아론 벤튼은 혁신적인 모바일 애플리케이션 개발을 위한 창의적인 솔루션을 전문으로 하는 숙련된 아키텍트입니다. 그는 10년 이상 ColdFusion, SQL, NoSQL, JavaScript, HTML 및 CSS를 포함한 전체 스택 개발 분야에서 경력을 쌓았습니다. 현재 노스캐롤라이나주 그린즈버러에 위치한 Shop.com의 애플리케이션 아키텍트인 Aaron은 카우치베이스 커뮤니티 챔피언.

FakeIt 시리즈 4/5: 기존 데이터로 작업하기
지금까지 FakeIt 시리즈를 통해 가짜 데이터 생성, 데이터 및 종속성 공유를 사용하여 소규모 모델에 대한 정의. 오늘은 입력을 통해 기존 데이터로 작업하는 FakeIt의 마지막 주요 기능에 대해 살펴보겠습니다.
개발자로서 그린필드 애플리케이션에서 작업하는 이점을 누리는 경우는 드물며, 우리 도메인은 다양한 레거시 데이터베이스와 애플리케이션으로 구성되어 있는 경우가 많습니다. 새로운 애플리케이션을 모델링하고 구축할 때는 이러한 기존 데이터를 참조하고 사용해야 합니다. FakeIt 를 사용하면 JSON, CSV 또는 CSON 파일을 통해 모델에 기존 데이터를 제공할 수 있습니다. 이 데이터는 각 모델의 *run 및 *build 함수에서 입력 변수로 노출됩니다.
사용자 모델
가장 최근에 업데이트한 users.yaml 모델부터 시작하겠습니다. 최근 게시물 사용하려면 주소 그리고 전화 정의.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 |
name: Users type: object key: _id data: min: 1000 max: 2000 properties: _id: type: string description: The document id built by the prefix "user_" and the users id data: post_build: "`user_${this.user_id}`" doc_type: type: string description: The document type data: value: "user" user_id: type: integer description: An auto-incrementing number data: build: document_index first_name: type: string description: The users first name data: build: faker.name.firstName() last_name: type: string description: The users last name data: build: faker.name.lastName() username: type: string description: The username data: build: faker.internet.userName() password: type: string description: The users password data: build: faker.internet.password() email_address: type: string description: The users email address data: build: faker.internet.email() created_on: type: integer description: An epoch time of when the user was created data: build: new Date(faker.date.past()).getTime() addresses: type: object description: An object containing the home and work addresses for the user properties: home: description: The users home address schema: $ref: '#/definitions/Address' work: description: The users work address schema: $ref: '#/definitions/Address' main_phone: description: The users main phone number schema: $ref: '#/definitions/Phone' data: post_build: | delete this.main_phone.type return this.main_phone additional_phones: type: array description: The users additional phone numbers items: $ref: '#/definitions/Phone' data: min: 1 max: 4 definitions: Phone: type: object properties: type: type: string description: The phone type data: build: faker.random.arrayElement([ 'Home', 'Work', 'Mobile', 'Other' ]) phone_number: type: string description: The phone number data: build: faker.phone.phoneNumber().replace(/[^0-9]+/g, '') extension: type: string description: The phone extension data: build: chance.bool({ likelihood: 30 }) ? chance.integer({ min: 1000, max: 9999 }) : null Address: type: object properties: address_1: type: string description: The address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` address_2: type: string description: The address 2 data: build: chance.bool({ likelihood: 35 }) ? faker.address.secondaryAddress() : null locality: type: string description: The city / locality data: build: faker.address.city() region: type: string description: The region / state / province data: build: faker.address.stateAbbr() postal_code: type: string description: The zip code / postal code data: build: faker.address.zipCode() country: type: string description: The country code data: build: faker.address.countryCode() |
현재 주소 정의는 임의의 국가를 생성하는 것입니다. 이커머스 사이트에서 195개 국가 중 일부 국가만 지원한다면 어떻게 해야 할까요? 우선 6개 국가를 지원한다고 가정해 보겠습니다: 미국, 캘리포니아, 멕시코, 영국, 에스파냐, 독일. 정의 국가 속성을 업데이트하여 임의의 배열 요소를 가져올 수 있습니다:
(간결성을 위해 다른 프로퍼티는 모델 정의에서 제외했습니다.)
