 전체 텍스트 검색은 문서 내의 텍스트 콘텐츠 또는 텍스트 콘텐츠가 포함된 문서 모음을 검색하는 기술을 말합니다. 전체 텍스트 검색 엔진은 단일 검색어 또는 여러 용어를 일치시키기 위해 문서 내의 모든 텍스트 콘텐츠를 검사하며, 텍스트 분석이 핵심적인 구성 요소입니다.
전체 텍스트 검색은 문서 내의 텍스트 콘텐츠 또는 텍스트 콘텐츠가 포함된 문서 모음을 검색하는 기술을 말합니다. 전체 텍스트 검색 엔진은 단일 검색어 또는 여러 용어를 일치시키기 위해 문서 내의 모든 텍스트 콘텐츠를 검사하며, 텍스트 분석이 핵심적인 구성 요소입니다.
가장 잘 알려진 전체 텍스트 검색 엔진에 대해 들어보셨을 것입니다: Lucene 와 함께 Elasticsearch 그 위에 구축되었습니다. Couchbase의 전체 텍스트 검색(FTS) 엔진 에 의해 구동됩니다. Bleve이 기사에서는 다음을 소개합니다. 텍스트를 분석하는 다양한 방법 이 엔진 내에서.
Bleve는 카우치베이스에서 자체 개발한 Go로 구현된 오픈 소스 텍스트 색인 및 검색 라이브러리입니다.
카우치베이스의 FTS 엔진은 다음과 같은 데이터를 구독하는 인덱스를 지원합니다. 카우치베이스 서버 서버에서 수집한 데이터를 색인합니다. 분산형 시스템으로 클러스터의 여러 노드에 데이터를 분할할 수 있으며, 검색은 요청을 분산하고 클러스터 내의 모든 노드에서 응답을 수집한 후 애플리케이션에 응답하는 방식으로 이루어집니다.
FTS 엔진은 인덱스에 대해 수집된 문서를 구성 가능한 수의 파티션에 분산하며, 이러한 파티션은 클러스터 내의 여러 노드에 걸쳐 존재할 수 있습니다. 각 파티션은 텍스트를 분석하고 전체 텍스트 검색 데이터베이스로 색인하기 위해 FTS 인덱스가 구성된 것과 동일한 규칙 집합을 따릅니다.
그리고 텍스트 분석 구성 요소는 원시 텍스트를 단어 목록으로 분해하는 역할을 하며, 이를 토큰이라고 부릅니다. 이러한 토큰은 데이터베이스에서 색인을 생성하고 검색하는 데 더 적합합니다.
카우치베이스의 FTS 엔진은 JSON 문서의 텍스트 인덱싱을 처리합니다. 분석된 콘텐츠에 대한 인덱스를 생성하고 데이터베이스에 저장하며, 생성된 토큰을 토큰이 있는 원본 문서에 연결하는 데 필요한 모든 관련 메타데이터와 함께 인덱스를 생성합니다.
An 반전 인덱스 은 텍스트에서 생성된 토큰을 색인화하여 검색 쿼리를 더 빠르게 하기 위해 선택한 데이터 구조입니다. 이 색인은 생성된 모든 토큰을 해당 토큰이 포함된 문서에 연결합니다.
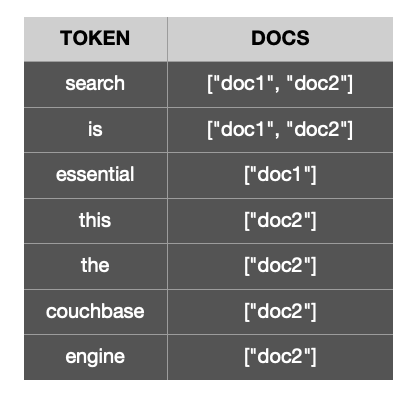
예를 들어 다음 문서를 예로 들어 보겠습니다.

위의 두 문서에서 생성된 토큰의 반전된 인덱스는 이와 비슷할 것입니다.
