카우치베이스 4.5가 출시되었습니다!! Part2 는 이 블로그의 연장선상에 있으며 배열 인덱스, UNNEST, ALL, ANY 및 EVERY 등과 같은 더 많은 연산자 지원 등을 다룹니다,
배열이 내장된 문서가 있고 해당 배열에 저장된 데이터에 액세스할 수 있는 효율적인 수단이 필요하신가요? 배열은 NoSQL/JSON 데이터 모델링의 강력한 기능 중 하나입니다. 배열은 여러 전화번호, 자녀 정보, 항공편 일정, 제품 리뷰, 블로그 댓글 및 답변 등과 같은 여러 값의 데이터를 문서 속성 안에 저장할 수 있습니다. 배열은 모든 관련 데이터를 동일한 문서에 함께 보관할 뿐만 아니라 불필요한 조인을 방지하여 쿼리 성능을 향상시킵니다. 문서의 배열은 Couchbase나 N1QL(JSON용 SQL)에 새로운 것이 아니며, 이미 배열을 저장, 색인, 처리하기 위한 다양한 구조와 연산자를 갖추고 있습니다.
카우치베이스 4.5 개발자 프리뷰는 다음에 대한 지원을 추가합니다. 배열 인덱싱 를 사용하여 개별 배열 요소 또는 배열 내에 중첩된 개체/속성을 색인하고 쿼리할 수 있습니다. 배열 인덱싱은 배열과 관련된 쿼리, 특히 배열 내의 값과 속성에 액세스하는 쿼리의 성능을 크게 향상시킵니다. 또한 배열 속성의 처리를 간소화하여 N1QL 쿼리. 이는 보조 인덱스를 생성한 후 전체 배열의 콘텐츠에 대해서만 쿼리할 수 있었던 이전 버전에서 크게 도약한 것입니다.
마법이 어떻게 작동하는지 살펴봅시다. 다음과 같이 'travel-sample' 버킷과 제품과 함께 배송되는 일정 배열 속성을 사용하여 문서의 유형 = “경로“

이전 버전에서는 인덱스가 생성될 때 일정 를 사용하면 전체 배열이 모든 콘텐츠/요소를 하나의 스칼라 값으로 인덱싱됩니다. 즉, 위 예제에서 파란색 상자에 표시된 모든 것이 하나의 단일 인덱스 값으로 간주됩니다. 따라서 나중에 쿼리할 때 일정에 전체 배열 값을 제공해야 합니다. WHERE-절 를 사용하여 인덱스를 사용해야 합니다. 이는 단순/소규모 배열의 경우 관리가 가능할 수 있지만 일반적으로 다음과 같은 문제가 있습니다:
-
배열 내에서 세분화된 데이터를 인덱싱합니다: 배열의 하위 집합만 인덱싱하려면 어떻게 해야 하나요? 비행 속성의 일정 배열을 사용하시나요, 아니면 특정 날짜에만 사용하시나요?
