아론 벤튼은 혁신적인 모바일 애플리케이션 개발을 위한 창의적인 솔루션을 전문으로 하는 숙련된 아키텍트입니다. 그는 10년 이상 ColdFusion, SQL, NoSQL, JavaScript, HTML 및 CSS를 포함한 전체 스택 개발 분야에서 경력을 쌓았습니다. 현재 노스캐롤라이나주 그린즈버러에 위치한 Shop.com의 애플리케이션 아키텍트인 Aaron은 카우치베이스 커뮤니티 챔피언.

FakeIt 시리즈 2/5: 공유 데이터 및 종속성
In FakeIt 시리즈 1/5: 가짜 데이터 생성하기 를 통해 FakeIt이 단일 YAML 파일을 기반으로 대량의 임의 데이터를 생성하고 그 결과를 Couchbase Server를 포함한 다양한 형식과 대상으로 출력할 수 있다는 사실을 알게 되었습니다. 오늘은 데이터 생성의 세계에서 FakeIt이 진정으로 독특하고 강력한 이유를 살펴보겠습니다.
수많은 무작위 데이터 생성기를 사용할 수 있습니다. Google 검색 는 선택의 폭이 넓습니다. 그러나 이들 대부분은 단일 모델만 다룰 수 있다는 실망스러운 결함을 가지고 있습니다. 개발자로서 단일 모델만 다룰 수 있는 경우는 드물고, 프로젝트에서 여러 모델을 대상으로 개발하는 경우가 더 많습니다. FakeIt은 여러 모델과 그 모델들이 종속성을 가질 수 있도록 허용합니다.
이커머스 애플리케이션에서 사용할 수 있는 모델을 살펴보겠습니다:
- 사용자
- 제품
- 장바구니
- 주문
- 리뷰
첫 번째로 정의한 모델인 사용자 모델에는 종속성이 없으며 다음에 정의할 제품 모델도 마찬가지입니다. 그러나 주문 모델은 사용자 모델과 제품 모델 모두에 종속된다고 말하는 것이 논리적으로 맞습니다. 진정으로 테스트 데이터를 원한다면 주문 모델에서 생성된 문서는 사용자 및 제품 모델 모두에서 생성된 실제 무작위 데이터여야 합니다.
제품 모델
FakeIt에서 모델 종속성이 어떻게 작동하는지 살펴보기 전에 제품 모델이 어떤 모습일지 정의해 보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