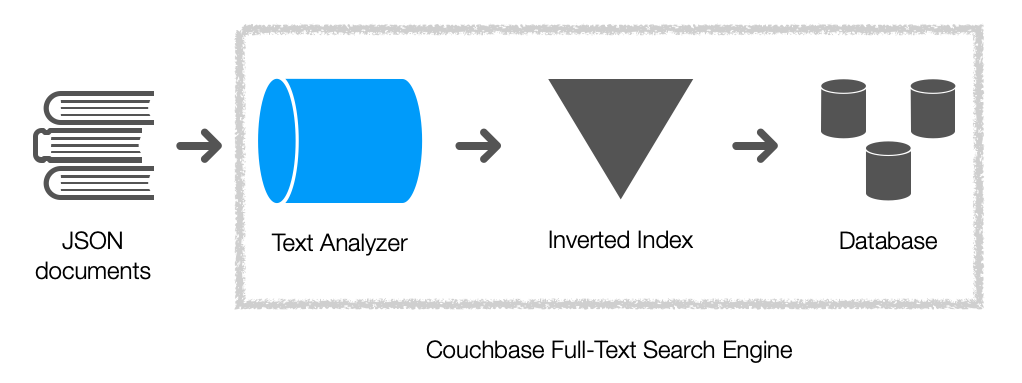
다음은 전체 텍스트 검색 엔진의 구성 요소를 강조하는 다이어그램입니다.
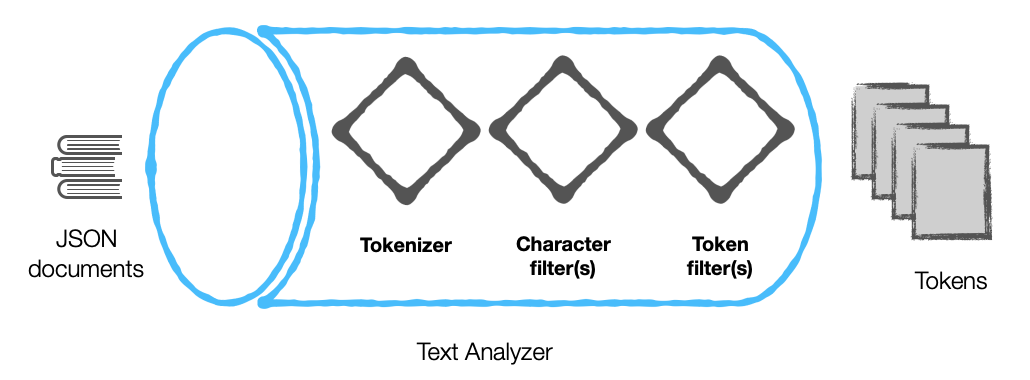
텍스트 분석기
텍스트 분석기의 구성 요소는 크게 두 가지 범주로 분류할 수 있습니다:
-
- 토큰화 도구
- 필터
카우치베이스의 엔진은 필터를 다음과 같이 더 세분화합니다:
-
- 문자 필터
- 토큰 필터
이러한 각 구성 요소의 기능을 자세히 알아보기 전에 텍스트 분석기에 대한 개요를 살펴보겠습니다.
토큰화 도구
토큰화 도구는 문서에 가장 먼저 적용되는 구성 요소입니다. 이름에서 알 수 있듯이 원시 텍스트를 토큰 목록으로 변환합니다. 이 변환은 토큰화기에 대해 정의된 규칙 세트에 따라 달라집니다.
주식 토큰화 ...
이 샘플 텍스트를 예로 들어 보겠습니다: "제 이메일 ID입니다: abhi123@cb.com”
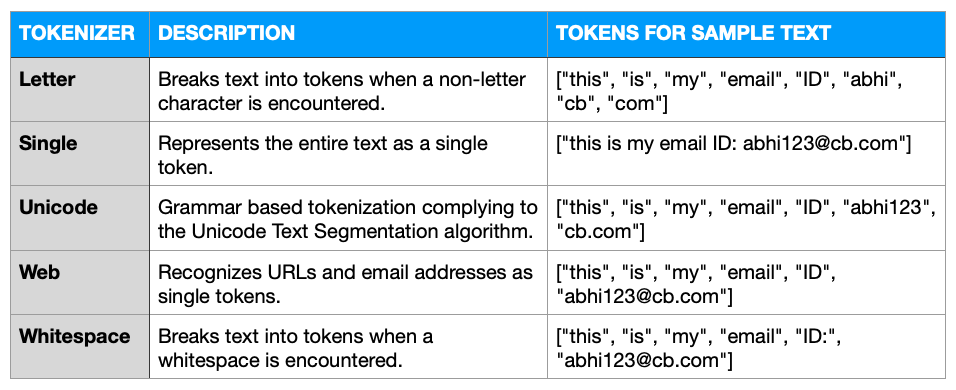
구성 가능한 몇 가지 토큰화 도구 ...
