카우치베이스는 다음용 SDK를 도입하여 고성능 데이터 분석을 지원하는 데 계속해서 앞장서고 있습니다. 카펠라 칼럼의 최첨단 분석 데이터베이스로, 실시간 JSON 분석을 위해 설계되었으며, ETL이 필요 없고 운영상 쓰기백 옵션이 있습니다. 컬럼형 데이터베이스에 빠르고 안정적으로 액세스해야 하는 개발자를 위해 이 SDK는 여러 프로그래밍 언어에 걸쳐 원활한 통합을 제공합니다. 구축 대상 언어 Java, Python또는 Node.js를 사용하면 최소한의 노력으로 Couchbase의 분석 데이터베이스의 고급 기능을 활용할 수 있는 Capella Columnar SDK를 사용할 수 있습니다.
이 블로그 게시물에서는 새로 출시된 새로운 기능의 주요 기능, 이점 및 사용 사례를 살펴봅니다. 카펠라 컬럼형 SDK-데이터 집약적인 애플리케이션을 개발하는 개발자를 위해 데이터 작업을 간소화하는 방법을 보여줍니다. 또한 접근 방식의 단순성과 일관성을 설명하기 위해 코드 예제를 보여줍니다.
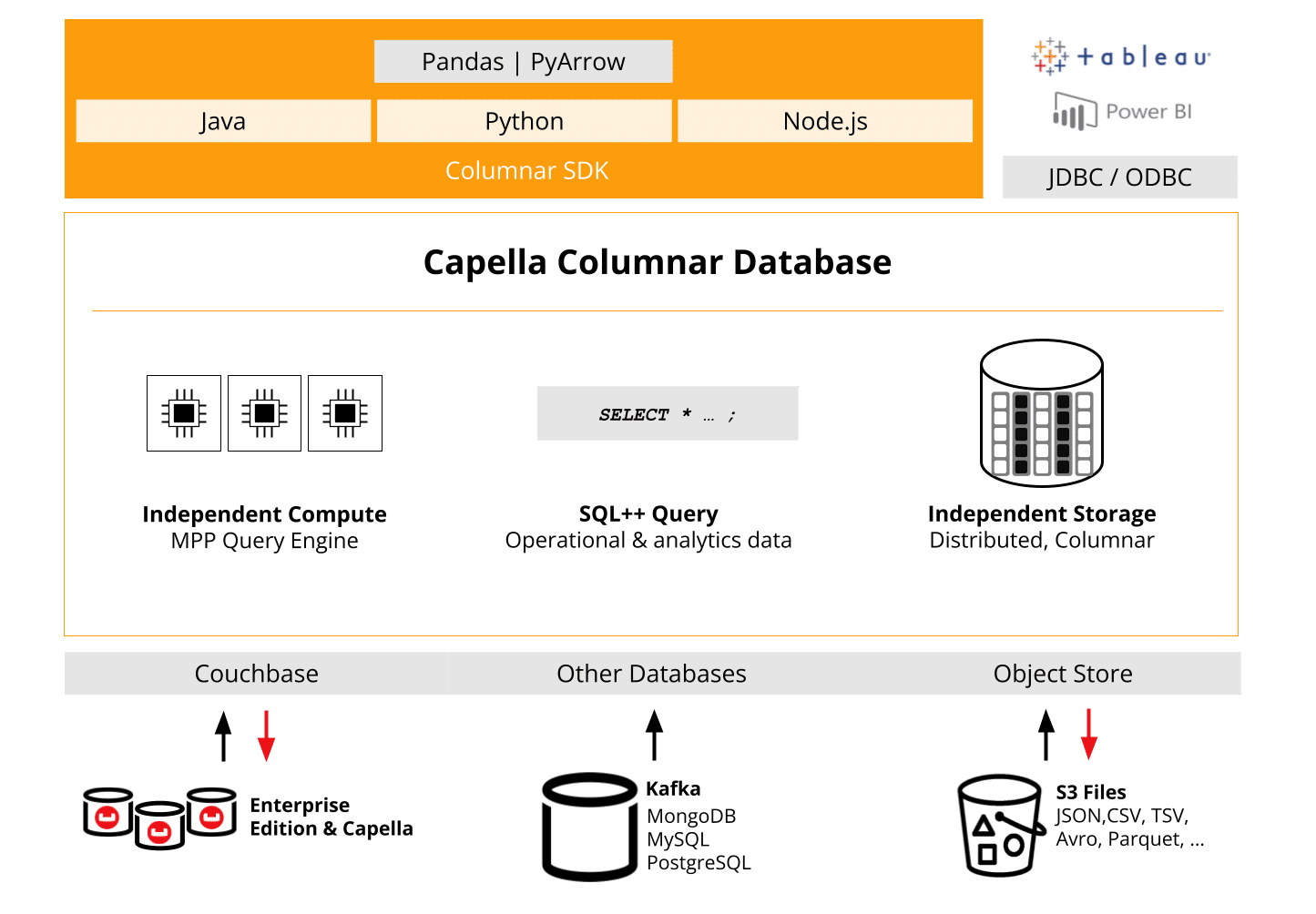
실시간 분석을 위해 특별히 제작된 SDK
Capella Columnar SDK의 핵심 강점 중 하나는 데이터 액세스 및 쿼리 성능을 최적화하는 기능으로, 대규모 분석 워크로드에 이상적입니다. 실시간 데이터 분석과 일괄 처리에 점점 더 의존하는 조직이 늘어나면서 효율적인 쿼리 및 리소스 관리가 중요해지고 있습니다.
Capella Columnar SDK는 이러한 요구사항을 염두에 두고 설계되었으며, 개발자가 까다로운 조건에서도 데이터 상호 작용을 미세 조정하고 높은 처리량을 보장하는 데 도움이 되는 다양한 기능을 제공합니다. 이 SDK는 처음부터 고성능과 안정성을 위해 특별히 제작되어 지름길(예: API를 통한 래퍼 등)을 사용하지 않았습니다.