|
1 2 3 4 5 6 |
... country: type: string description: The country code data: build: faker.random.arrayElement(['US', 'CA', 'MX', 'UK', 'ES', 'DE']); |
이 방법은 작동하지만 동일한 국가 정보에 의존하는 다른 모델이 있다면 이 로직을 복제해야 합니다. countries.json 파일을 만들고 데이터 속성에 입력에 대한 절대 또는 상대 경로가 될 수 있는 inputs 속성을 추가하면 동일한 작업을 수행할 수 있습니다. 모델이 생성되면 countries.json 파일은 inputs 인수를 통해 각 모델 빌드 함수에 inputs.countries로 노출됩니다.
(간결성을 위해 다른 프로퍼티는 모델 정의에서 제외했습니다.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Users type: object key: _id data: min: 1000 max: 2000 inputs: ./countries.json properties: ... definitions: ... country: type: string description: The country code data: build: faker.random.arrayElement(inputs.countries); countries.json [ "US", "CA", "MX", "UK", "ES", "DE" ] |
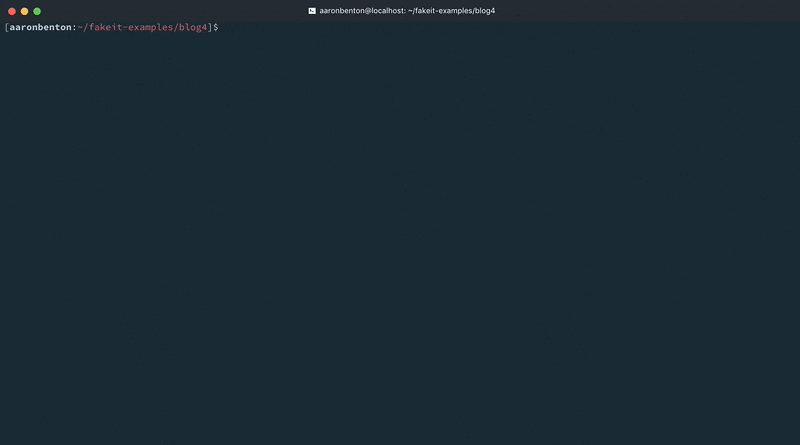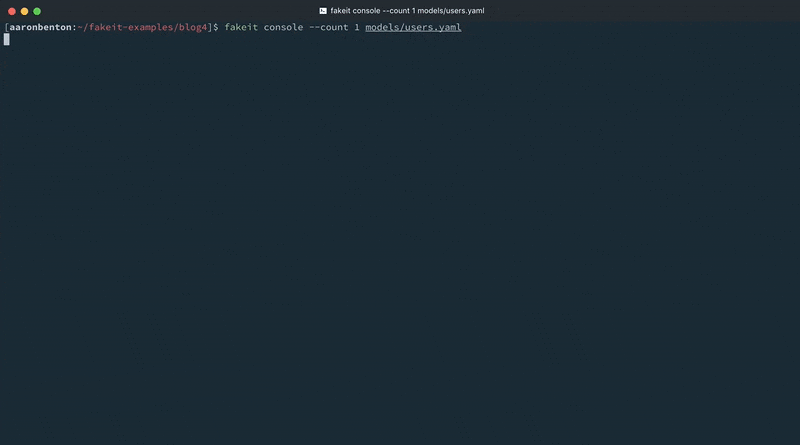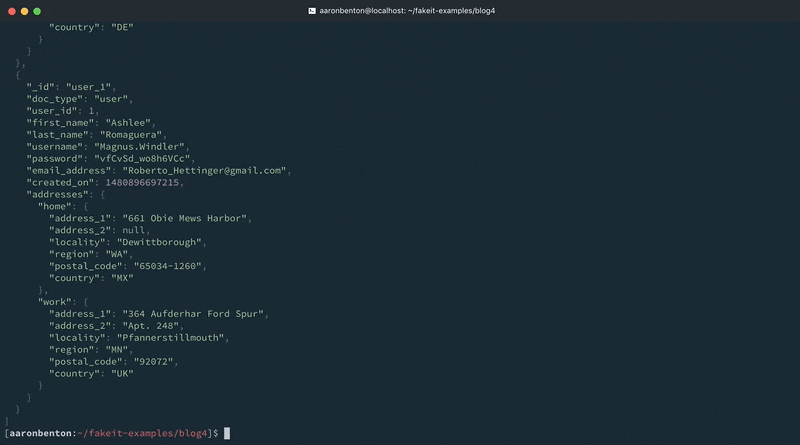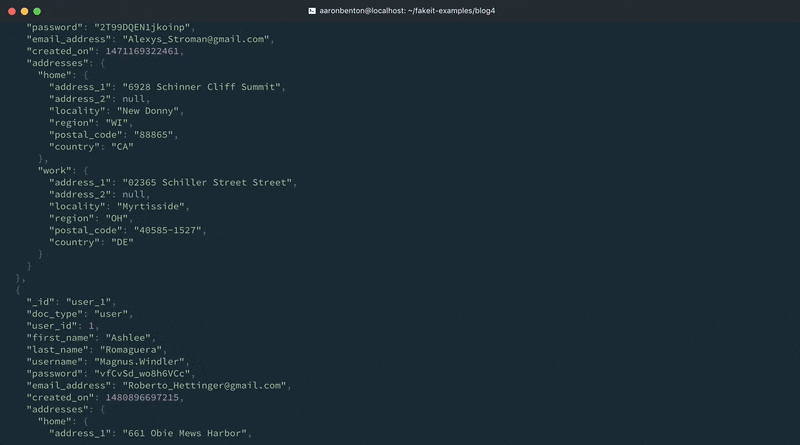
기존 라인 하나를 변경하고 모델에 다른 라인을 추가함으로써 사용자 모델에 기존 데이터를 제공했습니다. 애플리케이션이 지원하는 국가를 기반으로 임의의 국가를 생성할 수 있습니다. 다음 명령을 사용하여 변경 사항을 테스트해 보겠습니다:
|
1 |
fakeit console --count 1 models/users.yaml |
제품 모델
전자상거래 애플리케이션에서 분류를 위해 별도의 시스템을 사용하고 있으므로 유효한 카테고리 정보를 사용할 수 있도록 해당 데이터를 무작위로 생성된 제품에 노출해야 합니다. 여기서는 먼저 FakeIt 시리즈 2/5: 공유 데이터 및 종속성 게시물.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