-
- 예외 .. 이 토큰라이저를 사용하면 주식 토큰라이저에 예외 패턴(정규식)을 입력할 수 있습니다.
- 정규식 .. 이 토큰화 도구는 패턴(정규식)과 일치하는 텍스트를 토큰으로 추출합니다.
예를 들어

문자 필터
문자 필터는 원하지 않는 문자를 제거하거나 대체하는 기능입니다.
스톡 캐릭터 필터 ...

구성 가능한 문자 필터 ...
-
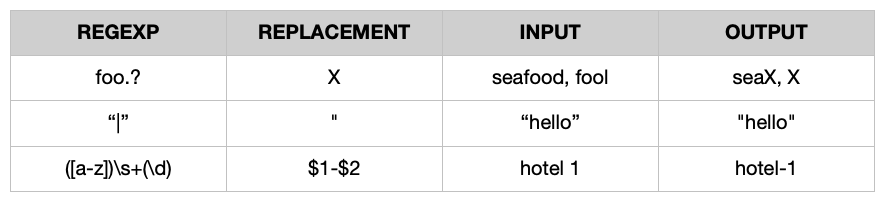
- 정규식 .. 일치하는 패턴을 대체할 유효한 정규식과 바꾸기 문자열을 받습니다.
예를 들어
토큰 필터
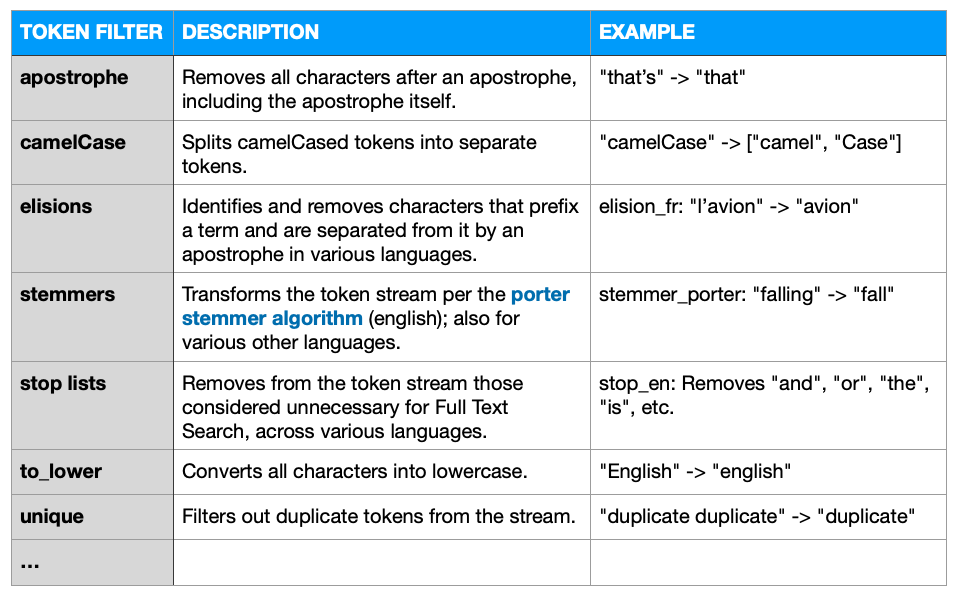
토큰 필터는 토큰화 도구가 제공하는 토큰 스트림을 수락하고 스트림의 토큰을 수정합니다. 토큰 필터링의 가장 일반적인 형태는 정규화와 스템밍입니다.
몇 가지 눈에 띄는 스톡 토큰 필터는 다음과 같습니다.
