카우치베이스 서버 6.5는 다음과 같은 다양한 기능을 제공합니다. 새로운 기능 [1를 선도적인 NoSQL 데이터베이스로 전환합니다. N1QL 쿼리 언어에 추가된 주요 기능 중 하나는 창 함수에 대한 지원입니다. 이러한 함수는 원래 SQL:2003 표준에 도입되었으며 여러 복잡한 비즈니스 쿼리에 대한 고성능 응답 방법을 제공합니다. 창 함수는 이전에 게시물 [2], [3], [4], 이번 편에서는 카우치베이스 애널리틱스에서의 구현에 대해 자세히 알아보겠습니다.
그리고 카우치베이스 애널리틱스 서비스 [5는 Couchbase 데이터 플랫폼에서 복잡한 애드혹 쿼리를 처리하도록 설계되었습니다. 핵심 구성 요소는 운영 데이터 노드의 워크로드 격리를 보장하기 위해 클러스터의 별도 노드 세트에서 실행되는 MPP 쿼리 엔진입니다. 데이터는 다음을 사용하여 Analytics로 수집됩니다. DCP 변경 프로토콜 [6] 및 사용 가능한 모든 Analytics 노드 간에 해시 분할됩니다. MPP 쿼리 프로세서는 단일 쿼리를 하위 작업으로 나누고 모든 노드에서 병렬로 실행되도록 예약하여 필요한 경우 데이터를 다시 분할합니다. 전체 서비스 아키텍처에 대한 자세한 내용은 최근 작성된 VLDB 2019 논문 [7] 및 동영상 채널 [8].
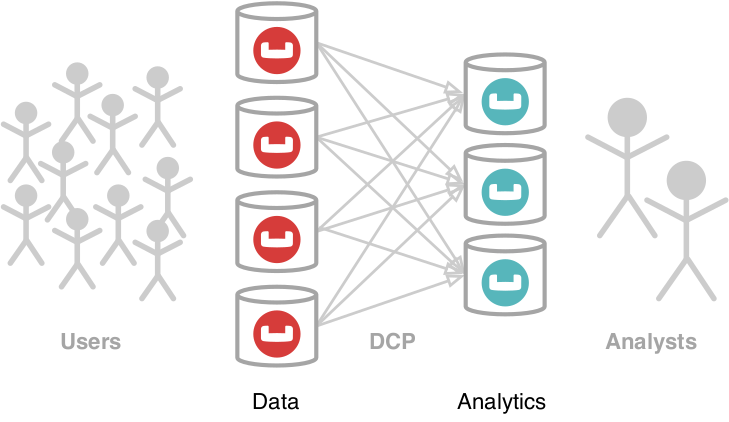
그림 1: Couchbase 분석 서비스
창 함수는 또한 Analytics 쿼리 엔진에 의해 분산된 파티션 병렬 방식으로 평가됩니다. 쿼리 컴파일러는 창 함수 호출의 결과를 계산하기 위해 함께 작동하는 여러 연산자가 포함된 실행 계획을 생성합니다. 그런 다음 이 실행 계획이 클러스터의 모든 Analytics 노드로 전송되어 각 연산자가 입력 데이터의 파티션에서 작업합니다. 실행 엔진은 연산자 실행을 조정하고 쿼리 결과를 클라이언트에 전달합니다. 예를 들어, 각 부서의 직원들의 급여를 기준으로 순위를 매기는 다음 쿼리를 생각해 보겠습니다.
|
1 2 3 4 5 |
선택 RANK() OVER (파티션 BY 부서_ID 주문 BY 급여 DESC) AS 순위, employee_id, department_id, 급여 FROM 직원 |
쿼리 프로세서는 그림 2에 표시된 대로 이 함수를 세 단계로 평가합니다.
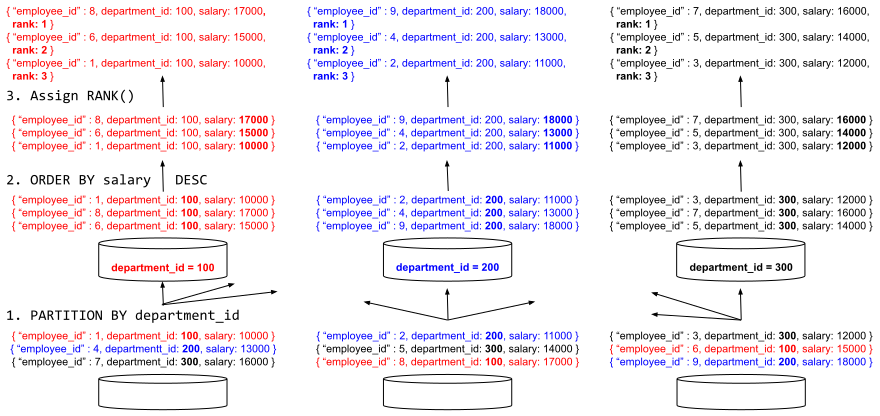
그림 2: 창 함수의 분산, 병렬 쿼리 실행
- 직원 데이터 집합에서 데이터를 선택한 후에는 OVER 절의 PARTITION BY 하위 절에 따라 다시 파티션이 지정됩니다. 초기 데이터 레이아웃에는 각 부서 레코드가 여러 Analytics 노드의 여러 스토리지 파티션에 흩어져 있을 수 있습니다. 파티션 재분할 단계가 끝나면 단일 부서의 모든 직원 기록이 동일한 계산 파티션에 도착합니다. 파티션 재분할 단계는 클러스터의 모든 노드/파티션에서 병렬로 실행됩니다. 가장 일반적인 Analytics 구성에서는 데이터 파티션 수와 클러스터에서 사용 가능한 CPU 코어 수 간에 일대일 관계가 있습니다.
