와 함께 카우치베이스 서버 5.5 출시를 소개했습니다. 엔드투엔드 압축 를 사용하여 데이터를 압축된 상태로 유지할 수 있습니다: 클라이언트를 캐시, 디스크 스토리지, 데이터 센터 간 데이터 복제에 사용할 수 있습니다. 대부분의 고객 데이터는 쉽게 압축할 수 있는 JSON 텍스트로 되어 있기 때문에 이를 통해 귀중한 스토리지와 대역폭을 절약할 수 있을 것으로 예상합니다.
데이터 압축에 대해 자세히 알아볼 수 있는 발판을 마련하기 위해 Couchbase 내의 데이터 흐름에 대한 간략한 개요를 제공해드리겠습니다.
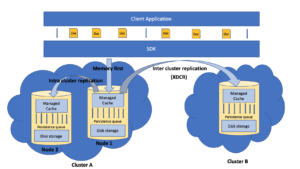
그림 1. 카우치베이스 데이터 플랫폼 내 데이터 흐름
클라이언트 애플리케이션의 데이터는 메모리 우선 아키텍처를 지원하고 옹호하기 때문에 먼저 SDK를 통해 관리되는 캐시로 이동합니다. 그런 다음 캐시에 있는 이 데이터는 지속성 큐를 통해 디스크에 지속됩니다. 캐시 미스가 발생하지 않는 한 모든 키-값 연산은 캐시에 있는 데이터에 대해 수행되며, 디스크에서 데이터가 검색되고 향후 액세스를 위해 캐시에 유지됩니다. 또한 캐시의 데이터는 고가용성을 위해 클러스터 내 복제 대기열을 통해 다른 복제 노드에 복제됩니다. 그 다음에는 클러스터 간 복제(해당되는 경우)가 이어지며, 메모리의 데이터는 Couchbase의 자체 XDCR(데이터센터 간 복제) 기술을 사용하여 대부분 다양한 지역에 있는 데이터센터에 분산된 다른 Couchbase 클러스터로 복제됩니다.
로컬 지속성, 클러스터 내 복제 또는 클러스터 간 복제 등 Couchbase의 모든 형태의 복제는 중단 시 손실 복구, RAM에서 RAM으로의 스트리밍 및 멀티스레드 병렬 처리를 특징으로 하는 DCP(데이터베이스 변경 프로토콜)라는 단일 프로토콜에 의존합니다.
아래 그림은 클라이언트 애플리케이션에서 카우치베이스 데이터 플랫폼 내에서 데이터가 압축되는 스토리지까지 데이터 흐름의 다양한 단계를 보여줍니다.
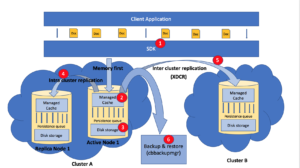
그림 2. 카우치베이스 데이터 플랫폼의 데이터 압축
- 그리고 SDK 는 애플리케이션 사용자의 선택에 따라 압축 또는 압축 해제 모드로 데이터를 수신하도록 선택할 수 있습니다. SDK는 관리되는 캐시에 플래그를 통해 이 상태를 표시합니다.
- 그리고 관리 캐시 키 값 저장소인 키값 저장소는 이제 압축 및 압축 해제된 데이터를 모두 수신할 수 있는 압축을 지원합니다.세 가지 모드로 작동합니다:
꺼짐: 압축 없음
패시브 : (기본값) 캐시에 압축된 문서가 수신되면 압축된 형태로 저장되지만 압축되지 않은 문서에 대해서는 압축을 시도하지 않습니다.
활성: 압축되지 않은 문서도 압축되어 저장됩니다.
- 에서 디스크를 사용하면 데이터는 항상 압축된 형태로 저장됩니다.
- 그리고 데이터센터 간 복제(XDCR) 는 압축을 지원합니다. 하지만 데이터 센터 간에 데이터를 복제하는 동안 압축을 사용하려면 사용자가 선택해야 합니다.
- Cbbackupmgr 는 카우치베이스의 기본 백업 및 복원 기술입니다. 5.0 cbbackupmgr은 백업 시 데이터를 압축하여 저장할 수 있는 압축을 지원합니다.
모든 복제는 데이터베이스 변경 프로토콜에 의해 처리되며 문서 압축을 지원합니다. 그러나 XDCR, 백업 및 복원 등과 같은 DCP의 클라이언트는 특정 클라이언트가 제공한 입력에 따라 압축 또는 비압축 데이터를 DCP로부터 수신합니다.
압축은 기존 배포에서도 스토리지, 네트워크, 메모리 비용을 최소화하기 때문에 Couchbase 데이터 플랫폼의 고객에게 상당한 가치를 더한다고 생각합니다. AWS, Azure 또는 GCP와 같은 퍼블릭 클라우드에 Couchbase를 배포하는 기업의 경우, 클라우드 제공업체가 대역폭 사용량에 따라 요금을 부과하므로 데이터 센터 간에 대량의 데이터(TB)를 복제하는 동안 대역폭을 절약하면 비용 절감으로 직결됩니다.
참고하세요: 궁극적인 효율성은 데이터 유형, 사용 가능한 대역폭, 처리량에 미치는 영향, CPU 사용률 등과 같은 다양한 요인에 따라 달라지기 때문에 데이터가 항상 압축되거나 압축되지 않는 것을 결정하는 경험 법칙은 없으며, 시스템은 모든 요인에 따라 최대 효율을 가진 경로를 선택하도록 설계되어 있습니다.
여기에서 피드백과 경험을 공유하거나 다음 연락처로 문의해 주세요. 포럼. 참조 카우치베이스 압축 관련 문서는 여기에서 확인하세요..
이 게시물을 작성해 주신 Chaitra에게 감사드립니다.
(디스크에서) 달성된 압축률을 측정할 수 있는 방법이 있나요? 버킷에 100개의 문서가 채워져 있다고 가정해 봅시다. 일단 압축이 완료되면 3~4개의 다른 버전이 있음을 알 수 있습니다. 따라서 각 문서의 크기를 알 수 없으므로 문서 수에 각 문서의 크기를 곱할 수 없습니다. 그리고 각 맛에 대한 하나의 (샘플) 문서를 식별하더라도 해당 맛의 모든 문서가 같은 크기일 필요는 없습니다. 그리고 모든 100m 문서의 평균 크기를 구할 수 있는 방법이 없는 것 같습니다(또는 방법이 있나요?).
그런 다음 디스크의 데이터 크기를 보면 압축 후의 크기입니다.
압축 전 크기를 알고 이를 디스크의 크기(압축된 데이터)와 비교했다면 압축률을 결정할 수 있었을 것입니다.
고마워요