일반적인 애드혹 분석 쿼리는 메모리에 들어갈 수 있는 것보다 훨씬 더 많은 데이터를 처리해야 합니다. 따라서 이러한 쿼리는 I/O 바인딩이 되는 경향이 있습니다. Couchbase 6.0에 분석 서비스가 도입되었을 때, 사용자는 노드 초기화 중에 여러 개의 "분석 디스크 경로"를 지정할 수 있었습니다. 이 문서에서는 클라우드의 여러 인스턴스에서 몇 가지 실험을 수행하여 여러 개의 "Analytics 디스크 경로"를 올바르게 설정하는 방법과 이 기능을 활용하여 Analytics 쿼리 속도를 높이는 방법을 보여줍니다.
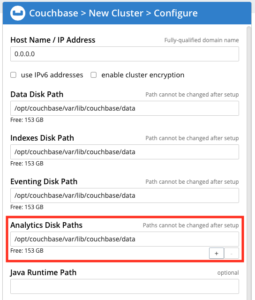
그림 1: 노드 초기화 중 Analytics 디스크 경로 지정하기
노드를 초기화하는 동안 이 경로가 있는 실제 물리적 저장 장치에 관계없이 모든 고유 파일 시스템 경로를 '애널리틱스 디스크 경로'로 사용할 수 있습니다. 동일한 장치에 있는 여러 경로를 사용할 수 있습니다. 애널리틱스 서비스의 데이터는 애널리틱스 서비스가 있는 모든 노드에서 지정된 모든 "애널리틱스 디스크 경로"에 걸쳐 분할됩니다. 예를 들어, 클러스터에 애널리틱스 서비스가 있는 노드가 2개 있고 노드 중 하나에 4개의 '애널리틱스 디스크 경로'가 지정되어 있고 다른 노드에 8개의 '애널리틱스 디스크 경로'가 있는 경우 애널리틱스에서 생성된 모든 데이터 세트는 총 12개의 파티션(데이터 파티션)을 갖게 됩니다.
쿼리 실행 중에 Analytics의 MPP 쿼리 엔진은 모든 데이터 파티션에서 데이터를 동시에 읽고 처리하려고 시도합니다. 따라서 각 데이터 파티션이 상주하는 실제 물리적 디스크의 초당 입출력 작업 수(IOPS)가 쿼리 실행 시간을 결정하는 데 중요한 역할을 합니다.
SSD와 같은 최신 저장 장치는 HDD보다 훨씬 높은 IOPS를 가지며 동시 읽기를 더 잘 처리할 수 있습니다. 따라서 IOPS가 높은 장치에 단일 데이터 파티션을 사용하면 해당 기능을 충분히 활용할 수 없습니다. 하나의 최신 저장 장치를 사용하는 노드의 일반적인 경우 설정을 간소화하기 위해, 노드 초기화 중에 하나의 "Analytics 디스크 경로"만 지정하는 경우에만 Analytics 서비스가 동일한 저장 장치 내에 여러 데이터 파티션을 자동으로 생성합니다. 자동으로 생성되는 데이터 파티션의 수는 이 공식에 따라 결정됩니다:
|
1 2 |
Maximum partitions to create = Min((Analytics Memory in MB / 1024), 16) Actual created partitions = Min(node virtual cores, Maximum partitions to create) |
예를 들어 노드에 가상 코어가 8개 있고 분석 서비스가 8GB 이상의 메모리로 구성된 경우, 해당 노드에 8개의 데이터 파티션이 생성됩니다. 마찬가지로 노드에 32개의 가상 코어가 있고 메모리가 16GB 이상으로 구성된 경우, 자동으로 생성되는 최대 파티션의 상한이 16개이므로 16개의 파티션만 생성됩니다.
디스크당 데이터 파티션 수에 대한 성능 영향을 보여주기 위해 Amazon Web Services EC2의 다양한 인스턴스 유형에 대해 다음을 사용하여 몇 가지 실험을 수행했습니다. 카우치베이스 서버 6.5 베타 2. 실험에 사용된 데이터는 유명한 데이터의 JSON화된 버전입니다. TPC-DS 데이터 세트에서 모든 행이 문서가 속한 테이블의 이름을 식별하는 추가 필드가 있는 JSON 문서로 변환되었습니다. 샘플 TPC-DS 데이터가 생성되어 다음과 같은 버킷에 로드되었습니다. tpcds. 두 실험 모두에서 Analytics 서비스에는 32GB의 메모리가 할당되었습니다.