이름: 제품 유형: 객체 키: _id 속성: _id: 유형: 문자열 설명: 그리고 문서 id 데이터: post_build: `product_${이.product_id}` doc_type: 유형: 문자열 설명: 그리고 문서 유형 데이터: 값: 제품 product_id: 유형: 문자열 설명: 고유 식별자 대표 a 특정 제품 데이터: 빌드: faker.무작위.uuid() 가격: 유형: double 설명: 그리고 제품 가격 데이터: 빌드: 기회.플로팅({ 분: 0, 최대: 150, 고정: 2 }) 판매 가격: 유형: double 설명: 그리고 제품 가격 데이터: post_build: | let 판매 가격 = 0; 만약 (기회.bool({ 가능성: 30 })) { 판매 가격 = 기회.플로팅({ 분: 0, 최대: 이.가격 * 기회.플로팅({ 분: 0, 최대: 0.99, 고정: 2 }), 고정: 2 }); } 반환 판매 가격; display_name: 유형: 문자열 설명: 디스플레이 이름 의 제품. 데이터: 빌드: faker.커머스.제품 이름() 짧은_설명: 유형: 문자열 설명: 설명 의 제품. 데이터: 빌드: faker.lorem.단락(1) long_description: 유형: 문자열 설명: 설명 의 제품. 데이터: 빌드: faker.lorem.단락(5) 키워드: 유형: 배열 설명: An 배열 의 키워드 항목: 유형: 문자열 데이터: 분: 0 최대: 10 빌드: faker.무작위.단어() 가용성: 유형: 문자열 설명: 그리고 가용성 상태 의 의 제품 데이터: 빌드: | let 가용성 = '재고 있음'; 만약 (기회.bool({ 가능성: 40 })) { 가용성 = faker.무작위.배열 요소([ '선주문', '품절', '단종' ]); } 반환 가용성; availability_date: 유형: 정수 설명: An epoch 시간 의 언제 의 제품 는 사용 가능 데이터: 빌드: faker.날짜.최근() post_build: new 날짜(이.availability_date).getTime() 제품_슬러그: 유형: 문자열 설명: 그리고 URL 친절한 버전 의 의 제품 이름 데이터: post_build: faker.도우미.슬러그파이(이.display_name).toLowerCase() 카테고리: 유형: 문자열 설명: 카테고리 에 대한 의 제품 데이터: 빌드: faker.커머스.부서() 카테고리_슬러그: 유형: 문자열 설명: 그리고 URL 친절한 버전 의 의 카테고리 이름 데이터: post_build: faker.도우미.슬러그파이(이.카테고리).toLowerCase() 이미지: 유형: 문자열 설명: 이미지 URL 대표 의 제품. 데이터: 빌드: faker.이미지.이미지() 대체 이미지: 유형: 배열 설명: An 배열 의 대체 이미지 에 대한 의 제품 항목: 유형: 문자열 데이터: 분: 0 최대: 4 빌드: faker.이미지.이미지() |
