시맨틱 검색에 선택성이 필요한 이유는 무엇인가요?
지금까지는 벡터 임베딩을 완전한 독립형 엔티티로 간주했으며, 전적으로 인코딩하는 의미에만 초점을 맞췄습니다. 이렇게 하면 시맨틱 검색이 가능하지만, 종종 높은 수준의 유사성를 사용하면 쿼리와 데이터 세트 임베딩 간의 유사성으로만 제한됩니다.
벡터 유사도 검색 서비스는 정확한 술어를 만족시키는 데 의존할 수 없었습니다. 사전 필터링은 일부 필터링 기준을 충족하는 벡터 중에서 유사한 벡터만 검색함으로써 이러한 간극을 정확히 해결하는 것을 목표로 합니다.
임베딩은 구직이든 부동산이든 검색 범위를 특정 지역으로 제한하는 것과 같습니다. 특정 주의 해변가 부동산을 찾고 있다고 가정해 보겠습니다. 또한 침실이 3개 이상인 숙소로 검색을 제한하고 싶을 수도 있습니다. 이러한 기준을 필터링할 수 있는 방법 없이 숙소를 검색하는 것은 수많은 숙소를 고려할 때 거의 불가능합니다.
사전 필터링을 사용하면 지리적 공간 및 숫자 쿼리를 통해 검색 공간을 적격 숙소로 제한하여 특정 위치로 검색을 제한할 수 있습니다. 이 제한된 하위 집합에서 "해변가", "해변가", "워터프론트" 숙소에 대한 벡터 유사도 검색이 수행됩니다.
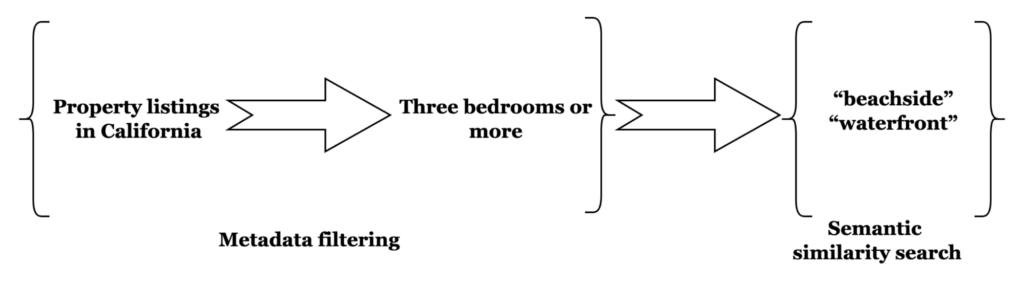
사전 필터링을 통해 사용자는 쿼리에서 kNN 속성의 일부로 필터 쿼리를 지정할 수 있으며, 그 결과만 kNN 쿼리에서 반환할 수 있는 것으로 간주됩니다. 간단히 말해, 사용자는 이제 익숙한 FTS 쿼리 구문을 사용하여 다음과 같은 작업을 수행할 수 있습니다. kNN 검색이 수행될 문서를 제한합니다..
사전 필터링은 언제 적용하나요?
이름에서 알 수 있듯이 임베딩은 메타데이터 필터링이 적용됩니다. 전에 를 사용하여 유사도 검색을 수행합니다. 이는 kNN 검색 후 메타데이터 필터링이 뒤따르는 사후 필터링과는 다릅니다. 사전 필터링은 필터링 단계를 통과한 문서가 적어도 그 수만큼 많다는 가정 하에 히트 문서를 반환할 확률이 훨씬 더 높습니다.

