인덱스 파티셔닝은 Couchbase Server 5.5에서 사용할 수 있는 새로운 기능입니다.
다음 내용을 확인하세요. 카우치베이스 서버 5.5 개발자 빌드 발표 그리고 릴리스 다운로드 지금 무료로 이용하세요.
이 글에서는 이에 대해 다뤄보려고 합니다:
- 인덱스 분할을 사용해야 하는 이유
- 수행 방법의 예
- 파티션 제거
- 주의해야 할 몇 가지 주의사항
인덱스 파티셔닝
애플리케이션을 개발할 때 인덱싱에 더 많은 리소스를 제공하기 위해 Couchbase Server의 간편한 확장 기능을 활용하고 싶을 수 있습니다. 와 다차원 스케일링(MDS)를 사용하면 필요에 따라 인덱스 기능을 갖춘 여러 대의 고급 머신을 클러스터에 추가할 수 있습니다.
인덱스 서비스에서 여러 노드를 활용하려면 다음을 생성해야 합니다. 인덱스 복제본. 이는 여전히 가능하며, 이 문제가 해결되지 않는다면 사라지지 않을 것입니다.
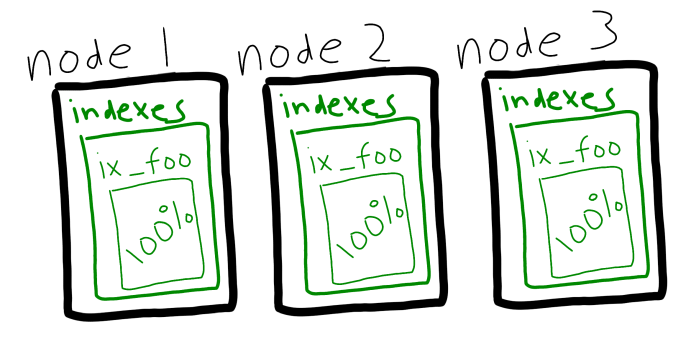
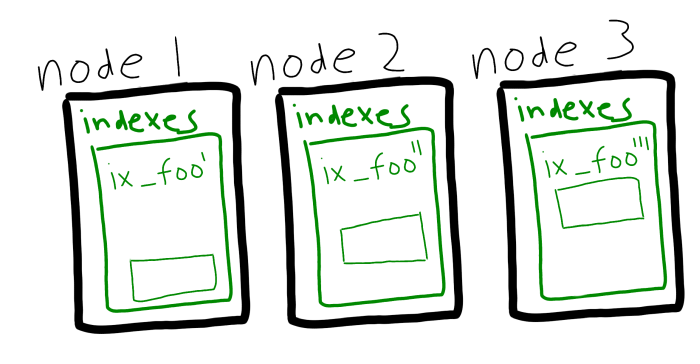
Couchbase Server 5.5에서는 인덱스 부하를 분산하는 또 다른 방법인 인덱스 분할이 도입되었습니다. 이제 인덱스를 복제하는 대신 해싱을 사용하여 노드 간에 인덱스를 분할할 수 있습니다.
그리고 파티셔닝과 복제본을 함께 사용할 수 있습니다. 인덱스 파티션 복제본은 노드가 다운되더라도 중단 없이 자동으로 사용됩니다.
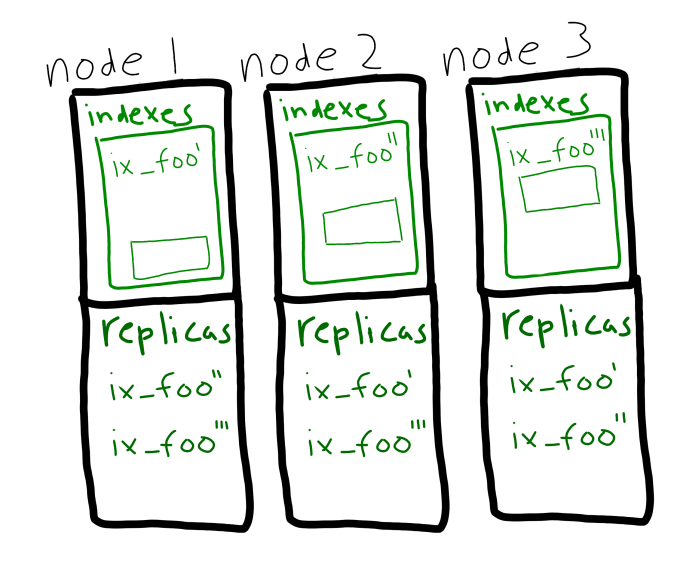
인덱스 파티셔닝의 주요 이점은 다음과 같습니다:
- 인덱스 스캔 로드는 이제 균형 잡힌 를 모든 인덱스 노드에 분배합니다. 이렇게 하면 작업이 더 고르게 분산되고 성능이 향상됩니다.