실험 1: 8개의 가상 코어와 1개의 NVMe SSD를 사용하는 단일 인스턴스
이 실험에서는 다음과 같이 애널리틱스 서비스에서 3개의 데이터 세트를 생성했습니다:
|
1 2 3 |
CREATE DATASET store_sales ON tpcds WHERE table_name='store_sales'; CREATE DATASET date_dim ON tpcds WHERE table_name='date_dim'; CREATE DATASET item ON tpcds WHERE table_name='item'; |
두 가지 다른 구성에서 응답 시간을 측정하기 위해 다음 TPC-DS 자격 증명 쿼리를 N1QL for Analytics 쿼리로 변환한 후 사용했습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT dt.d_year, item.i_brand_id brand_id, item.i_brand brand, sum(ss.ss_ext_sales_price) sum_agg FROM date_dim dt, store_sales ss, item WHERE dt.d_date_sk = ss.ss_sold_date_sk AND ss.ss_item_sk = item.i_item_sk AND item.i_manufact_id = 128 AND dt.d_moy=11 GROUP BY dt.d_year, item.i_brand, item.i_brand_id ORDER BY dt.d_year, sum_agg DESC, brand_id LIMIT 100; |
첫 번째 구성에서는 동일한 디스크에 두 개의 "분석 디스크 경로"를 지정하여 각 데이터 세트에 2개의 데이터 파티션이 생겼습니다. 두 번째 구성에서는 하나의 "애널리틱스 데이터 경로"를 지정하면 자동 구성 옵션이 트리거되었습니다. 노드에는 8개의 가상 코어가 있으므로 8개의 데이터 파티션이 자동으로 생성되었습니다. 아래 그림 2는 이 두 가지 구성의 평균 쿼리 응답 시간을 보여줍니다. 평균 쿼리 응답 시간 측면에서 보면, 파티션이 8개인 자동 구성이 데이터 파티션이 2개인 구성보다 2배 이상 빨랐습니다. 이러한 개선은 이러한 유형의 디스크는 8개의 동시 읽기를 처리할 수 있기 때문에 단일 NVMe SSD의 활용도가 더 높았기 때문입니다. 또한 이 쿼리에는 그룹화 및 정렬이 포함되므로 8개 파티션에서 동시에 데이터를 처리하면 쿼리 성능이 크게 향상되었습니다.
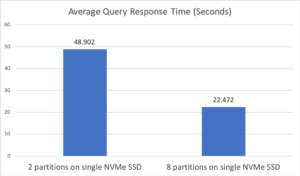
그림 2: 실험 1 평균 쿼리 응답 시간
실험 2: 8개의 가상 코어와 6개의 HDD를 사용하는 단일 인스턴스
이 실험에서는 다음과 같이 tpcds 버킷에 있는 모든 데이터를 포함하는 단일 데이터 세트를 생성하여 더 큰 용량의 데이터를 스캔해 보겠습니다:
|
1 |
CREATE DATASET tpcds on tpcds; |
두 가지 다른 구성을 사용하여 모든 데이터를 스캔하는 다음 N1QL for Analytics 쿼리를 사용했습니다:
|
1 2 3 |
SELECT SUM(ss_ext_sales_price) FROM tpcds WHERE table_name = "store_sales"; |
첫 번째 구성의 경우, 단일 "분석 데이터 경로"가 지정되었으며, 그 결과 시스템이 자동으로 단일 HDD. 두 번째 구성에서는 6개의 '분석 데이터 경로'를 지정하고 각 경로를 서로 다른 물리적 HDD에 배치하여 6개의 데이터 파티션을 만들었습니다. 아래 그림 3은 두 구성의 평균 쿼리 응답 시간을 보여줍니다. 첫 번째 구성에서는 단일 HDD에서 8개의 동시 읽기를 수행한 결과 성능이 저하되었습니다. 그 주된 이유는 나머지 5개 HDD의 I/O 대역폭이 사용되지 않았기 때문입니다. 또한 단일 HDD에 대한 8방향 동시 읽기는 더 많은 디스크 암 이동으로 이어져 디스크 I/O의 평균 비용을 증가시켰습니다. 6개의 HDD를 모두 동시에 활용하는 두 번째 구성은 결과적으로 7배 이상의 성능 향상을 가져왔습니다.
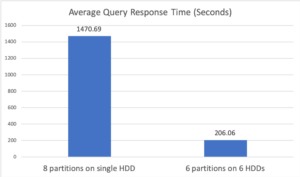
그림 3: 실험 2 평균 쿼리 응답 시간
결론:
분석 엔진은 30년 이상의 관계형 MPP R&D에서 도출된 "동급 최강의" 알고리즘을 기반으로 병렬 조인, 집계 및 정렬을 지원하는 본격적인 병렬 쿼리 프로세서이지만 JSON 데이터용입니다. 두 가지 실험을 통해 '분석 디스크 경로'를 구성할 때 서로 다른 선택을 할 때 발생할 수 있는 상당한 성능 영향을 보여주었습니다. 또한, 사용 가능한 경우 여러 개의 물리적 디스크를 활용하여 분석 엔진이 분석 쿼리 속도를 크게 높일 수 있는 방법도 시연했습니다.