-
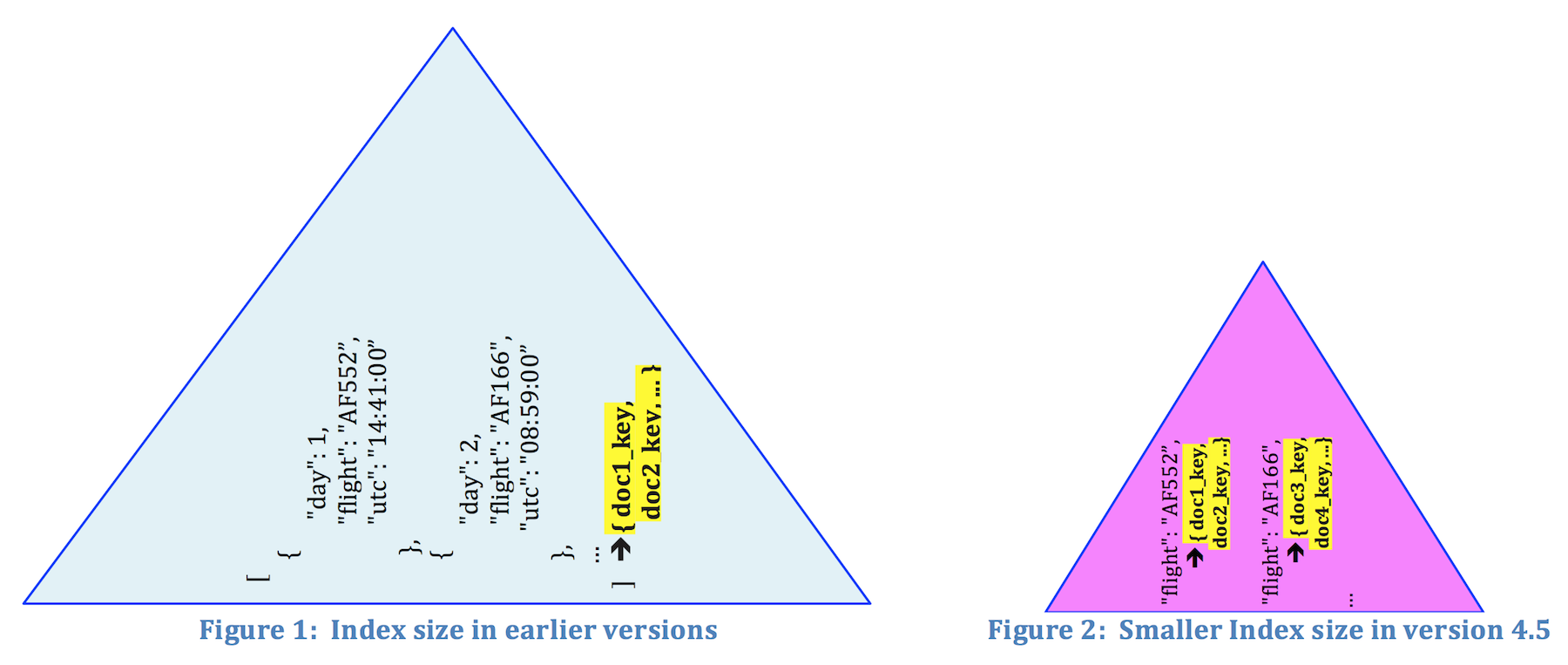
인덱스 크기 및 성능: 전체 배열을 인덱싱하면 인덱스 저장 공간이 더 많이 소모되고 인덱스를 검색하는 데 시간이 더 오래 걸립니다. 그림 1은 속성에 대해 생성된 인덱스를 보여줍니다. 일정 4.5 이전 버전으로.
-
배열 내에서 검색하기: 전체 배열을 인덱싱하면 배열 내의 특정 데이터를 효율적으로 검색할 수 없습니다. 애플리케이션이 원하는 데이터를 찾으려면 먼저 전체 배열 값을 가져오거나 선택한 다음 이를 처리해야 합니다.
-
대형 배열: 배열에 많은 요소가 있는 경우 전체 배열 값을 WHERE 절에 제공하는 것은 편리하지 않으며 때로는 불가능합니다.
Couchbase 4.5의 배열 인덱싱은 이러한 모든 문제를 해결하고 인덱싱된 배열을 활용할 수 있도록 N1QL 및 인덱서 기능이 향상되었습니다. 여기에는 부분 인덱스, 중첩 배열, 복합 인덱스 및 다음과 같은 연산자에 대한 지원이 포함됩니다. 임의, 내부, 고유 배열. 몇 가지 예를 살펴보겠습니다:
-
먼저, 배열 인덱스를 생성합니다. 일정 속성을 사용하여 배열 구분 연산자를 사용하여 인덱스 키로 사용할 정확한 배열 요소 또는 중첩된 속성을 지정할 수 있습니다. 다음 문은 다음을 인덱싱합니다. "평일에 예약된 모든 항공편(예 일 <= 5)”. 관심 있는 배열 요소의 하위 집합에만 인덱스를 생성할 수 있다는 점에 유의하세요. 따라서 새로운 배열 인덱스는 간결하고 효율적이며(그림 2 참조), 필요한 정보만 인덱스에 저장합니다.