Capella Columnar SDK의 중심에는 세 가지 핵심 요소가 있습니다:
- 개발의 용이성
개발자는 추가 도구나 구성 없이도 기존 기술 스택 내에서 Couchbase의 컬럼형 데이터베이스와 상호 작용할 수 있습니다. SDK는 기본적으로 각 언어를 지원하며 다음을 제공합니다. 관용적 API 개발자에게 자연스러운 느낌을 줍니다. - 검색 가능한 API
SDK는 완전히 검색 가능한 API로 설계되었습니다. 즉, 여러분의 IDE를 사용하면 함수, 클래스 및 매개변수에 대한 자동 완성 및 제안을 통해 개발 주기를 단축할 수 있습니다. 더 이상 올바른 방법을 찾아 헤맬 필요 없이 SDK가 빌드하는 동안 여러분을 안내합니다. - 견고성
성능을 염두에 두고 제작된 SDK는 다음과 같은 고급 기능을 제공합니다. 연결 관리, 오류 처리, 시간 초과및 재시도. 이러한 기능은 부하가 높거나 내결함성 환경에서도 애플리케이션이 안정적으로 유지되도록 보장합니다.
플랫폼 및 언어 지원
Capella Columnar SDK는 다음과 같은 다양한 플랫폼과 언어를 지원합니다:
- 언어: Java(17+), Python(3.9-3.12), Node.js(v20, v22)
- 운영 체제: Linux, Windows, macOS(AWS Graviton 및 Apple M1과 같은 ARM 프로세서 지원 포함)
이러한 플랫폼 전반에 걸쳐 지원을 제공함으로써 Couchbase는 개발자가 클라우드 인프라에서 온프레미스 시스템에 이르기까지 다양한 환경에 애플리케이션을 배포할 수 있도록 보장합니다.
