trainingData = splits(0).cache() //let's ignore the test data for now as we are not doing model selection val testData = splits(1) val lr = new LinearRegression() .setMaxIter(1000) .setStandardization(true) .setRegParam(0.1) .setElasticNetParam(0.8) val lrModel = lr.fit(trainingData) |
그리고 lrModel 변수는 이미 집값을 예측할 수 있는 학습된 모델입니다!
예측을 시작하기 전에 학습된 모델의 몇 가지 메트릭을 확인해 보겠습니다:
|
1 2 3 4 5 6 7 |
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}") val trainingSummary = lrModel.summary println(s"numIterations: ${trainingSummary.totalIterations}") println(s"objectiveHistory: [${trainingSummary.objectiveHistory.mkString(",")}]") trainingSummary.residuals.show() println(s"RMSE: ${trainingSummary.rootMeanSquaredError}") println(s"r2: ${trainingSummary.r2}") |
여기서 주의해야 할 것은 RMSE - 루트 평균 제곱 오차 대략적으로 모델이 예측한 가격 X 실제 판매 가격의 평균 편차.
|
1 2 |
RMSE: 147556.0841305963 r2: 0.8362288980410875 |
평균적으로 다음과 같이 실제 가격을 놓치고 있습니다. $147556.0841305963를 거의 사용하지 않았다는 점을 고려하면 전혀 나쁘지 않습니다. 기능 엔지니어링 또는 이상값을 제거했습니다(일부 주택은 설명할 수 없는 높은 가격 또는 낮은 가격을 가질 수 있으며 선형 회귀를 엉망으로 만들 수 있습니다).
이 데이터 집합에서 누락된 가격이 있는 집은 처음에 지적한 바로 그 집 한 채뿐입니다:
|
1 2 3 4 |
val missingPriceData = renamedDF.select("features") .filter("price is null") missingPriceData.show() |
이제 드디어 예상 집값을 예측할 수 있게 되었습니다:
|
1 2 3 |
//printing out the predicted values val predictedValues = lrModel.transform(missingPriceData) predictedValues.select("prediction").show() |
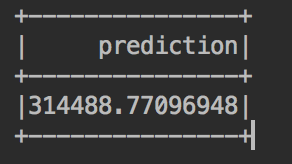
멋지지 않나요?
프로덕션 목적의 경우 여전히 모델 선택 먼저 회귀의 다른 메트릭을 확인하고 모델을 즉석에서 훈련하는 대신 저장하지만, 100줄 미만의 코드로 얼마나 많은 작업을 수행할 수 있는지 놀랍습니다!
궁금한 점이 있으면 트위터에서 언제든지 문의해 주세요. @deniswsrosa 또는 포럼.