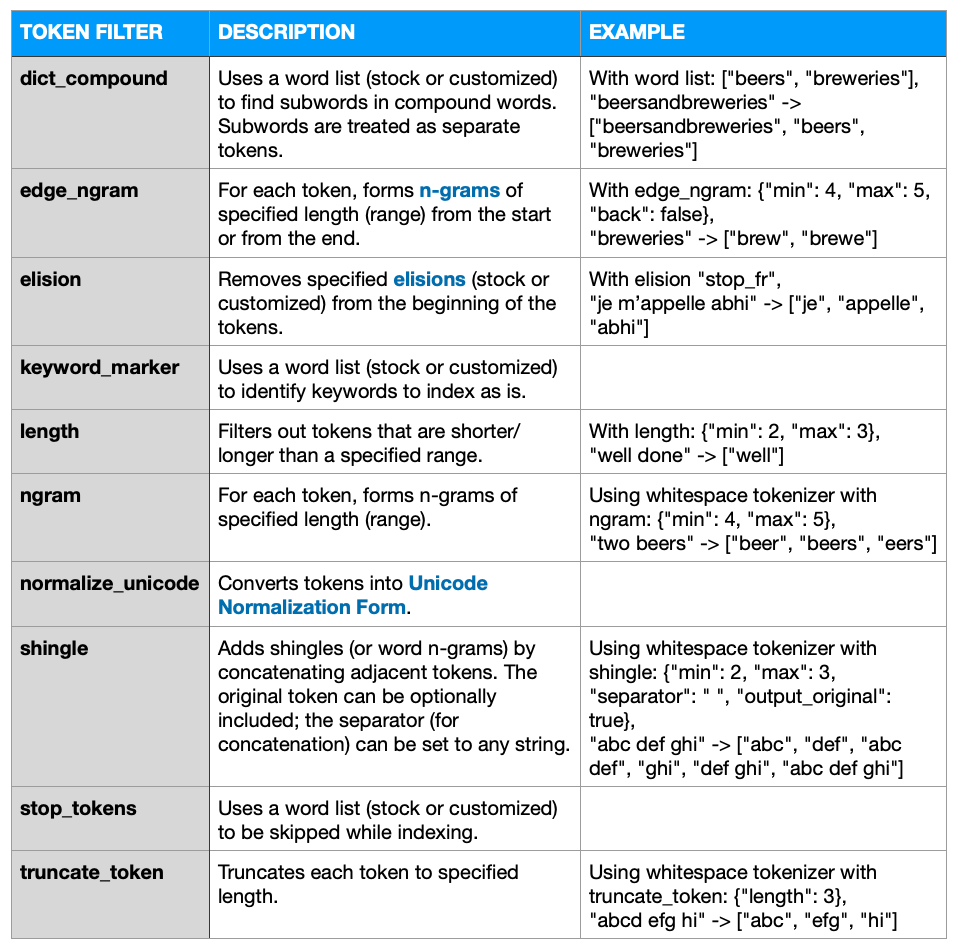
구성 가능한 토큰 필터 ...
주식 분석기
Couchbase의 전체 텍스트 검색 엔진을 사용하면 분석기와 모든 구성 요소는 JSON 문서 내에서 필드 값을 구성하는 텍스트에 대해 작동합니다. 필드 이름에서는 작동하지 않습니다.
JSON 문서를 생각해 보세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "field1": "value1", "field2": "value2", "array_field3": [ "value3", "value4" ], "object_field4": { "field5": "value5", "field6": "value6" } } |
문서의 경우, 분석기가 "value1", "value2", "value3", "value4", "value5" 및 "value6"에 대해 작동하도록 정의할 수 있습니다.
카우치베이스는 여러 주식 분석기를 제공합니다 ...
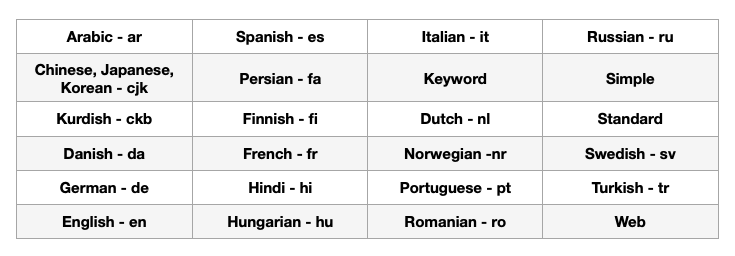
다음은 몇 가지 예입니다.