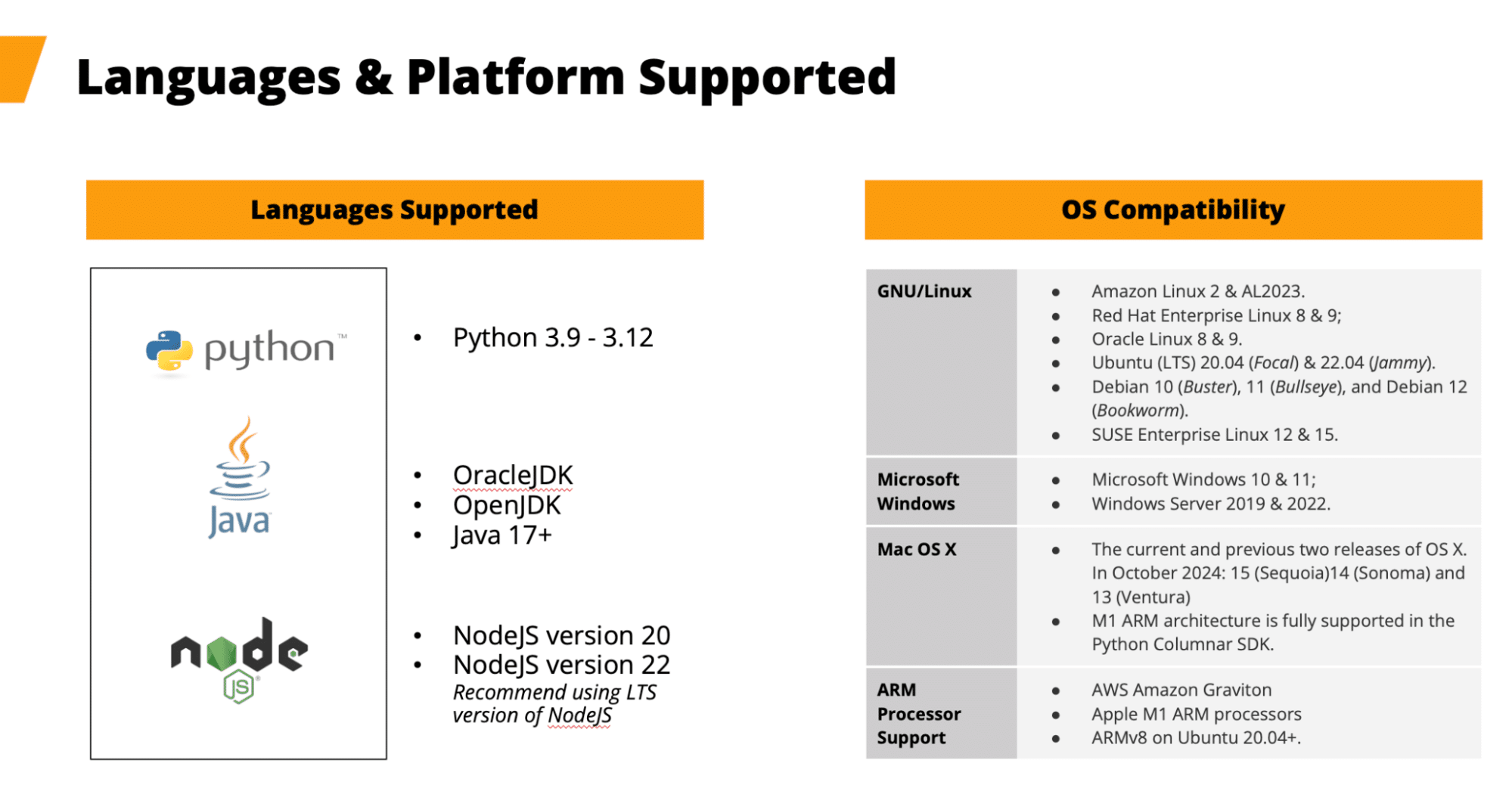
그림 2. 언어/플랫폼 지원에 대한 변경 사항은 SDK 설명서를 참조하세요.
카우치베이스는 SDK 버전 간 하위 호환성을 유지하여 개발자가 변경 사항에 대한 걱정 없이 애플리케이션을 업그레이드할 수 있도록 함으로써 미래 대비를 우선시합니다. 이러한 노력으로 새로운 기능과 개선 사항이 도입되더라도 기존 기능은 그대로 유지되므로 조직은 기존 워크플로우를 유지하면서 최신 기능을 활용할 수 있습니다.
카펠라 컬럼형 SDK가 대규모 마스터 데이터를 지원하는 방법
그리고 카우치베이스 카펠라 컬럼형 SDK 는 일관성, 성능, 확장성에 중점을 두고 대규모 데이터 분석을 효율적으로 관리할 수 있는 포괄적인 도구 세트를 제공합니다.