작동 방식
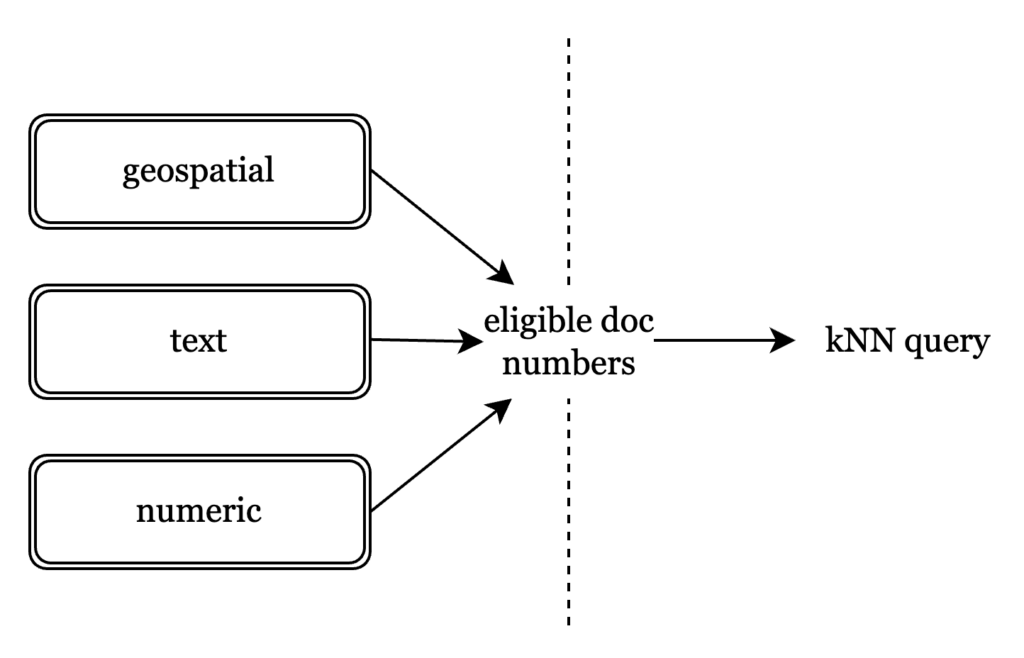
kNN을 사용한 사전 필터링에 대해 자세히 알아보기 전에 검색 서비스 인덱스에 벡터 인덱스와 전체 텍스트 인덱스가 어떻게 함께 배치되는지 이해해 보겠습니다. 각 검색 인덱스에는 하나 이상의 파티션이 있으며, 각 파티션에는 하나 이상의 세그먼트가 있습니다. 이러한 각 세그먼트는 파일이며, 파일은 인덱스 유형당 하나씩 별도의 섹션으로 나뉩니다. 세그먼트를 텍스트와 벡터 콘텐츠가 모두 포함된 독립된 단위로 보는 것은 문서 배치 인덱싱은 세그먼트 수준에서 사전 필터링이 어떻게 작동하는지 이해하는 데 유용합니다.
 이를 구축할 때 주요 고려 사항은 다음과 같아야 한다는 것이었습니다. 술어에 구애받지 않는 로 설정할 수 있습니다. 즉, 벡터 인덱스에서의 필터링은 전체 텍스트 술어에 관계없이 동일한 방식으로 작동해야 한다는 뜻입니다. 텍스트 필드에 대한 텍스트 술어는 다른 필드에 대한 숫자 술어와 다르지 않아야 합니다.
이를 구축할 때 주요 고려 사항은 다음과 같아야 한다는 것이었습니다. 술어에 구애받지 않는 로 설정할 수 있습니다. 즉, 벡터 인덱스에서의 필터링은 전체 텍스트 술어에 관계없이 동일한 방식으로 작동해야 한다는 뜻입니다. 텍스트 필드에 대한 텍스트 술어는 다른 필드에 대한 숫자 술어와 다르지 않아야 합니다.
이를 위해 문서 고유의 식별자인 문서 번호는 어떤 문서가 kNN 쿼리에 적합한지 구분하는 데 사용됩니다. 텍스트, 숫자, 위치 기반 정보 등 모든 FTS 쿼리는 문서 번호로 히트를 식별하는 것으로 요약됩니다. 문서 번호를 사용하면 벡터에 대한 인덱싱 전략을 변경할 필요가 없고 검색 시간 변경으로 제한할 필요가 없습니다.
1단계: 메타데이터 필터링
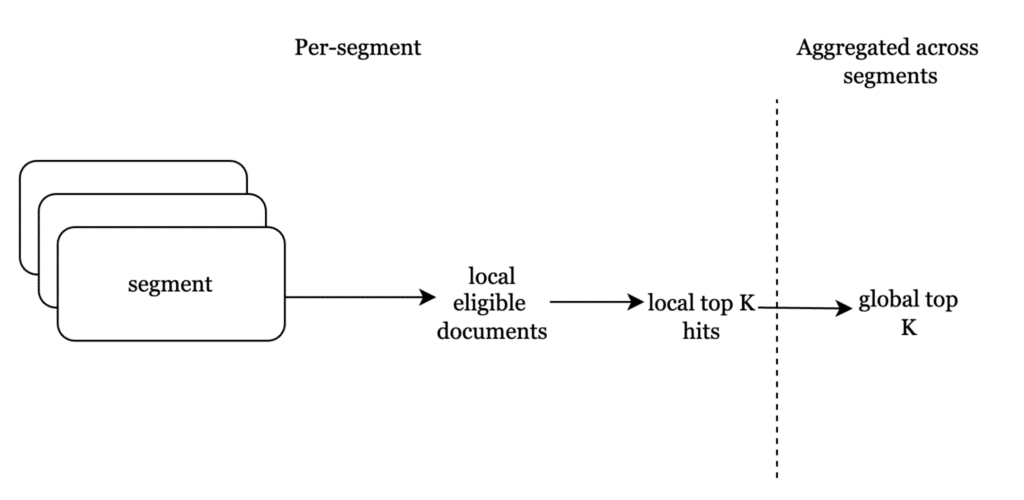
세그먼트는 기본적으로 텍스트 및 벡터 콘텐츠가 색인된 불변의 문서 배치이므로, 전체 텍스트 메타데이터 쿼리는 모든 적격 문서를 반환합니다. 세그먼트 수준에서. 그런 다음 문서 번호가 벡터 인덱스로 전달되어 가장 가까운 적격 벡터를 검색합니다.