- 집계를 사용하는 쿼리(예
SUM+그룹 기준)는 다음과 같습니다. 병렬로 실행 를 클릭합니다.
인덱스 분할 사용 방법
인덱스 파티션을 만드는 구문은 다음과 같습니다. PARTITION BY HASH(). 예를 들어, 'travel-sample' 버킷에 항공사, 항공편, source_airport, 목적지_공항 필드에 대한 복합 인덱스를 만들고 싶다고 가정해 보겠습니다:
|
1 |
CREATE INDEX ix_route ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(airline); |
이 인덱스를 생성하면 Couchbase 콘솔에서 "파티션됨"으로 표시됩니다.

파티션 제거
파티션 제거는 인덱스 파티셔닝을 사용하면 얻을 수 있는 이점 중 하나입니다. 이것은 NoSQL 시장에서 Couchbase만이 제공하는 고유한 기능입니다.
위와 같이 항공사 필드에 파티션이 있다고 가정해 보겠습니다. 그런 다음 해당 인덱스를 사용하고 항공사 값을 지정하는 쿼리를 작성합니다:
|
1 2 3 4 |
SELECT t.* FROM `travel-sample` t WHERE airline IN ["UA", "AA"] AND source_airport = "SFO" |
그러면 인덱싱 서비스는 일치하는 파티션("UA" 및 "AA")만 스캔합니다. 이렇게 하면 클러스터 크기에 관계없이 범위 쿼리 응답이 더 빨라지고 지연 시간은 분할되지 않은 인덱스와 동일해집니다. 이에 대해서는 나중에 자세히 설명합니다.
인덱스 파티셔닝 주의 사항
위에서 '항공사'가 사용된 것을 보셨을 것입니다. 인덱스 생성 명령을 사용합니다. 인덱스 분할을 사용할 때는 분할에 사용할 해시에 제공할 필드를 하나(또는 여러 개)를 지정해야 합니다. 이 해시에 따라 인덱스를 분할하는 방법이 결정됩니다.
가장 간단하게 할 수 있는 방법은 해시에 문서 키를 사용하는 것입니다:
|
1 2 |
CREATE INDEX ix_route2 ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(META().Id); |
하지만 Couchbase의 키값 엔진과 달리 원하는 필드를 사용할 수 있습니다. 하지만 다음 필드를 고려해야 한다는 점을 명심해야 합니다. 불변. 즉, 필드 값을 변경해서는 안 됩니다. 따라서 일반적으로 변경되지 않는 값을 가진 필드가 있는 경우(예를 들어 많은 Couchbase 사용자가 '유형' 필드를 만드는 경우) 파티셔닝에 적합한 후보가 될 수 있습니다.
"불변" 필드에서 인덱싱하도록 선택하면 파티션이 약간 왜곡될 수 있다는 경고가 표시됩니다( META().Id 를 사용하면 왜곡이 최소화됩니다). '유형' 필드에서 10%의 문서 유형이 '주문'이고 90%의 문서 유형이 '송장'인 경우, 파티션이 비슷하게 보일 수 있습니다. 인덱스 파티셔닝은 재조정 중에 최적화 알고리즘을 사용하여 RAM, CPU 및 데이터 크기의 균형을 맞추지만 여전히 왜곡이 발생할 수 있습니다.
그래서 META().Id를 사용하지 않는 이유는 무엇입니까? 를 사용하여 왜곡을 줄일 수 있나요? 위의 파티션 제거 섹션을 기억하세요. 쿼리가 인덱스 파티션과 동일한 라인에 속하는 경우, 모든 파티션을 확인해야 하는 '분산+수집' 작업을 최소화하고 지연 시간을 더욱 줄일 수 있습니다.
주의할 점이 하나 더 있습니다: 인덱스 파티셔닝은 Enterprise Edition 전용 기능입니다..
요약
인덱스 파티셔닝을 사용하면 인덱싱 기능을 보다 쉽고 자동으로 확장할 수 있습니다. 프로젝트에서 많은 N1QL 쿼리를 사용하는 경우, 이 기능이 매우 유용하고 작업이 훨씬 쉬워집니다.
인덱스 파티셔닝이나 인덱싱과 관련된 다른 질문이 있는 경우에는 카우치베이스 서버 포럼 또는 N1QL 포럼 색인 및 쿼리 생성에 대해 궁금한 점이 있으면 문의하세요. 다음 사항을 확인하세요. Couchbase Server 5.5 릴리스 다운로드 를 다운로드하여 사용해 보세요. 여러분의 피드백을 듣고 싶습니다.
아래에 댓글을 남기거나 다음에서 저를 찾아 연락하실 수 있습니다. 트위터 @mgroves.