|
1 2 3 4 |
CREATE INDEX isched ON `travel-sample`(DISTINCT ARRAY v.flight FOR v IN schedule WHEN v.day <= 5 END) WHERE type = "route"; |
-
이제 WHERE 절에 인덱스 키와 인덱스 술어를 지정하여 SELECT 또는 다른 DML 문에서 인덱스를 사용할 수 있습니다. 현재 릴리스에서, 정확한 변수 이름을 지정해야 합니다., 인덱스 키 (예 브이, 브이데이, 브이플라이트), 및 술어 (유형 = "경로") 그리고 (v.day = 4) 인덱스 생성 정의에 지정된 것과 일치합니다.. 이 인덱스 선택 기준은 N1QL이 쿼리를 처리하기 위해 일치하는 인덱스를 자동으로 선택하는 데 필요합니다. 평소와 같이, 언제 일치하는 인덱스가 여러 개 생성됩니다, USE INDEX 절을 사용하여 N1QL이 특정 인덱스를 사용하도록 제안할 수 있습니다.
예를 들어 다음 쿼리는 "4에 예약된 UA 항공편 수th day" 배열 인덱스를 사용합니다. 이 쿼리는 isched 인덱스는 인덱스 선택 요구 사항을 따르기 때문입니다:
-
변수 v 가 사용되며, 이는 인덱스 정의에 사용된 정확한 변수입니다.
-
인덱스 키 v.flight 는 WHERE 절에 사용됩니다.
-
인덱스 술어(유형 = "경로") 그리고 (v.day = 4) 는 WHERE 절에 사용됩니다. 참고 (v.day = 4)에 의해 "포함"되기 때문에 일치하는 것으로 간주됩니다. (v.day <= 5)인덱스 생성 정의에 지정되어 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
EXPLAIN SELECT count(*) FROM `travel-sample` USE INDEX(isched) WHERE type = "route" AND ANY v IN schedule SATISFIES v.flight LIKE "UA%" AND v.day = 4 END; { "requestID": "90da999e-114d-4f13-ad6f-d4ab30512b1c", "signature": "json", "results" : [ { "#operator": "Sequence", "~children": [ { "#operator": "DistinctScan", "scans": [ { "#operator": "IndexScan", "index": "isched", "keyspace": "travel-sample", "namespace": "default", ... |
- 성능: 배열 인덱스는 인덱스를 활용할 수 있는 쿼리의 성능을 크게 향상시킵니다. 예를 들어 배열 인덱스를 사용하는 위의 (2)의 쿼리는 다음과 같습니다. 'isched' 는 제 노트북에서 약 256ms가 걸렸습니다. 그러나 인덱스를 사용하여 다음 쿼리를 수행하면 'def_type' 는 거의 2.38초가 걸렸습니다. 이는 배열 인덱스를 사용하면 무려 9배나 향상된 성능입니다.
|
1 2 3 4 5 |
SELECT count(*) FROM `travel-sample` USE INDEX(def_type) WHERE type = "route" AND ANY v IN schedule SATISFIES v.flight LIKE "UA%" AND v.day = 4 END; |
배열 인덱싱에 대해 자세히 알아보고 복합 및 중첩 배열 인덱스와 같은 더 많은 예제를 보려면 Couchbase 4.5에서 확인할 수 있습니다. 문서를 클릭하고 데모.
한번 사용해 보시고 질문/의견이 있으시거나 얼마나 멋진지 알려주세요 ;-)
건배!!