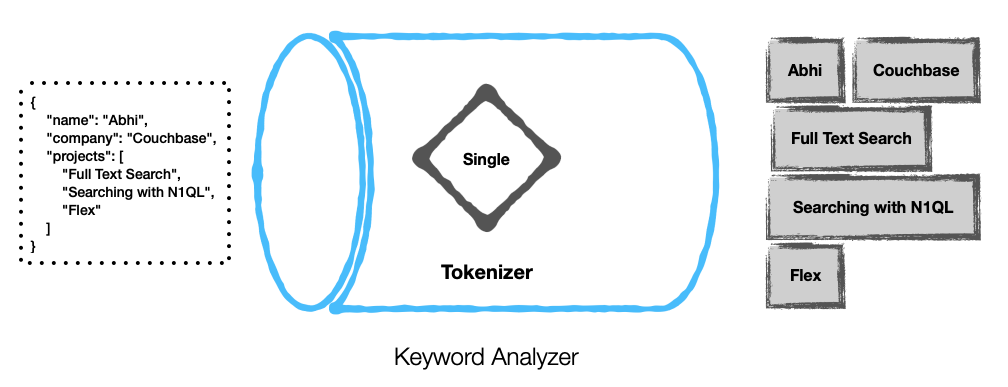
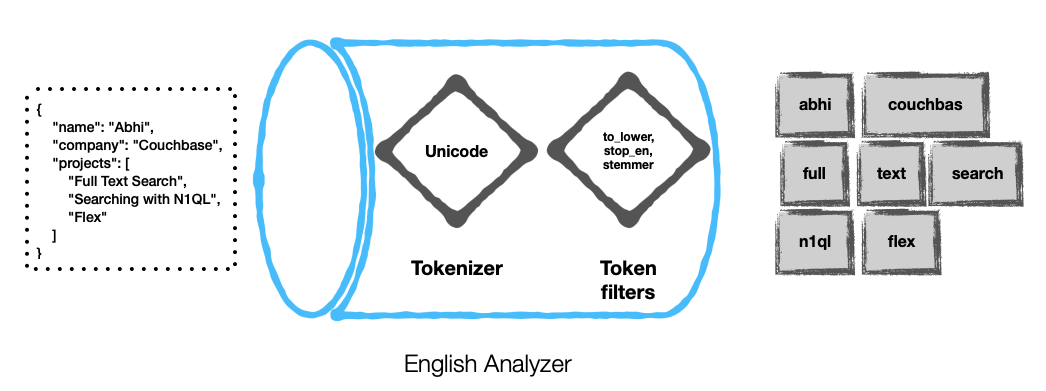
사용자 지정 분석기 구성
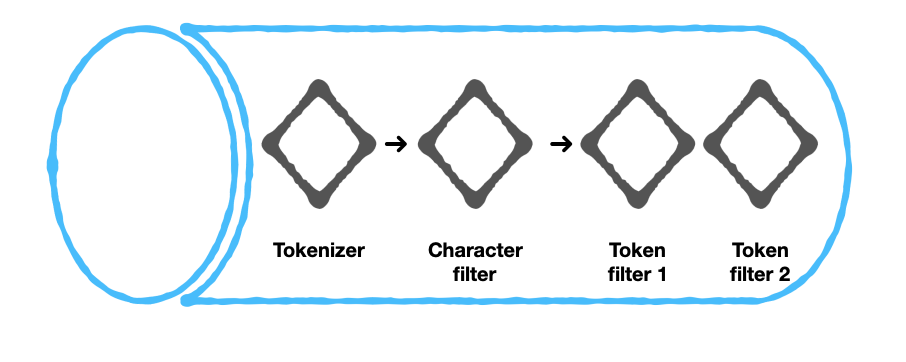
- 사용자 지정 분석기를 설계하는 데 있어 핵심은 올바른 토큰화 도구와 필터를 선택하는 것뿐만 아니라 올바른 순서로 적용하는 것입니다.
- 따라서 첫 번째 단계는 필요한 경우 사용자 지정 토큰화 도구, 문자 필터 및 토큰 필터(사용자 지정 단어 목록과 함께)를 설정하는 것입니다.
- 다음으로 원하는 토큰화 도구, 문자 필터, 토큰 필터를 선택하여 분석기를 생성합니다. 사용자 지정한 항목을 설정한 경우 사용 가능한 옵션 목록에 표시됩니다.
- 선택한 문자 필터와 토큰 필터의 순서에 따라 표시되는 출력에 차이가 있을 수 있습니다.