다음은 핵심 기능에 대한 개요입니다:
여러 언어에 걸친 통합 API
카펠라 컬럼형 SDK는 다음과 같은 기능을 제공합니다. 일관된 API 다음과 같은 언어에 걸쳐 Java, Python및 Node.js를 사용하여 팀 간 협업을 간소화하고 개발자가 통합된 개발 환경을 유지하면서 언어 간에 전환할 수 있습니다.
간소화된 데이터 관리 및 쿼리 실행
이러한 SDK는 다음에 대한 직관적인 액세스를 제공합니다. 범위 및 컬렉션를 모두 지원하며 동기 및 비동기 API 호출. 쿼리 실행을 위해 다음과 같은 옵션을 사용하여 유연한 SQL++ 쿼리를 사용할 수 있습니다. 버퍼링된 읽기 (인메모리 데이터 세트의 경우) 및 스트리밍 읽기 (대규모 데이터 세트의 실시간 처리를 위해)를 사용하여 운영상의 필요에 따라 성능을 최적화합니다.
탄력적인 연결 관리 및 오류 처리
SDK는 자동으로 다음과 같이 조정됩니다. 데이터베이스 토폴로지 변경를 통해 원활한 성능을 보장합니다. 장애 조치 또는 리밸런싱. 또한 다음과 같은 특징이 있습니다. 자동 쿼리 재시도 를 제공하고 오류 메시지 지우기 카우치베이스의 애널리틱스 오류 코드 를 사용하여 빠른 문제 해결을 지원합니다.
크로스 플랫폼 지원 및 버전 관리 유연성
다음과 같은 다양한 환경을 지원합니다. Linux, Windows, MacOS및 ARM 프로세서SDK는 인프라 전반에 걸쳐 유연성을 제공합니다. 그들의 버전이 지정된 API 프레임워크 는 새로운 Couchbase 기능과의 호환성을 보장하므로 개발자가 호환성 문제 없이 업데이트를 통합할 수 있습니다.
확장성 및 분산 아키텍처
카펠라 컬럼형 SDK는 카우치베이스의 분산 아키텍처 자동 데이터 파티셔닝을 위한 데이터 센터 간 복제(XDCR). 이를 통해 여러 노드 및 지역에 걸쳐 원활하게 확장할 수 있으므로 다음을 보장합니다. 고가용성 효율적인 글로벌 데이터 배포 애플리케이션이 성장함에 따라
카펠라 컬럼형 SDK의 사용 사례
실시간 데이터 분석
실시간 분석을 처리하는 조직의 경우, Capella Columnar SDK를 사용하면 데이터 처리를 간소화할 수 있습니다. 와 함께 스트리밍 쿼리 지원를 사용하면 개발자가 들어오는 데이터를 행 단위로 처리할 수 있으므로 다음과 같은 시나리오에 적합합니다. 로그 분석, IoT 센서 데이터또는 실시간 금융 거래.
광고 타겟팅 사용 사례 예시
Capella Columnar SDK를 사용한 실시간 분석 사용 사례에는 예를 들어 S3 버킷의 클릭스트림 또는 웹 상호 작용 데이터를 통합하여 적시성 광고 게재를 추진하는 것이 포함될 수 있습니다. 이 시나리오에서는 웹사이트의 실시간 사용자 상호작용을 캡처하는 클릭스트림 데이터가 외부 링크 구성을 사용하여 Capella Columnar로 스트리밍됩니다. SDK는 이 데이터가 도착하는 즉시 유연한 SQL++ 쿼리를 사용하여 빠르고 효율적으로 쿼리하여 사용자 행동을 즉각적으로 분석할 수 있도록 지원합니다.
동시에 NoSQL 또는 관계형 데이터베이스에 저장된 사용자 프로필 데이터는 Kafka 커넥터를 통해 시스템으로 공급되어 각 사용자의 선호도와 기록을 통합적으로 파악할 수 있습니다. 이러한 데이터 스트림을 Columnar SDK에서 사용하는 코드와 결합함으로써 기업은 광고 타겟팅 전략을 최적화하여 사용자의 최신 상호 작용과 과거 선호도를 기반으로 개인화된 광고를 제공할 수 있으며, 이 모든 과정은 Capella Columnar의 분산 아키텍처를 사용하여 대규모로 신속하게 처리됩니다.