이 모델은 이전 사용자 모델보다 조금 더 복잡합니다. 이 속성 중 몇 가지를 더 자세히 살펴보겠습니다:
- _id: 이 값은 문서의 모든 프로퍼티가 빌드된 후에 설정되며 빌드 후 함수에서 사용할 수 있습니다. 이 컨텍스트는 현재 생성 중인 문서의 컨텍스트입니다.
- 판매 가격: 판매 가격의 30% 확률을 정의하고 판매 가격이 가격 속성보다 낮은 판매 가격이 있는 경우
- 키워드: 는 배열입니다. Swagger와 유사하게 정의되며, 빌드/포스트빌드 함수를 사용하여 배열 항목과 배열 구성 방법을 정의합니다. 또한 최소값과 최대값을 정의할 수 있으며 FakeIt은 이 값 사이에 임의의 배열 요소를 생성합니다. 정해진 수의 배열 요소를 생성하는 데 사용할 수 있는 고정 프로퍼티도 있습니다.
이제 제품 모델을 구성했으므로 임의의 데이터를 생성하고 콘솔에 출력하여 명령을 사용하여 어떻게 보이는지 확인해 보겠습니다:
|
1 |
fakeit 콘솔 모델/제품.yaml |
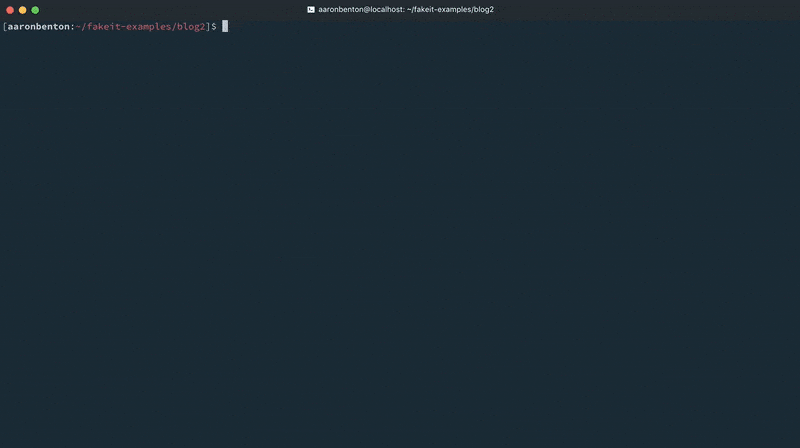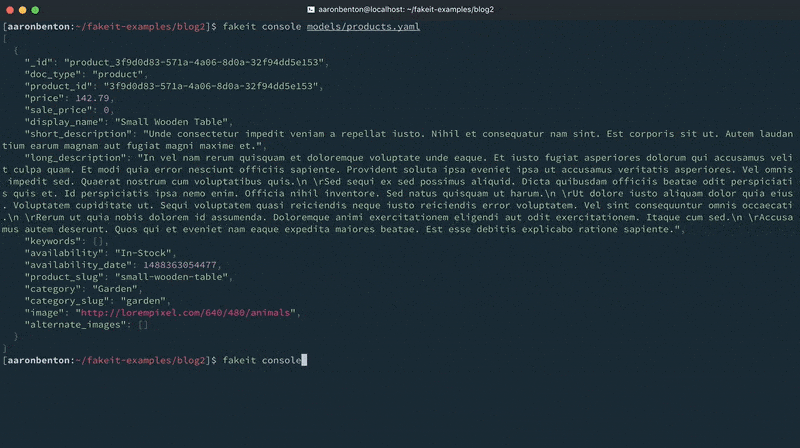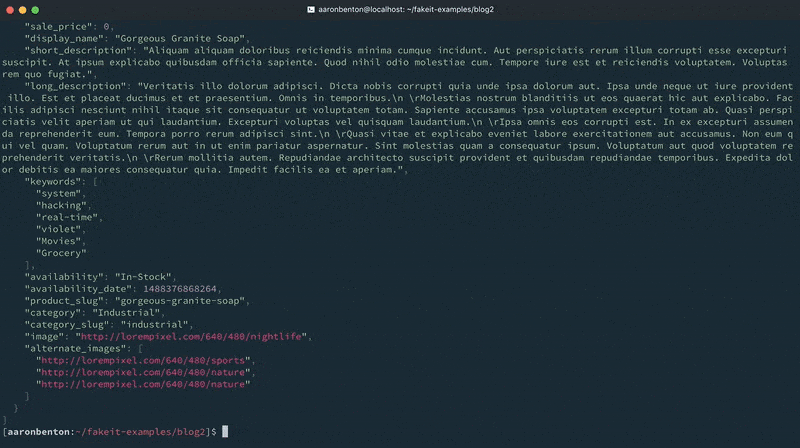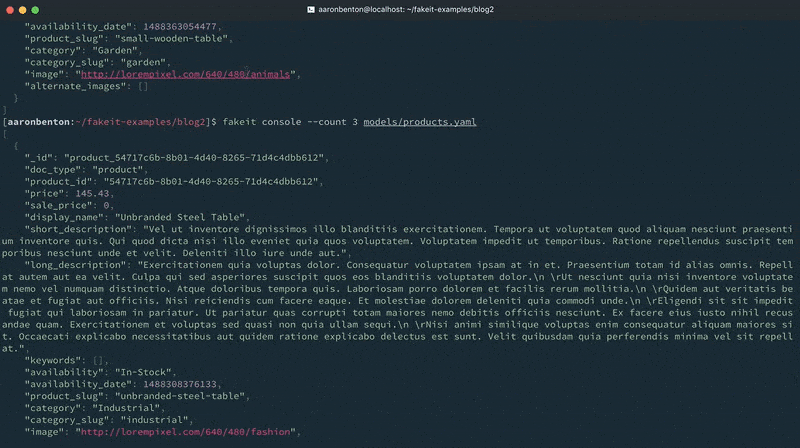
주문 모델
우리 프로젝트의 경우 이미 다음 모델을 정의했습니다:
- users.yaml
- products.yaml
속성이 없는 또는 주문 모델을 정의하고 종속성을 지정하는 것으로 시작하겠습니다:
|
1 2 3 4 5 6 7 8 |
이름: 주문 유형: 객체 키: _id 데이터: 종속성: - 제품.yaml - 사용자.yaml 속성: |
주문 모델에 대해 두 개의 종속성을 정의하고 파일 이름으로 참조했습니다. 모든 모델이 동일한 디렉터리에 저장되므로 전체 경로를 지정할 이유가 없습니다. 런타임에 FakeIt은 문서 생성을 시도하기 전에 먼저 모든 모델을 구문 분석하고 각 모델 종속성(있는 경우)에 따라 실행 순서를 결정합니다.