- 각 부서 내의 레코드는 OVER 절의 ORDER BY 하위 절에 따라 정렬됩니다. 각 부서의 레코드가 해당 계산 파티션에 도착하면 쿼리 프로세서가 데이터 정렬을 시작합니다. 이 정렬 단계는 모든 Analytics 노드에서도 병렬로 수행됩니다.
- 그런 다음 각 부서 내에서 정렬된 레코드에 대해 RANK() 함수를 계산합니다. 이 특정 함수는 현재 레코드만 보고 이전 레코드와 비교하면 되므로 추가 데이터 구체화 없이 스트리밍 방식으로 평가할 수 있습니다.
사용 가능한 모든 노드에서 이러한 단계를 병렬로 실행하면 Analytics가 클러스터의 모든 컴퓨팅 리소스를 활용할 수 있습니다. 이를 통해 필요한 성능 목표를 달성하기 위해 더 많은 노드를 추가할 때 선형 확장성을 달성할 수 있습니다.
쿼리 실행 계획 내에서 위의 단계를 어떻게 식별할 수 있는지 살펴보겠습니다. Analytics 설명 계획 기능에 대한 설명은 이전 게시물 [9], 따라서 여기서는 창 기능 평가와 관련된 계획 조각에만 초점을 맞춥니다. (Analytics 쿼리 계획은 아래에서 위로 읽어야 한다는 점을 기억하세요.)
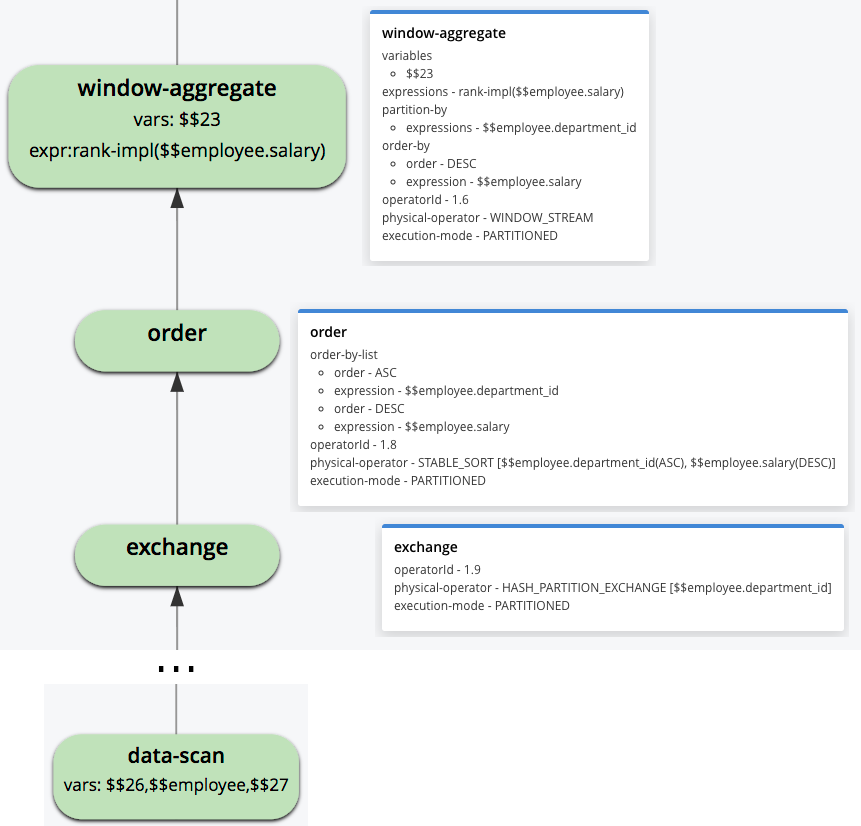
그림 3: 쿼리 실행 계획의 일부분
"data-scan" 연산자에 의해 직원 데이터 세트에서 데이터가 읽혀지고 데이터 재분할을 담당하는 "exchange" 연산자에게 전달됩니다. 재분할 필드는 PARTITION BY 하위 절에서 요청한 대로 "department_id"입니다. 그런 다음 "order" 연산자는 ORDER BY 하위절에 따라 데이터를 정렬합니다. 마지막으로, "window-aggregate" 연산자는 RANK() 함수를 계산합니다. 이 연산자의 "physical-operator" 값이 "WINDOW_STREAM"으로 설정되어 있는데, 이는 연산자가 스트리밍 방식으로 작동하며 추가 데이터 구체화가 필요하지 않음을 의미합니다. "실행 모드" 필드는 모든 연산자에 대해 "PARTITIONED"로 설정되어 있으므로 클러스터의 사용 가능한 모든 계산 파티션에서 모두 실행됩니다.