데이터 과학 모델을 다른 도구에 적용하여 트렌드를 찾고 최종 사용자에게 적절한 경험을 제공하는 분석 결과를 구축할 수 있습니다. 이를 통해 시의적절하고 관련성 높은 광고를 게재할 수 있으며, SDK에 구축된 애플리케이션을 통해 참여도와 전환율을 극대화할 수 있습니다.
일괄 데이터 처리
데이터가 대량으로 처리되는 보다 전통적인 분석 워크로드의 경우, 데이터를 대량으로 처리하는 버퍼링 쿼리 모드 는 데이터 세트를 메모리에 로드하는 동안 효율적인 메모리 사용을 보장합니다. 다음과 같은 사용 사례 ETL 프로세스, 비즈니스 인텔리전스및 데이터 웨어하우징 이 기능의 이점을 누릴 수 있습니다. BI 도구는 SQL++의 강력한 기능을 사용하여 많은 타사 분석 도구에 의존하지 않고도 높은 가치의 정보를 신속하게 추출할 수 있습니다.
다국어 데이터 작업
그리고 통합 API 를 사용하면 개발팀이 새로운 패턴을 배울 필요 없이 프로그래밍 언어 간에 쉽게 전환할 수 있습니다. 이는 특히 다음과 같은 작업을 하는 팀에 유용합니다. 마이크로서비스 아키텍처에서 서로 다른 컴포넌트를 다른 언어로 작성할 수 있습니다(예: 백엔드 서비스용 Java, 실시간 API용 Node.js).
기술 개요: 시작하기
모든 Capella Columnar SDK를 얼마나 쉽게 시작할 수 있는지 알려드리기 위해, 다음 예시를 통해 Capella Columnar 클러스터에 연결하는 방법을 알려드리겠습니다. Python SDK를 참조하세요. Java 및 Node.js용 문서 예제:

그림 3. 파이썬의 연결 관리 코드 예제
이 과정은 전반적으로 유사합니다. 모든 SDK를 사용하여 언어에 관계없이 일관된 환경을 보장합니다. 연결되면 SQL 쿼리를 실행하고, 범위를 관리하고, 컬렉션으로 작업할 수 있습니다.
비동기 쿼리 실행
Python SDK는 동기화 및 비동기 스트리밍 API를 모두 지원합니다. 비차단 작업이 필요한 애플리케이션은 Python의 asyncio 프레임워크를 사용하세요. 이를 통해 쿼리가 완료될 때까지 기다리지 않고 쿼리를 실행할 수 있으므로 특히 대규모 데이터 세트나 느린 작업을 처리할 때 처리량이 증가합니다. 이 예는 또한 버퍼링 데이터 액세스와 스트리밍 데이터 액세스를 보여줍니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
에서 acouchbase_columnar 가져오기 GET_EVENT_LOOP 에서 acouchbase_columnar.클러스터 가져오기 비동기 클러스터 쿼리 = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM `travel-sample`.inventory.route GROUP BY 항공사 ORDER BY route_count DESC """ res = 기다림 클러스터.실행_쿼리(쿼리) # 버퍼링: 쿼리를 실행하고 모든 결과 행을 클라이언트 메모리에 버퍼링합니다. all_rows = 기다림 res.get_all_rows() # 참고: all_rows는 목록이며, `async for`를 _사용하지_ 않습니다. 에 대한 행 in all_rows: 인쇄(f'행을 찾았습니다: {row}') # 스트리밍: 쿼리를 실행하고 서버에서 도착하는 대로 행을 처리합니다. res = 기다림 클러스터.실행_쿼리(문) 비동기 에 대한 행 in res.행(): 인쇄(f'행을 찾았습니다: {row}') |
이 예제에서는 asyncio 이벤트 루프는 쿼리를 비동기적으로 처리하는 데 사용되므로 애플리케이션이 쿼리 결과를 기다리는 동안 다른 작업을 수행할 수 있습니다.