- 인덱싱할 필드 값을 선택하는 동안 원하는 분석기를 선택합니다. 그렇지 않으면 상위 매핑에서 분석기가 상속됩니다. 사용자 정의 옵션이 사용 가능한 옵션 목록에 표시됩니다.
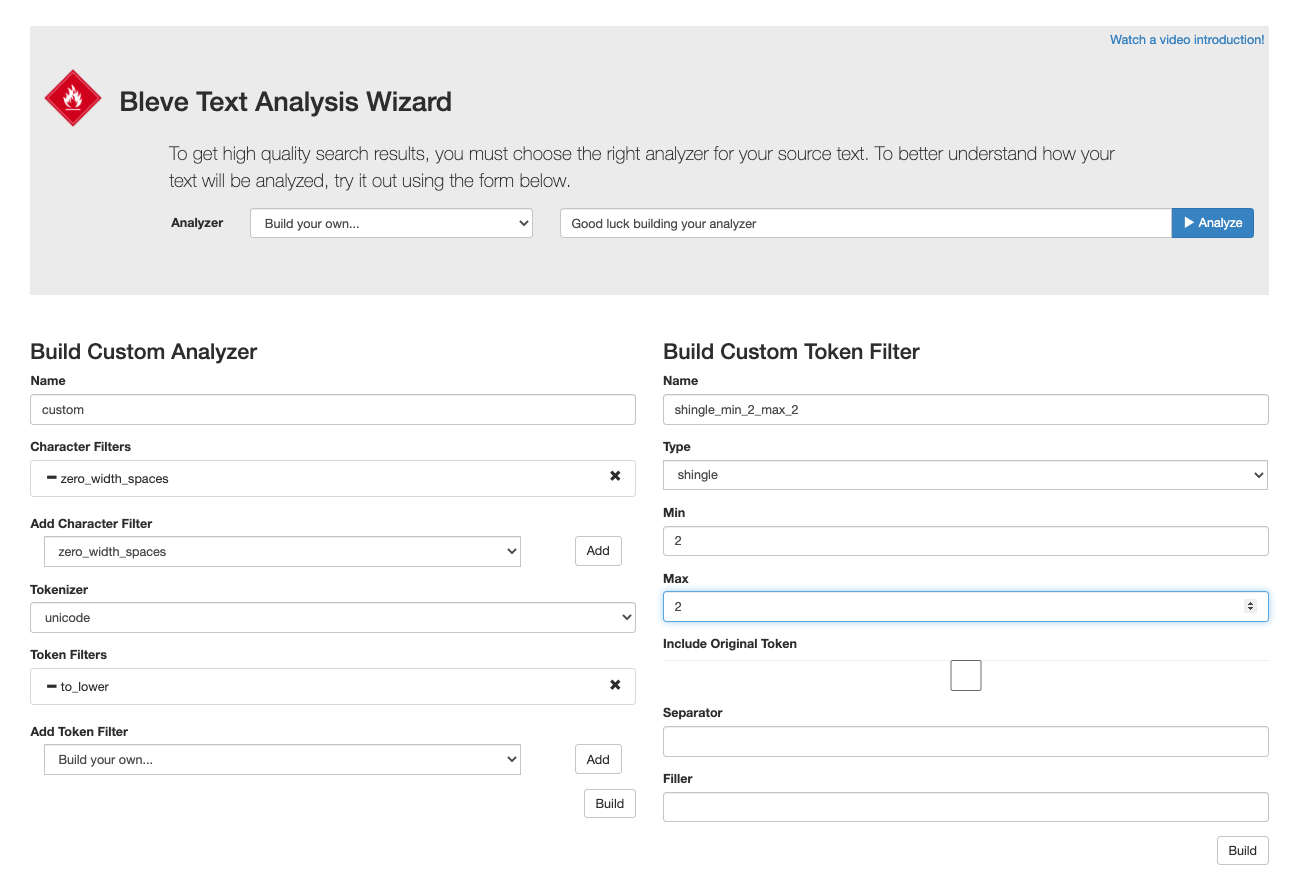
텍스트 분석 놀이터
여기에서 주식 분석기 및 맞춤형 분석기의 동작을 테스트해 보세요.
https://bleveanalysis.couchbase.com
다음은 Couchbase의 전체 텍스트 검색을 사용하는 동안의 모범 사례에 대한 좋은 글입니다.