products.yaml name: Products type: object key: _id data: min: 4000 max: 5000 properties: _id: type: string description: The document id data: post_build: `product_${this.product_id}` doc_type: type: string description: The document type data: value: product product_id: type: string description: Unique identifier representing a specific product data: build: faker.random.uuid() price: type: double description: The product price data: build: chance.floating({ min: 0, max: 150, fixed: 2 }) sale_price: type: double description: The product price data: post_build: | let sale_price = 0; if (chance.bool({ likelihood: 30 })) { sale_price = chance.floating({ min: 0, max: this.price * chance.floating({ min: 0, max: 0.99, fixed: 2 }), fixed: 2 }); } return sale_price; display_name: type: string description: Display name of product. data: build: faker.commerce.productName() short_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(1) long_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(5) keywords: type: array description: An array of keywords items: type: string data: min: 0 max: 10 build: faker.random.word() availability: type: string description: The availability status of the product data: build: | let availability = 'In-Stock'; if (chance.bool({ likelihood: 40 })) { availability = faker.random.arrayElement([ 'Preorder', 'Out of Stock', 'Discontinued' ]); } return availability; availability_date: type: integer description: An epoch time of when the product is available data: build: faker.date.recent() post_build: new Date(this.availability_date).getTime() product_slug: type: string description: The URL friendly version of the product name data: post_build: faker.helpers.slugify(this.display_name).toLowerCase() category: type: string description: Category for the Product data: build: faker.commerce.department() category_slug: type: string description: The URL friendly version of the category name data: post_build: faker.helpers.slugify(this.category).toLowerCase() image: type: string description: Image URL representing the product. data: build: faker.image.image() alternate_images: type: array description: An array of alternate images for the product items: type: string data: min: 0 max: 4 build: faker.image.image() |
기존 카테고리 데이터는 CSV 형식으로 제공되었습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
categories.csv "category_id","category_name","category_slug" 23,"Electronics","electronics" 1032,"Office Supplies","office-supplies" 983,"Clothing & Apparel","clothing-and-apparel" 483,"Movies, Music & Books","movies-music-and-books" 3023,"Sports & Fitness","sports-and-fitness" 4935,"Automotive","automotive" 923,"Tools","tools" 5782,"Home Furniture","home-furniture" 9783,"Health & Beauty","health-and-beauty" 2537,"Toys","toys" 10,"Video Games","video-games" 736,"Pet Supplies","pet-supplies" |
이제 이 기존 데이터를 사용하려면 products.yaml 모델을 업데이트해야 합니다.