매개 변수화된 쿼리
매개 변수화된 쿼리는 애플리케이션을 다음으로부터 보호하는 데 도움이 됩니다. SQL 인젝션 공격 쿼리 로직과 데이터 입력을 분리합니다. 이는 사용자가 제공한 데이터를 처리할 때 특히 중요합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 위치 매개변수 쿼리 = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$1 AND distance>=$2 GROUP BY 항공사 ORDER BY route_count DESC """ res = 범위.실행_쿼리(쿼리, 쿼리 옵션(위치_파라미터=['SFO', 1000])) # 명명된 매개변수 쿼리 = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$source_airport AND distance>=$min_distance GROUP BY 항공사 ORDER BY route_count DESC """ res = 범위.실행_쿼리(쿼리, 쿼리 옵션(named_parameters={'source_airport': 'SFO', 'min_distance': 1000})) |
이 예에서는 공항 코드를 매개변수로 전달하여 쿼리가 안전하게 유지되고 SQL 인젝션과 관련된 위험을 피할 수 있도록 합니다.
데이터 분석 라이브러리에서 쿼리 결과 사용
Couchbase Columnar SDK는 다음과 같이 널리 사용되는 Python 데이터 분석 라이브러리와 원활하게 통합됩니다. 판다 그리고 PyArrow데이터 과학 및 AI/ML 프로젝트에 일반적으로 사용되는 도구로, 쿼리 결과를 분석 워크플로우에 쉽게 통합할 수 있습니다.
쿼리 결과를 Pandas 데이터 프레임으로 가져오기
이 예는 Couchbase 쿼리 결과를 다음과 같이 쉽게 변환할 수 있는 방법을 보여줍니다. 판다스 데이터프레임를 사용하여 데이터를 조작하고 탐색할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
가져오기 판다 as pd res = 범위.실행_쿼리(쿼리) df = pd.데이터프레임.from_records(res.행(), 색인='항공사') 인쇄(df.head()) # 항공사 노선_수 평균_노선_거리 # AA 2354 2314.884359 # UA 2180 2350.365407 # DL 1981 2350.494112 # US 1960 2101.417609 # WN 1146 1397.736500 |
쿼리 결과를 PyArrow 테이블로 가져오기
성능 집약적인 작업의 경우, Couchbase 결과를 다음에서 사용할 수 있습니다. PyArrow 테이블를 사용하여 인메모리 분석 및 컬럼형 스토리지 시스템과의 통합을 용이하게 합니다.
|
1 2 3 4 5 6 7 8 9 10 |
가져오기 pyarrow as pa res = 범위.실행_쿼리(쿼리) 테이블 = pa.표.from_pylist(res.get_all_rows()) 인쇄(테이블.to_string()) # pyarrow.Table # 경로_수: int64 # 평균_경로_거리: 더블 # 항공사: 문자열 |
Pandas와 PyArrow 라이브러리를 모두 지원하는 Couchbase Columnar Python SDK는 기존 데이터 과학 및 데이터 분석 파이프라인과의 통합을 간소화하여 효율적인 데이터 분석 및 처리를 가능하게 합니다.
이 예제에서는 Couchbase SDK를 사용하여 버퍼링, 스트리밍, 비동기 및 매개변수화된 쿼리를 실행하는 방법을 보여줍니다, 를 사용하면 애플리케이션의 요구 사항에 맞게 쿼리 실행을 조정할 수 있습니다.
결론
대규모 데이터 분석 작업을 하는 개발자를 위한 강력한 추가 기능인 Capella Columnar SDK입니다. 여러 언어에 대한 강력한 지원, 간소화된 쿼리 실행, 플랫폼 간 호환성을 갖춘 이 SDK는 최신 데이터 워크로드를 처리하는 데 필요한 유연성, 성능, 안정성을 제공합니다. 실시간 데이터 스트림을 처리하든 복잡한 분석 쿼리를 실행하든, Capella Columnar SDK는 개발 경험을 향상시키도록 설계되었습니다.
지금 바로 Capella Columnar로 가능성을 살펴보고 더 스마트하고 빠른 애플리케이션 구축을 시작하세요!
리소스