FakeIt 모델의 각 빌드 함수는 함수 본문으로, 다음과 같은 인수가 전달됩니다.
|
1 2 3 |
함수 (문서, 글로벌, 입력, faker, 기회, 문서_색인, require) { 반환 faker.인터넷.사용자 이름(); } |
실행 순서가 설정되면 각 종속성은 메모리에 저장되고 문서 인수를 통해 종속 모델에서 사용할 수 있습니다. 이 인수는 각 모델에 대한 키를 포함하는 객체이며, 그 값은 생성된 각 문서의 배열입니다. 문서 속성의 예시에서는 이와 비슷하게 보입니다:
|
1 2 3 4 5 6 7 8 |
{ "사용자": [ ... ], "제품": [ ... ] } |
이를 활용하여 임의의 제품 및 사용자 문서를 검색하여 해당 속성을 주문 모델 내의 속성에 할당할 수 있습니다. 예를 들어, 사용자 모델에서 생성된 문서에서 임의의 user_id를 검색하고 빌드 함수를 통해 이를 주문 모델의 user_id에 할당할 수 있습니다.
|
1 2 3 4 5 |
user_id: 유형: 정수 설명: 그리고 user_id 그 배치 의 주문 데이터: 빌드: faker.무작위.배열 요소(문서.사용자).user_id; |
나머지 주문 모델이 어떤 모습일지 정의해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 |
이름: 주문 유형: 객체 키: _id 데이터: 종속성: - 제품.yaml - 사용자.yaml 속성: _id: 유형: 문자열 설명: 그리고 문서 id 데이터: post_build: `주문_${이.주문_ID}` doc_type: 유형: 문자열 설명: 그리고 문서 유형 데이터: 값: "주문" 주문_ID: 유형: 정수 설명: 그리고 주문_id 데이터: 빌드: 문서_색인 + 1 user_id: 유형: 정수 설명: 그리고 user_id 그 배치 의 주문 데이터: 빌드: faker.