(간결성을 위해 다른 프로퍼티는 모델 정의에서 제외했습니다.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
name: Products type: object key: _id data: min: 4000 max: 5000 inputs: - ./categories.csv pre_build: globals.current_category = faker.random.arrayElement(inputs.categories); properties: ... category_id: type: integer description: The Category ID for the Product data: build: globals.current_category.category_id category: type: string description: Category for the Product data: build: globals.current_category.category_name category_slug: type: string description: The URL friendly version of the category name data: post_build: globals.current_category.category_slug ... |
products.yaml 모델을 업데이트한 방법에 대해 몇 가지 주목해야 할 사항이 있습니다.
- 입력: 문자열이 아닌 배열로 정의됩니다. 여기서는 하나의 입력만 사용하지만, 모델에 필요한 만큼의 입력 파일을 제공할 수 있습니다.
- pre_build 함수는 모델의 루트에 정의됩니다. 이는 세 가지 카테고리 속성 각각에 대해 임의의 배열 요소를 가져올 수 없기 때문에 값이 일치하지 않기 때문입니다. 모델에 대한 개별 문서가 생성될 때마다 이 pre_build 함수가 먼저 실행됩니다.
- 각 카테고리 속성 빌드 함수는 모델의 pre_build 함수에 의해 설정된 전역 변수를 참조합니다.
다음 명령을 사용하여 변경 사항을 테스트할 수 있습니다:
|
1 |
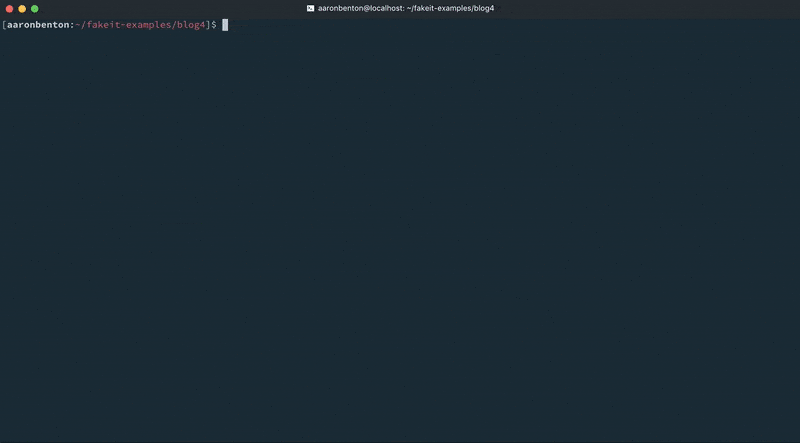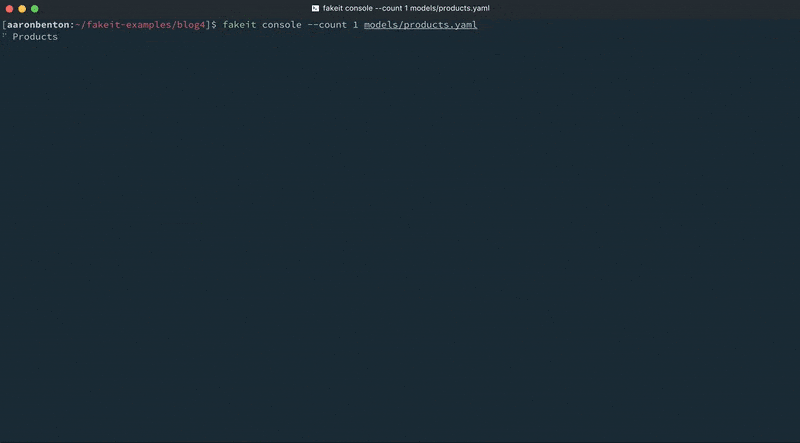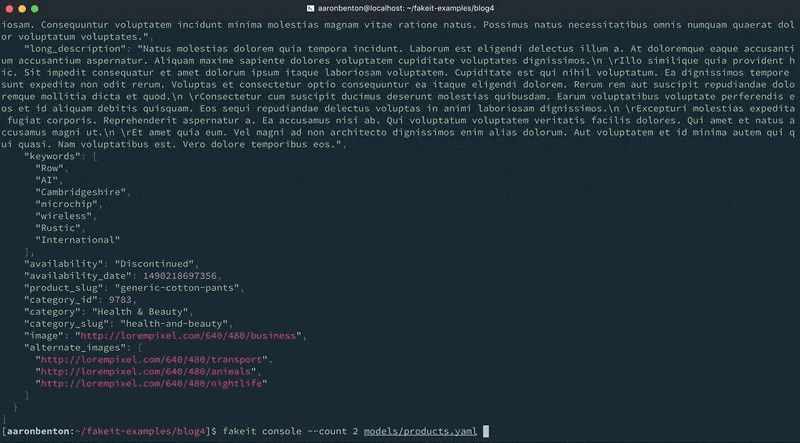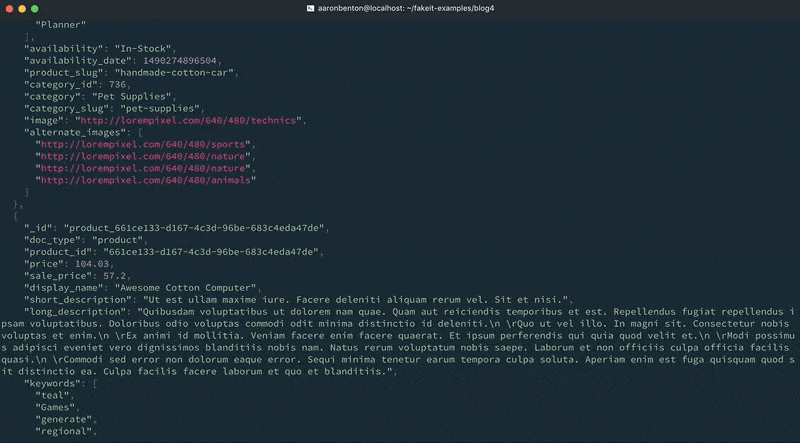
fakeit console --count 1 models/products.yaml |
결론
기존 데이터로 작업할 수 있다는 것은 매우 강력한 기능입니다. FakeIt. 무작위로 생성된 문서의 무결성을 유지하여 기존 시스템에서 작업하는 데 사용할 수 있으며, 기존 데이터를 변환하여 Couchbase Server로 가져오는 데에도 사용할 수 있습니다.
다음 단계
이전 게시물

이 게시물은 카우치베이스 커뮤니티 글쓰기 프로그램의 일부입니다.