일부 창 함수를 평가하려면 전체 논리적 파티션(예를 들어 NTILE() 및 PERCENTILE_RANK() 함수의 총 튜플 수)과 관련된 정보 또는 전체 파티션에 대한 여러 반복(집계 함수의 창 프레임을 계산할 때)이 필요할 수 있습니다. 이러한 함수는 비스트리밍 창 연산자에 의해 처리됩니다. 비스트리밍 윈도우 연산자는 쿼리 실행 계획에서 "WINDOW"의 "물리적 연산자" 값으로 식별됩니다. 연산자는 한 번에 하나의 논리적 파티션을 구체화한 다음 해당 파티션의 각 튜플에 대해 윈도우 함수 계산을 시작합니다. 임의의 양의 들어오는 데이터를 처리하기 위해 운영자는 Analytics 실행 엔진의 메모리 관리 모델을 따릅니다. 쿼리 플래너는 각 연산자에게 메모리 예산을 할당합니다. 쿼리 실행 중에는 이 예산을 초과할 수 없습니다. 예산을 초과하는 운영 데이터는 각 운영자가 디스크에 흘려보내고 나중에 메모리를 사용할 수 있게 되면 다시 읽습니다. 쿼리는 일반적으로 여러 연산자로 구성되므로 런타임에 초과할 수 없는 전역 메모리 예산이 있습니다. Analytics 쿼리 프로세서는 들어오는 쿼리에 대해 리소스 기반 로드 제어를 구현하여 모든 노드에서 사용 가능한 메모리 내에서 실행할 수 있는 쿼리만 허용합니다.
또한 분석용 N1QL은 창 함수 호출의 구문 컨텍스트에 대한 제한이 더 적습니다. SQL과 달리, N1QL for Analytics의 쿼리는 WHERE 및 HAVING 절뿐만 아니라 N1QL 전용 LET 절에서도 창 함수를 허용합니다.
예를 들어, 원래 쿼리는 각 부서에서 가장 높은 직급을 가진 직원만 반환하도록 쉽게 수정할 수 있습니다:
|
1 2 3 4 5 |
선택 employee_id, department_id, 급여 FROM 직원 어디 RANK() OVER (파티션 BY 부서_ID 주문 BY 급여 DESC) = 1 |
결론적으로, Analytics의 창 함수는 병렬 데이터 분석 및 보고를 위한 강력한 메커니즘을 제공합니다. Couchbase N1QL 쿼리 언어를 사용하면 사용자가 애플리케이션의 JSON 데이터에서 직접 이러한 함수를 쉽게 평가할 수 있으므로 복잡한 ETL 처리를 피할 수 있습니다.
Couchbase Server 6.5 다운로드 지금 바로 문의하세요. 포럼 으로 문의하세요.
참조
[1] Couchbase Server 6.5 GA 발표 - 새로운 기능 및 개선 사항
https://www.couchbase.com/blog/announcing-couchbase-server-6-5-0-whats-new-and-improved/
[2] 창 기능과 동등한 수준
https://www.couchbase.com/blog/on-par-with-window-functions-in-n1ql/
[3] N1QL 창 함수 및 CTE로 더 큰 그림 얻기
https://www.couchbase.com/blog/get-a-bigger-picture-with-n1ql-window-functions-and-cte/
[4] 카우치베이스 애널리틱스의 창 기능
https://www.couchbase.com/blog/window-functions-in-couchbase-analytics/
[5] 애널리틱스가 포함된 Couchbase Server 6.0 발표
https://www.couchbase.com/blog/announcing-couchbase-6-0/
[6] 카우치베이스의 모든 것의 역사: DCP
https://www.couchbase.com/blog/couchbases-history-everything-dcp/
[7] 무르타다 알 후바일, 알리 알술리만, 마이클 블로우, 마이클 캐리, 드미트리 리차긴, 이안 맥슨, 틸 웨스트만. 카우치베이스 애널리틱스: 확장 가능한 NoSQL 데이터 분석을 위한 NoETL. PVLDB, 12(12): 2275-2286, 2019
http://www.vldb.org/pvldb/vol12/p2275-hubail.pdf
[8] 카우치베이스 애널리틱스: Under the Hood - 커넥트 실리콘 밸리 2018
https://www.youtube.com/watch?v=1dN11TUj58c
[9] 애널리틱스 플랜 설명 - 1부
https://www.couchbase.com/blog/analytics-explain-plan-part-1/
좋은 게시물입니다!