무작위.배열 요소(문서.사용자).user_id; 주문 날짜: 유형: 정수 설명: An epoch 시간 의 언제 의 주문 는 배치 데이터: 빌드: new 날짜(faker.날짜.과거()).getTime() 주문_상태: 유형: 문자열 설명: 그리고 상태 의 의 주문 데이터: 빌드: faker.무작위.배열 요소([ '보류 중', '처리 중', '취소됨', '배송됨' ]) 청구_이름: 유형: 문자열 설명: 그리고 이름 의 의 사람 의 주문 는 에 be 청구됨 에 데이터: 빌드: `${faker.이름.이름()} ${faker.이름.성()}` 청구_전화: 유형: 문자열 설명: 그리고 청구 전화 데이터: 빌드: faker.전화.전화 번호().대체(/x[0-9]+$/, '') 청구_이메일: 유형: 문자열 설명: 그리고 청구 이메일 데이터: 빌드: faker.인터넷.이메일() 청구_주소_1: 유형: 문자열 설명: 그리고 청구 주소 1 데이터: 빌드: `${faker.주소.거리 주소()} ${faker.주소.거리 접미사()}` 청구_주소_2: 유형: 문자열 설명: 그리고 청구 주소 2 데이터: 빌드: 기회.bool({ 가능성: 50 }) ? faker.주소.보조 주소() : null 청구_로컬리티: 유형: 문자열 설명: 그리고 청구 도시 데이터: 빌드: faker.주소.도시() 청구_지역: 유형: 문자열 설명: 그리고 청구 지역, 도시, province 데이터: 빌드: faker.주소.stateAbbr() 청구_우편_코드: 유형: 문자열 설명: 그리고 청구 zip 코드 / 우편 코드 데이터: 빌드: faker.주소.zipCode() 청구_국가: 유형: 문자열 설명: 그리고 청구 지역, 도시, province 데이터: 값: US 배송_이름: 유형: 문자열 설명: 그리고 이름 의 의 사람 의 주문 는 에 be 청구됨 에 데이터: 빌드: `${faker.