2단계: kNN 검색

클러스터 닫기 를 쿼리 벡터에 추가하면 훨씬 더 멀리 있는 쿼리 벡터보다 적격 조회 수가 훨씬 적을 수 있습니다.
리콜을 높게 유지하면서 필터 히트 분포를 고려한다는 것은 필터 히트 밀도만을 기준으로 클러스터를 스캔할 수 없다는 것을 의미합니다. 즉, 필요한 만큼 많은 클러스터를 스캔하여 부적격 벡터에 대한 거리 계산을 최소화하여 가장 가까운 이웃.
더 일찍, nprobe 는 절대 제한 를 스캔하는 클러스터 수로 변경합니다. 이제 더 적은 수의 클러스터에 충분한 적격 벡터가 있다고 가정할 때 스캔할 최소 클러스터 수에 가깝습니다. 각 클러스터에 적격 벡터가 상대적으로 적은 희소 필터 히트 분포의 경우, 가장 가까운 이웃 k 개를 찾으면 다음과 같은 결과를 얻을 수 있습니다. N프로브 클러스터보다 훨씬 더 많은 것을 스캔합니다.. 필터링된 클러스터와 필터링되지 않은 클러스터 모두 쿼리 벡터로부터 거리가 멀어지는 순서대로 클러스터를 스캔하며, 그 차이는 잠재적으로 더 많은 수의 클러스터에 걸쳐 벡터의 하위 집합을 스캔하는 데 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
eligible_clusters: clusters with at least 1 filtered hit if eligible_clusters < nprobe : scan all clusters else: total_hits(1,n): Cumulative count of eligible hits in closest 'n' eligible clusters if total_hits(1,nprobe) >= k: scan nprobe eligible clusters else: while total_hits(1,n) < k: n++ scan n eligible clusters |
벡터 인덱스가 세그먼트 수준에서 가장 유사한 벡터를 반환하면, 필터링 없이 kNN에서 수행되는 방식과 유사하게 글로벌 인덱스 수준에서 집계됩니다.
사용 방법
버킷을 가져가 보겠습니다, 랜드마크. 이것은 샘플 문서입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "title": "Los Angeles/Northwest", "name": "El Cid Theatre", "alt": null, "address": "4212 W Sunset Blvd", "directions": null, "phone": null, "tollfree": null, "email": null, "url": null, "hours": null, "image": null, "price": null, "content": "Built around turn of the century and, after several reincarnations, offers one of the only dinner theater options left in Los Angeles. The menu is heavily Spanish and the shows differ depending on the night and range from flamenco performances to tongue-in-cheek burlesque.", "geo": { "accuracy": "ROOFTOP", "lat": 34.0939, "lon": -118.2822 }, "activity": "do", "type": "landmark", "id": 35034, "country": "United States", "city": "Los Angeles", "state": "California", "embedding_crc": "fa6edfd97ffa665b", "embedding": [-0.003134159604087472, -0.020280055701732635,.... -0.014541691169142723] } |
인덱스를 만듭니다, 테스트, 를 인덱싱하는 임베딩, id 그리고 도시 필드.
첫 번째 질문은 길링엄에 있는 왕립 엔지니어 박물관을 임베딩하는 것입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "knn": [ { "k": 10, "field": "embedding", "vector": [ 0.0022478399332612753, .... ] } ], "explain": true, "size": 10, "from": 0 } |
가장 가까운 곳은 런던 소방대 박물관, 세인트 알반스의 베룰라미움 박물관, 런던의 RAF 박물관입니다.
이제 글래스고에서 유사한 박물관을 검색하려고 합니다. 즉, 도시 필드에 값이 있어야 합니다. 글래스고.
필터링된 쿼리의 모습은 다음과 같습니다. 필터 절을 추가했습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "knn": [ { "k": 10, "field": "embedding", "vector": [ 0.0022478399332612753, .... ], "filter": { "match": "Glasgow", "field": "city" } } ], "explain": true, "size": 10, "from": 0 } |
예상대로 글래스고에서 가장 가까운 켈빙그로브 미술관 및 박물관과 리버사이드 박물관에 한정되어 있습니다.
이 예에서 볼 수 있듯이, 필터링된 kNN 쿼리는 좋은 FTS 쿼리를 사용하여 유사성 검색을 위한 문서를 선택할 수 있는 이점을 제공합니다.
계속 학습하기
-
- 블로그에서 FAISS와 벡터 인덱싱에 대해 자세히 알아보세요, 벡터 검색 성능: 리콜의 부상
- Couchbase로 더 빠르고 저렴하게 LLM 앱 구축하기
- 시맨틱 검색이란 무엇인가요?
- 지금 바로 카우치베이스 카펠라를 사용하세요, 무료