이름.이름()} ${faker.이름.성()}` 배송_주소_1: 유형: 문자열 설명: 그리고 배송 주소 1 데이터: 빌드: `${faker.주소.거리 주소()} ${faker.주소.거리 접미사()}` 배송_주소_2: 유형: 문자열 설명: 그리고 배송 주소 2 데이터: 빌드: 기회.bool({ 가능성: 50 }) ? faker.주소.보조 주소() : null 배송_지역: 유형: 문자열 설명: 그리고 배송 도시 데이터: 빌드: faker.주소.도시() 배송 지역: 유형: 문자열 설명: 그리고 배송 지역, 도시, province 데이터: 빌드: faker.주소.stateAbbr() 배송_우편_코드: 유형: 문자열 설명: 그리고 배송 zip 코드 / 우편 코드 데이터: 빌드: faker.주소.zipCode() 배송 국가: 유형: 문자열 설명: 그리고 배송 지역, 도시, province 데이터: 값: US 배송 방법: 유형: 문자열 설명: 그리고 배송 메서드 데이터: 빌드: faker.무작위.배열 요소([ 'USPS', 'UPS 표준', 'UPS Ground', 'UPS 2nd Day Air', 'UPS 익일 배송', 'FedEx Ground', 'FedEx 2Day Air', 'FedEx 스탠다드 오버나이트' ]); 배송 총액: 유형: double 설명: 그리고 배송 합계 데이터: 빌드: 기회.달러({ 분: 10, 최대: 50 }).슬라이스(1) 세금: 유형: double 설명: 그리고 세금 합계 데이터: 빌드: 기회.달러({ 분: 2, 최대: 10 }).슬라이스(1) line_items: 유형: 배열 설명: 그리고 제품 그 는 주문 항목: 유형: 문자열 데이터: 분: 1 최대: 5 빌드: | const 무작위 = faker.무작위.배열 요소(문서.제품); const 제품 = { product_id: 무작위.product_id, display_name: 무작위.display_name, 짧은_설명: 무작위.짧은_설명, 이미지: 무작위.이미지, 가격: 무작위.판매 가격 || 무작위.가격, 수량: faker.무작위.숫자({ 분: 1, 최대: 5 }), }; 제품.sub_total = 제품.수량 * 제품.가격; 반환 제품; grand_total: 유형: double 설명: 그리고 grand 합계 의 의 주문 데이터: post_build: | let 합계 = 이.세금 + 이.배송 총액; 에 대한 (let i = 0; i < 이.line_items.길이; i++) { 합계 += 이.line_items[i].sub_total; } 반환 기회.달러({ 분: 합계, 최대: 합계 }).슬라이스(1); |
그리고 명령을 사용하여 콘솔에 출력합니다:
|
1 |
fakeit 콘솔 모델/주문.yaml |
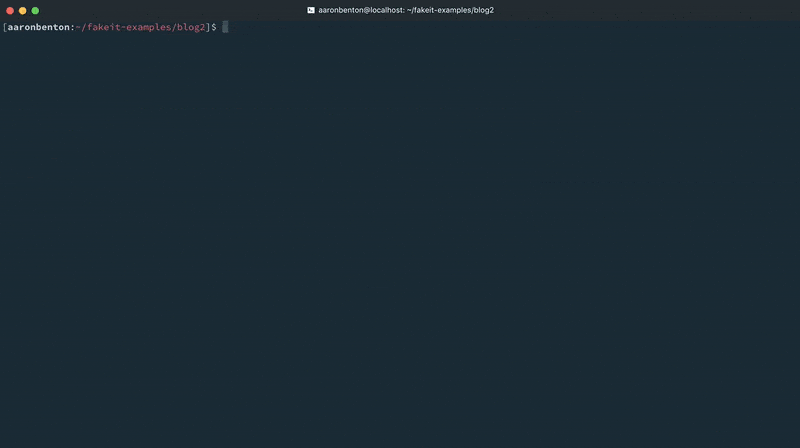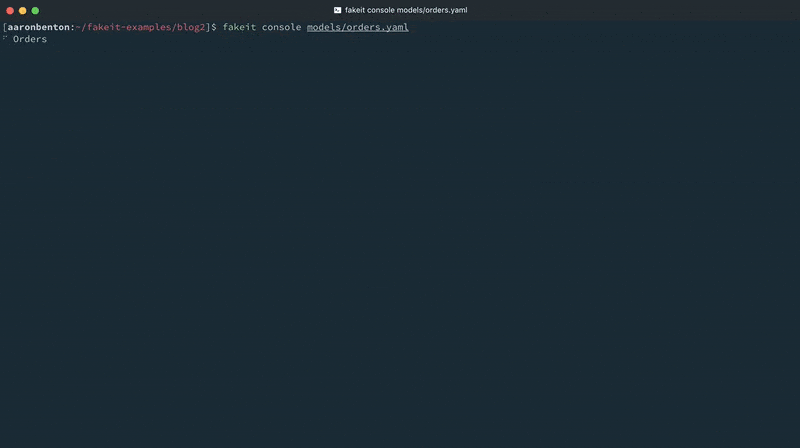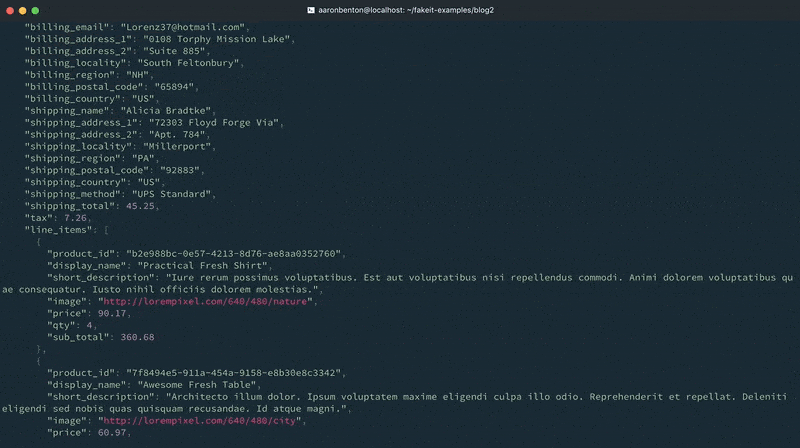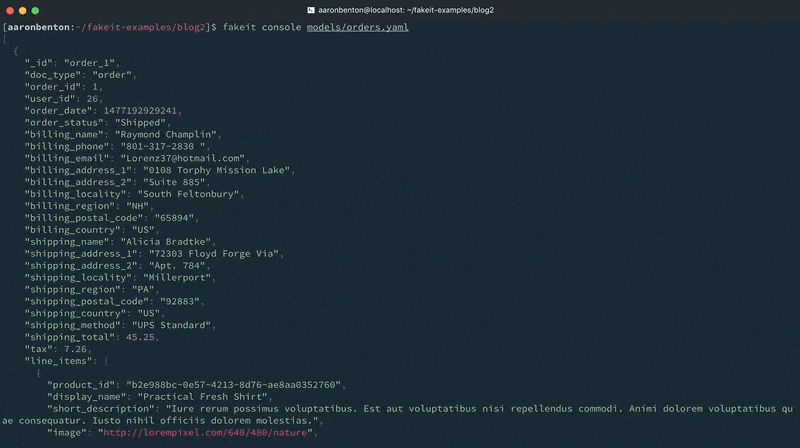
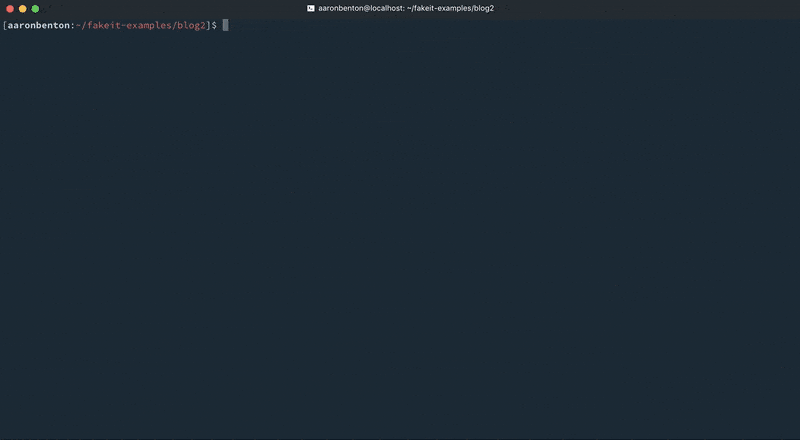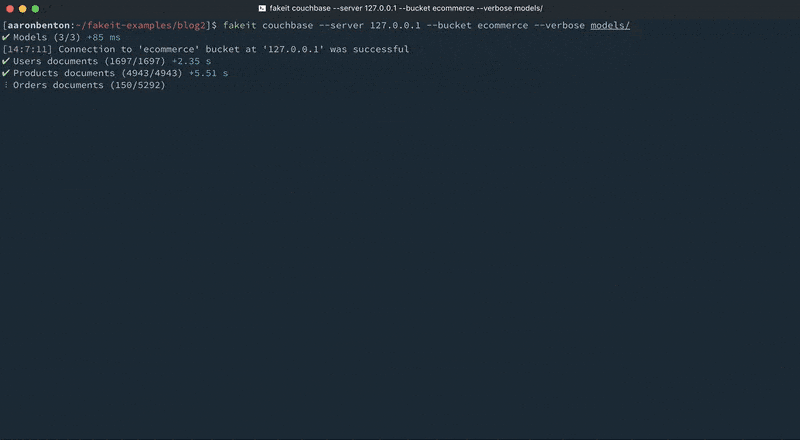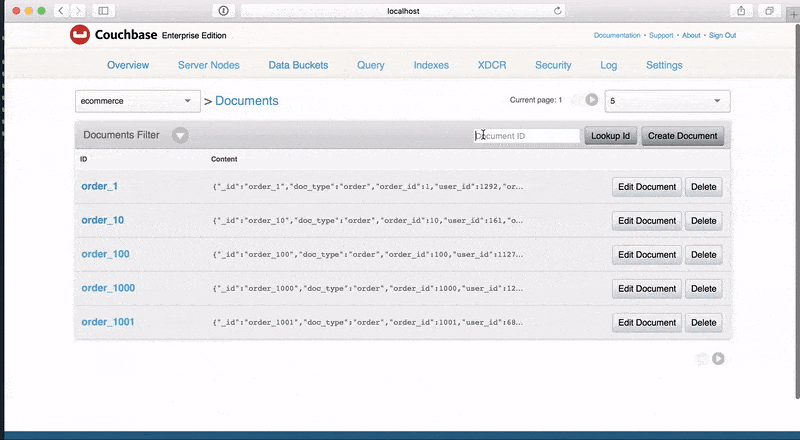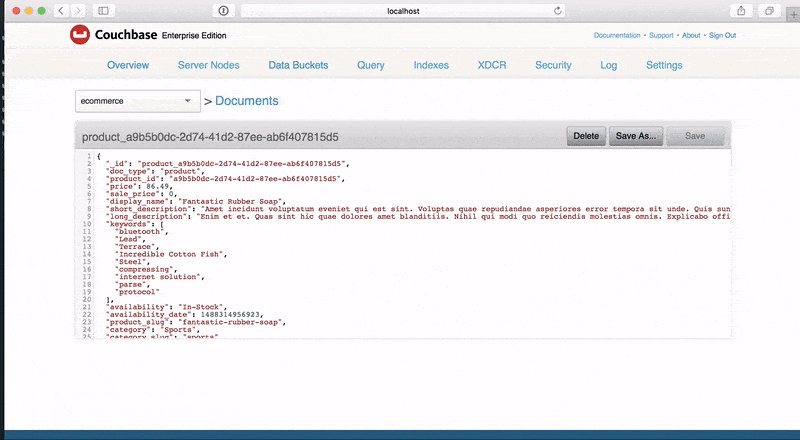
콘솔 출력에서 볼 수 있듯이 사용자 및 제품 모델에 대한 문서가 생성되었으며 이러한 문서는 주문 모델에서 사용할 수 있게 되었습니다. 그러나 출력이 요청된 것은 주문 모델뿐이었기 때문에 출력에서 제외되었습니다.
이제 종속성이 있는 3개의 모델(사용자, 제품 및 주문)을 정의했으므로 각 모델에 대해 여러 개의 문서를 생성하여 Couchbase Server로 출력할 수 있어야 합니다. 지금까지는 -count 명령줄 인수를 통해 생성할 문서의 수를 지정해 왔습니다. 모델의 루트에 있는 데이터: 속성을 사용하여 문서 수 또는 문서 범위를 지정할 수 있습니다.
|
1 2 3 4 5 6 7 8 |
사용자.yaml 이름: 사용자 유형: 객체 키: _id 데이터: 분: 1000 최대: 2000 |
|
1 2 3 4 5 6 7 8 |
제품.yaml 이름: 제품 유형: 객체 키: _id 데이터: 분: 4000 최대: 5000 |
|
1 2 3 4 5 6 7 8 9 10 11 |
주문.yaml 이름: 주문 유형: 객체 키: _id 데이터: 종속성: - 제품.yaml - 사용자.yaml 분: 5000 최대: 6000 |
이제 명령을 사용하여 관련 문서 모델의 임의의 집합을 생성하고 해당 문서를 Couchbase Server로 직접 출력할 수 있습니다:
|
1 |
fakeit 카우치베이스 --서버 127.0.0.1 --버킷 전자 상거래 --verbose 모델/ |
결론
세 가지 간단한 FakeIt YAML 모델을 통해 모델 종속성을 생성하여 무작위로 생성된 데이터를 모델 간에 연관시키고 Couchbase Server로 스트리밍할 수 있는 방법을 살펴보았습니다. 또한 모델 루트의 속성 데이터를 사용하여 모델별로 생성할 문서 수를 지정하는 방법도 살펴봤습니다.
이러한 모델은 프로젝트 저장소에 저장할 수 있어 공간을 거의 차지하지 않으며 개발자가 완전히 다른 데이터로 동일한 데이터 구조를 생성할 수 있습니다. 다중 모델 관계를 통해 문서를 생성할 수 있는 또 다른 장점은 다양한 문서 모델을 탐색하고 다양한 N1QL 쿼리에서 어떻게 수행되는지 확인할 수 있다는 것입니다.
다음 단계
이전 게시물
- FakeIt 시리즈 1/5: 가짜 데이터 생성
 이 게시물은 카우치베이스 커뮤니티 글쓰기 프로그램의 일부입니다.
이 게시물은 카우치베이스 커뮤니티 글쓰기 프로그램의 일부입니다.
[...] 이전 포스트 FakeIt 시리즈 2/5: 공유 데이터 및 종속성에서는 FakeIt으로 다중 모델 종속성을 만드는 방법을 살펴봤습니다. 오늘 우리는 [...]
[...] 지금까지 FakeIt 시리즈에서 가짜 데이터를 생성하고, 데이터와 종속성을 공유하고, 소규모 모델에 정의를 사용하는 방법을 살펴봤습니다. 오늘은 [...]의 마지막 주요 기능에 대해 살펴보겠습니다.